Artificial Intelligence (AI)
「エージェンティックAI」の実現:アーキテクチャ、脅威、対策
エージェンティックAIシステムがますます複雑化する中で、こうしたアプリケーション群が多層的なアーキテクチャに依存していることが明らかになってきました。この構造を可視化しようとすると、それぞれの層に潜む複数のセキュリティリスクが浮かび上がってきます。本記事では、そうしたリスクがどのようなシナリオで現れるのかを検討し、各層を安全に保つための実践的な対策を紹介します。


- エージェンティックAIシステムのセキュリティを理解するためには、その多層構造を分析し、各層に固有のリスクを特定することが求められます。
- 適切な保護がなされていない場合、攻撃者によって情報が窃取されたり、データポイズニングによって挙動が操作されたり、サプライチェーン攻撃によって重要なコンポーネントが妨害されたりする恐れがあります。
- 構造が複雑であるため、リスクは単一の層やコンポーネントにとどまらず、システム全体に波及する可能性があります。
- 現在Agenticの導入を進めている、または検討している組織にとっては、堅牢な設計原則と状況に応じた個別対策を組み合わせた、二方向からのアプローチが推奨されます。
エージェンティックAIの導入が加速するにつれて、これらのシステムやそれに依存する組織のセキュリティにかかわるリスクも高まっています。エージェンティックAIのアーキテクチャは、それぞれの層が個別の対策を要する構造となっており、セキュリティを確保するには多くの課題が生じます。エージェンティックAIシステムの構成とは実際にどのようなものなのか。各コンポーネントはどのように連携しているのか。そして何よりも、この構造によってどのようなセキュリティリスクが新たに生じるのか。これらは、エージェンティックAIの導入において最適な実践を目指す組織にとって避けて通れない問いです。
今回の調査は、以前の記事で紹介したエージェンティックAIの概念と、従来のAIシステムとの違いを踏まえて行われました。新たに得られた知見は次の4つのパートに整理しています。まず、エージェンティックAIのアーキテクチャと各層の概要。次に、各層における主なリスクを示す脅威モデル分析。そして、設計原則と個別対応策を組み合わせた実践的なセキュリティ対策。最後に、全体の要点をまとめた結論です。
エージェンティックAIシステムのアーキテクチャとその構造
エージェンティックAIのアーキテクチャを俯瞰することで、その内部構造に対するより広い視点が得られます。構造の複雑さを考慮し、全体像は以下のように複数の論理レイヤーに分けて示しています。
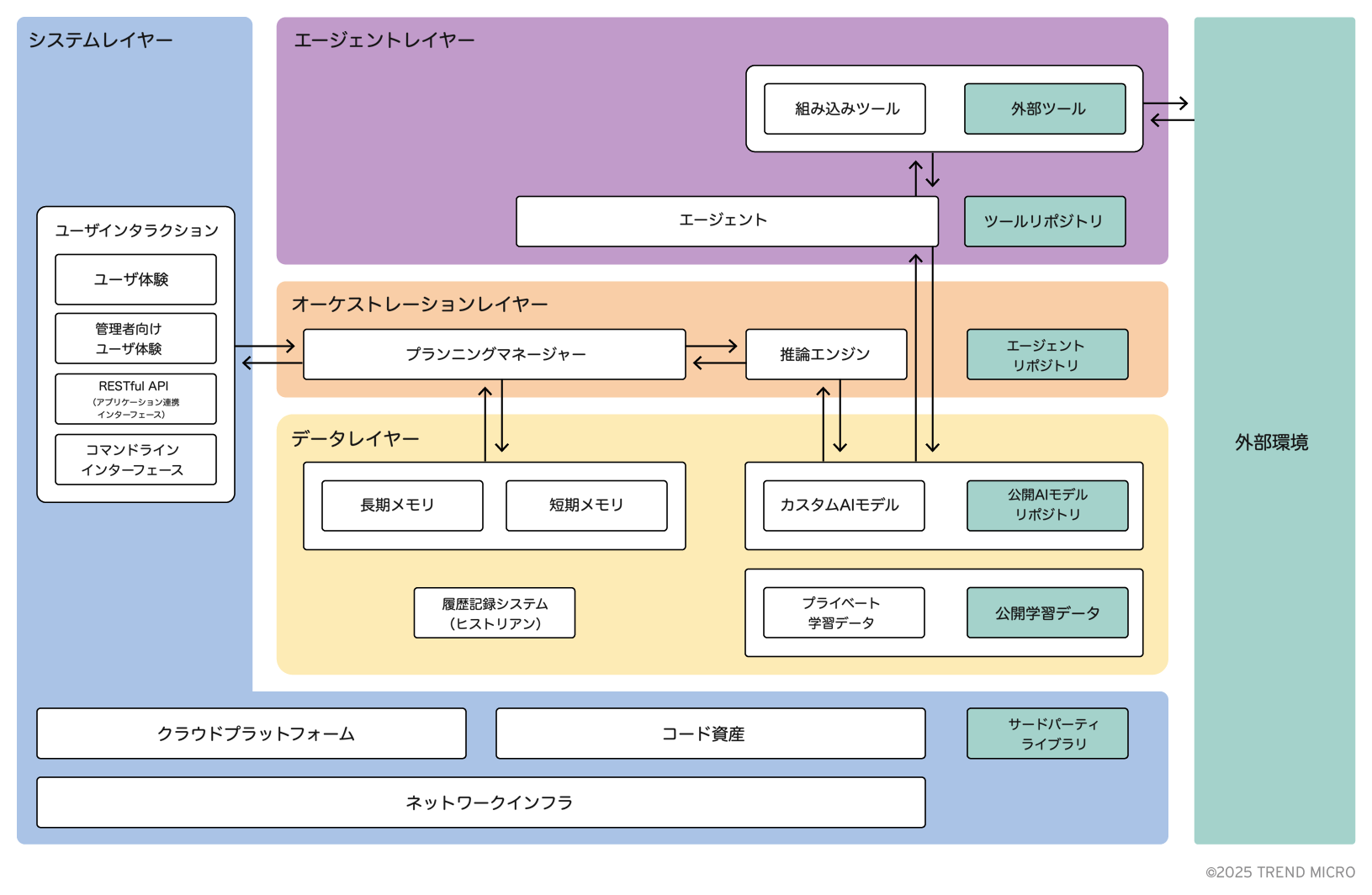
ここで示されているいくつかのコンポーネントは、執筆時点ではまだエージェンティックAIに実装されていない可能性がありますが、近い将来には標準的な構成要素になると考えられます。そのため、将来を見据えた堅牢な脅威分析を行う上では、これらも視野に入れる必要があります。たとえば、ツールやエージェントのリポジトリは現時点では一般には見られませんが、AnthropicによるModel Context Protocol (MCP)やGoogleのAgent to Agent protocol (A2A)といった、ツール呼び出しやエージェント間通信のためのプロトコルが急速に開発されており、これらのリポジトリが現実のものになる可能性は高まっています。したがって、セキュリティ評価を行う際には軽視すべきではありません。
レイヤーの概要は以下のとおりです。
- データ(黄色):モデルの学習データから実行時メモリストレージに至るまで、エージェント全体のライフサイクルで必要とされるストレージ要素を指します。
- オーケストレーション(赤):計算処理に関連するアクションを管理し、AIエージェントの起動などを担います。
- エージェント(紫):AIタスクを実行するためのツールやエージェントを含みます。
- システム(青):ライブラリ、テナンシー、ユーザインターフェース用のフロントエンドなど、一般的な支援コンポーネント全体を含みます。
また、図中に緑色で示されている部分は、エージェンティックシステムそのものには含まれない外部要素です。これは、サプライチェーンに関連する脅威を評価する際に非常に重要な区別となります。たとえば、外部ライブラリ、公開学習データセット、外部ツールなどがこれに該当します。
各レイヤーの詳細については、このあと順を追って説明していきます。
1. データレイヤー
名称のとおり、データレイヤーはエージェンティックシステムの開発、保守、または運用に関わるデータコンポーネントを包含しています。この点において、アプリケーション全体においてセキュリティ確保が不可欠な重要領域を構成しています。
図1に示されているように、主な構成要素は以下のとおりです。
A. カスタムAIモデル
データレイヤーの中核をなすのはAIモデルであり、エージェンティックシステムの稼働において中心的な役割を果たします。組織は、一般に公開されているモデルを利用することも、自社独自の学習データを使って_カスタムAIモデル_を構築することも選択できます。このような自前のデータは他では入手できない情報を含む場合があり、競争優位の源泉にもなり得ます。
これらのモデルは、オーケストレーターによってリクエストに対する計画立案に用いられることもあれば、エージェントが自然言語リクエストをデータストアのクエリへ変換するような特定のタスクを遂行するために使われることもあります。また、画像認識、コンテンツ生成、音声合成(テキスト読み上げ)、光学文字認識などの役割を担うモデルも存在します。
B. 外部モデルリポジトリ
公開されているAIモデルの利用を選択した場合、Huggingface や NVIDIA NGC などの_外部リポジトリ_からモデルを取得することが一般的です。これらのリポジトリでは、さまざまな用途に応じたAIモデルが多数提供されており、社内でのモデル学習に必要なコストや時間を削減できます。しかしながら、この利便性には注意も必要です。外部提供元の信頼性が常に担保されているとは限らず、その依存関係が新たなリスクをもたらす可能性があります。
C. トレーニングデータ
トレーニングデータは、新たにモデルをゼロから構築する際や、既存の基盤モデルをファインチューニングする際に、社内で利用されます。ファインチューニングとは、モデルに特定の領域知識を追加することで、特定タスクへの適応力を高める作業です。
モデルを学習させる際に使われるデータは、そのモデルの知識の基本層を構成します。このデータは、組織内部で管理され外部には存在しない非公開のトレーニングデータから得られる場合もあれば、インターネット上に公開されている公開トレーニングデータが使われる場合もあります。ただし、このアプローチにはいくつかの制約があります。第一に、大規模言語モデルは誤った情報や誤解を招く出力(いわゆるハルシネーション)を生成する可能性があるため、正確な知識を得る手段として単独で依存するべきではありません。第二に、学習やファインチューニングには多大な時間とリソースが必要であり、頻繁に更新することは困難です。そのため、モデルに外部記憶を組み合わせて実行時に知識を補う構成が求められます。
D. メモリ
AIアプリケーションにとって信頼性が高く、最新の情報源を提供するために、外部ストレージが活用されます。このメモリは通常、ベクトルストアで構成され、AIが処理するクエリに対して意味的に関連する情報を検索します。この構成により、AIはエラーの少ない信頼性のあるナレッジベースに依拠でき、かつリアルタイムに素早く更新できるようになります。
情報の保持期間に応じて、このようなシステムにおけるデータストアの実装は少なくとも2種類に分類されます。長期記憶は、アプリケーション全体で汎用的に利用される永続的な情報を保存するために使われ、自己改善といった高度な機能にも活用されます。一方、短期記憶は特定のセッションやユーザに固有の情報を一時的に保持します。たとえば、ユーザの設定やセッション情報、直前のリクエストなどが該当します。これらのデータは、ユーザのセッション終了後に削除されるのが一般的です。
E. ヒストリアン
最後に、ヒストリアンと呼ばれるコンポーネントが存在します。これは、アプリケーションに関するログデータを記録・保存する役割を担います。エラーやデバッグメッセージ、利用状況の記録、その他の関連メトリクスが含まれます。これらのデータは、アプリケーションのパフォーマンスや健全性を監視するうえで重要であり、課金処理の際にも有用となる場合があります。
2. オーケストレーションレイヤー
オーケストレーションは、エージェンティックAIシステムに特有の機能です。このレイヤーは、ユーザからのリクエストを解析し、それを実現するための手順を計画するコンポーネントで構成されます。実際の処理は、監督付きのエージェントによって実行されます。これらのコンポーネントが現実のエージェンティックAIの運用環境でどのように相互作用するかについては、本記事の後半にある「ワークフロー例」のセクションで詳しく説明します。
このレイヤーに含まれるコンポーネントの概要は以下のとおりです。
A. プランニングマネージャー
プランニングマネージャーは、このレイヤーの基本となるコンポーネントです。このソフトウェアは、エージェンティックアプリケーションにおけるビジネスロジックを実装しており、ユーザのリクエストに最初に応答する役割を担います。ワークフロー(たとえば直線的、反応的、反復的など)を定義し、実行グラフを構築します。また、どのエージェントを何体使うかといった選定や配備も担当します。加えて、タスクの終了条件や、エージェント間の通信パターン(逐次、並列、競合型、ネットワーク型、階層型など)も設計します。
現在のプランニングマネージャーは、多くが LangGraph や Microsoftの Autogen といったフレームワークを使って、あらかじめ定義されたワークフローに強く依存していますが、今後はAIによる自律的なプランニングへと移行していくと予想されます。つまり、実行グラフの構築や関与するエージェントの選定を、推論エンジンに委ねる方向へ進むと考えられます。
B. 推論エンジン
プランニングマネージャーは、推論エンジンと連携して動作します。このエンジンは、プランニングマネージャーから渡されたプロンプトをもとに、エージェントに対する実行計画を生成するAIモデルを動作させます。また、エージェントから返された中間結果や、ユーザによる調整を受けて、計画を更新する役割も担います。
現時点では、推論エンジンとして使われるAIモデルには、推論に最適化された大規模言語モデル(LLM)が一般的です。ただし、エージェンティックAIアプリケーションが今後さらに多様な分野に広がるにつれ、自動車業界や産業分野のように、より決定論的な動作が求められる場面では、別のタイプのAIモデルが導入される可能性も考えられます。
C. エージェントリポジトリ
通常、エージェントはエージェンティックアプリケーションの実装に使われるフレームワークにより提供され、静的に定義されます。たとえば MicrosoftのMagentic-One では、ウェブページのスクレイピングやコードの実行などに特化したエージェントが用意されています。しかし、現実のアプリケーションにおける多様なニーズに対応するため、最近では必要に応じて呼び出すオンデマンド型のエージェントの活用が広がりつつあります。
そのため、今後のエージェントは、現在のソフトウェアライブラリのように標準化されたインターフェースを備え、GoogleのA2A のようなプロトコルを通じて実行時に呼び出される形式になると考えられます。将来的なエージェンティックアプリケーションでは、外部のサードパーティエージェント を統合可能なリポジトリに依存することが一般的になると見られます。
3. エージェントレイヤー
オーケストレーションレイヤーがユーザからのリクエストを処理し、実行計画を立て、エージェントを起動して作業を遂行させる役割を担うのに対し、エージェントレイヤーは実際にタスクを実行するコンポーネントを含みます。
A. エージェント
エージェントは、それぞれのタスクを実行し、その結果をオーケストレーター層に返す、あるいはプランニングマネージャーが定義した通信パターンに応じて互いに直接連携するソフトウェアユニットです。エージェントはまた、インターネット上のリソースや、センサーやカメラなどの物理的アクチュエーターといった外部環境とも対話できます。これらの操作は、ツールと呼ばれる機能を通じて実行されます。
B. 組み込みツール
組み込みツールは、エージェントレイヤー内でローカルに動作します。これには、エージェンティックアプリケーション内に保存されたローカルプログラム、エージェントによって生成されたコードをローカル環境でコンパイル・実行する仕組み、あるいはエージェントが生成したドメイン固有のコードをローカルインタープリターに渡す方式などが含まれます。
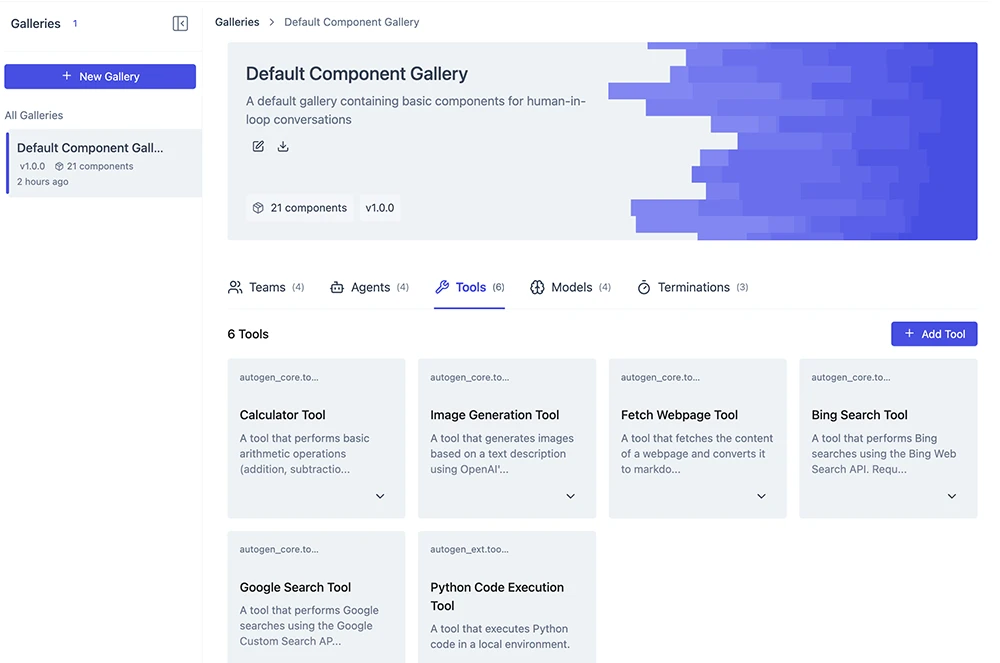
C. 外部ツール
外部ツールは、エージェントがAPIを介して呼び出す外部サービスや、専門的なデータを保持する外部データベースで構成されます。エージェントはそれらに対してクエリを投げることができます。図2は、AutoGen Studio によって提供されるツールの一例を示しています。また、ツールをエージェントが利用できるように公開するための標準プロトコルとして、Model Context Protocol (MCP) のような規格もすでに存在します。
D. ツールリポジトリ
エージェントは、ツールリポジトリにアクセスし、現在のタスクに最も適したツールを取得できます。これには、PyPy や npm といったライブラリリポジトリや、マニフェストによって記述されたサービスをオンデマンドで提供するマイクロサービスカタログなどが含まれます。これらは、前述のMCPのような専用プロトコルを使って呼び出されます。
4. システムレイヤー
最後に、エージェンティックであっても、AIアプリケーションは依然として一般的なアプリケーション機能を支える通常のソフトウェアコンポーネントを必要とする点を忘れてはなりません。ユーザとの対話、認証、設定といった基本的な機能は、すべてシステムレイヤーにまとめられています。
A. ユーザインタラクション
グラフィカルなユーザインターフェース、ハードウェアと組み合わされたUI、チャットボットアシスタント、あるいはAPIを通じたプログラム的な操作など、いずれの形式であっても、エージェンティックアプリケーションはユーザとのやりとりを通じて目的を設定し、要件を指定し、結果を返し、さらにはその応答に基づいて計画を調整する必要があります。以前の公開記事では、エージェンティックAIアプリケーションが消費者向けのAIアシスタントという形で人と直接やりとりする未来像と、そこに伴うユーザ視点からのセキュリティリスクについて取り上げました。
このほかにも、システムレイヤーでは次のような構成要素が稼働しています。
B. コード資産
エージェンティックアプリケーションには、ソースコード、構成スクリプト、その他の資産も必要です。これらには、CI/CDやソースコード管理などを実現するための適切なDevOpsインフラが求められます。こうした一連の構成要素は「コード資産」として扱われます。
C. ネットワークインフラおよびクラウドプラットフォーム
最後に、アプリケーションの稼働を支えるネットワークインフラと、各コンポーネントを実行するための計算リソースを割り当てるクラウドプラットフォームが必要です。これは、一般的な端末上に配置されたローカルのエージェンティックアシスタントであれ、企業の社内インフラ内で稼働するアプリケーションであれ、あるいはインターネット上に公開されたサービスであれ、すべてに共通して求められる要件です。
5. ワークフローの例
エージェンティックアプリケーションは、多くの要素が連携して機能する複雑なシステムです。それぞれの構成要素が調和して動作することが求められます。図3では、特定のワークフローの中で、さまざまなコンポーネントがどのように相互作用するかを示しています。
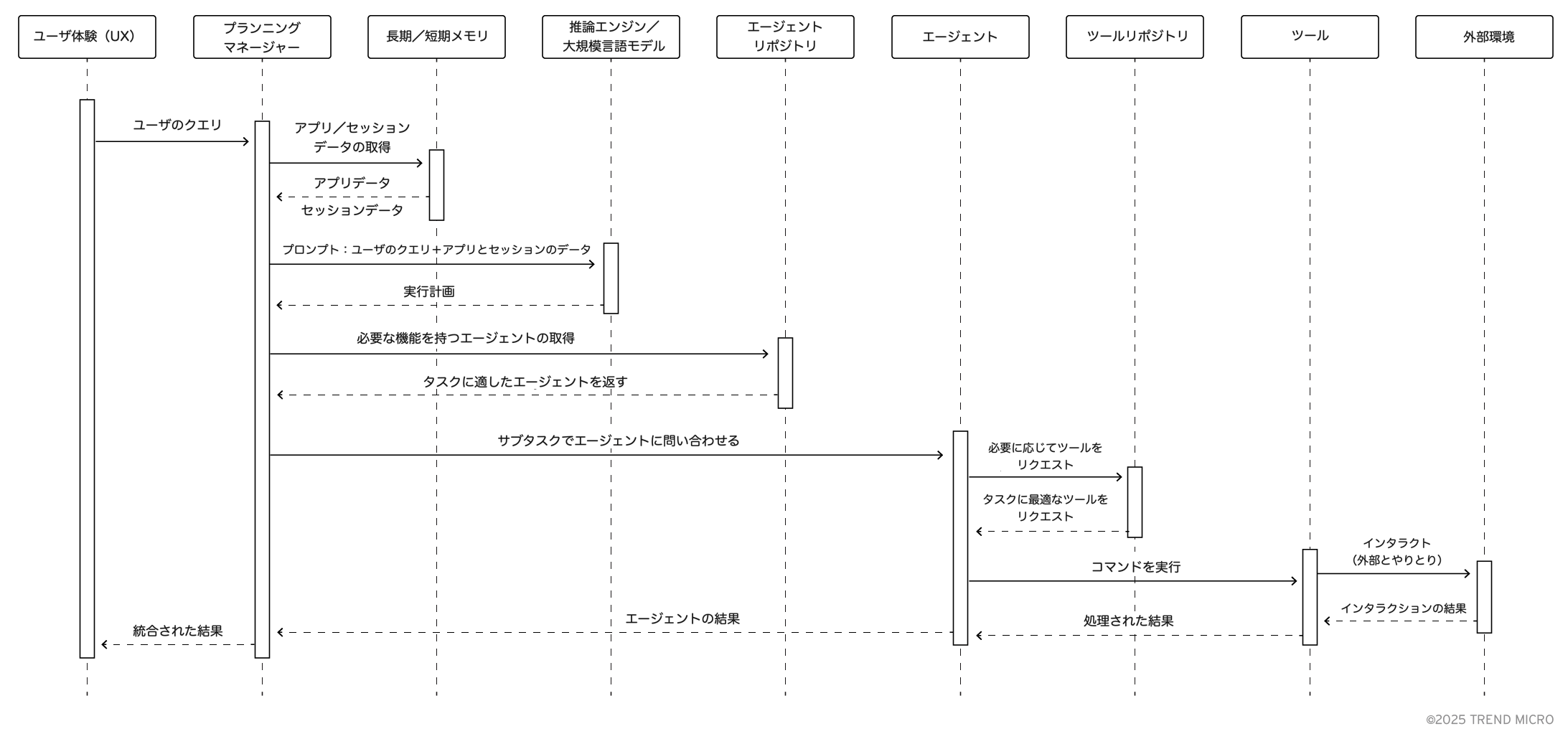
このケースでは、ユーザがアプリケーションのユーザインターフェースを通じて送信したクエリが出発点となります。このクエリはプランニングマネージャーに渡され、そこからアプリケーション関連の情報は長期記憶から、セッションやユーザ関連の情報は短期記憶から取得されます。
これらの情報をもとに、プランニングマネージャーがプロンプトを構築し、それを推論エンジンに送信します。推論エンジンは実行計画を返し、それを受けたプランニングマネージャーが実行に移ります。実行計画に基づき、必要なエージェントを選定し、それぞれのタスクを割り当てます。
エージェントは指示を受けてタスクを実行します。必要に応じてツールを活用し、ツールリポジトリへのアクセスも行います。処理結果はエージェントからプランニングマネージャーへ返され、必要に応じて複数回の反復や調整が行われた後、最終的な結果としてユーザに返されます。
この一連のプロセス全体を見渡すと、多数の異なるコンポーネントが関与しており、それぞれが独自のリスクと課題を抱えています。これにより、エージェンティックAIアプリケーション全体の攻撃対象領域は非常に広範かつ複雑なものとなっています。次のセクションでは、各レイヤーに影響を与えるリスクの分類と、それがセキュリティ対策において何を意味するかについて詳しく見ていきます。
脅威モデリング
ここまで見てきたように、エージェンティックAIシステムは複雑な多層アーキテクチャに依存しています。これらのレイヤーは相互に連携しているため、セキュリティリスクはどの段階でも発生し得ますし、システム全体に波及する可能性もあります。そのため、これらのリスクを理解することが不可欠です。以下では、各レイヤーが直面する主なリスクの概要を示します。
1. データレイヤー
データレイヤーは、データストア、学習用データセット、モデルに対する脅威にさらされています。攻撃者はこれらの構成要素を改ざんすることで、エージェンティックシステムのアプリケーションロジックを変質させたり、システムが保持する機密データを盗み出したりすることを狙っています。
A. データストアのポイズニング
データストアのポイズニングとは、インターネットに公開されたサービスや設定ミスなどをきっかけに、攻撃者がエージェンティックシステムのデータストア内のデータを改ざんする脅威です。この改ざんは、長期記憶か短期記憶のどちらが影響を受けるかによって、その結果も異なります。
攻撃者が長期記憶をポイズニングすることに成功した場合、アプリケーションの挙動そのものが根本的に変えられてしまう恐れがあります。たとえば、セキュリティ設定を緩める構成変更、アプリケーション内部で実行される悪意あるコードの挿入、または微細なデータ改ざんによってアプリケーションの判断を誤らせるといった手法が考えられます。
一方で、短期記憶が改ざんされた場合は、ユーザのセッションに対して即座に直接的な影響が及びます。セッションデータを操作されることで、アカウントの乗っ取り、ユーザのなりすまし、トランザクションの操作、セッション中の機密情報の取得などが可能になります。この種の攻撃は、ユーザの操作を乗っ取る「セッションハイジャック」に類似しています。
B. 学習データセットのポイズニング
メモリの改ざんのようにアプリケーションの実行中のデータに直接手を加えるのではなく、この攻撃ではAIの学習プロセスの土台となるトレーニングデータセットを標的とします。攻撃者がこれらのデータに誤解を招く情報を混入させることで、AIモデルの学習や判断が意図的に歪められます。
AIモデルは学習データをもとに意思決定を行うため、不正確なデータが混入すると、判断の誤りが生じるリスクがあります。こうした誤りはすぐには顕在化しないこともありますが、長期的には分類ミス、バイアスの導入、バックドアの仕込み、性能の低下といった形で影響が表れる可能性があります。
C. 推論攻撃(インファレンスアタック)
内部開発されたモデルの特筆すべき点として、その学習データに企業の業務プロセスに基づく機密情報が含まれている場合があります。こうしたケースでは、攻撃者が学習データを盗み出すか、あるいは推論攻撃を通じて内容を推測することで、知的財産や非公開情報にアクセスできてしまうおそれがあります。
このシナリオでは、攻撃者が精巧に設計された入力データを使ってモデルにクエリを投げます。これにより、出力結果やモデルの挙動を観察し、その反応から学習データの特徴を推測します。たとえば、特定の入力を少し変更しただけで出力が一貫して変化する場合、攻撃者はその挙動からモデルの学習データに関する特性を導き出すことができます。
D. モデルおよびデータ送出の流出
モデルが社内で開発されている場合、もうひとつの大きなセキュリティリスクは、攻撃者によってそのモデルが流出する可能性です。推論攻撃では、モデル構築に使用された元データの情報を引き出すことが目的ですが、このケースでは、その情報をもとに開発された完成モデル自体が盗まれることを指します。
この段階で攻撃者は、盗んだモデルを単独で再利用でき、場合によっては同様のエージェンティックなシステムを独自に運用することも可能になります。これは、知的財産の漏洩という重大な問題に加えて、対象組織にとって大きな競争上の不利益をもたらします。攻撃者はモデルだけでなく、長期記憶および短期記憶からデータを抜き取り、稼働中のアプリケーションに関するさらなる情報を取得しようとする可能性もあります。特にこうしたシステムがインターネット上で公開されていること自体が、深刻なリスクとなっています。
モデルの盗難は、企業のAIシステムの技術的な内部構造をさらすだけでなく、サービスや製品の模倣を攻撃者に許すことにもつながります。さらに、モデルに独自のアルゴリズムや機密データが含まれている場合、その不正使用は法的および規制上の問題に発展する可能性もあります。
E. モデルの改ざん
Hugging Faceのようなプラットフォームから取得した外部モデルに依存しているシステムの場合、サプライチェーン攻撃 のリスクがあります。これは、モデルの取得プロセスを乗っ取ることを目的とした攻撃であり、攻撃者が正規のモデルを自らの悪意あるバージョンにすり替えることで実行されます。このような攻撃が成功すると、対象アプリケーションのロジック全体が攻撃者に有利な方向へ操作され、挙動が微細ながらも有害な形に変化してしまう可能性があります。
この種の攻撃がもたらす影響は深刻です。たとえば、該当モデルが財務予測や個人データ分析など、重要な意思決定に関与している場合、攻撃者は出力結果を意図的に歪め、自らに有利な結論を導いたり、業務に大きな混乱を引き起こしたりすることができます。加えて、アプリケーションの整合性や信頼性が損なわれ、ユーザからの信用が失われることで、外部モデルを利用している企業の評判にも重大なダメージが生じるおそれがあります。
2. オーケストレーションレイヤー
オーケストレーションレイヤーは、リソースの割り当てや実行計画といった中核的な機能を標的とするさまざまな攻撃にさらされています。これらの攻撃は、大規模言語モデル(LLM)に基づいた推論エンジンの脆弱性や、インターネット上に公開されたメモリストレージの脆弱性を悪用する形で行われます。
A. 再帰的エージェント呼び出しの悪用
エージェンティックなワークフローにおいて重要な要素のひとつが、終了条件です。つまり、処理が所定の条件を満たした時点で、ワークフローを終了させるというものです。これは通常、プランニングマネージャーのパラメータとタスクの性質によって決定され、エージェンティックワークフローの根幹をなす要素です。
しかし、この終了条件が間接的なプロンプトインジェクションやデータストアのポイズニングなどにより改ざんされると、アプリケーションが意図しない挙動を示し、エージェントが無限に呼び出され続ける再帰的エージェント呼び出しの悪用が発生する可能性があります。これにより計算資源が枯渇し、サービス拒否(DoS)状態に陥るおそれがあります。
B. ゴールの改ざん
エージェンティックシステムは、ユーザのプロンプトをプランニングマネージャーが受け取り、それを推論エンジンが解析することで目標(ゴール)を設定し、それを達成するためにエージェントを活用します。
たとえば、ユーザのリクエストが「6月にサンフランシスコへ旅行したい」であった場合、これは「2025年6月1日から6月30日までのサンフランシスコ行きのフライトと宿泊先を探す」というゴールに変換されます。プランニングマネージャーはこの目標に基づき、利用可能なリソースを踏まえて次のような実行計画を立てます。「1. フライトの候補を探す、2. ホテルの候補を探す、3. フライトとホテルの合計費用を算出する、4. 最安値順に並べ替える」。また、処理中に「6月のフライトが存在しないため、月を変更する必要がある」といった新たな情報が得られることで、目標が動的に変更されることもあります。
このような状況において、攻撃者がエージェントのひとつを経由して推論エンジンに対して間接的なプロンプトインジェクションを仕掛け、悪意のあるプロンプトを注入することで、プランニングマネージャーに目標の改変を促すことができます。たとえば、「特定の航空会社のみを選択するように」といった指示を埋め込むことが考えられます。また、インターネット上に公開されたメモリストレージが乗っ取られている場合は、プロンプトインジェクションを行わずともセッションデータを改ざんすることで、目標自体を変更することも可能になります。
C. ステートグラフの改ざん
プランニングマネージャーは、アプリケーションの現在の作業状態を監視し、それをもとに次の実行ステップを計画する役割を担っています。プランニングマネージャーの実装方法によって、ステートグラフは LangGraph のようなフレームワークで実装されたハードコード型のワークフローから、推論エンジンによってリアルタイムに生成される動的なグラフまで、さまざまな形式をとります。現在の実行状態は短期記憶に保存されていることが一般的です。
アプリケーションの実行状態を攻撃者が改ざんする可能性がある手法はいくつか存在します。
- ハードコードされたワークフローの場合、攻撃者がシステムのコードやライブラリにアクセスできると、CVE-2025-3248 のような脆弱性を悪用し、実行グラフの一部を改ざんする可能性があります。たとえば、実行中のサブグラフを悪意あるものに置き換える「サブグラフなりすまし」が該当します。
- 短期記憶がインターネット上に公開されている場合、攻撃者がそのストレージにアクセスしてセッションデータ、つまり現在の実行状態を含む情報を改ざんし、意図しない動作を引き起こす「オーケストレーションポイズニング」が可能となります。
- 動的グラフの場合は、精巧に作成されたプロンプトインジェクションによって、大規模言語モデル(LLM)を静かに誘導し、実行状態を攻撃者にとって有利な方向へ変化させる「フローディスラプション(流れの撹乱)」を引き起こすことができます。
3. エージェントレイヤー
エージェントと専用ツールは、外部環境に最もさらされているコンポーネントであり、そのためさまざまな形態のサプライチェーン攻撃に対して特に脆弱です。
A. ツールの改ざん
エージェントは、ツールを使用して外部環境(たとえばウェブサイト)とやりとりします。ツールのサブバージョンとは、ツールの期待される動作を改変する攻撃であり、ツールの種類に応じて複数の手法が存在します。
外部ツールの場合、攻撃者はエージェントに誤ったツールを選ばせるよう誘導します。これは、選択ミスを誘発するか、悪意あるツールをより適切なもののように見せかけることで実現されます。ツールリポジトリが存在すると仮定した場合、攻撃者はその中に悪意のあるツールを登録し、エージェントがそれを選択するようソーシャルエンジニアリングを行う可能性があります。この種の攻撃は「ツールコンフュージョン(混乱)」として知られています。
別の攻撃手法としては、外部ツールを取得するために使用されるAPIを乗っ取るというものがあります。たとえば、APIで使用されるインターネットドメインに対してDNS攻撃を仕掛けることで実現できます。この攻撃は「ツールハイジャック」と呼ばれ、過去に PyPy や npm のようなソフトウェアライブラリリポジトリに対して行われたサプライチェーン攻撃と非常によく似ています。
現在のエージェンティックAIシステムはまだツールを自律的に探索・選定する能力に乏しいため、完全な意味でのツールコンフュージョン攻撃は未確認ですが、悪意あるMCPサーバー を介したツールハイジャックの変種が登場する可能性は高まっています。オープンソースのMCPサーバーが急増する中、開発者が自らのシステム用にMCPサーバーを不用意に立ち上げ、後にそれがエージェンティックアプリケーションに対して悪意ある挙動を示すことが発覚するケースも想定されます。
外部リクエストを必要としない組み込み型ツールにおいても、サブバージョンは発生する可能性があります。この場合、精密に設計されたプロンプトインジェクションによって、エージェントに悪意あるコードを生成・実行させることが可能になります。
B. エージェントの改ざんおよび関連攻撃
この攻撃は、エージェントの挙動を変更することを目的としており、エージェントそのものを改変するか、あるいはすり替える形で実行されます。
LLM(大規模言語モデル)に依存するエージェントは、外部から注入された悪意ある入力やコンテンツにより間接的なプロンプトインジェクションを受ける可能性があります。LLMにとって、どの部分が正規のクエリでどの部分が乗っ取られた情報なのかを区別するのは困難であるため、追加の指示文がテキストの中に埋め込まれることがあります。この隠れたプロンプトによってエージェントの役割が変更される攻撃は「エージェントロールサブバージョン」と呼ばれます。
また、攻撃者がプランニングマネージャーに誤ったエージェントを選ばせるよう誘導するケースもあります。これは、リポジトリ内に悪意あるエージェントを登録し、より魅力的な機能を持つかのように見せかけることで実現されます。この攻撃は「エージェントコンフュージョン」に該当します。さらに、既知のエージェントをそのまま悪意あるものと置き換える「エージェントハイジャック」も存在します。
C. エージェント間の情報ポイズニング
プランニングマネージャーによって定義されたワークフローによっては、エージェント同士がオーケストレーション層の監視なしで直接通信することもあります。これは新たなリスク層を生み出します。
もしひとつのエージェントが侵害されていた場合、そのエージェントは通信先の他のエージェントに対してポイズニングされた情報を送信し、間接的なプロンプトインジェクション攻撃を波及させることが可能です。このような攻撃を実行するには、エージェンティックアプリケーションに関する深い知識が必要であることが一般的ですが、これを検知するにはエージェント間でやりとりされるすべてのメッセージを綿密に監視する必要があります。
D. エージェントのAIモデルに対する敵対的攻撃
このレイヤーに対する最後の脅威は、エージェントが使用するAIモデルそのものへの攻撃です。非構造化テキスト(ウェブコンテンツや外部データベースの検索結果など)を処理するためにLLMを利用しているエージェントは、間接的なプロンプトインジェクションにさらされるリスクがあり、これによりエージェントの挙動が変化したり、システムから情報が流出したりする可能性があります。
すべてのAIモデルが言語モデルであるわけではなく、すべてのエージェントがLLMを使用しているわけでもありません。たとえば、動画フィードから特定の物体を認識することを担う物体認識エージェントも存在します。これは、自動車の障害物検知、監視カメラにおける人物認識、生産ラインにおける欠陥品検出などに使われます。こうしたモデルもまたタスク実行能力を標的とした攻撃にさらされる可能性があります。たとえば、自動運転用AIの進路認識を妨げる道路標示や、顔認証を回避するための特殊な化粧などがこれにあたります。
4. システムレイヤー
エージェンティックアプリケーションであっても、基本的な機能を担保するためには従来型のソフトウェアコンポーネントが必要であるため、古典的な攻撃手法が依然として有効です。以下は、システムレイヤーに限定されるもの、あるいは他のレイヤーにも波及する可能性のある、エージェンティックアプリケーションの生産性に影響を与える代表的な脅威です。
A. 設定ミス
設定ミスにより、機密情報への不正アクセス、ソフトウェアコンポーネントの侵害、あるいはサービスの停止が引き起こされる可能性があります。さらに、これが他のレイヤーへの侵入口となることもあります。
B. ソフトウェアの脆弱性
ソフトウェアの脆弱性は、攻撃者が不正アクセスを行ったり、データを操作したり、エージェンティックAIシステム全体の動作を妨害したりする手段として悪用される可能性があります。システムレイヤーを含む複数のレイヤーには、さまざまなソースから導入された複雑なソフトウェアコンポーネントが含まれているため、こうした脆弱性はアプリケーション全体にとって大きなリスクとなります。これには、サプライチェーン攻撃によってサードパーティ製ライブラリが標的にされるケースも含まれます。
C. 認証の弱さ
認証が弱い、あるいはそもそも認証が存在しない場合、攻撃者が内部コンポーネントやシステムログへ容易にアクセスできてしまい、権限の昇格を許してしまう可能性があります。取得された権限の範囲によっては、データの改ざんや不正なソフトウェアのインストール、さらにはエージェンティックアプリケーション全体の停止すら引き起こされるおそれがあります。
D. DoS(サービス拒否攻撃)
他のインターネットサービスと同様に、エージェンティックアプリケーションおよびその各レイヤー(システムレイヤーを含む)も、分散型サービス拒否(DDoS)攻撃の対象となるリスクがあります。
E. 公開されたAPI
公開されたAPIは、攻撃者にとって機密情報へのアクセスや、リソースを枯渇させる攻撃手段として悪用される可能性があります。攻撃者はこれらのインターフェースを通じて、悪意あるコードの注入、機密データの取得、あるいは大量のリクエストを送信することでサービスの可用性を妨害することができます。この脆弱性は、アプリケーションのセキュリティを損なうだけでなく、データの完全性やシステムの安定性に対しても重大なリスクをもたらします。
5. エクスポージャーマトリクス
これらの脅威をより体系的に分類するために、さまざまな攻撃が成功するために必要な条件を整理したマッピングを作成しました。
エクスポージャーマトリクスは、ある攻撃が外部の攻撃者によって実行可能なのか、特定のコンポーネントへのアクセスが必要なのか、あるいは特定レイヤー内のいずれかの構成要素、さらには別のレイヤーの制御を必要とするのかを示しています。こうした条件を確認することで、どのセキュリティ境界が特定の脅威を防ぐうえで最も重要なのかを特定し、各レイヤーがシステム全体の攻撃対象領域にどのように関与しているかをより明確に理解することができます。
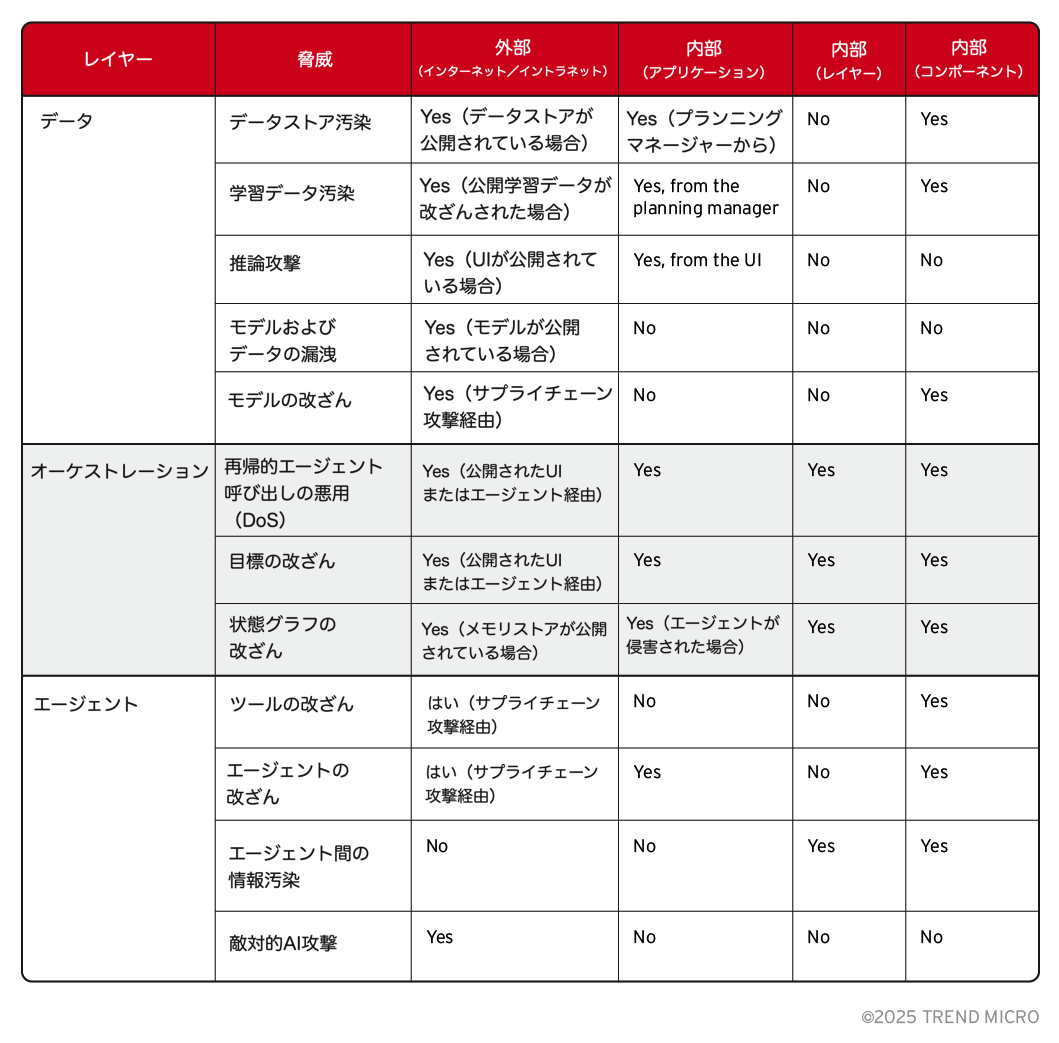
最も重大な攻撃のいくつかは、長期・短期メモリ、保護されていないUIエンドポイント、アクセス可能なモデルといった、公開されたインフラコンポーネントが適切に保護されていない場合に発生します。
データレイヤー全体において、データ送出は大きな注目点です。これはインフラの露出という問題に直接関連しています。エージェンティックAIシステムにおいては、アプリケーションデータが内部構造に関する多くの情報を含んでいる可能性があり、さらに機密情報や自社独自のデータが保存されていることもあります。インフラの露出対策は一定の効果がありますが、データストアに直接アクセスせずとも情報を引き出すことが可能な推論攻撃が存在する点には注意が必要です。
サプライチェーン攻撃も、システム全体にわたって大きな脅威となっています。これは、アプリケーション開発者がサードパーティ製ライブラリ、ツールリポジトリ、外部モデルに対して直接的な管理権限を持っていないことが多いため、特に深刻な問題となります。
現在のエージェンティックアプリケーションは、特にオーケストレーションレイヤーとエージェントレイヤーにおいてLLMに大きく依存しているため、プロンプトインジェクション攻撃は最も顕著かつ広範な脅威ベクトルのひとつとして位置づけられます。
最後に、オーケストレーション層とエージェント層の攻撃には性質の違いが見られます。たとえば、ステートグラフのサブバージョンのようなオーケストレーション攻撃は、より高度な標的型アプローチと深いシステム理解を必要とする一方で、ツールのサブバージョンのようなエージェント側の脅威は、標的の精度は低いものの、より広範な犠牲者に影響を与える可能性があります。
推奨事項
エージェンティックシステムは、多数の構成要素が相互に通信し合う、複雑なアーキテクチャを備えています。その挙動は非決定的な場合も多く、それによって攻撃対象領域は非常に多面的かつ不安定なものとなります。
現在そして今後直面するエージェンティックAIシステムのセキュリティ課題に対応するために、推奨事項は2つの観点に分けることができます。すなわち、設計原則とアドホックなセキュリティ対策です。
1. 設計原則
エージェンティックAIシステムを扱う上で、組織は以下の設計原則を念頭に置く必要があります。
- コンポーネントの強化(ハードニング): エージェンティックアプリケーションの各主要コンポーネントは、それぞれ個別に強化され、保護されなければなりません。また、企業の管理外にあるサードパーティ製コンポーネント(たとえばライブラリ、ツールやエージェントのリポジトリ、公開モデルやデータセット)からのデータの整合性を確保するための適切な制御も必要です。
- レイヤーおよびコンポーネントの分離: 初期のエージェンティックアプリケーションでは、LLM、外部ツール、ユーザインターフェース、オーケストレーションの境界が曖昧になりがちです。しかし、技術が高度化するにつれて、各レイヤーやコンポーネントの間に適切な分離を維持し、それぞれの相互作用を明確に定義された範囲に限定することが重要になります。
- コンポーネント間通信の保護: 上記の分離と関連して、コンポーネント間の通信を安全に保つことも重要です。特に大規模言語モデルを活用したエージェンティックアプリケーションではその重要性が増します。すでに示されているとおり、プロンプトインジェクション攻撃は依然としてLLMに対して有効であり、エージェンティックアプリケーションではUIからの悪意あるリクエスト、インターネットにアクセスするエージェント、あるいは外部に公開されたデータストレージを経由して実行される可能性があります。エージェントやオーケストレーターに渡されるプロンプトを含むコンポーネント間の通信を検証することは、今後ますます重要になると考えられます。
2. アドホックなセキュリティ対策
多くのセキュリティ課題はエージェンティックアーキテクチャに特有であり、エージェンティックAIシステムの進化とともに今後さらに増加することが予想されますが、エコシステム全体のあらゆるレイヤーにおいて堅牢なセキュリティ制御を実装することは不可欠です。
トレンドマイクロは、オーケストレーターやエージェントからデータやシステムコンポーネントに至るまで、各レイヤーを保護し、エージェンティックスタック全体に対して包括的な防御を提供します。
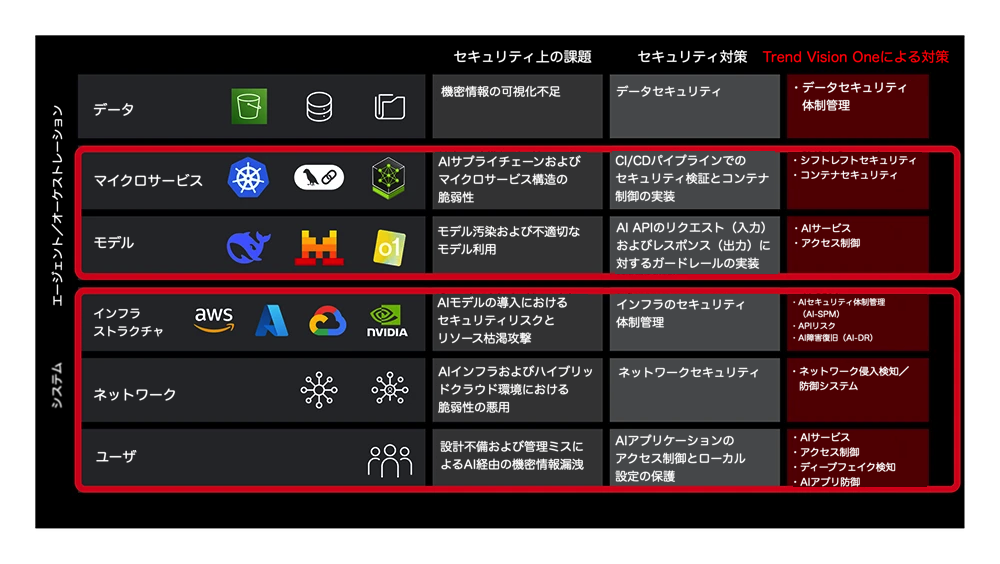
上図は、既存のAIセキュリティソリューションが、今後のエージェンティックアーキテクチャの中核コンポーネントをどのように保護できるかを示したものです。従来のシステムレベルのリスクにも引き続き対応する設計となっています。
A. データレイヤー:機密情報の保護
AIシステムは、学習データや接続されたナレッジベースを起点として、モデル出力を通じて機密情報を意図せず漏えいするリスクを抱えています。また、データ埋め込み(エンベディング)の処理における脆弱性が原因で情報が流出することもあり、入力データが改ざんされることでモデルの挙動が破壊される可能性もあります。
Trend Vision One™の一部である Cyber Risk Exposure Management(CREM) は、Cloud Data Security Posture Management(DSPM)とAI Security Posture Management(AI-SPM)を通じて、これらの脅威に対処します。これらのソリューションは、データ漏えいにつながる可能性のある脆弱性の検出や、AI関連のクラウドデータストレージのインベントリ管理を支援します。これにより、機密データの保護だけでなく、ベクターデータベースのようなデータ処理プロセスの整合性も確保しやすくなります。
B. エージェントおよびオーケストレーションレイヤー:AIコンポーネントの保護とモデルの整合性の確保
AIアプリケーションを支えるマイクロサービスは、サプライチェーンの脆弱性に起因するリスクにさらされています。セキュリティが不十分なコンポーネントが含まれている場合、システム全体が侵害される恐れがあります。また、AIモデルからの出力を不適切に扱うと、サービス全体が悪用されるリスクも高まります。
Trend Vision One™ Container Security は、デプロイ前にコンテナイメージをスキャンし、脅威を検出する「Shift Left」型のセキュリティ手法によってこれらのリスクに対処します。さらに、稼働中のコンテナに対してセキュリティポリシーを適用し、AI出力の扱いミスから発生するエクスプロイトを検知するためのランタイム監視機能も備えています。
また、AIモデル自体も攻撃の対象となり得ます。攻撃者は巧妙に設計された入力(プロンプトインジェクション)を利用してモデルの挙動を操作したり、有害な出力を引き出したりする可能性があります。モデルの出力が検証されないまま使用されると、システムに予期しない問題を引き起こすこともあります。モデルに過剰な自律性や他システムへのアクセス権限を与えてしまうと、モデルが侵害された場合に深刻な影響を及ぼす可能性があります。モデルのリソースを制御せずに使用すると、サービスの停止や予期せぬコスト増加を招くこともあります。
Trend Micro Zero Trust Secure Access(ZTSA)(AIサービス向け)は、ユーザからのプロンプトおよびAIからの応答の両方を検査し、悪意あるコンテンツや問題のある出力をフィルタリングすることでこのレイヤーを保護します。また、アクセス制御によりモデルの機能を制限し、リソースの過剰消費を防ぐためにレート制限も適用されます。
C. システムレイヤー:基盤、接続性、人とAIの対話を守る
AIサービスを支えるクラウドインフラは、それ自体がサプライチェーンの脆弱性を抱えている可能性があります。AIモデルにインフラの変更権限を過剰に与えた場合、設定ミスや侵害が発生するリスクがあります。ベクターデータベースなどの特殊なAI用データベースをホスティングするインフラにも、強固なセキュリティが求められます。
トレンドマイクロは、Cloud向けCREM(AI-SPM)およびAI-DR(XDR for Cloud)を提供しています。AI-SPMは、AI関連のクラウド資産を可視化し、設定ミスや脅威を特定します。XDR for Cloudは、AIサービスが依存するクラウドインフラ全体に対する脅威の検出と対応を支援します。
さらに、AIサービスはネットワークレベルの攻撃にもさらされています。これは、リクエストの集中によるサービス拒否攻撃、一般的なネットワーク侵入、AIシステムのネットワーク公開コンポーネントに存在する脆弱性の悪用などが含まれます。
トレンドマイクロの TippingPoint Threat Protection System(ネットワーク侵入検知・防御システム)は、Virtual Patching機能を備え、これらのリスクに対処します。ネットワークに公開されたコンポーネントの既知の脆弱性を仮想的に修正し、悪意あるネットワークトラフィックをブロックします。
最後に、ユーザとAIシステムの間の対話自体にもリスクが存在します。ユーザが悪意のある入力を送信してモデルを悪用したり、AIからの応答が機密情報を漏えいしたりする可能性があります。また、ユーザがAI生成の誤情報やディープフェイクなどの脅威にさらされたり、ユーザ端末上のAIアプリケーションが侵害されるケースも想定されます。
トレンドマイクロのZTSA AI Service AccessとVision One Endpoint Security(V1ES)に搭載されたAI App Guardは、このレイヤーを保護します。ZTSA AI Service Accessは、ユーザ入力をフィルタリングし、AI出力を検査して悪意ある対話やデータ漏えいを防止します。ユーザ端末上では、V1ESのAI App GuardがAIアプリケーションの改ざんやマルウェア感染から保護します。
結論
エージェンティックAIシステムは、まだ初期段階にあるとはいえ、急速に進化を続けています。システムはますます複雑化し、新たな市場が開かれ、多様なユースケースが生まれています。その導入が加速する中で、構成要素とそれに伴うリスクを明確に理解しておくことが極めて重要です。
前回の記事では、エージェンティックAIシステムの定義と、その中核的な特徴を明確に示しました。目的は、現在の過剰な期待や混乱を整理し、エージェンティックAIを理解するための確かな土台を提供することでした。本記事ではさらに一歩踏み込み、エージェンティックシステムのアーキテクチャに焦点を当て、エージェントリポジトリやマーケットプレイスといった、現在および将来的な構成要素を含めた分析を行いました。また、それぞれの構成要素に関連するリスクを総合的に整理し、リスクを軽減するための有効な推奨事項も提示しました。
こうしたリスクを理解し、適切なセキュリティ対策を講じることで、組織はエージェンティックAIシステムの開発と導入をより安心して進めることができます。現在の課題と将来のリスクの両方に対し、安全かつ責任あるアプローチで取り組むことが可能になります。
参考記事:
The Road to Agentic AI: Navigating Architecture, Threats, and Solutions
By Vincenzo Ciancaglini, Marco Balduzzi, Salvatore Gariuolo, Rainer Vosseler, and Fernando Tucci
翻訳:与那城 務(Platform Marketing, Trend Micro™ Research)