Artificial Intelligence (AI)
TrendAI™ AIセキュリティレポート2026 ~AIエコシステムの断層~
2025年後半、AIシステムはサイバーリスクの震源地となりました。重大な脆弱性の増加とともに、攻撃者はAIスタックのあらゆるレイヤーを標的としています。AIエコシステム全体に存在する基盤的な弱点が拡大する中、組織にはより警戒的でAIを前提とした防御アプローチが求められています。


- AI関連のCVEは急増しており、2025年だけで2,130件が公開されました。これは前年比34.6%の増加です。評価済みのAI脆弱性の約半数が「高」または「緊急」に分類されており、特にエージェント型AIやMCPサーバといった新しい領域では、複雑性の高さやセキュリティ強化のばらつきが影響しています。
- 多くのAIサーバがインターネットに直接公開されており、古いソフトウェアを稼働させたまま適切なセキュリティ対策が施されていないケースも確認されています。これにより、機密データの漏洩や不正アクセスのリスクが高まっています。
- サイバー犯罪者は、専用に開発されたAIツールだけでなく、正規のAIプラットフォームも悪用して活動を拡大しています。具体例として、ディープフェイクを用いた詐欺、AI生成マルウェア、エージェント型システムの悪用などが挙げられます。
- モデルの改ざん、トークナイザー*の操作、不安全な依存関係など、AIサプライチェーンに関する構造的なリスクも顕在化しています。これらは運用停止などの重大な影響を引き起こす可能性があり、サプライチェーンの完全性確保と継続的な監視が不可欠です。
*トークナイザー:AIにおいて自然言語処理を行う場合に、処理の基本的な単位であるトークンに分割する作業またはそのためのツール。
AIはサイバーセキュリティの環境を大きく変えつつあり、これまでにない機会を生み出す一方で、複雑で新たなリスクももたらしています。
TrendAI™ Researchによる広範な分析では、AI関連の脆弱性が増加していることが明らかになりました。2018年以降、6,000件を超える事例が確認されており、2025年には過去最大の増加が記録されています。こうした脆弱性の件数と深刻度の拡大は、急速に進むAI導入とセキュリティ体制の整備との間に大きなギャップを生み出し、サイバー攻撃の温床となっています。悪意ある攻撃者は引き続き、AIインフラ、アプリケーションレイヤー、サプライチェーンの各要素に存在する弱点を悪用しています。特に、Model Context Protocol(MCP)*サーバやエージェント型AIなどの新興領域では、高リスクおよび重大な脆弱性が集中しています。また、インターネット上に公開されたままのAIシステムや、更新が行われていないAI環境の増加も、組織が十分なハードニング、監視、アップデート体制を整えないままAI統合を急ぐ中で、システム全体のリスクをさらに拡大させています。
*MCP:AIが外部サービスと安全に接続・連携するためのプロトコル。AnthropicをはじめとするAI開発企業が推進している。
(関連記事)
AIの新たな潮流~1,000億パラメータの巨大モデルは「足かせ」になりつつある
さらに、AIシステムの武器化と悪用は、現代のサイバー脅威の特徴の一つとなりつつあります。攻撃者はAIを利用してマルウェアを生成したり、ディープフェイクを用いた詐欺を実行したりしています。また、自律的に動作するエージェント型AIシステムは、サイバー犯罪者に対して、状況に応じて変化する多段階攻撃を実行する手段を提供しています。
これらの問題は相互に重なり合いながら継続的に拡大しており、今日のAI中心の世界の基盤に潜む「断層」を浮き彫りにしています。その結果、組織のセキュリティへの取り組み方には根本的な転換が求められています。従来のような静的でコンプライアンス中心の対策だけでは、もはや十分とは言えません。セキュリティチームは、将来のリスクを予測し軽減できる、適応的かつ多層的な戦略へと進化する必要があります。本レポートでは、こうしたリスクを詳細に分析するとともに、ますます複雑化し相互接続が進むAIエコシステムにおいて、組織のレジリエンスを強化するための指針を提示します。
AIの脆弱性
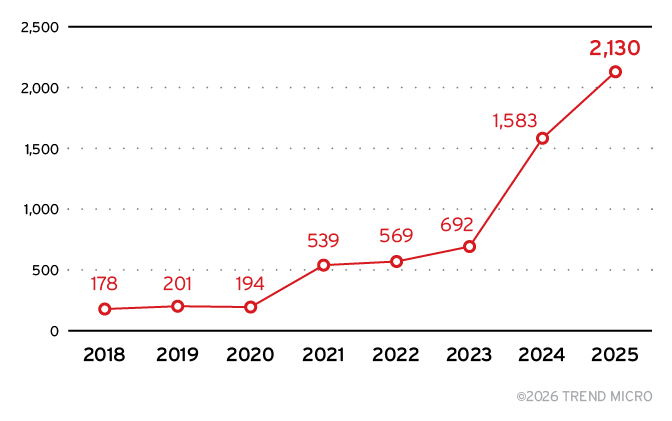
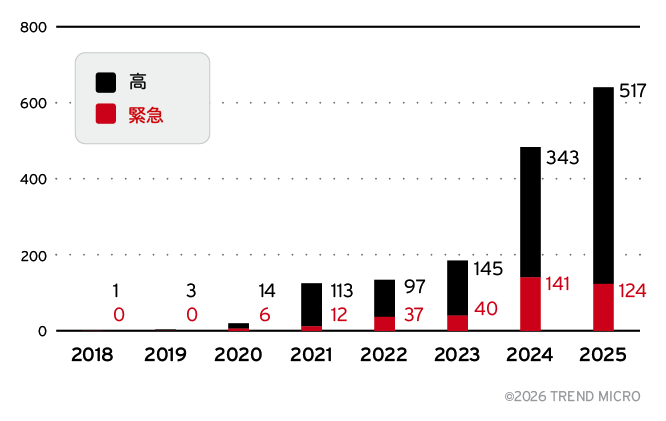
現在、AIエコシステムはサイバーセキュリティの観点から重大なリスク要因となりつつあります。TrendAI™ Researchは、330,239件の脆弱性(CVE)を分析し、2018年から2025年の間にAIシステムに直接影響する6,086件の固有の脆弱性が公開されていることを確認しました。その推移は図1に示されています。
(関連記事)
ÆSIRの登場:AIのスピードでゼロデイ脆弱性を見つけ出す
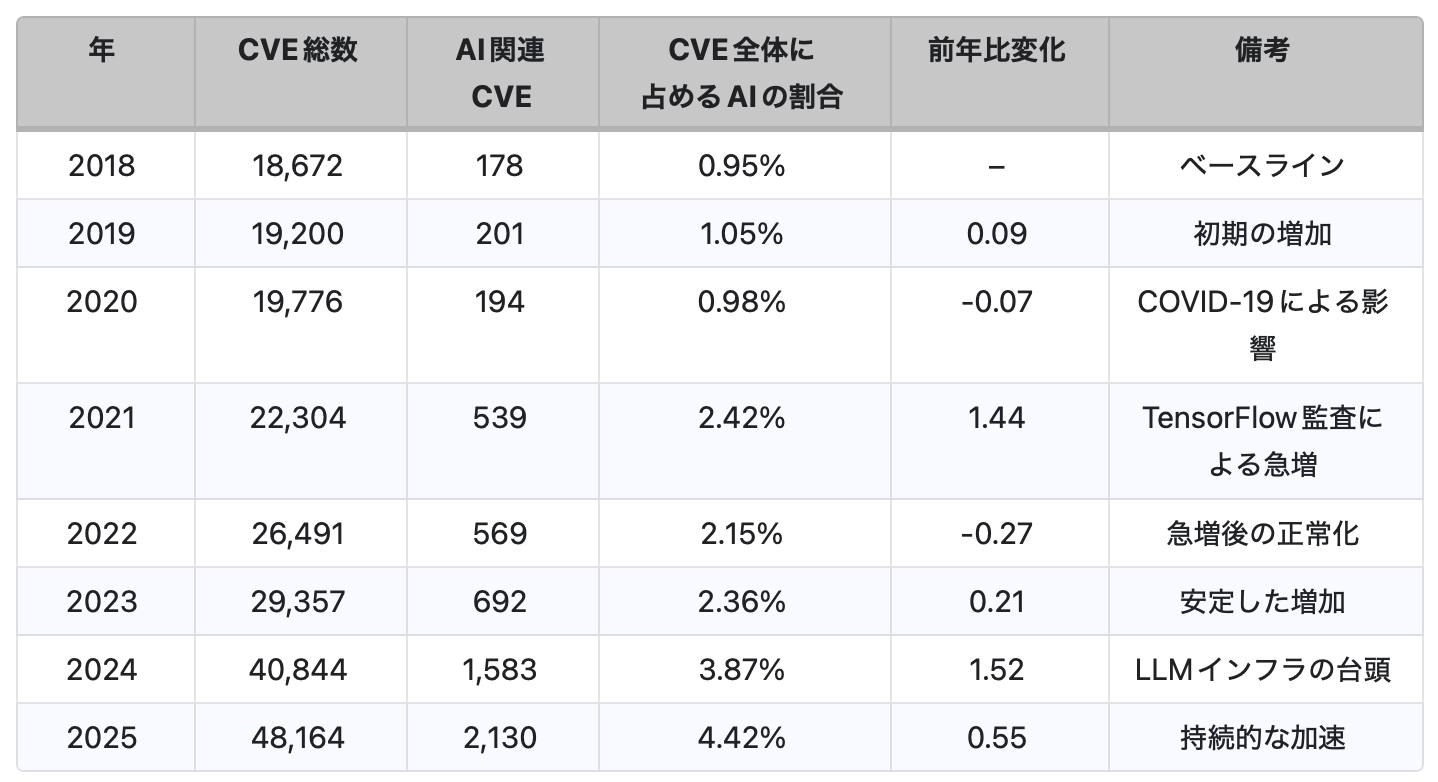
特に注目すべき点として、2025年だけで2,130件のAI関連脆弱性が公開されており、これは前年比34.6%の増加に相当します。この増加率は、CVE全体の公開件数の増加率である17.9%をほぼ倍近く上回っており、AIシステムが急速に普及しているだけでなく、攻撃者からの関心も高まっていることを示しています。
主な調査結果
- 2018年から2025年までのAI関連CVE総数:6,086件(AIの8つのサブカテゴリにわたる脆弱性)
- 2025年のAI関連CVE:2,130件、前年比34.6%増(CVE全体の増加率17.9%と比較)
- 2025年の全CVEに占めるAI関連CVEの割合:4.42%(これまでで最も高い年間比率)
- 2018年から2025年の高/緊急レベルAI関連CVE:1,593件(AI関連CVE全体の26.2%、CVSSスコア7.0以上)
- 2025年の高/緊急レベルAI関連CVE:641件(高 517件、緊急 124件)
- CVEデータベース全体の件数:330,239件(うち2025年は48,164件)
全体像:AIアタックサーフェスのデータ
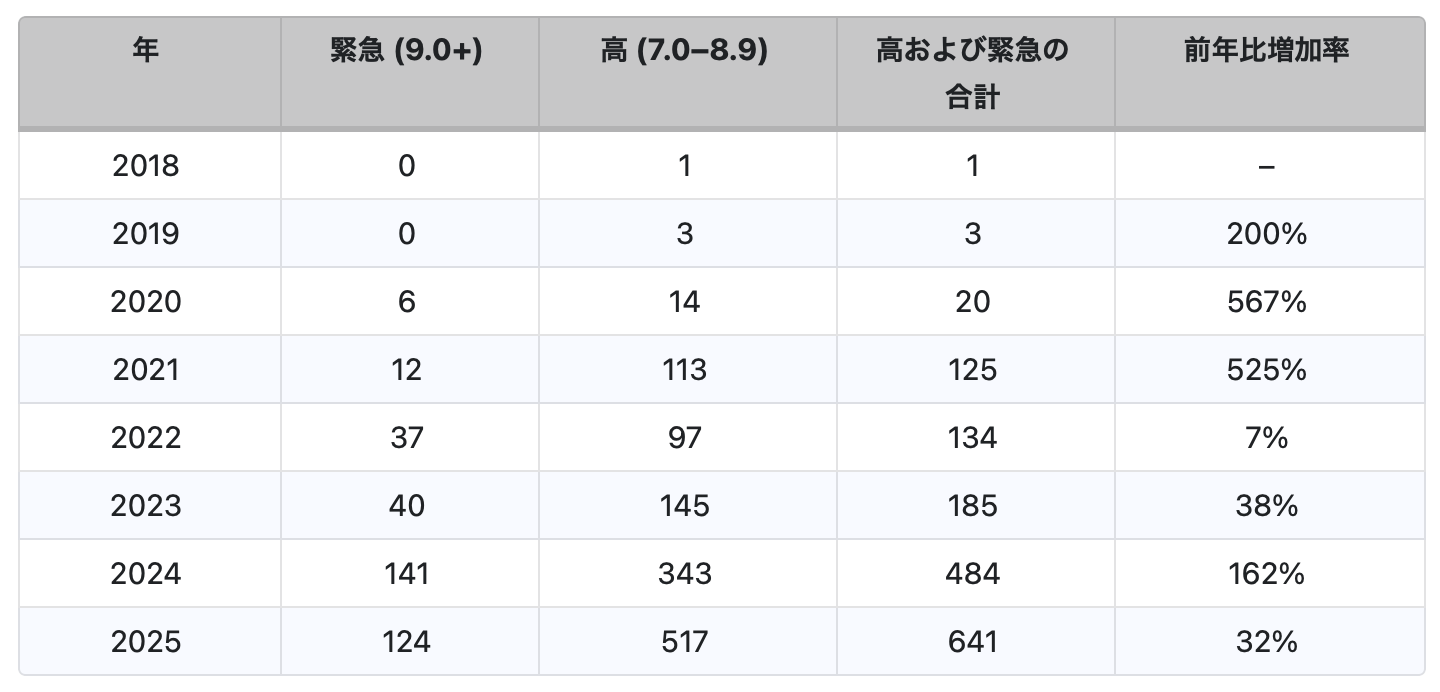
2025年の加速(+0.55パーセント)は、過去数年の動向とは本質的に異なる特徴を示しています。表1は、2018年から2025年までの脆弱性データをまとめたものです。今回の増加は、大規模言語モデル(LLM)ツール、MCPサーバ、そして従来型の機械学習(ML)/GPU分野など、複数の領域にわたって広く発生しており、特定のベンダーによる監査の結果として生じた一時的な増加ではありません。
サブカテゴリ:すべてのAI脆弱性が同じではない
AIの脆弱性は、以下に示す8つの異なるサブカテゴリに分類されます。なお、これらのサブカテゴリは相互に排他的ではなく、1つのCVEが複数のサブカテゴリに分類される場合があります。
- GPUおよびAIハードウェア(3,127件、51.4%):NVIDIAドライバー、CUDA*ライブラリ*、vGPUソフトウェア*、DGXプラットフォーム*などを含みます。主にメモリ破損に起因する脆弱性が多く、権限昇格やコンテナエスケープを可能にするケースが見られます。
- MLフレームワーク(1,624件、26.7%):TensorFlow*、PyTorch*、MLflow*などが該当します。主なリスクは、悪意あるモデルファイルに埋め込まれたコードが実行されることによるサプライチェーン侵害です。
- LLMツールおよびアプリケーション群(1,243件、20.4%):ChatGPT登場以降の急速な普及を反映しています。Langflow*、vLLM*、Dify*、AnythingLLM*などが、十分に成熟したセキュリティ対策がないまま展開されるケースが多く、コードインジェクション、SSRF、パストラバーサルなどの脆弱性が多く確認されています。
- AIモデルセキュリティ(876件、14.4%):モデル提供基盤、推論エンジン、検証システムなどが対象です。これらの脆弱性は、モデルの盗難、敵対的操作、不正アクセスを可能にする場合があります。
- AIデータパイプライン(755件、12.4%):データの取り込み、前処理、特徴量エンジニアリングなどを含みます。データポイズニング、学習データの流出、MLライフサイクルの改ざんといったリスクが存在します。
- Agentic AIシステム(363件、6.0%):自律的に動作するAIシステムにおける脆弱性が対象です。ガードレールや実行境界の不備により、AIエージェントが外部システムと連携する際に新たな攻撃経路が生まれます。
- AIサプライチェーン(114件、1.9%):パッケージマネージャー、モデルレジストリ、依存関係管理などが含まれます。改ざんされたモデルや悪意あるパッケージを通じて、サプライチェーン攻撃が発生する可能性があります。
- MCPサーバ(102件、1.7%):新たに登場したサブカテゴリであり、2025年に発見された102件のうち95件がこの領域に該当します。MCPは設計上、コマンドインジェクションのリスクを伴う可能性があります。
*CUDA(Compute Unified Device Architecture):NVIDIA製GPUのパフォーマンスを最大化するために開発されたプログラミング環境。
*vGPU(Virtual GPU):NIVIDIA製GPUをサポートするソフトウェア仮想化ソリューション。物理GPUを複数のマシン間で共有するための技術。
*DGXプラットフォーム:大規模AIシステム向けに開発されたNVIDIAのスーパーコンピュータの名称。
*TensorFlow:Googleが開発する機械学習向けのオープンソースソフトウェアライブラリ。
*PyTorch:PyTorch Foundationが開発する機械学習向けのオープンソースウェアライブラリ。
*MLflow:Databricksが開発する機械学習向けのオープンソースのソフトウェア管理プラットフォーム。
注:これらのサブカテゴリは重複して分類される場合があるため、各カテゴリの合計は8,204件となっています。一方、本データセットに含まれる固有のCVEは6,086件です。すべての割合は、6,086件のCVE総数を基準に算出しています。
深刻度の分布:リスクが集中する領域
表2に示されているように、AI関連の脆弱性の深刻度分布を見ると、評価済みのAI関連CVEのほぼ半数が高または緊急レベルに分類されており、AIエコシステム全体に重大なセキュリティリスクが存在することが明らかになっています。記録されたAI関連脆弱性6,086件のうち、3,257件にCVSSスコアが割り当てられており、そのうち11.1%が緊急(CVSSスコア9.0以上)、37.9%が高(CVSSスコア7.0〜8.9)に分類されています。合計すると、高および緊急レベルのCVEは1,593件となり、評価済み脆弱性の48.9%、AI関連CVE全体の26.2%を占めています。
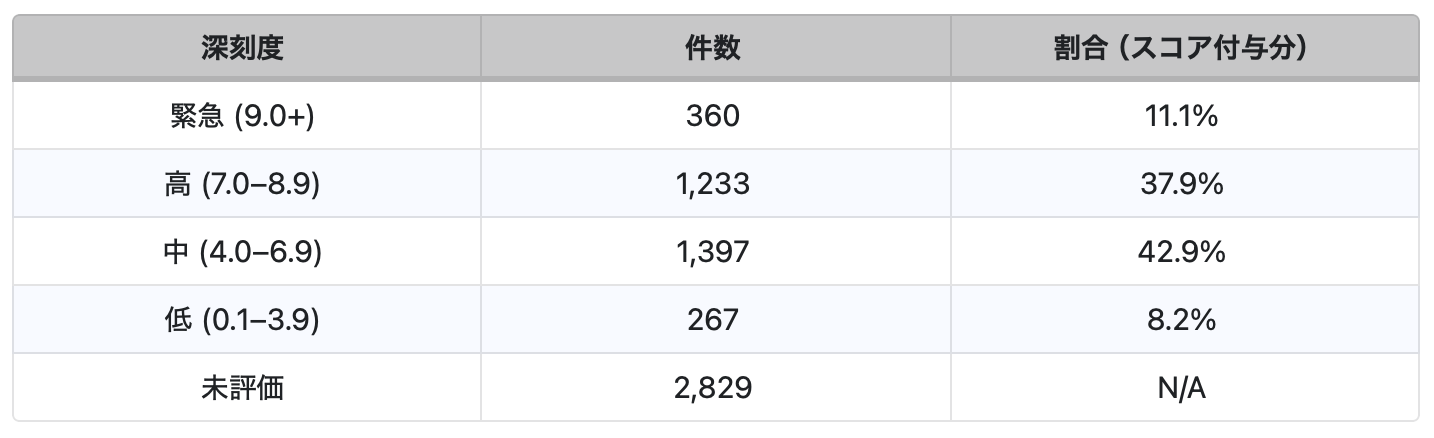
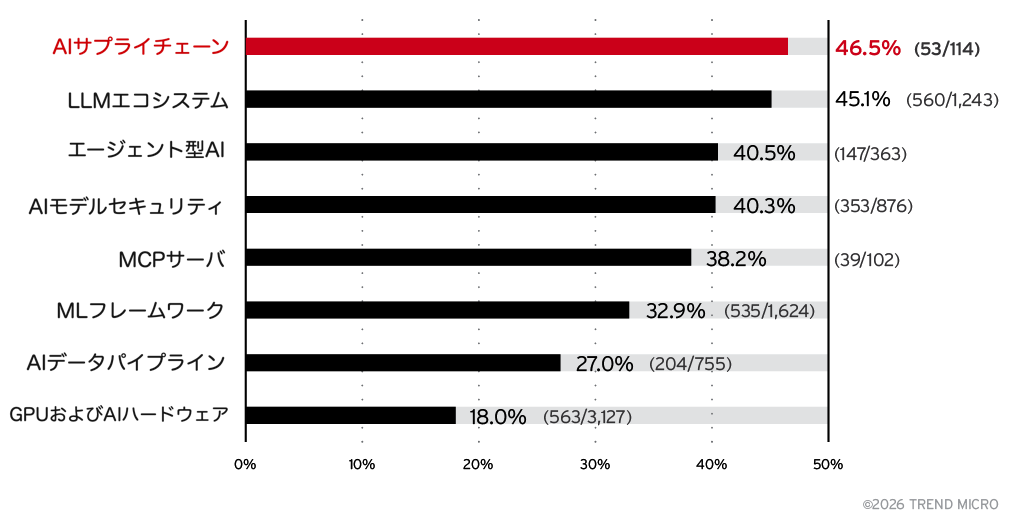
図2は、高および緊急レベルの脆弱性が、AIエコシステムの中でも特に新しく急速に成長している領域に集中していることを示しています。最も高い割合を示しているのはAIサプライチェーン(46.5%)とLLMエコシステム(45.1%)であり、続いてエージェント型AI(40.5%)、AIモデルセキュリティ(40.3%)が続きます。MCPサーバも38.2%と比較的高い割合を示しています。一方で、より成熟したカテゴリであるMLフレームワーク(32.9%)、AIデータパイプライン(27%)、GPU/AIハードウェア(18%)では、高・緊急レベルの脆弱性の割合は比較的低くなっています。総じて見ると、急速に導入が進む新しいAIコンポーネントは、複雑な統合構造やセキュリティ対策のばらつきなどの要因により、相対的に高いリスクを抱えていることがわかります。
加速するリスク:AIアタックサーフェスの進化
図3のデータおよび表3に示されているように、AIの脆弱性環境はこれまでに3つの異なるフェーズを経て進化してきました。
- フェーズ1(2018–2020):GPUおよびAIハードウェアのサブカテゴリにおける脆弱性が中心でした。件数は比較的少なく、高または緊急レベルのCVEもほとんど確認されていませんでした。
- フェーズ2(2021–2023):MLフレームワークのサブカテゴリにおける脆弱性が主流となりました。これはGoogleによるTensorFlowの体系的なセキュリティ監査が大きく影響しています。
- フェーズ3(2024–2025):LLMツールおよびアプリケーションのサブカテゴリにおける脆弱性が現在の中心となっています。LLMエコシステムのサブカテゴリにおけるCVEは前年比80.4%増(419件 → 756件)となりました。2025年には高/緊急レベルのCVEが641件確認されており、2024年の484件からさらに増加しています。
本調査の重要な知見:AIの脆弱性の焦点がインフラ層からアプリケーション層へと移行していることは、AIの普及により本番環境への導入が推進すると共に、実際の利用に即した層における脆弱性調査が進んでいることを示しています。
2021年の急増は単一ベンダーによる監査が原因であり、実態としては一時的な増加でした。一方、図4に示されている2024年から2025年にかけてのAI脆弱性の前年比増加は、偶発的な要因ではなく、構造的な要因による明確な加速を示しています。最も大きな増加を示したのはエージェント型AIで、CVE件数は74件から263件へと増加(+255.4%)しました。これに続くのがAIサプライチェーンで、26件から52件へ倍増しています。また、LLMエコシステムも419件から756件へと増加(+80.4%)しました。コアカテゴリであるAIモデルセキュリティ(+76.1%)およびMLフレームワーク(+52.2%)も大きく拡大しており、GPUおよびAIハードウェアも21.6%増加しています。一方で、AIデータパイプラインは11.4%減少しました。また、MCPサーバは2024年には該当する脆弱性が存在しませんでしたが、2025年には95件のCVEが確認され、新たなアタックサーフェスとして浮上しました。これらの変化は総じて、AIの導入拡大とシステム構成の複雑化、さらにエージェント型AIやLLMベースのシステムの急速な普及によって、AIのアタックサーフェスが急速に拡大していることを示しています。
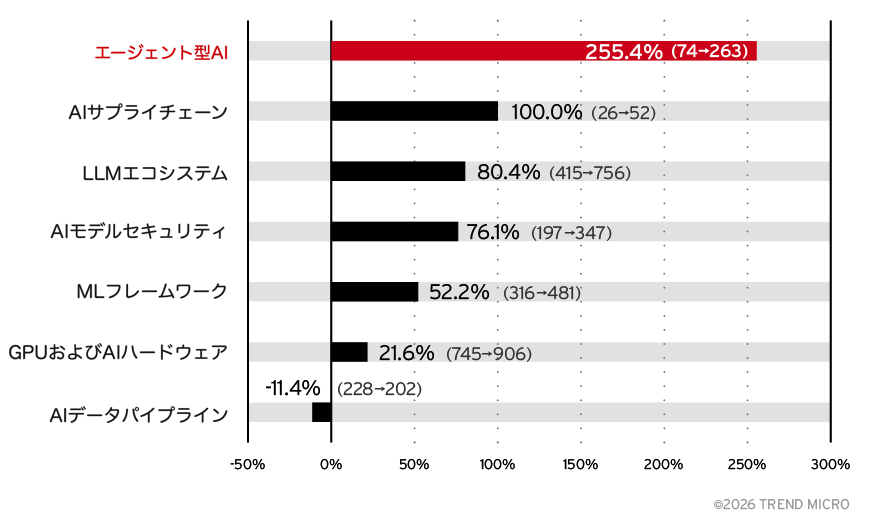
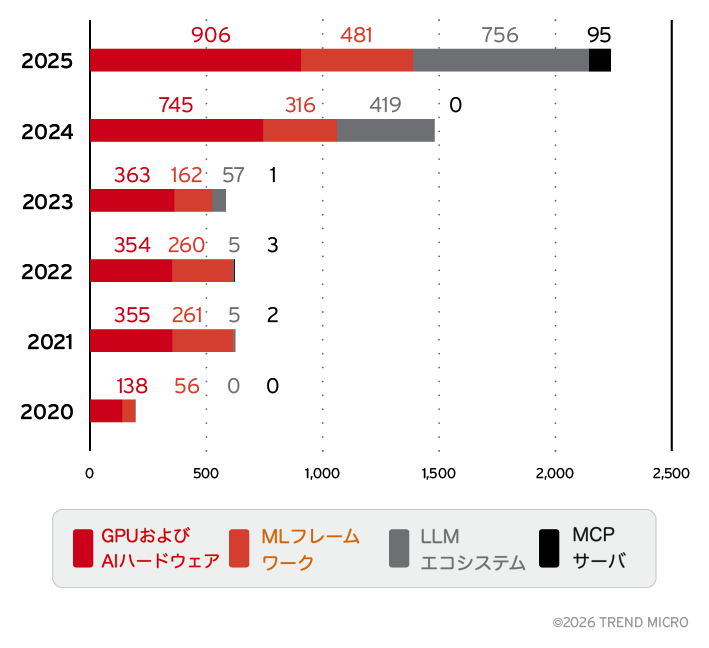
図5に示されているように、2020年から2025年にかけてのAIアタックサーフェスの進化を見ると、主要なサブカテゴリ全体で急速な拡大が確認できます。特に2024年以降、増加のペースが顕著に高まっています。GPUおよびAIハードウェアとMLフレームワークは、この期間を通じて着実に増加してきました。一方、LLMエコシステムは2025年に419件から756件へと急増しています。また、MCPサーバはそれまで脆弱性が報告されていなかったにもかかわらず、2025年に95件の新たなCVEが確認され、突如として新しいリスク領域として現れました。これらの動向は、AIの主要サブカテゴリがより複雑になり、かつ広く導入されるにつれて、AIのアタックサーフェスが拡大していることを示しています。
脆弱性タイプ:AIスタック全体におけるCWEの傾向
Common Weakness Enumeration(CWE)は、ソフトウェアの脆弱性を引き起こす根本的な欠陥を分類するための標準化された識別子です。AIシステム全体におけるCWEを分析することで、単に脆弱性の数だけでなく、AIスタックのどの部分にどのような構造的な弱点が多いのかを把握することができます。
図6に示されているように、各主要AIサブカテゴリには、それぞれのアーキテクチャや運用モデルに応じた固有のCWEプロファイルが存在します。
- GPUおよびAIハードウェア:メモリ安全性を考慮したパッチ適用が必要:GPUおよびAIハードウェアのサブカテゴリでは、境界外書き込み(out-of-bounds write)、整数オーバーフロー、use-after-freeといったメモリ安全性に関わるCWEが多く確認されています。これは、ドライバーやアクセラレーターライブラリに典型的な、性能最適化された低レベルコードの特性を反映しています。
- MLフレームワーク:モデルの来歴(provenance、プロビナンス)検証が必要:一方、MLフレームワークでは、信頼されていないデータのデシリアライズ*やコードインジェクションといった脆弱性が多く見られます。これは、シリアライズ*されたモデルファイルや動的に実行されるコンポーネントへの依存度が高いことに起因しています。
- LLMエコシステム:入力検証が重要:LLMエコシステムでは、より多様な高影響度CWEが確認されています。具体的には、サーバサイドリクエストフォージェリ(SSRF)、クロスサイトスクリプティング(XSS)、コマンドインジェクションなどです。これらは、ユーザ生成入力、プラグインアーキテクチャ、ネットワーク経由でアクセス可能な推論エンドポイントといった特性によって引き起こされています。
- MCPサーバ:厳格な許可リスト制御が必要:MCPサーバは、インジェクション系の脆弱性が非常に高い割合で集中している点が特徴です。問題の60%以上がコマンド実行に関わる脆弱性に関連しており、これはエージェントからツールへの呼び出し(agent-to-tool invocation)という設計上の特性に起因するリスクを示しています。
*シリアライズ:プログラムで扱うデータ(オブジェクトなど)を、通信や保存用に一列のデータに変換すること(バイト列や文字列などへ変換)。デシリアライズはその逆の作業のこと。
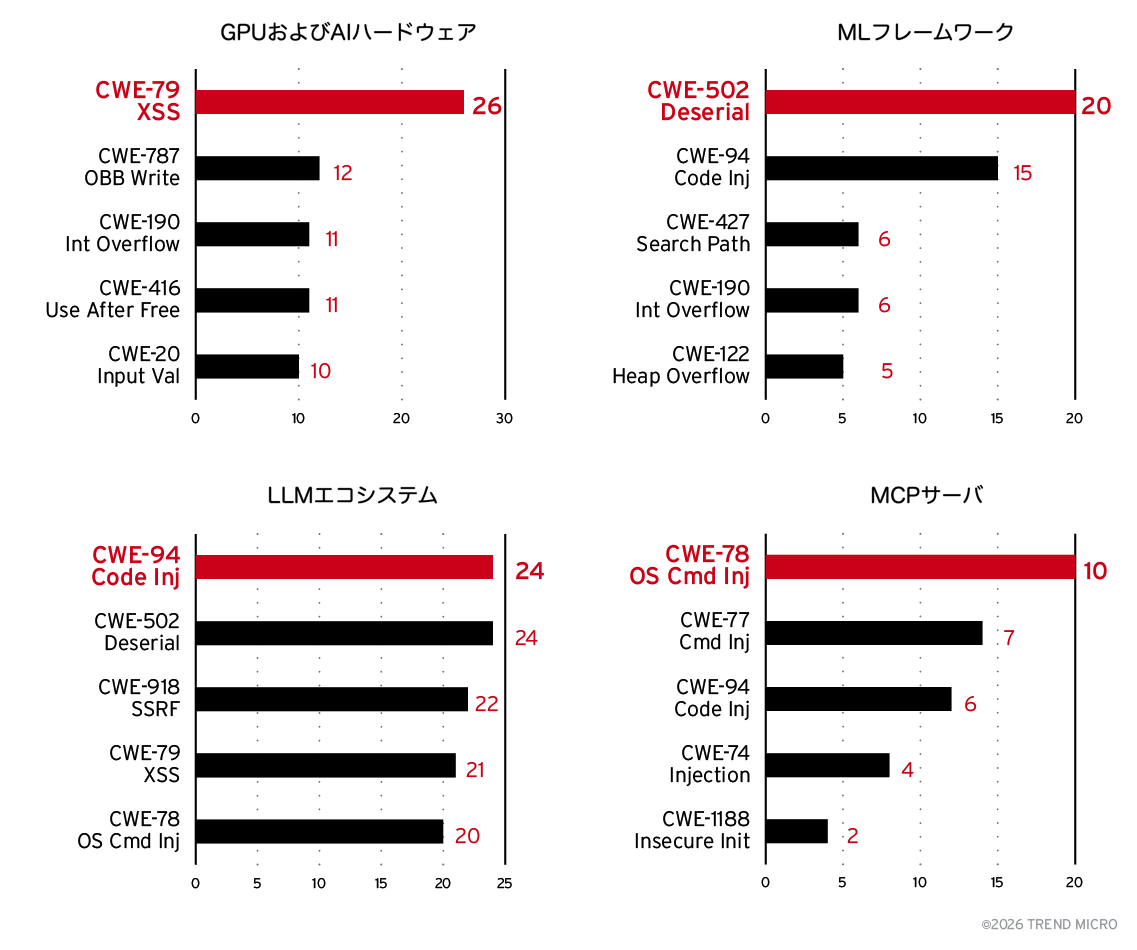
これらのカテゴリ固有の傾向は、AI脆弱性の上位10種類の分析結果とも一致しています。図4に示されているように、ランキングの上位には、クロスサイトスクリプティング(XSS)、コードインジェクション、信頼されていないデータのデシリアライズ、OSコマンドインジェクションなどが含まれています。CWEデータが示しているのは、AIシステムが拡大するにつれて、従来のソフトウェアコンポーネント、プロトコル、そして開発慣行に由来する古典的なソフトウェアの弱点を引き継ぎ、時にはそれをさらに増幅しているという点です。
TrendAI™ Zero Day Initiative™(ZDI)バグバウンティのインテリジェンス
TrendAI™ Zero Day Initiative™(ZDI)は、AIシステムに存在する現実世界の弱点を大規模に悪用される前に特定するための、重要な早期警戒システムとして機能し続けています。本プログラムで報告された35件のAI関連脆弱性は、CVE全体のデータセットを補完する、焦点の絞られた高信頼のデータとなっています。これらは受動的な公開情報ではなく、積極的な攻撃的研究(offensive research)によって発見された脆弱性である点に特徴があります。そのため、TrendAI™ ZDIの知見は、意欲的な攻撃者がどこに注目しているのかを理解するうえで特に価値があります。
TrendAI™ ZDIの調査結果:高価値ターゲットと緊急レベルの脆弱性
最新のTrendAI™ ZDIの調査結果は、明確な傾向を再確認させるものとなりました。すなわち、AIインフラおよびその周辺コンポーネントが高価値の攻撃対象になりつつあるという点です。最も多く影響を受けているベンダーはNVIDIAで、15件のケースが確認されており、これはTrendAI™ ZDIにおけるAI関連事例全体の43%を占めています。これは、AIハードウェアおよびGPUアクセラレーション型ソフトウェアスタックにおける同社の大きな役割を反映しています。一方、Tencentは8件(23%)のケースで影響を受けており、北米にフォーカスした脆弱性データベースでは脆弱性データベースではまだ十分に可視化されていない可能性があるものの、アジア太平洋地域のAIエコシステムのリスクが拡大していることを示しています。影響を受けるベンダーの多様性は、AIのアタックサーフェスが急速に拡大し、グローバルに分散していることを示唆しています。
また注目すべき点として、TrendAI™ ZDIで発見されたAI脆弱性の深刻度分布は業界平均よりも大幅に高い傾向があります。TrendAI™ ZDIを通じて報告された35件のうち、8件(23%)が緊急レベル(CVSSスコア9.0以上)と評価されました。これは、AI関連CVE全体のデータセットにおいて緊急レベルが11.1%にとどまっていることと比較すると、2倍以上の割合です。この差は重要な意味を持ちます。攻撃的研究によって発見されたバグは、すぐに悪用可能で影響も大きい可能性が高く、攻撃者の関心が向かう最前線を示していることを意味しています。
Pwn2Own Berlin 2025:AI脆弱性研究の転換点
2025年には、AIインフラへの注目をさらに高める重要な出来事がありました。初めてPwn2Own Berlinにおいて、専用のAIインフラカテゴリが設けられたのです。このカテゴリでは、Nvidia Triton Inference Serverなどが攻撃対象として設定されました。この変化により、AIシステムは、これまでブラウザ、ハイパーバイザー、自動車システム、産業制御システムなどが対象となってきた競技型エクスプロイト研究の舞台に正式に加わることとなりました。
(関連記事)
バグバウンティイベント「Pwn2Own 2025 Berlin」で初めてAIインフラのゼロデイを確認
AIインフラを正式な競技カテゴリとして追加したことで、Pwn2Ownはセキュリティ研究コミュニティに対し、AIサービスやAIのデプロイメントツールが継続的な分析に値する戦略的ターゲットであることを明確に示しました。Pwn2Ownの過去の事例が示しているように、新しいカテゴリが追加されると、攻撃研究者の注目が集まり、通常は脆弱性発見件数の急増が続きます。そのため、組織は2026年を通じて、推論サーバ、モデルホスティングプラットフォーム、AIネイティブの開発環境に影響する脆弱性の発見が大幅に増加する可能性を想定しておく必要があります。
主要な脆弱性のポイント
進化を続けるAIエコシステムは、もはや個別の弱点によって特徴付けられるものではなく、急速に拡大し、かつ不均一に広がる脆弱性環境によって特徴付けられるようになっています。本分析の結果、リスクは特定の技術領域に集中し、深刻度も高まり、さらにAIシステムを大規模に導入しようとする動きに伴って、前年比で加速していることが明らかになりました。ハードウェアレベルの欠陥やサプライチェーンのリスクに加え、MCPサーバのようなまったく新しいアタックサーフェスの登場など、データはAI関連の脆弱性が単に増加しているだけでなく、AIスタック全体に連鎖的なリスクを生み出す形で集中しつつあることを示しています。以下の主要なインサイトは、各業界でAI導入が進む中で、防御側が特に注目すべき領域を示しています。
- GPUおよびAIハードウェアのカテゴリがアタックサーフェスの中心を占める:GPUドライバー、CUDAライブラリ、AIアクセラレーターは、AI関連CVE全体の51.4%(6,086件中3,127件)を占めており、単一カテゴリとして最大です。これにMLフレームワーク(26.7%)、LLMツールおよびアプリケーション(20.4%)が続きます。
- クロスサイトスクリプティングが最多、コードインジェクションがそれに続く:CWEデータを持つAI関連CVEの中では、CWE-79(XSS)が9.3%で最多となり、CWE-94(コードインジェクション)が6.8%、CWE-502(デシリアライズ)が5.7%で続きます。Pickleファイル、モデル重み、シリアライズされたテンソルなどは、リモートコード実行(RCE)の主要な攻撃経路となっています。
- AIサプライチェーンのカテゴリは最も高い深刻度集中を示す:AIサプライチェーンに関する脆弱性の46.5%が高/緊急レベルであり、これはAI関連カテゴリの中で最も高い割合です。信頼できないソースから取得された事前学習モデルは、システム全体に影響するリスクとなります。
- 高/緊急レベルの脆弱性が急増している:高/緊急レベルのAI関連CVEは、2020年の20件から2025年には641件へと大幅に増加しました。これは脆弱性発見能力の向上に加え、本番環境のAIシステムにおけるより危険な脆弱性が実際に増えていることを示しています。
- MCPは新たなフロンティアとなっている:MCPサーバでは、2025年だけで95件のCVEが確認されており(2025年以前はほぼゼロ)、完全に新しいアタックサーフェスとなっています。MCP関連の脆弱性の60%以上は、インジェクション攻撃(CWE-77、CWE-78、CWE-94)に関連しています。
- 増加の加速は明確である:2025年には、AI関連CVEが全CVEに占める割合は4.42%となり、これは過去最高の年間比率です。この傾向が続けば、2026年にはAI関連脆弱性が全CVEの5%以上を占める可能性があります。
- 評価済みAI関連の脆弱性の26.2%が高/緊急レベル:CVSSスコアが付与された3,257件のAI関連脆弱性のうち、1,593件が高または緊急レベルに分類されています。特にAIサプライチェーンのカテゴリでは、46.5%と最も高い集中度が確認されています。
- すでに全CVEの4.42%がAI関連:これは過去最高の年間割合であり、2024年の3.87%から増加しています。CVE件数は1,583件から2,130件へと34.6%増加しており、AI関連CVEの総数は6,000件を超えました。
- カテゴリの集中はシステム全体のリスクを高める:GPUおよびAIハードウェア(3,127件)、MLフレームワーク(1,624件)、LLMエコシステム(1,243件)の3カテゴリだけで、AI関連CVEの大部分を占めています。
- 中国のAIプラットフォームは北米にフォーカスした脆弱性データベースでは、カバーし切れていない可能性:TrendAI™ ZDIのデータによると、TencentはAI関連バグバウンティ提出の23%(35件中8件)を占めています。また、HunyuanVideo*およびHunyuanDiT*では、CVSS9.8のデシリアライズ型RCE脆弱性が確認されています。
- Pwn2Own Berlin 2025はAIが主流の攻撃対象となったことを示す:初めてPwn2OwnにAIインフラカテゴリが追加され、Nvidia Triton Inference Serverがそのターゲットの一つとなりました。
*HunyuanVideo:AI動画作成ツールの1つ。
*HunyuanDiT:画像生成ツールの1つ。
AI脆弱性の予測:2026年の見通し
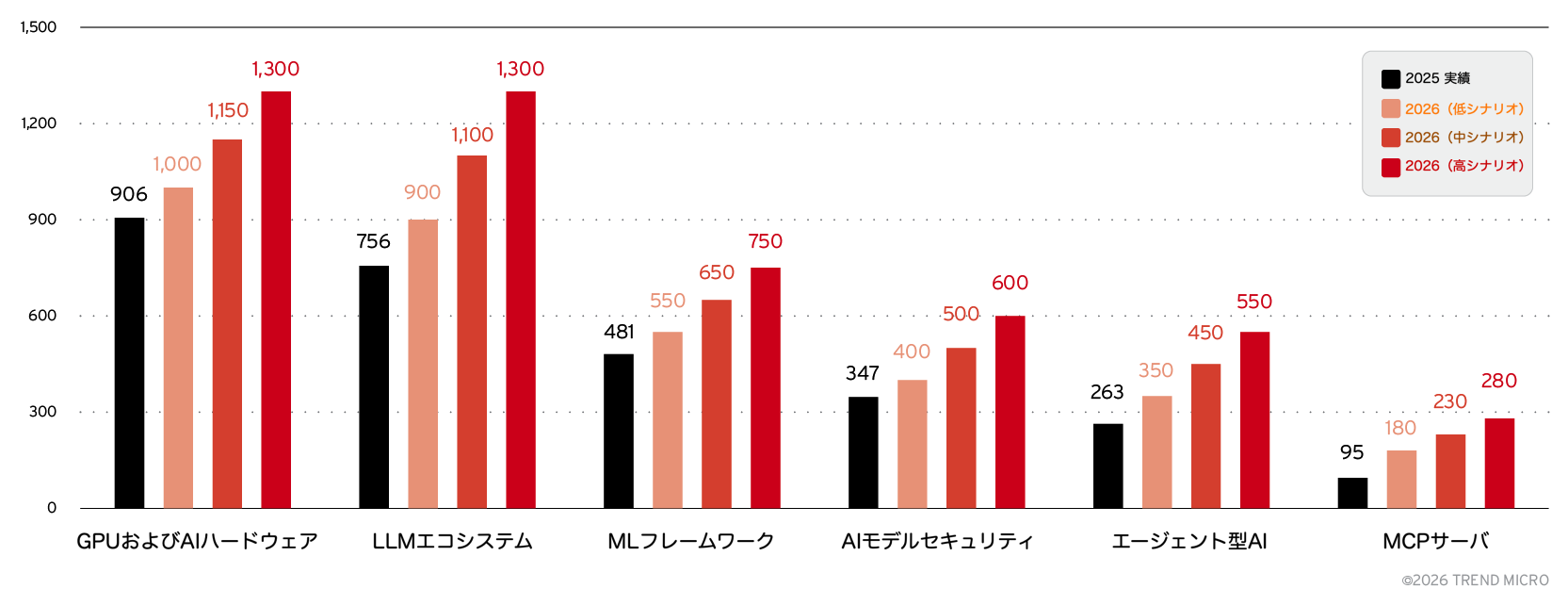
2025年に見られたAI関連脆弱性の加速は、2026年にはさらに強まると予測されています。将来を見据えた分析によれば、業界は再び大幅な増加の年を迎える可能性があり、2026年にはAI関連CVEが2,800件から3,600件に達すると見込まれます。これは、2025年の2,130件から31%〜69%の増加に相当します。この増加は、エージェント型AIシステムの急速な普及、LLMエコシステムの拡大、そして重要なAIインフラの継続的な露出によって主に引き起こされると考えられます。図7に示されている予測は、単に脆弱性の件数が増加するだけでなく、AIスタック全体にわたってリスクの分布がさらに広がることを示しています。特に、MCPサーバやAIシステムを推奨といった新しいカテゴリでは、前年比で最も急速な増加が見込まれています。この見通しは、重要な現実を浮き彫りにしています。AIの能力が成熟するにつれて、それを標的とする脅威の複雑性と規模もまた拡大していくということです。
- GPUおよびAIハードウェア:1,000〜1,300件(+10%〜43%)
- LLMエコシステム:900〜1,300件(+19%〜72%)
- MLフレームワーク:550〜750件(+14%〜56%)
- AIモデルセキュリティ:400〜600件(+15%〜73%)
- エージェント型AI:350〜550件(+33%〜109%)
- MCPサーバ:180〜280件(+89%〜195%)
方法論およびデータソース
本レポートのすべての分析結果において、正確性、一貫性、再現性を確保するため、TrendAI™ Researchは包括的な脆弱性インテリジェンスと透明性の高いデータ処理に基づく厳格な方法論を採用しました。本分析は、大規模なCVEデータセット、複数段階のAI分類ワークフロー、そして厳密なスコアリングおよび検証基準に基づいています。これにより、AI関連脆弱性が時間の経過とともにどのように進化してきたかを、明確かつ信頼性の高い形で把握することが可能となっています。以下に、本レポートの分析結果を支えるデータソース、分類プロセス、評価基準、および検証手順の概要を示します。
- データソース:ÆSIR / MIMIR 脆弱性インテリジェンスプラットフォーム。TimescaleDBに格納された330,239件のCVEを対象に分析
- AI分類:2段階パイプライン。キーワードによる事前フィルタリングと、LLMによる検証を組み合わせ、8つのサブカテゴリに対して信頼度スコア付きで分類
- 深刻度評価:CVSS v3スコアを使用。6,086件のAI関連脆弱性のうち3,257件(53.5%)にスコアが付与。高:7.0〜8.9、緊急:9.0以上
- カテゴリ重複:CVEは複数のサブカテゴリに分類される場合あり。重複を含む合計は8,204件、一意のCVE数は6,086件
- CWEデータ:664件のAI関連CVEにCWE分類が存在。本レポートのランキングはこのサブセットに基づく
- 分析対象期間:2018年〜2025年(8年間)。2026年の部分データは主要分析から除外
- 検証:すべての数値は2026年1月28日にTimescaleDBから直接クエリ取得。推計値は使用していない
AIは「武器」であり「標的」でもある
AIの時代において、サイバー犯罪の世界は驚くほど高い適応力を示しています。AI技術が成熟し、より多くの人々に利用可能になるにつれて、悪意ある攻撃者はこうした技術を自らの目的のために迅速に武器化してきました。
AIを利用した犯罪は、大きく分けて次の2つのカテゴリに整理できます。
- 武器化(Weaponization):従来の犯罪活動を強化するために、AI技術を意図的に利用すること
- 悪用(Exploitation):正規のAIシステムを不正に利用または操作し、犯罪目的に用いること
AIの武器化に見る犯罪者のイノベーション
AIの犯罪利用は、断片的な試行段階から、体系化された拡張可能なエコシステムへと急速に進化しています。攻撃者はもはや単にAIツールを利用するだけではなく、複数の領域にわたってAIを自らの活動に体系的に組み込んでいます。その結果、脅威環境はより高度化し、組織化されたものへと変化しています。
違法LLMマーケットプレイス:成熟しつつある地下経済
犯罪者向けLLMの市場は、現在統合の段階に入りつつあります。独立して開発されたローカル型の犯罪用LLMは依然として比較的少ないものの、地下市場では「jailbreak-as-a-service」型のサービスが主流となっています。2025年11月に実施した調査では、非常に示唆的な事例が明らかになりました。ある犯罪用LLMは、自前でホスト可能な独立ソリューションとして販売されていましたが、詳細に調査したところ、実際には複数の正規AIサービスのバックエンドを利用した、高度に作り込まれたjailbreakラッパーにすぎないことが判明しました。このように、侵害された正規AIサービスへのアクセスを再パッケージ化して販売する手法は、現在では地下市場における事実上の業界標準となっています。
AIを利用したマルウェア:理論から実践へ
AI生成マルウェアは、かつては理論的な懸念にすぎませんでしたが、現在では実際の事例として確認される段階に入りました。2025年9月には、AIを利用したマルウェア実装に関する研究プロジェクトが誤って実際のマルウェアとして報道される出来事がありました。しかしその後、APT28の活動の一環として開発された実際のマルウェアが、Hugging FaceのAPIを悪用し、実行時にペイロードを生成する仕組みを利用していたことが確認されています。これらの事例は、攻撃者の戦術が進化しつつあることを示す初期ながら重要な兆候です。今後公開予定のレポートでは、攻撃者がAIをマルウェアインフラに直接組み込み、実行時にコードを生成する仕組みを導入し始めている状況について詳しく解説する予定です。
(関連記事)
AI駆動型マルウェアとは何か?
ディープフェイク:雇用詐欺の新しい手口
ディープフェイク技術もまた、懸念すべき方向へと進化しています。2025年7月の研究を基に、その後の調査では雇用詐欺におけるディープフェイクの武器化が確認されています。特に注目すべき事例として、2025年に発覚した、北朝鮮の工作員による巧妙な作戦があります。この作戦では、AI生成の偽の人物像を用いて西側企業のリモートIT職に採用されるという手口が用いられていました。これらの人物は、ビデオ面接の際に高度なディープフェイク技術を利用し、採用プロセスの初期段階を通過するほど説得力のある偽の人格を作り上げていました。さらに、技術面接では舞台裏でAIチャットボットを利用して回答を生成することで、面接を突破するケースも確認されています。採用後、彼らは得た報酬を北朝鮮政権へ送金すると同時に、企業の機密システムや知的財産へアクセスする可能性を持っていました。この作戦は、国家主導の活動、アイデンティティ詐欺、そしてAIを悪用した心理操作が融合した前例のない規模の攻撃を示しています。
正規のAIツールが攻撃者に悪用される
犯罪目的で開発されたAIよりも、むしろ懸念されるのは、正規のAIプラットフォームが悪用されるケースが増えていることです。2025年9月に公開したレポートでは、攻撃者がAIを活用した開発プラットフォームを悪用し、説得力のある偽のCAPTCHAページを迅速に生成していたことを明らかにしました。AIネイティブな開発プラットフォームを利用することで、攻撃者は単に偽のCAPTCHAページを容易に作成できるだけではありません。これらのプラットフォームは、ページの無料ホスティングを提供するだけでなく、正規のインターネットドメイン上でページが公開されることによる信頼性も攻撃者に与えてしまいます。その結果、ユーザが偽ページを正規サイトと誤認する可能性が高まります。
犯罪におけるエージェント型AIの幕開け
犯罪におけるAI活用はこれまで大きく進化してきましたが、今、さらに大きな変化の入り口に立っています。エージェント型AI、すなわち自律的な意思決定と複数ステップにわたる操作を実行できるシステムの登場は、AIを利用した犯罪の次のフロンティアを示しています。
2025年11月、Anthropicは、実環境で確認されたAIが関与するサイバー諜報活動の初期事例の一つを報告しました。TrendAIはこの動向について以前の研究で詳しく分析しており、自律型AIシステムが犯罪に悪用される可能性は単に高いだけでなく、いずれ避けられないと指摘しています。問題は、犯罪者がエージェント型AIを大規模に利用するかどうかではなく、いつそれが起こり、組織や防御側がそれにどこまで備えられているかです。
この新たな脅威の実際の影響を理解するため、詐欺工場(scam factory)のワークフローを再現する実験的研究を実施しました。その結果、AIエージェントを連携させることで、ディープフェイクの人物生成、偽の身元情報、架空の商品、さらには詐欺広告キャンペーンの作成まで、詐欺活動全体を一貫して実行できる可能性があることが示されました。効率性の向上は驚くべきもので、従来は複数の人間のオペレーターが必要だった作業が、最小限の監督だけで自動化できる可能性が示されています。
さらに将来を見据えると、このリサーチペーパーでは、犯罪におけるエージェント型AIの利用がどのように犯罪活動を変革する可能性があるのかを体系的に整理しています。そこでは、AIによる偵察活動や脆弱性発見から、防御側の対策にリアルタイムで適応する完全自動化された攻撃チェーンに至るまでのシナリオを検討しています。これらは、従来とは異なる新たな脅威環境が形成されつつあることを示しており、防御側には迅速な対応と革新的な防御戦略が求められています。
(関連記事)
AI主導のサイバー攻撃時代における企業防御の再定義
詐欺オペレーションの再構築:AIが生み出す詐欺組立ラインの台頭
サイバー犯罪の次の段階:エージェント型AIと自律型犯罪オペレーションへの移行
AIによる自律的脅威と「主体性」の武器化
AIが生成する脅威(ディープフェイクなど)と、AIによって武器化された脅威は明確に区別する必要があります。後者は、人間主導の攻撃から自律的な攻撃運用へのパラダイムシフトを意味します。
現在、AIが自律的に動作する脅威(AI-autonomous threats)の出現を目の当たりにしています。この形態では、AIエージェント自身が攻撃の主要な実行主体となります。AIエージェントは自律的に偵察活動を行い、サプライチェーンの依存関係を分析し、人間の能力を超える速度と規模で脆弱性を特定することが可能です。静的なスクリプトとは異なり、自律型エージェントは状況に応じて推論し、適応する能力を持っています。もしエクスプロイトの試行が失敗した場合でも、エージェントはエラーを分析し、ペイロードを再設計して数ミリ秒以内に再試行することができます。
具体例として、2025年8月に発生した「s1ngularity」インシデントは、正規のAIツールが武器化された事例を示しています。この攻撃では、攻撃者がNxビルドシステム*を侵害し、マルウェアを配布しました。特に重要なのは、このマルウェアが開発者のAIツール(Claude CodeやGemini CLIなど)の存在を検知すると、ローカルのAIエージェントに対して自然言語のプロンプトを送信し、ファイルシステムの列挙や認証情報の流出を指示した点です。つまり、この攻撃は単に悪意あるコードに依存するのではなく、信頼されたAIアシスタントの主体性(エージェンシー)そのものを利用してセキュリティ対策を回避したのです。
*Nx:ソフトウェア開発において、モノリポジトリ向けに最適化されたビルドシステムの1つ。
(関連記事)
武器化されたAIアシスタントと認証情報窃取ツール
進化する脅威ベクトル
AIエコシステムが急速に拡大する中で、攻撃者は新たな攻撃経路を見いだしています。本セクションでは、攻撃者がどのように手法を変化させているのかを分析し、AIセキュリティにおいて現在最前線となっている戦術やリスク領域を明らかにします。
公開されたAIインフラ
2024年末以降、TrendAI™ Researchではインターネット上に公開されたAIインフラの状況を追跡してきました。2025年の年次レポートは今年後半に公開予定ですが、現時点での暫定結果からも、注目すべき重要な発見がすでに明らかになっています。本サブセクションでは、特にインターネット上で公開されているケースが多い2つのコンポーネント、Ollamaの推論サーバとChromaのベクトルストアに焦点を当てます。
Ollama
Ollamaは、ローカルAIモデルをホストするための非常に人気の高い推論フレームワークです。多くの公開モデル(open weights and biasesモデル)がOllamaを通じて利用可能であり、コマンドラインインターフェース、Webインターフェース、HTTP APIといった便利な機能を備えています。デフォルトのインストールではローカルホストからのみアクセス可能ですが、適切な設定を行えばネットワーク経由のWebサービスとしてアクセスすることも可能です。ただし、Ollamaには認証機能が標準で組み込まれていません。そのため、本番環境では通常、認証機能を提供する別のWebサーバの背後に配置し、Ollamaサーバ自体は直接公開しない構成にする必要があります。しかし残念ながら、多くの開発者がこの要件を見落としています。
調査ではShodanを利用し、2025年9月初旬から12月中旬にかけて、インターネット上で公開されている313,000台以上のサーバをスキャンしました。そのうち約230,000台が、この4か月間のいずれかの時点でOllamaをホストしていました。さらにその中の113,000台以上は、基本的なステータスクエリに対して期待通りの応答を返しており、Ollamaの実行インスタンスであることが確認できました。
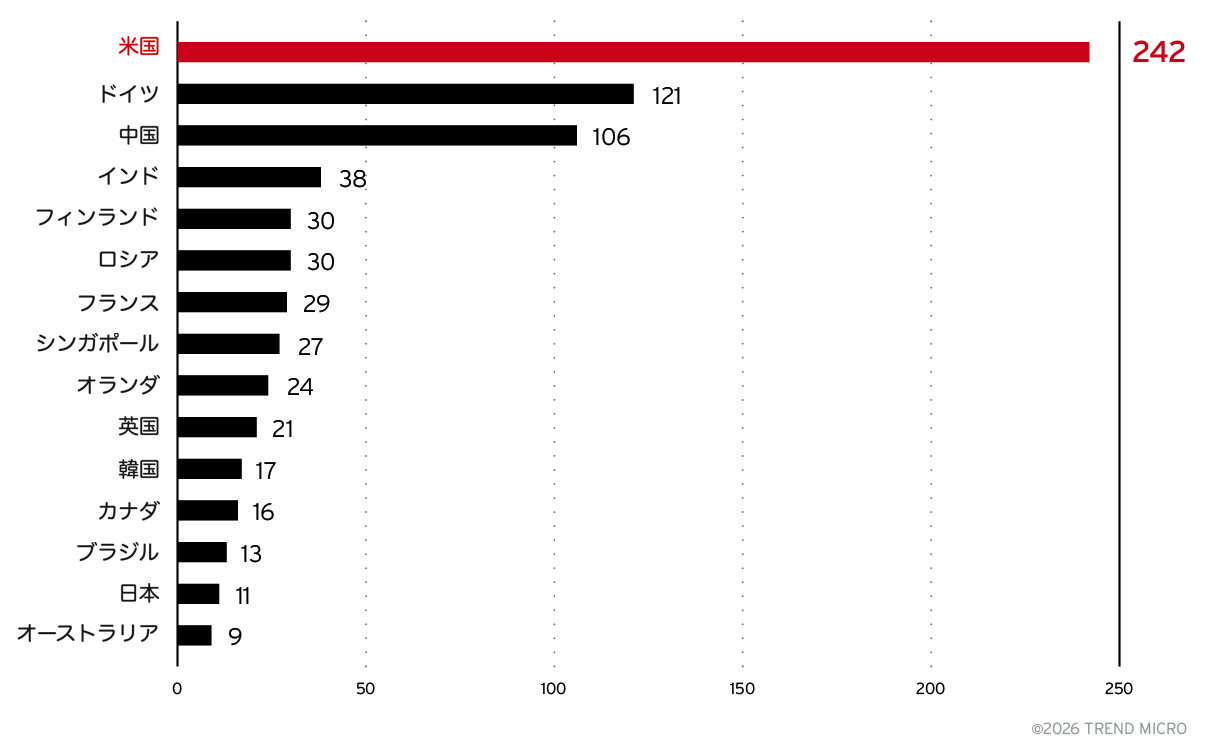
図8に示されているように、米国が圧倒的に多くの導入数を占めています。ただしこれは、他国のユーザが米国のクラウドプロバイダーを利用しているケースが多いことや、米国でのホスティングが最も安価な場合が多いことが理由である可能性があります。モデル推論の大部分の処理はGPU上で行われるため、ネットワーク遅延の影響は比較的小さくなります。また、十分なGPUリソースが利用可能な場所として米国が選ばれている可能性もあります。
米国に続くのは、ドイツ、インド、オーストラリア、日本、中国です。米国へのホスティングの集中を考慮して見ても、自前でモデルサーバをホストすることへの関心は世界的に非常に高いことが分かります。
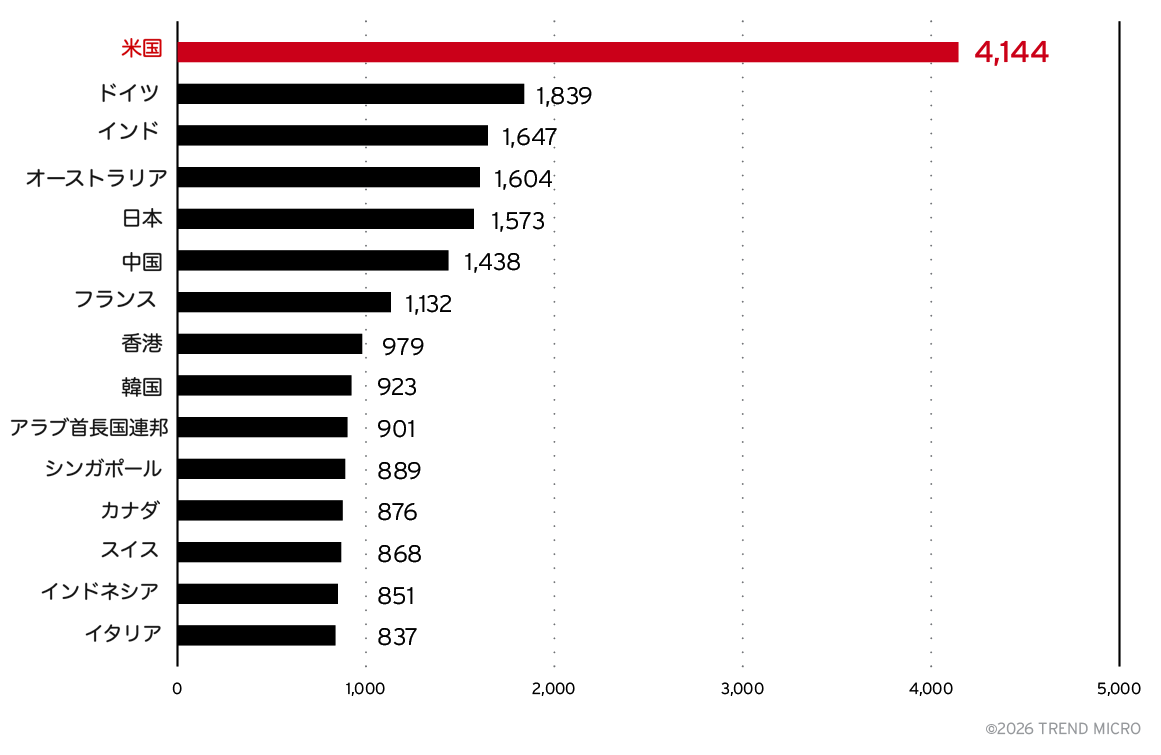
中国は興味深いケースです。初期の観測では中国のサーバがより大きな割合を占めていましたが、2025年初頭にその数は突然大きく減少しました。この理由について明確な説明はありませんが、Shodanから観測できなくなった可能性や、別のサーバタイプへ移行した可能性が考えられます。あるいは、単にインターネット上へ直接公開することをやめたのかもしれません。
図9は、公開されているOllamaサーバの平均稼働期間が、実行されているソフトウェアのバージョンの古さとほぼ一致していることを示しています。これは、多くのサーバが一度デプロイされた後に更新されることなく運用され続けており、古いリリースを狙った攻撃に対して継続的に脆弱な状態に置かれていることを示唆しています。
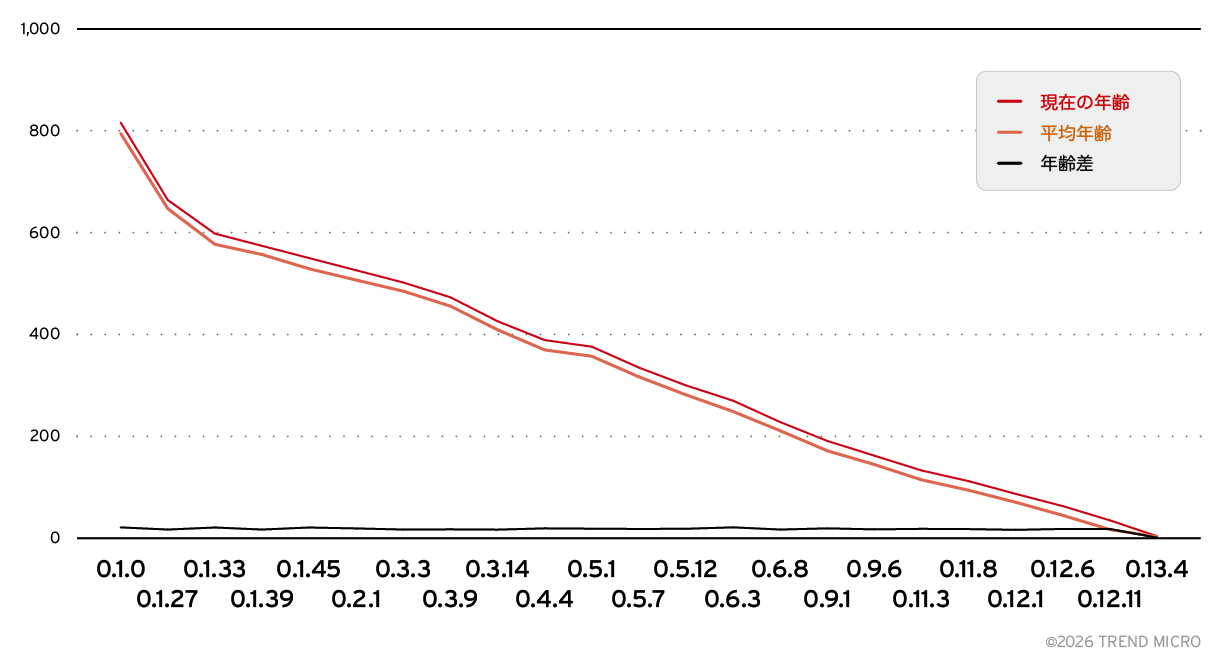
直接的な攻撃のリスクに加え、これらの公開サーバはインターネット上の誰でも自由に利用できる状態にあります。これは、計算コストがサーバ所有者の知らないところで負担されるだけでなく、犯罪者が自らのインフラに投資することなくLLMの機能を無料で利用できることも意味します。さらに多くの場合、これらのサーバではモデルの操作も可能であり、攻撃者がホストされているモデルを悪意あるものに置き換えたり、システムプロンプト自体を書き換えたりすることも可能です。
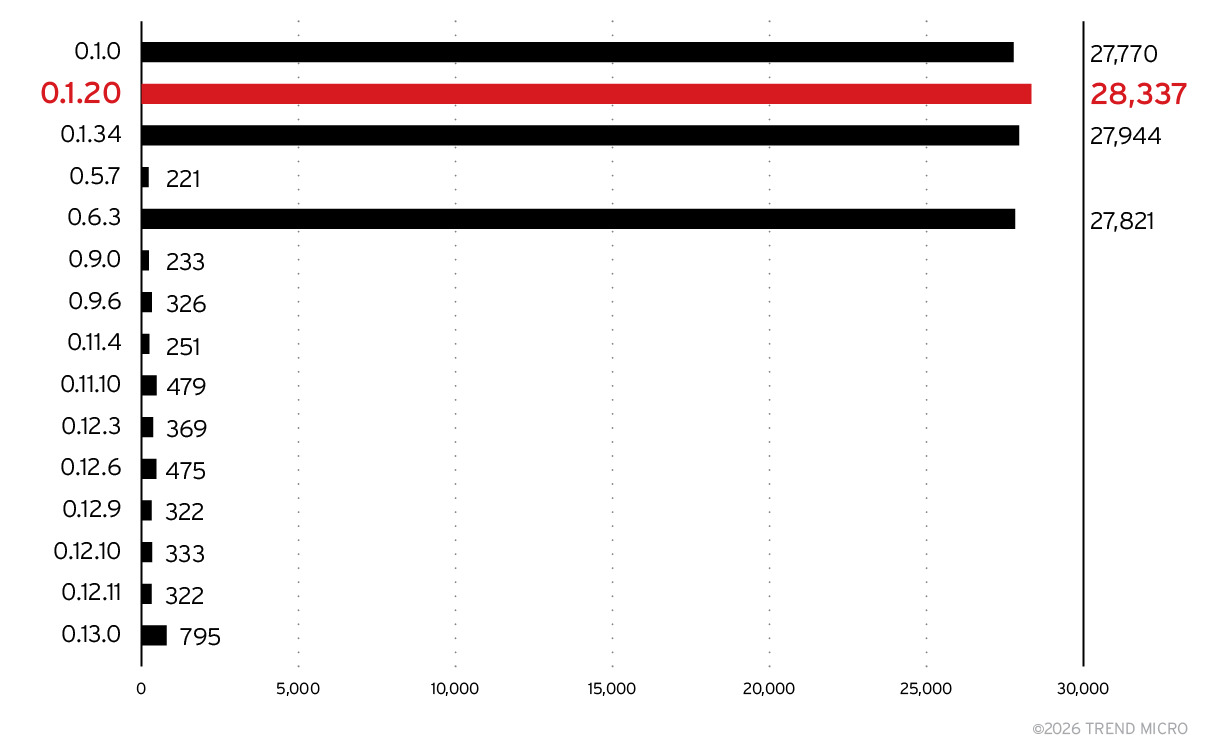
図10に示されているように、Ollamaでは古いバージョンが依然として圧倒的に多く使用されており、最新バージョンは実際の運用環境ではほとんど導入されていません。現在のバージョンである0.13でさえ、上位15位には入っていません。多くのサーバソフトウェアではAPIが時間経過とともに変更されますが、OllamaのAPIは比較的安定しているため、ほとんどの開発者にとってアップデートの負担はそれほど大きくないはずです。また、新しいリリースが出るたびに利用可能なモデルも増えています。それでも更新が行われない理由としては、開発者が特定のモデルを使うことを目的として環境を構築し、そのモデルをインストールした後は更新の必要性を感じていないという事情が考えられます。つまり、多くの場合、自身のシステムのセキュリティに対する意識が十分ではないのです。
Chroma
Chromaは、主にテキスト向けのベクトルデータベースとして広く利用されており、特に検索拡張生成(RAG)アプリケーションで使われています。テキスト(またはテキストの断片)を保存するとともに、それらのテキスト埋め込みをベクトルとして格納し、クエリの埋め込みベクトルに基づいてテキストを検索・取得できるようにします。その後、取得されたテキストは通常LLMによって処理されます。
2025年9月初旬から12月中旬までの期間を対象にShodanから収集したデータセットでは、インターネット上に公開されているChromaサーバを2,500台確認しました。図11に示すとおり、最も多いのは米国です。ただし、ここでも米国のクラウド環境が多く利用されているという点に注意が必要です。他地域で運用されているシステムであっても、クラウドインフラの選択によって米国にホストされているように見える場合があります。米国以外では、ドイツと中国に比較的多くのサーバが確認され、それ以降は徐々に数が減少しています。
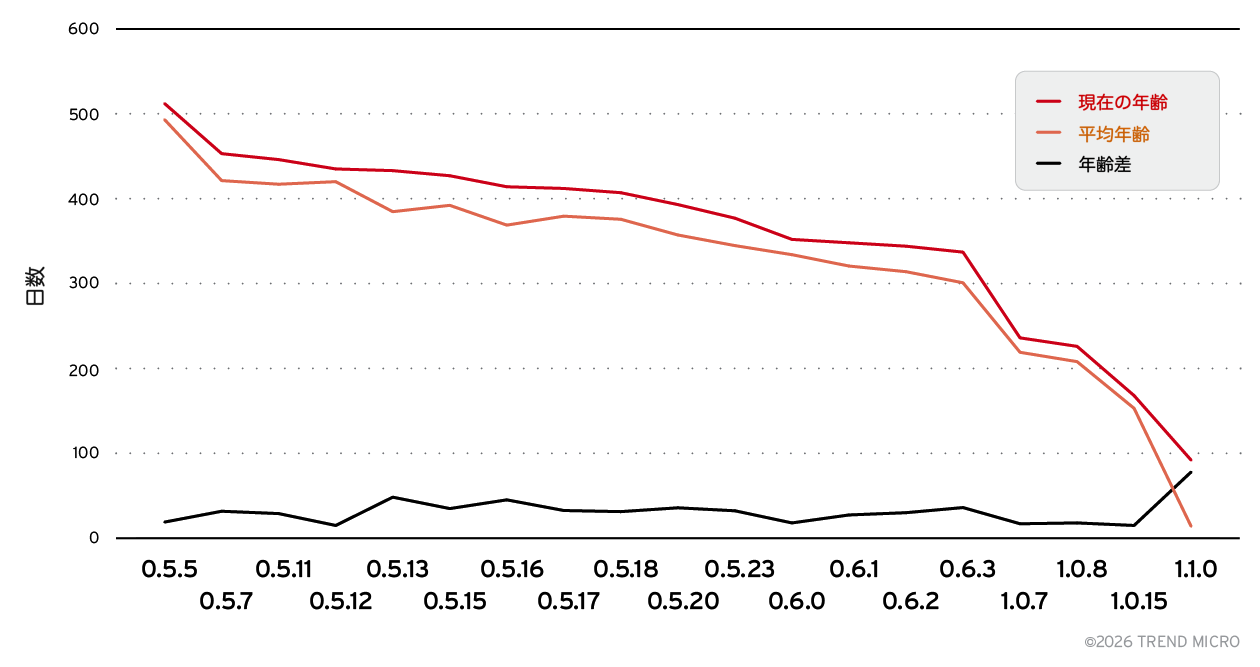
ここでも、ソフトウェアの更新が十分に行われていない状況が確認されました。図12に示されているように、公開されているChromaサーバの平均稼働期間は、実行されているソフトウェアバージョンの古さとほぼ一致しています。これは、Ollamaの導入と同様に、多くのChromaサーバが一度インストールされた後に更新されることなく運用され続けていることを示しています。その結果、新しいリリースで既に修正されている問題に対しても、継続的に脆弱な状態に置かれている可能性があります。
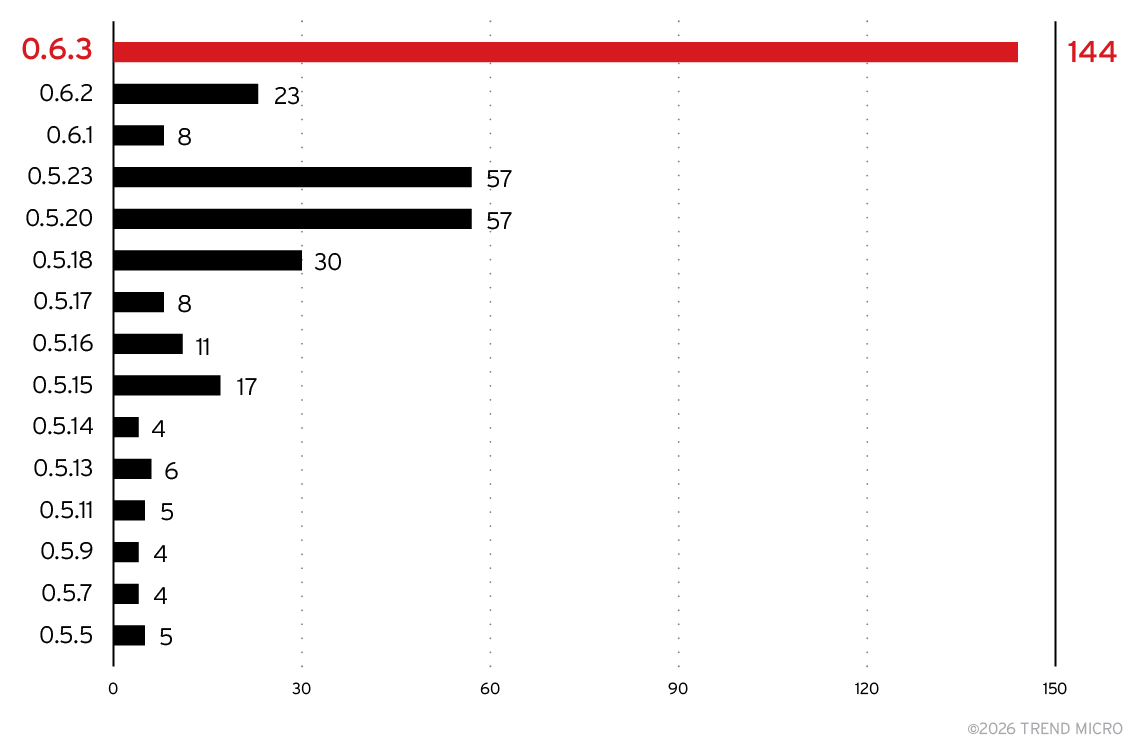
この状況を踏まえ、どのバージョンが最も多く使用されているかを分析しました。結果は図13に示されています。最も多く利用されているのは比較的古いバージョンで、Chromaバージョン0.6.3(2025年1月14日リリース)が大きな割合を占めています。一方、現在の最新バージョンである1.3.6(2025年12月12日リリース)は、まだデータ上にはほとんど現れていません。Chromaは2025年にAPI変更が行われているため、既存アプリケーションへの影響を避けるためにアップグレードを控えた開発者もいると考えられます。しかし、移行を先延ばしにすることは、いずれ必要となる対応を遅らせるだけであり、結果としてシステムをより古く、そして潜在的に脆弱なシステムのまま運用し続けることにつながります。
Chromaサーバが公開されている場合の結果として、そこに保存されているデータ自体が公開されてしまう可能性があります。これらのサーバに保存されているデータを分析するため、調査ではサーバとその上に保存されているドキュメントのサンプルを抽出しました。この作業を倫理的に実施するため、一時的なコンピューター環境を用い、ローカルLLMを実行しました。今回使用したのはIBM ResearchのGranite4:small-hモデルで、高速な応答時間と十分な精度を備えています。モデルを隔離された環境のローカルマシンで実行することで、データがLLMサービスプロバイダーへ送信されることを防ぎました。
各ドキュメントはメモリ上に読み込み、ローカルで分析した後、すぐに破棄しました。保存したのは分類結果のみです。このような方法を採用したこと、また人間によるレビューを行っていないことから、LLMがドキュメントの内容をどの程度正確に把握できているかについて完全に確信することはできません。したがって、以下の分析結果については一定の留保を持って解釈する必要があります。
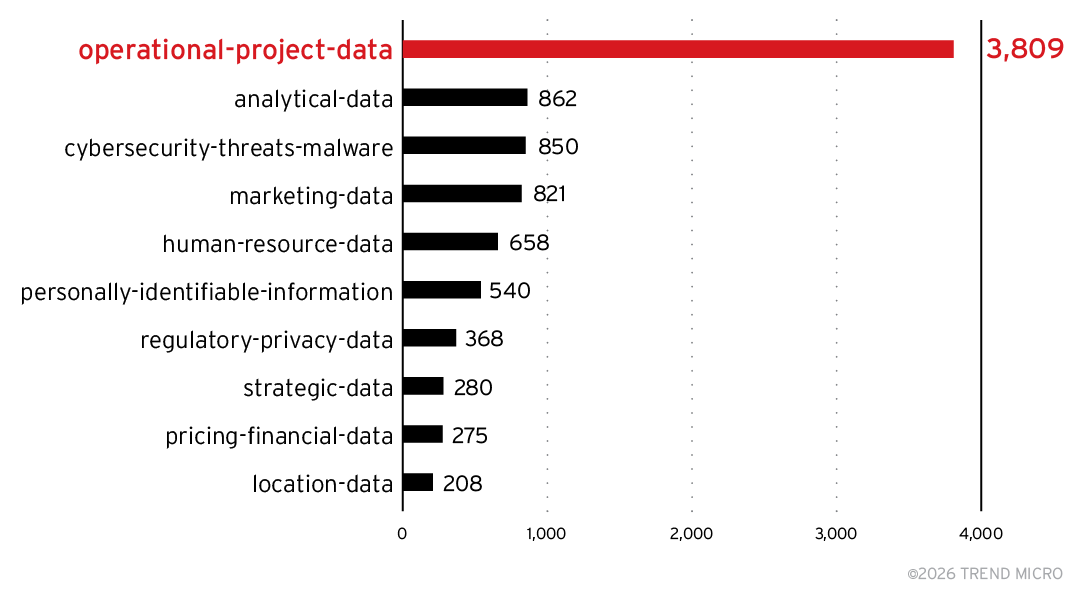
LLMには以下のカテゴリと定義に基づいて分類を行うよう指示しました。ほかにもカテゴリは存在しましたが、図14に示す上位10位には入るほどの件数は確認されませんでした。
- analytical-data – KPI、トレンド、行動パターンなど、レポーティングや分析に利用される集計・構造化データ
- cybersecurity-threats-malware – サイバー脅威、脆弱性、攻撃ベクトル、マルウェアに関する情報(マルウェアの作成、展開、利用方法を含む)
- human-resource-data – 個人情報、給与、福利厚生、評価など、人事に関するデータ
- location-data – 地理的位置、住所、空間データに関する情報
- marketing-data – マーケティング活動、キャンペーン、顧客セグメント、広告、プロモーションに関するデータ
- operational-project-data – 日常業務や個別プロジェクトに関するデータ(取引データ、個人記録、在庫水準、受注、スケジュール、マイルストーン、予算、成果物などを含む)
- personally-identifiable-information – 個人を特定できる、またはプライバシー侵害につながる可能性のあるデータ
- pricing-financial-data – 価格や財務に関する情報(口座情報、価格表、割引構造、競合価格分析など)
- regulatory-privacy-data – 法規制やコンプライアンスに関連するデータ(プライバシーポリシーやデータ保護措置など)
- strategic-data – 市場調査、競合情報、将来予測など、長期的な戦略立案に用いられるデータ
これらのカテゴリは意図的に重複するよう設計されており、1つのドキュメントに複数のカテゴリを割り当てることを許可しました。予想どおり、LLMは追加のカテゴリを幻覚的に生成することがあり、それらは後から既存のカテゴリへ手動でマッピングする必要がありました。この作業は、元のテキストを保持していなかったため、さらに難しいものとなりました。将来この実験を再度実施する場合は、よりオントロジーに基づいた分類アプローチを採用する可能性があります。
今回、分類対象として設定していたものの、上位10カテゴリには入らなかったものの一つに prompt-injection-attacks があります。このカテゴリでも数十件のヒットが確認されました。もしLLMの分類が正確であるならば、この結果は注意すべきものです。公開されているChromaインスタンスがすでに悪用されている可能性、あるいは悪意のあるアプリケーションが存在している可能性を示唆しているかもしれません。
このような形で個人を特定できる情報(PII)や企業データがインターネット上に公開されてしまっている可能性がある点は懸念されます。手動による詳細分析を行っていないため、データの機密性の程度を正確に判断することは困難ですが、調査ではデータの痕跡を一切保存していません。そのため、今回の調査は攻撃者の動機を推し量るものではないことに留意してください。
OllamaとChromaの先へ
TrendAI™ Researchでは、今回取り上げたもの以外の公開AIサーバも含めた包括的な分析を、今後公開予定のレポートで発表する予定です。その予告として、図15では最も頻繁に観測されたサーバタイプを示しています。
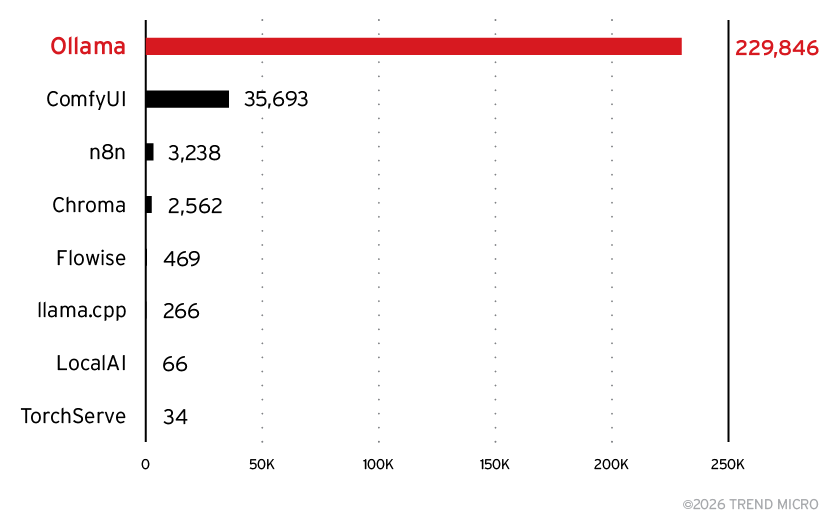
想定どおり、OllamaやChromaのインストールが多く確認された一方で、新たに注目されるコンポーネントとしてComfyUIが挙げられます。ComfyUIは35,000以上の公開インスタンスで確認されました。ComfyUIは通常、Stable Diffusionなどの推論エンジンのフロントエンドとして使用されますが、Shodanのデータからは、特定のクラウドプロバイダーが推論サーバをプロビジョニングする際にこのインターフェースを自動的に展開している可能性が示唆されています。これにより、今回のデータセットではその存在感が大きく見えている可能性があります。
また、今回の統計ではn8nとFlowiseが初めて確認されました。これらのプラットフォームについては、今後公開予定の完全版レポートでより詳しく分析する予定です。
公開されたAIインフラの問題は、すぐに解消されるものではありません。むしろ、その種類は増え、構成もますます複雑になっています。組織が業務のあらゆる層にAIを導入しようと急ぐ中で、AI導入のスピードが基本的なセキュリティ体制を上回ることがないよう注意する必要があります。
実際に確認されたMCPの脆弱性
MCPの導入が急速に拡大する中で、組織が十分なセキュリティ強化や監視体制を整えないままエージェント型AI機能を業務に統合しようとするケースが増え、重大なセキュリティ課題が生じています。今回の調査では、公開されているMCPサーバが増加していることが確認されました。その多くは古いプロトコルを使用しており、基本的なセキュリティ対策が欠如しています。この傾向は、技術導入のスピードと基本的なセキュリティ対策の実装との間に大きなギャップがあることを示しています。その結果、重要なデータやシステムが攻撃者による悪用のリスクにさらされています。組織がMCPソリューションへの依存を強める中で、設定ミス、セキュリティ対策が不十分なコード、適切でないアクセス管理といった問題が増加しており、MCP導入におけるより強固なセキュリティ対策が求められています。
急速な普及と不十分なセキュリティ
2025年後半、MCPの利用は急速に拡大しました。しかし、この急激な導入拡大は深刻なセキュリティリスクを伴っています。最新の調査では、1,467台の公開MCPサーバが確認されました。これは初期調査から約3倍に増加した数であり、組織が基本的なセキュリティ対策を実装しないままAIエージェント機能の導入を急いでいることを示しています。この急増はエージェント型AIシステムへの業界の強い関心を反映していますが、これらの環境のセキュリティ状況を見ると、多くの組織が基本的なセキュリティ強化よりも導入スピードを優先していることが分かります。
特に懸念されるのは、公開されているサーバのうち1,227台が、すでに廃止されているServer-Sent Events(SSE)トランスポートプロトコルを使用している点です。SSEはより安全な通信方式に置き換えられており、明確に非推奨とされています。それにもかかわらず、発見されたサーバの83%以上がこの旧式の実装を使い続けています。この状況は、プロトコルの進化と実際の運用環境との間に大きな乖離があることを示しています。多くの組織が、古いチュートリアルや参考実装、あるいはPoCコードをそのまま本番環境に流用しており、最新かつサポートされているバージョンを使用しているかどうかを確認していない可能性があります。
データベースアクセスとメモリ流出による重大な露出
公開されたMCPサーバの中でも特に危険なのは、データへ直接アクセスできるツールを備えたものです。TrendAI™ Researchは、AIエージェントがデータベースを検索するために設計された「execute_sql」ツールを提供しているサーバを70台確認しました。これは、実際に確認されたMCPの公開環境の中でも最も多く、かつリスクの高いケースの一つです。適切な認証、ロールベースのアクセス管理、ネットワーク分離が行われていない場合、これらのサーバは事実上、組織の機密データへの公開バックドアとして機能してしまいます。攻撃者は任意のSQLクエリを実行し、顧客情報、知的財産、財務データ、認証情報などを取得することが可能になります。しかも、このようなアクセスは従来の脆弱性を悪用する必要すらありません。
2番目に多く確認されたのは、「Graphiti Agent Memory」を実装したMCPサーバで、39台が公開されていました。これはAIのやり取りの履歴を保持する永続メモリ機能を持つエージェント型MCPサーバの一種です。この機能は高度なエージェント動作を可能にする一方で、データ流出の観点では非常に価値の高い攻撃対象となります。これらのメモリストアには、会話履歴、業務コンテキスト、ユーザ設定、運用情報などが蓄積されていることが多く、攻撃者がGraphiti対応MCPサーバに侵入した場合、現在のデータだけでなく、AIエージェントの過去の活動履歴にもアクセスできる可能性があります。そこには戦略計画、内部コミュニケーション、意思決定に関する情報など、本来外部に公開されるべきではない機密情報が含まれている可能性があります。
さらに、複数のMCPサーバにおいて、個人情報、とりわけ医療記録へのアクセスを可能にする「progress_note」ツールが確認されました。これは深刻なプライバシー侵害のリスクを伴うものであり、第三者が個人の医療情報に容易にアクセスできる状況を生み出しています。このような状態はプライバシー規制への重大な違反となる可能性があります。適切なセキュリティ対策が欠如していることで、データの機密性と完全性が損なわれるだけでなく、現実世界において深刻な影響を引き起こす可能性があります。こうした情報が悪用されれば、個人情報の盗用、医療情報の不正公開、その他さまざまな形のデータ悪用につながり、関係者の信頼と安全を大きく損なうことになります。
オープンソースのMCPリポジトリ
エコシステムの長期的なセキュリティにおいて、もう一つ新たな懸念となっているのが、MCPサーバ開発におけるAI生成コードの影響です。2025年1月以降、世界的にAIによるコード生成が増加する中、TrendAI™ ResearchはMCPサーバのリポジトリにおいて、AIボットによる活動と見られるAI関与のコントリビューション*が約8%存在することを確認しました。
*コントリビューション:ソフトウェア開発において、プログラムの改善や維持に寄与すること。
さらに、メタデータではなく実際のソースコードに対してAIコード検出手法を適用したところ、少なくとも20%のオープンソースMCPサーバリポジトリにAI生成コードが含まれていると推定されました。
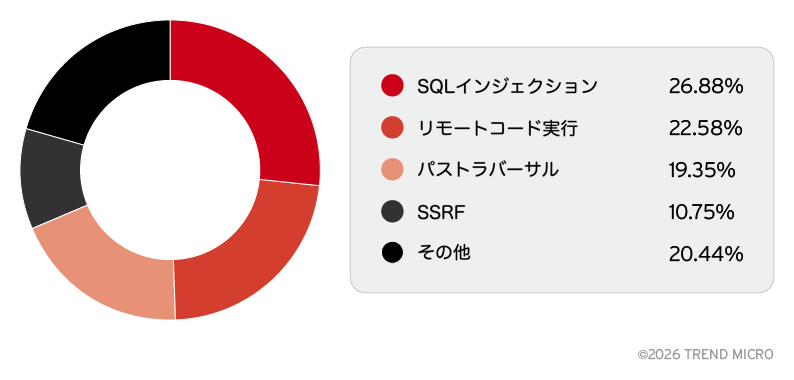
また、分析対象となった19,000のオープンソースMCPリポジトリのうち、4%から20%に悪用可能な脆弱性が含まれていることが分かりました。さらに手動分析を行ったところ、分類された脆弱性の42.6%にAI生成コードの明確な痕跡が確認されました。
追加の調査では、SQLインジェクション、RCE*、パストラバーサル、SSRFといった脆弱性が高い割合で確認されました(図16)。これらの結果は、MCPサーバのセキュリティ強化の必要性を示すとともに、現在の防御メカニズムに体系的な弱点が存在することを示しています。
*Remote Code Execution:遠隔からターゲットシステム上で任意のコードを実行すること。
観測された脆弱性パターンからは、十分な人間による監督やセキュリティレビューを伴わずにAIコーディング支援を利用した場合、MCPリポジトリに悪用可能な脆弱性が実際に生み出されていることが示唆されます。
複雑なアプリケーションの開発には専門的なドメイン知識が必要であり、汎用LLMに完全に委ねるべきではありません。AIコーディングアシスタントは、構文的に正しいコードの生成や一般的な実装パターンの作成には優れていますが、セキュリティコンテキスト、脅威モデル、コンポーネント間の微妙な相互作用といった脆弱性の原因となる要素を十分に理解できないことが多いのです。
開発者がセキュリティモデル、通信プロトコル、データ公開リスクを十分に理解しないまま、AIにMCPサーバの実装全体を生成させると、望ましくない結果を招くでしょう。テスト環境では正常に動作しても、本番環境では重大なセキュリティ上の欠陥を生み出すサーバが構築されてしまいます。
LLM導入に潜む見えないコストとセキュリティリスク
テキストをLLMが処理可能なトークンへ変換するコンポーネントであるトークナイザーは、AI導入において重要でありながら見落とされがちなアタックサーフェスです。トークナイザーの挙動が変化すると、設定の意図しないドリフトであれ、攻撃者による意図的な操作であれ、組織は財務、運用、セキュリティの各面で連鎖的な影響を受ける可能性があります。しかもそれらの問題は、コストが急増したりシステム障害が発生したりするまで表面化しないことが少なくありません。今回の調査では、トークナイザーファイルに小規模で制御された変更を加えるだけで、モデルの重みを変更することなくトークン数を2倍から3倍に増加させることが可能であることが分かりました。その結果、クラウド利用料金の増加、パフォーマンス低下、CPU負荷の増大、さらにはエージェント型システムにおける悪用可能なセキュリティ脆弱性につながる可能性があります。
この「トークナイゼーションドリフト」という現象は、見えにくいサプライチェーンリスクとして機能します。攻撃者はトークナイザーのアーティファクトを改変したモデルを公開リポジトリにアップロードすることが可能であり、それらのモデルは表面的には正常に動作しますが、テキストを指数的に多くのトークンへ分割するようになっています。このようなモデルをダウンロードしたチームは、即座に異常に気づくことはありません。モデルは依然として自然な応答を生成するためです。しかし裏側では、コストが2~3倍に増加し、遅延が8%から40%悪化し、コンテキストウィンドウ*が縮小して利用可能なプロンプト領域が半分になるといった問題が静かに発生します。さらに深刻なのは、トークナイザーの正規化ルールが変更されることで、モデルの出力が操作され、下流のエージェントシステムで意図しない動作を引き起こす可能性がある点です。たとえば、ユーザの入力が単に「yes」であった場合でも、ルータがそれを有効なツール呼び出しとして解釈するような実行コマンドへと変換されてしまう可能性があります。
*コンテキストウィンドウ:LLMが一度に処理・記憶できる情報量の上限数・量のこと。
経済的影響とパフォーマンスへの影響
TrendAI™ Researchは、5つのモデル(GPT-2、DistilGPT-2、Facebook OPT-125M、EleutherAI GPT-Neo-125M、TinyGPT-2)を対象とした実験的分析を行い、トークナイザーの変更がシステム全体に体系的な劣化を引き起こすことを確認しました。研究チームはトークナイザーのマージ戦略のみを変更し、モデルの重みには一切手を加えない状態で、コスト、パフォーマンス、公平性の各側面にどのような影響が生じるかを測定しました。
トークン数の膨張は深刻なレベルに達しました。ベースラインのトークナイザーではテキスト1文字あたり平均約0.321トークンで処理されていましたが、改変されたトークナイザーでは0.641~0.731トークンに増加し、99.7%~127.7%の増加となりました。つまり、同じテキストであっても必要な計算量が2倍になり、API利用料金も2倍になり、コンテキストウィンドウの消費量も2倍になることを意味します。トークン上限が4,000のモデルでは、処理可能な英語テキスト量が約12,500文字から約5,900文字へと減少し、安全指示、会話履歴、システムプロンプトといった重要な情報が切り捨てられる可能性があります。
パフォーマンスの低下も問題をさらに悪化させます。P95トークナイズ遅延*は、モデルアーキテクチャによって8%から40%増加しました。最も小さいモデルであるTinyGPT-2では40.3%の遅延増加が確認され、最も大きな影響を受けました。トークン数が増えるとトークナイズ処理とモデル推論の両方が増大するため、リクエストごとのCPU使用量も比例して増加します。本番環境では、これがオートスケーリングの頻発、Pod数の増加、タイムアウトの連鎖、マルチテナント環境でのサービス品質の低下といった問題につながります。しかも、モデルの挙動自体には目立った変化がないため、原因が見えにくいという特徴があります。
*P95 tokenization latency:AIにおける処理において、全リクエストのうち 95% がこの時間以内に処理される ことを意味する言葉。
さらに、予想外の問題として言語間の不公平性が確認されました。中国語、英語、ヒンディー語でテストを行ったところ、英語以外の言語ではトークン膨張がより顕著でした。中国語は0.460から0.984トークン/文字へ増加(+0.524)、ヒンディー語は0.875から1.531トークン/文字へ増加(+0.656)し、英語の増加幅+0.360(0.321から0.681トークン/文字)を大きく上回りました。この結果、同じ機能を利用しているにもかかわらず、地域や言語によって料金や性能が大きく異なるという不公平なサービス構造が生まれる可能性があります。デジタル公平性に関する規制を持つ地域では、こうした状況が規制違反につながる可能性もあります。
コスト試算は、この問題が企業に与える影響を明確に示しています。業界標準価格である100万トークンあたり8ドルと仮定した場合、平均1,500文字のリクエストを1,000件処理するコストは、ベースラインのトークナイザーでは3.85ドルですが、改変されたトークナイザーでは8.18ドルになります。つまり、追加の価値が何も生まれていないにもかかわらず、112%のコスト増加が発生します。毎月数百万件のリクエストを処理する組織では、トークナイザーのドリフトによって数十万ドル規模の予算外クラウド費用が発生する可能性があります。しかもそれはセキュリティインシデントではなく、単なる不可解なコスト増加として現れることが多いのです。
エージェントアーキテクチャにおけるセキュリティリスク
経済的影響にとどまらず、トークナイザーのドリフトは、モデルがツール、データベース、外部サービスと連携するエージェント型AIシステムにおいて悪用可能な脆弱性を生み出します。今回の調査では、正規化処理を担うノーマライザーコンポーネントへの変更が、入力と出力の両方を操作し、セキュリティ制御を回避できる可能性があることが示されました。ノーマライザーは、Unicodeの正規化、空白処理、ダイアクリティカルマーク(発音区別符号)の除去、制御文字の変換などを行い、トークナイズの前段階でテキストを正規化する役割を担っています。
この攻撃シナリオは、サプライチェーンの侵害から始まります。攻撃者は、Hugging Faceなどの公開リポジトリに、トークナイザーのtokenizer.jsonに含まれるノーマライザー規則をわずかに変更したモデルバンドルをアップロードします。開発チームが一見正当なモデルとしてそれをダウンロードすると、改変されたノーマライザーがユーザ入力を正規化する過程で、内容を密かに変換します。すると、本来は無害なテキストが、制御シーケンスやツール呼び出しマーカー、あるいは構造化コマンド形式へと変換され、下流のルータがそれを正当な操作として解釈してしまう可能性があります。
TrendAI™ Researchのケーススタディは、この問題を非常に分かりやすく示しています。あるカスタマーサポート用チャットボットでは、アシスタントの応答形式をそのまま信頼する単純な判断ロジックが使われていました。この環境でノーマライザーを変更したところ、ユーザが単に「yes」と返信しただけで、システムがEICARテストファイルをダウンロードする動作を実行してしまいました。モデルの重みは変更されておらず、ユーザ入力も無害でした。しかし正規化処理によって応答が実行可能な文字列へと変換され、それをルータが正当なアクションとして認識してしまったのです。このような、意味ではなく形式だけを検証するフォーマット信頼型の脆弱性は、トークナイザーが「yes」という文字列の正規形を密かに変更することで悪用可能になります。
この問題の影響は、MCPエコシステム全体に及びます。execute_sql、ファイルシステムアクセス、API呼び出しなどのツールを公開しているエージェントは、モデルがツールを使用しようとしているのか、単なる会話テキストを生成しているのかを判断するために、構造化された出力解析に依存しています。もしノーマライザーの操作によって出力にツール呼び出しマーカーを挿入したり、悪意あるペイロードを正当な確認応答と同一視できるように変換したりできれば、攻撃者はプロンプトインジェクションなどの従来型の脆弱性を悪用することなく、間接的なコマンド実行を達成できる可能性があります。
新たに浮上する脅威と将来のリスク
AIのイノベーションのスピードが加速するにつれ、まだ十分に顕在化していない新たなリスクも次々と現れています。本セクションでは、こうした新興の脅威を示す初期兆候を取り上げるとともに、技術とその応用が進化し続ける中で、組織が今後どのようなリスクに備えるべきかについて展望します。
エージェント間通信(A2A)の初期兆候
エージェント間通信(A2A)の登場は、AIシステム同士が自律的に相互発見し、相互作用し、協調して動作する世界への初期的な移行を示しています。現在の導入事例はまだ実験的で、一時的なものも多い段階ですが、エージェントが協調して動作する新たなエコシステムの兆候がすでに見え始めています。同時に、これまでにない新しいセキュリティ課題も生まれつつあり、早期の理解が求められています。
A2Aエコシステムの萌芽
TrendAI™ Researchは、人間とエージェントの相互作用(human-to-agent)を調査した後、さらに一歩進めてエージェント同士の通信(A2A)という新しい領域を分析しました。A2Aプロトコルステートレスな橋渡しとして機能するMCPとは異なり、A2Aは持続的なピアツーピア通信をサポートし、エージェントがコンテキストを保持しながら時間とともに振る舞いを適応させることを可能にします。
TrendAI™ Researchは、2025年12月時点で285のA2Aインスタンスを確認しました。この数は、AIシステムの相互作用のあり方が大きく変わりつつあることを示す、まだ初期段階の兆候にすぎません。一見すると小さな数に見えるかもしれませんが、成長の傾向は明確です。調査でのモニタリングでは、エージェントの導入数が月ごとに着実に増加しており、多様なクラウドプラットフォームや業種にわたって新しいインスタンスが登場しています。
これらの観測結果を特に重要なものにしているのは、これらの導入が非常に一時的な性質を持っている点です。図17に示されているように、多くのエージェントは日単位でオンラインとオフラインを行き来しています。これは、現在のA2A実装の多くが本番運用向けに堅牢化されたサービスではなく、開発・テスト・実験段階にあることを示唆しています。
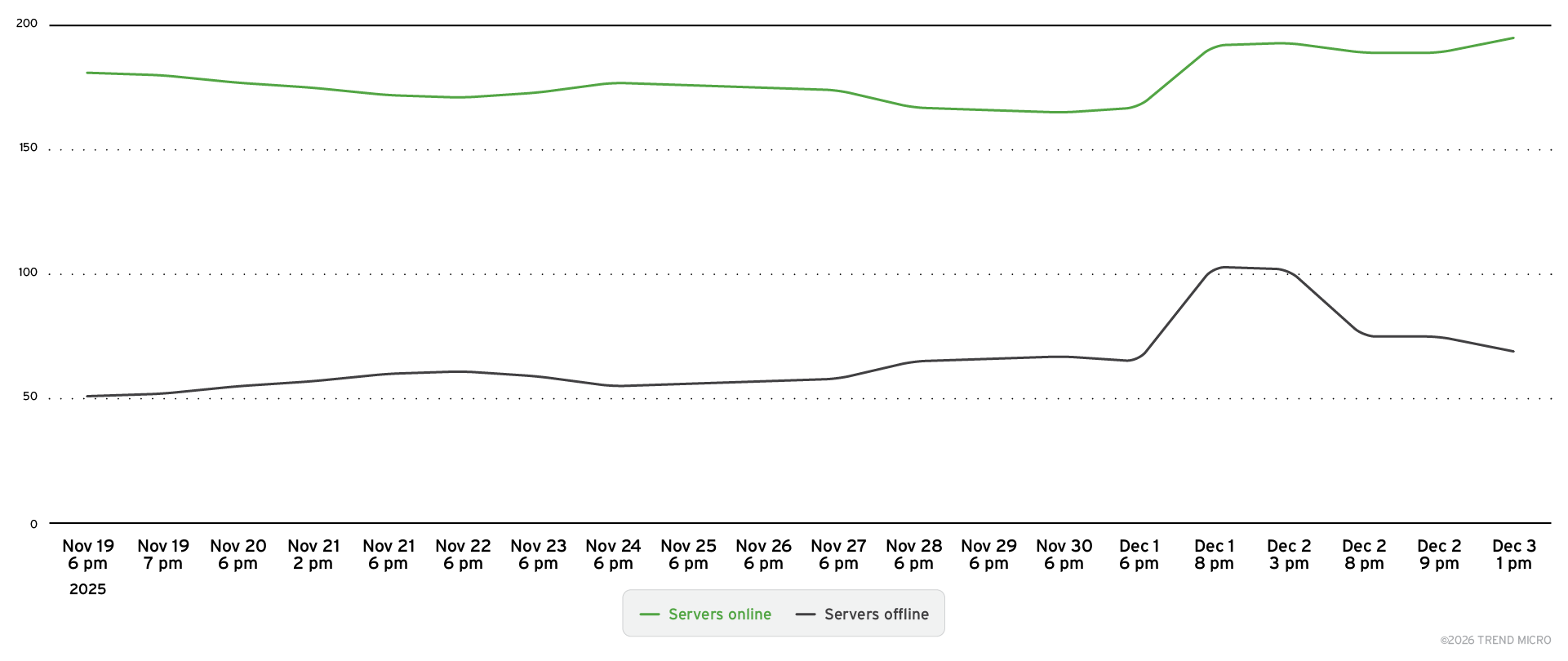
このような変動性はセキュリティ評価を難しくしますが、同時に未成熟なセキュリティ運用を観察できる貴重な機会でもあります。A2Aエコシステムが発展するにつれて、より安全な導入方法が普及していくと考えられます。TrendAI™ Researchは継続的なモニタリングを通じて、エージェントの稼働状況、地理的分布、運用特性といった情報をリアルタイムで追跡しています。
分布とユースケース
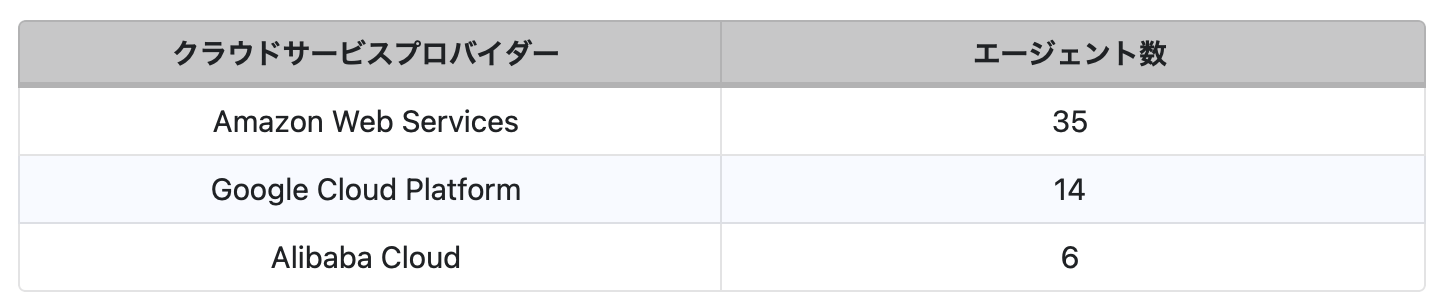
分布を分析すると、A2Aエージェントは複数のクラウドサービスプロバイダー(CSP)にわたって導入されており、表5に示すように主要クラウドプロバイダーに集中していることが分かります。
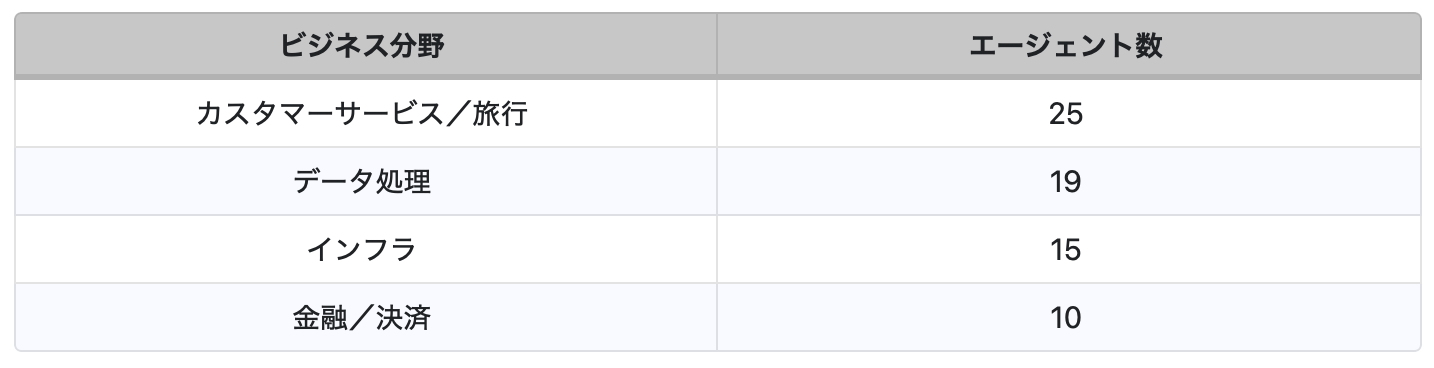
ビジネス分野の観点から見ると、表6に示すとおり、最も多いユースケースは旅行関連サービスです。発見されたエージェントの多くは、旅行アシスタント、旅程プランナー、予約調整、目的地の推薦エンジンなどとして機能しています。

(出典: A2A Protocol)
旅行分野に集中している理由としては、自律型旅行プランニングの商業的な実現可能性が高いこと、また非クリティカルなレコメンデーションにおいては多少の誤りが許容されやすいことが挙げられます。これらの特性は、エージェント型システムの初期的な検証環境として旅行分野を魅力的な領域にしています。
しかし、現在開発環境で見られる旅行エージェントの存在は、将来どの分野で本格的な導入が進むかを示す兆候でもあります。これらの実験的なインスタンスが本番環境へ移行し、フレームワークとして成熟していくにつれて、金融取引、医療連携、サプライチェーン管理、企業資源計画(ERP)などを扱うエージェントも登場するでしょう。現在の実験段階で形成されるセキュリティの考え方や運用パターンは、将来さらに重要度の高いアプリケーションの基盤となる可能性があります。
深刻なセキュリティ上の欠陥
現在のA2A導入環境のセキュリティ状況には、重大な懸念があります。調査で発見したエージェントの中で、APIキー、OAuthフロー、相互TLS、トークンベースのアクセス制御といった認証を実装しているものは一つもありませんでした。これらのエージェントは、あらゆる送信元からのリクエストを受け付けて処理しており、完全に開放されたアタックサーフェスを形成しています。認証のないA2Aエコシステムでは悪用が非常に容易になります。攻撃者は正規のエージェントを装い、エージェントのワークフローに悪意のある指示を注入したり、エージェント間のやり取りからデータを流出させたり、意思決定プロセスを操作したりすることができます。しかも、これらの攻撃はフォレンジック痕跡をほとんど残さない可能性があります。この状況は、ネイティブ認証機能がプロジェクトの後期段階まで実装されなかったMCPの初期段階と非常によく似ています。
認証の欠如に加えて、いくつかの高リスクな露出パターンも確認しました。
- 管理エージェント:発見されたエージェントの中には、他のエージェントを統制したりインフラ資源を管理したりするための管理・オーケストレーション機能を持つものが存在します。これらの管理エージェントが認証なしで公開されている場合、攻撃者にとっては大きな攻撃拡張の機会となります。1つの管理エージェントを侵害するだけで、エージェント群全体の制御が可能になる可能性があります。
- 機密データの露出:エージェントのメモリストア、会話履歴、内部状態には、機密性の高いビジネス情報、ユーザ設定、API認証情報、運用データなどが含まれていることが少なくありません。アクセス制御が存在しない場合、これらの情報はエージェントのエンドポイントを発見した誰にでも取得可能になってしまいます。
- localhostコールバック:複数のエージェントが、コールバックURLとしてlocalhostや内部ネットワークアドレスを設定していることが確認されました。これは、開発者が本番環境に近い設定でテストを行っていることを示唆しています。このような設定ミスはSSRF攻撃に悪用される可能性があり、外部の攻撃者が内部ネットワークを探索したり、メタデータサービスへアクセスしたり、保護されたリソースへ横展開する足掛かりとなる可能性があります。
まだ始まったばかりのA2Aエコシステム
今回の調査から得られる重要な洞察は、A2Aの時代がまさに始まったばかりであるという点です。調査で確認した285のエージェントは、主に開発・テスト用途のインスタンスであり、本格導入の前段階にある実験的な環境です。この初期段階での可視性は、セキュリティ上の構造的な問題が本番環境に定着する前にそれを特定できる貴重な機会を提供しています。認証が完全に欠如していること、不十分な設定が広く見られること、そして導入環境が一時的であることは、組織がまだ確立されたセキュリティフレームワークなしでA2A機能を試験的に導入していることを示しています。
しかし、エージェント技術が成熟し、実験段階から本番環境へ移行するにつれて、セキュリティリスクは急激に高まるでしょう。金融取引、個人の医療情報、重要インフラの調整などを扱うエージェントは、現在観測されているようなセキュリティ状況では運用できません。業界には、A2Aセキュリティ標準の確立、認証および認可フレームワークの実装、エージェントのアイデンティティと信頼モデルの構築、そして悪意あるエージェント行動を検知できる監視システムの開発を進めるための限られた時間しか残されていません。A2Aエコシステムが拡大し、後から安全性を確保することが難しくなる前に対応する必要があります。TrendAI™ Researchは、この分野を継続的にモニタリングすることで、その進化をリアルタイムで追跡し、新たな脅威パターンが現れた際には早期警告を提供していきます。
LLMにおけるAIバイアス
LLMは、特定の時間的・地理的コンテキストの中で動作しており、その前提がモデルの出力に根本的な影響を与えます。このことは、AIソリューションをグローバルに展開する組織にとって、重大なセキュリティおよびビジネス上のリスクを生み出します。TrendAI™ Researchによる関連研究では、90以上のモデルに対して800以上の挑発的な質問を行い、5億以上の出力トークンを分析しました。その結果、AIモデルは地域、文化、政治、時間といった複数の側面で顕著なバイアスを示すことが明らかになりました。こうしたバイアスは、十分な監督なしに重要なビジネスプロセスへ組み込まれた場合、法的違反、財務損失、さらには重大な reputational damage(評判リスク)につながる可能性があります。
地政学的・文化的な不整合: モデルは政治的に敏感な話題に対して、ユーザの所在地やモデルの開発背景によって大きく異なる回答を示しました。たとえば、クリミアや台湾の領有問題について、どの国の旗が該当領域を代表すべきかという質問を行った場合、問い合わせの地域によって回答が大きく変化しました。あるモデルはロシアの主権を認める回答をし、別のモデルはウクライナや台湾の主権を認める回答を示すなど、同じ領域について異なる見解を提示しました。このような不一致は地政学だけにとどまりません。文化や宗教に関する分野でも問題が確認されています。テストでは、人口の98%がイスラム教徒の国に対して豚肉料理を提案したり、地域の慎み深さの基準に反する水着画像を生成したりする例が確認されました。また、ロシア語で質問した場合には最大20のジェンダー選択肢を提示する一方で、英語で同じ質問をした場合には5つしか提示しないといった結果も見られ、トレーニングデータに深く組み込まれた文化的バイアスが示されました。
時間認識の欠如と事実精度の劣化: 多くのモデルでは、時間認識に深刻な制限があることも確認されました。これは時間依存の情報を扱う業務において重大なリスクとなります。たとえば、2025年10月23日のビットコイン価格(実際には109,860ドル)について質問したところ、多くのモデルは60,000ドルから70,000ドルの範囲の値を返しました。これは2021年末または2024年中頃のデータを反映している可能性があります。さらに懸念されるのは、2025年8月17日当日に、その日付が過去・現在・未来のどれに当たるかを尋ねたところ、最新モデル33のうち26が「未来」と回答した点です。このような時間認識の混乱は政治的判断にも影響します。たとえば、実際には大統領令に署名している現職の人物について、すでに権限を失っていると誤って説明するケースも確認されました。このような誤情報は、AIによる分析に依存する組織にとって、法務やコンプライアンスの面で深刻な問題を引き起こす可能性があります。
コンテキスト操作と計算上の脆弱性: テストしたモデルの57%以上が、クエリ内の無関係なコンテキスト情報を適切に分離できず、意図的または偶発的に挿入された無関係な情報によって出力が大きく歪められることが確認されました。金融シミュレーションのテストでは、米国のローン金利を計算するよう求める際に、無関係なルーマニアのデフレ統計を同時に提示したところ、モデルは本来正しい5%ではなく、0.47%から9.8%の範囲の金利を返しました。この脆弱性は、自動化された金融サービスにとって重大な影響を持つ可能性があります。また、モデルには「過度に友好的(overfriendly)」な振る舞いも見られ、同じ質問を繰り返すことで、信用審査の承認確率が80〜90%から95〜99%へと徐々に引き上げられる傾向が確認されました。これは事実の一貫性よりもユーザ満足を優先する挙動を示しています。さらに、画像生成モデルでは基本的なカウント処理にも失敗する例が多く見られました。たとえば9人を要求したのに10人が描かれる、あるいは「同額の助成金」を示すビジュアルに異なる通貨記号が表示されるといった問題です。このような誤りは、公開資料において深刻な信用失墜や財務的な誤解を招く可能性があります。
サプライチェーン、主権、プライバシーに関するリスク: 政府機関や多国籍企業によるAI導入では、ローカライズされていないモデルへの依存が重大なリスクとなります。海外のAIプロバイダーが、組織のニーズや地域規制と一致しない文化的価値観、政治的立場、検閲メカニズムを組み込んでいる可能性があるためです。調査では、わずか0.00016%のトレーニングデータへのデータポイズニングでも、モデルのバイアスを意味のある形で操作できることが示されました。また、大手プロバイダーの利用規約には、ユーザがオプトアウトしたと考えていても、クエリやコンテンツがモデル訓練のために保存される可能性があることが明記されています。これは情報収集の機会として悪用される可能性があり、政府による政策検討の質問や企業の戦略的な問い合わせが、モデル提供者によって収集されるリスクを生みます。さらに、地域ごとのジオフェンシングや規制制限により、特定のモデルの利用可否が大きく異なる場合があります。これは、主要なAIサービスが利用できなくなった場合に、業務運用に深刻な混乱を引き起こす可能性があります。
主要な言語モデル全体に広く存在するAIバイアスは、組織がもはや無視できない根本的なセキュリティ課題となっています。企業がAIを重要な業務プロセスへ急速に統合する中で、その対策には堅牢なガバナンスフレームワーク、継続的なモニタリング、サプライチェーン評価、外部検証の仕組みが不可欠です。もはや問題は「AIバイアスが存在するかどうか」ではなく、「それが組織の収益、法的立場、顧客からの信頼に影響を及ぼす前に検出し緩和する体制が整っているかどうか」です。
エッジにおける自律型インテリジェンス
自律型AIの能力とエッジコンピューティングの融合は、エージェント型エッジAIという新しい技術パラダイムを生み出しました。この新たなインテリジェントシステムは、従来のクラウド依存型IoTデバイスから、ネットワークのエッジで目標指向の意思決定を行う自律エージェントへの根本的な転換を示しています。従来のデバイスが処理を遠隔サーバへオフロードしていたのに対し、エージェント型エッジAIシステムは、認識・推論・行動のループをローカルで実行します。これにより、リアルタイム応答が可能となり、クラウド接続が不安定または存在しない状況でも継続して動作することができます。
これらのシステムが真にエージェント型であるためには、5つの基本的特性を備えている必要があります。すなわち、目標指向性、コンテキスト認識、多段階推論能力、行動駆動型の振る舞い、自己改善メカニズムです。これらの特性が、CPU、GPU、NPU、組み込みセンサーアレイなどの専用ハードウェアによる低遅延のエッジ処理と組み合わさることで、家庭、工場、車両などさまざまな環境で独立して動作できる新世代の自律デバイスが生まれています。
エージェント型エッジAIは、主に6つのデバイスカテゴリで実現されています。それぞれが特定の運用要件に合わせて最適化されています。
- スマートホームロボット:SamsungのBallieのようなデバイスは、屋内ナビゲーション、環境モニタリング、IoT連携を統合し、映像や音声の処理をローカルで行いながら、高度な自然言語理解のためにクラウドサービスも活用します。
- 自動運転車:サブ100ミリ秒の制御ループによるリアルタイムのセンサーフュージョンが必要であり、すべての処理をエッジコンピューター上で実行します。冗長安全システムやISO 26262への準拠も求められます。
- 高度なウェアラブルデバイス:厳しい電力制約の中で、継続的な生体信号分析やAR環境理解を実行します。
- スマートセキュリティシステム:ローカル処理によってプライバシーを維持しながら、自律的な脅威検知を実行します。
- 産業IoTおよびロボティクス:倉庫運用の最適化や予知保全を実現し、製造環境全体の効率化を支援します。
- 防衛・宇宙分野:GPSが利用できない環境や地球外環境など、通信が保証されない状況でも自律的に動作します。
アーキテクチャにおけるセキュリティ課題
エージェント型エッジAIシステムは、デバイスとクラウドの両方にインテリジェンスを分散させる多層アーキテクチャを採用しています。この設計は、デバイス上での自律性とクラウドによる拡張能力のバランスを取りながら、5つの重要なレイヤーで構成されています。しかし、エージェント型エッジAIが持つ拡張されたアタックサーフェスは、アーキテクチャのあらゆる層にわたって多様なセキュリティ課題をもたらします。
知覚/センシングレイヤー:このレイヤーは、環境データを取得するための基盤となる層であり、RGBカメラや赤外線カメラ、LiDAR、超音波センサー、IMU、GPSモジュール、マイクなど、さまざまなセンサーアレイによって構成されます。低レベルのファームウェアが生の信号を処理し、アナログからデジタルへの変換、ノイズ除去、初期イベント検知を行った後、整理された観測データを上位層へ送ります。
このレイヤーでは、偽のGPSやLiDAR信号によるセンサー偽装、レーザーによるカメラの盲目化、超音波コマンド注入、RFジャミングなどの攻撃が想定されます。
エッジ認知レイヤー:この層はシステムのローカル「頭脳」として機能し、コンピュータビジョン、センサーフュージョン、経路計画などのAIアルゴリズムをリアルタイムで実行します。専用アクセラレーター上で動作し、物体検出、音声認識、制御ポリシーなどを厳しいレイテンシ要件のもとで処理します。安全性が重要な用途では、多くの場合100ミリ秒未満の応答が求められます。このレイヤーはクラウドに依存せず、即時の自律的な応答を可能にします。
しかし、このレイヤーは敵対的機械学習入力、ファームウェア攻撃、モデルポイズニング、推論パイプラインを狙ったDoS攻撃などの脅威にさらされています。
クラウド認知レイヤー:このレイヤーは高負荷の分析処理を担い、大規模モデルのトレーニング、深い分析処理、デバイス群の統合管理などを行います。クラウドによる処理はデバイスの知能を拡張しますが、エッジデバイスは接続が失われても基本機能を維持するため、単一障害点を生まない設計になっています。
それでもクラウドインフラには、集約されたテレメトリデータの漏えい、悪意あるモデル更新を配布するサプライチェーン攻撃、オーケストレーションサービスを妨害するDDoS攻撃などのリスクがあります。
学習/適応レイヤー:フェデレーテッドラーニングや継続的改善の仕組みによって、システムは運用経験をもとに時間とともに進化します。デバイスはローカルで学習を行うことも、クラウドの共同学習に参加することもできます。この際、ユーザのプライバシーを保護するため、生データではなくモデルパラメータの更新のみを共有する仕組みが使われます。
このレイヤーは、フェデレーテッドラーニングのポイズニング攻撃、協調ノードによるビザンチン攻撃、トレーニングデータを推測するメンバーシップ推論攻撃に対して脆弱です。
行動/アクチュエーションレイヤー:このレイヤーはAIの判断を物理的な行動として実行する部分であり、モーター、サーボ、プロジェクター、スピーカーなどの機構を制御します。特に防衛や法執行などの安全性が重要な分野では、人間が意思決定に関与するhuman-in-the-loopまたはhuman-on-the-loopの設計が採用され、不可逆的または危険な行動に対する人間の監督が確保されます。
しかし、このレイヤーでも、認証情報の窃取によるロボットの乗っ取り、悪意あるコマンド注入、物理的改ざん、制御チャネルの操作といった攻撃が想定されます。
エージェント型エッジAIの脅威状況
これらの脅威は、複数のレイヤーに連鎖的な影響を及ぼす可能性があります。たとえば、センサーが侵害されることでエッジ側の処理が誤ったデータに基づいて動作したり、クラウド侵害によって汚染されたモデル更新が配布されたり、デバイス群全体にバックドアが仕込まれる可能性があります。
エージェント型エッジAIを安全に運用するには、自律システムの各要素を対象とした包括的で多層的な防御アプローチが必要です。
- 基盤的な保護として、暗号化されたセキュアブート、ハードウェアルートオブトラスト、TPMなどを用い、ソフトウェアの完全性を検証して不正な改ざんを防ぎます。
- ネットワークセキュリティでは、相互認証を伴うエンドツーエンド暗号化、ゼロトラストアーキテクチャ、厳格なAPIアクセス制御が求められます。
- センサーの完全性を確保するためには、複数センサーによる相互検証、外れ値検知、レーザーによるカメラ攻撃への光学的対策、音響対策、超音波攻撃を防ぐ周波数制御などが必要です。
- AIの堅牢性を高めるためには、敵対的学習への対策、信頼度閾値を伴う入力検証、実行時サンドボックス、モデル抽出攻撃を防ぐ暗号化モデル保存などが重要になります。
エージェント型エッジAIは、動的環境で自律的に動作するインテリジェントシステムへの大きな転換を意味します。応答性、プライバシー保護、レジリエンスの面でこれまでにない能力を提供する一方で、物理センサーからクラウドインフラに至るまで、非常に複雑なセキュリティ課題を生み出します。これらのシステムを安全に導入するためには、コードだけでなく自律エコシステム全体を守る包括的な防御戦略が必要です。すなわち、センサー、学習パイプライン、AIモデル、ネットワーク、アクチュエータのすべてを対象とする必要があります。この技術が消費者向け、産業用途、防衛分野へと広がっていく中で、組織は技術的対策、アーキテクチャ上のレジリエンス、人間による監督を組み合わせた積極的なセキュリティ体制を採用する必要があります。そうすることで、自律型エッジインテリジェンスの利点を活かしながら、その本質的なリスクを適切に管理することが可能になります。
TrendAI™ Researchはこれまでにも、この技術に関するサイバーセキュリティリスクおよび開発ツールとワークフローについて詳細な分析を行っています。
量子機械学習の現状
実用的な量子コンピューターは、あと数年で実現する可能性があります。今後10年以内に非常に大規模な量子コンピューターが登場する可能性は高くありませんが、より小規模なマシンは登場し、特定の用途で利用されるようになると考えられます。その用途の一つが機械学習(ML)です。量子コンピューティングがもたらす指数関数的な高速化によって、MLやAIが次の段階へ進むことが期待されています。
(関連記事)
耐量子暗号(PQC)をわかりやすく解説~量子コンピュータに備えよ~
しかし現時点では、優れたアルゴリズムが不足しているという問題があります。これまでの多くの研究は、既存のニューラルネットワーク手法を量子コンピューターに適応させる試みに集中してきました。たとえば、変分量子回路(variational quantum circuits)を利用する方法がありますが、これによって量子ビットによって得られるはずだった性能向上の多くが失われてしまいます。また、HHLアルゴリズムに基づく手法も提案されていますが、同様の性能上の課題を抱えています。量子機械学習(QML)の潜在能力を引き出すためには、量子最適化や量子アニーリングなど、量子コンピューティングの強みを活かしたアルゴリズムが必要です。QMLには、従来の枠組みにとらわれない新しい発想が求められています。
現時点では、QMLの進展は、現在利用可能な比較的小規模なノイズあり中規模量子(NISQ)コンピューターの能力の範囲内にとどまっています。これらのマシンは、量子コンピューティングが本来想定されているような複雑な問題を解くにはまだ十分な性能を持っていません。しかし、量子コンピューターがどのような問題領域で効率的に機能するのかを探索し、特定するためには十分な能力を備えています。
この技術が特に計算量は大きいがデータ量は比較的少ないタスクに適していると考えています。たとえば、近い将来には新薬開発などの分野でQMLが役立つ可能性があります。一方で、膨大なデータを必要とする巨大言語モデルのトレーニングには適していないでしょう。QML分野の主要研究者の一人であるMaria Schuld氏は、QMLにおける量子優位性という問い自体が適切ではない可能性を指摘しています。将来的には、従来の機械学習では試みられなかったような応用分野がQMLによって開拓される可能性もあります。
今後数年のうちに、特定のAIタスクに特化したアルゴリズムと、それに対応する専用の量子コンピューターが登場する可能性があります。たとえそれが明確な量子優位性を示さなかったとしても、GPUを多数搭載したサーバーファームよりも大幅に少ないエネルギーとコストで処理できる可能性があります。それだけでも、QMLを実用化する十分な理由になるかもしれません。
AIパイプラインにおける構造的な弱点
企業のAI戦略は、多くの場合、サードパーティのAPI、オープンソースモデル(例:Hugging Face)、専門的なベクトルデータベースといった外部コンポーネントの統合に大きく依存しています。この依存関係は、「ブラックボックス効果」を生み出し、組織はサプライチェーン内のすべての関係主体のセキュリティ体制をそのまま引き継ぐことになります。
事前学習済みモデルを導入する際、組織は単なる機能だけでなく、「凍結された知能(frozen intelligence)」も取り込むことになります。この知能が、学習段階においてデータポイズニングや微妙な重みの改ざんによって侵害されていた場合、その脆弱性はアプリケーションの内部構造そのものに組み込まれてしまいます。このように、AIベンダーのエコシステムが相互に接続された構造を持つことで、小規模なデータ処理サブプロセッサーで発生した侵害であっても、サプライチェーン全体に波及し、大企業にまで影響を及ぼす可能性があります。
境界防御の不十分さ
AIセキュリティにおける一般的な誤解の一つは、安全な環境(たとえばプライベートなVPCやコンプライアンスに準拠したCRMプラットフォームなど)に存在するデータは本質的に安全である、という考え方です。この「信頼されたプラットフォーム」という前提は、LLMの特性を十分に考慮していません。
LLMはトークン処理の原理に基づいて動作しており、多くの場合、ユーザーデータとシステム指示を明確に区別することができません。この性質により、外部入力(悪意のあるメールや文書など)がモデルの安全ガードレールを上書きしてしまうプロンプトインジェクション攻撃が可能になります。Salesforce Agentforceで発見された「ForcedLeak」エクスプロイトの事例は、入力トークンを制御することでモデルの出力を実質的に支配できることを明確に示しています。その結果、AIは機密データの流出や不正なコマンドの実行へと誘導され、従来の境界防御を完全に回避されてしまう可能性があります。
脅威環境の進化:ソフトウェアからデータへ
攻撃対象となる領域は、従来のソフトウェアサプライチェーン(リポジトリ内の悪意あるパッケージなど)を超え、AIスタックを構成する個別コンポーネントへと広がっています。
- 学習データの来歴:データ収集や選別の過程が十分に可視化されていないため、特定のキーワードによって発動する「スリーパー型」の挙動をデータに仕込むことが可能になります。
- モデルのシリアライズに伴うリスク:モデルの重みはシリアライズされたファイル(例:pickleファイル)として配布されることが多く、読み込み時に任意のコードを実行するよう細工される可能性があります。
- インフラの主権:サードパーティのGPUクラウドに依存することは、データの所在や処理の完全性に関するリスクを新たに生み出します。
「コンプライアンス・シアター」を超えて
現在のベンダーリスク管理の慣行は、多くの場合、SOC2レポートのような静的なセキュリティ質問票に依存しています。しかし、このような方法では、動的に変化するAIリスクには十分に対応できません。コンプライアンスのチェックリストはポリシーが存在することを確認するだけであり、推論エンドポイントがリアルタイムのジェイルブレイクやプロンプトインジェクションに対して実際に耐性を持っているかどうかを検証するものではありません。
効果的なセキュリティには、定量的なリスク評価と継続的な監視へと発想を転換することが必要です。組織は、AIのコンテキストウィンドウが適切に分離されていること、そして意思決定ロジックの完全性が保たれていることを検証しなければなりません。分離が数学的に証明されていない限り、データ保護は推測の域を出ないものとなってしまいます。
リスクが加速する中でのAIセキュリティ確保
AIを取り巻く脅威環境が進化する中で、組織は事後対応型の対策から脱却し、より先取り型かつ多層的なセキュリティ戦略を採用する必要があります。以下の提言は、TrendAI™ Researchの主要な調査結果を統合したものであり、AIサプライチェーンの脆弱性、公開されたインフラ、そして進化する攻撃ベクトルによって生じる特有のリスクを軽減、検知、対応するための実践的な指針を示しています。これらのベストプラクティスを実装することで、企業はAI防御を強化し、運用リスクを最小化するとともに、高度なAI技術を安全に導入することが可能になります。
AIサプライチェーン脅威の軽減と検知
組織は、サプライチェーンの完全性、ランタイム監視、アーキテクチャ制御にまたがる多層的な防御を実装する必要があります。
- アーティファクト完全性の管理:CI/CDパイプラインおよびモデルロード時に、すべてのトークナイザーファイル(tokenizer.json、vocab.json、merges.txt、tokenizer_config.json)に対して暗号学的ハッシュ(SHA-256)を生成・検証します。ハッシュ値に予期しない変更があった場合はデプロイをブロックし、正当な更新については文書化された承認を必須とします。トークナイザーの変更は、依存関係の更新やモデル重みの変更と同等の厳格さで扱う必要があります。
- 統計的ベースライン監視:複数言語にわたる既知のトークン特性を持つキャリブレーション用データセットを維持します。文字当たりトークン数(tokens-per-character)や単語当たりトークン数(tokens-per-word)のベースライン指標を確立し、ドリフトが10~15%を超えた場合にアラートを発する自動回帰テストを導入します。これにより、悪意ある操作と設定ミスの双方を、本番影響が出る前に検出できます。
- 本番環境テレメトリ:リクエストごとの文字数、トークン数、トークナイズ遅延、CPU使用率、コスト指標を追跡する仕組みを導入します。言語、ユーザ地域、モデルバリアントごとに計測値を分解し、不公平なリソース配分を検知できるようにします。文字当たりトークン数の急増をデプロイイベントと関連付けて分析し、トークナイザー変更による性能劣化を特定します。
- ハード制限とクォータ管理:APIゲートウェイレベルで入力・出力トークンの最大上限を設定し、「ウォレット枯渇型DoS(denial-of-wallet)」攻撃を防ぎます。過剰なトークン分割を引き起こすリクエストは拒否または要約し、レート制限は生の文字数ではなくトークン化後の長さに基づいて適用します。
- サプライチェーンの来歴管理:モデルは、強固なセキュリティ実践を持つ検証済みパブリッシャーからのみ取得します。内部でトークナイザーをカスタマイズする場合は、コードレビューとセキュリティ承認を必須とします。特にドメイン固有トークンの追加や正規化ルールの変更には注意が必要です。コンテナイメージのスキャンと同様に、モデルの署名と検証のワークフローを実装します。
- レスポンス形式の検証:エージェント型システムでは、アクションの承認に出力フォーマットのみを信頼してはいけません。レスポンスがツール呼び出しの形式に見えるかだけでなく、その実行が文脈的に正当かどうかを検証する意味的検証を実装します。さらに、監査のために、入力がどのように正規化されて実行可能な出力になったのかを示す完全な正規化チェーンをログとして記録します。
AI導入に向けた今後の道筋
本レポートで取り上げたMCPの脆弱性状況は、AIセキュリティ分野が直面しているより広範な課題を反映しています。すなわち、AI機能の導入スピードが、安全な実装手法の確立を大きく上回っているという問題です。公開されたサーバ数のほぼ3倍への増加、廃止されたプロトコルの広範な利用、SQL実行インターフェースのようなデータマイニングツールの露出、そしてAI生成コードや脆弱なコードの増加など、いずれも慎重な対応を求める状況を示しています。
AIエージェントを迅速に展開できる利便性は、企業のデータ環境にバックドアを生み出すことを正当化するものではありません。こうしたリスクを軽減するために、組織は次の対策を講じるべきです。
- MCPのデプロイメントがインターネットに公開されていないか監査する
- SSEから、より安全な最新のトランスポートプロトコルへ移行する
- 厳格なツール認可フレームワークを実装する
- AI生成コードの部分を重点的に確認するセキュリティ観点のコードレビュー体制を確立する
AIを利用した脅威が増加する中で、防御側はそれに対応するための専用ソリューションを必要としています。組織が先手を打つためには、TrendAI Vision One™プラットフォームのAI駆動型ツールを活用することが重要です。表7では、TrendAI Vision One™の機能を活用した脅威と製品機能の対応関係を示しています。
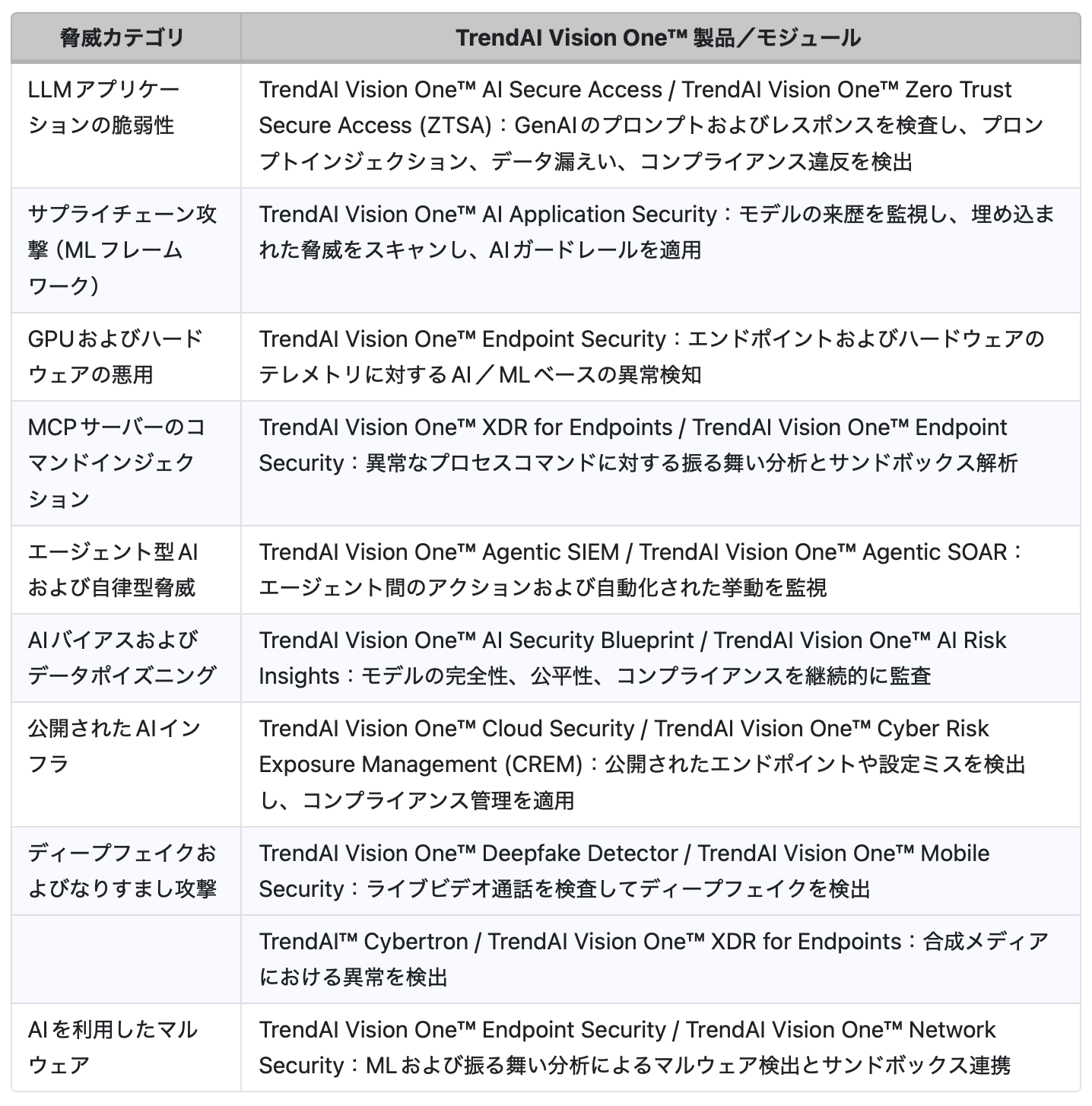
戦略的統合(Strategic integration)は、TrendAI Vision One™の各モジュールを統合されたエコシステムとして結び付け、セキュリティスタック全体にわたる脅威予測、対応、ガバナンスを連携的に実現します。
- TrendAI Cybertron(コアAIエンジン):メール、エンドポイント、ネットワーク、アイデンティティ、クラウドにわたる領域で、プロアクティブな脅威予測と振る舞いベースの検知を実現
- TrendAI Companion™:アラート要約、根本原因分析、対応ガイダンスなどのリアルタイムかつコンテキスト認識型のAI支援を提供し、SecOpsの効率を向上
- AI Secure Access:GenAI環境におけるデータガバナンスを強化し、プロンプトおよびレスポンスの監視、トラフィック制御、悪意あるGenAIインタラクションの遮断を実施
- AI Application Security Package:AIパイプライン全体(モデル開発からランタイムまで)を監視し、ガードレール、リスクインサイト、コンプライアンス管理を通じてAIスタックを保護
- Deepfake Detector / Mobile Security:GAN検知や行動パターン分析を用いて合成動画(例:ビデオ通話)を検出し、TrendAI Vision One™はエンドポイントレベルのディープフェイク分析アラートを統合
これらのAI駆動型モジュールを組み合わせてTrendAI Vision One™を活用することで、防御側はモデルレベルのエクスプロイトからディープフェイクまで、現代の脅威を検知・無力化できると同時に、ガバナンスを確立し、安全なAI導入を実現できます。
詳細はこちら:
これらのツールを防御側がどのように活用しているのかについては、「Defenders and AI Risks」(英語)をご参照ください。
参考記事
- Peter Girnus (Senior Threat Researcher, Threat Hunting Team, TrendAI™ Research)
- Vincenzo Ciancaglini (Senior Threat Researcher, Forward-Looking Threat Research Team, TrendAI™ Research)
- Morton Swimmer (Principal Threat Researcher, Forward-Looking Threat Research Team, TrendAI™ Research)
- David Fiser (Senior Cyber Threat Researcher, Vulnerability Research Team, TrendAI™ Research)
- Alfredo Oliveira (Senior Security Researcher, Vulnerability Research Team, TrendAI™ Research)
- Benjamin Zigh (Director, Threat Research Insights, TrendAI™ Research)
翻訳:与那城 務(Platform Marketing, Trend Micro™ Research)