Artificial Intelligence (AI)
トークナイザーのズレが招くLLM運用のコストとセキュリティの危機
あらゆる大規模言語モデルの中心にはトークナイザーがあります。これがわずかにずれていくとき、見過ごされた欠陥や悪意ある干渉のいずれによってであれ、コストは上昇し、性能は低下します。この新たなリスクの実態と影響、そしてそれを防ぐための手立てについて考察します。


はじめに
大規模言語モデルは、学習によって得られた膨大な数値パラメータ(いわゆる「重み」)や、与えられた指示文(プロンプト)だけで動いているわけではありません。その根幹にはトークナイザーがあり、テキストをどのように細かな単位(トークン)に分けるかを決めています。トークンの分け方によって、必要な計算量、APIの利用コスト、そしてモデルのコンテキストウィンドウに収まる情報量が大きく変わります。
トークナイザーの動作が変化すると、その影響は技術面とビジネス面の両方に波及します。同じテキストが突然2倍、3倍のトークン数を消費することがあります。開発者やプラットフォームチームにとっては、CPU使用率の上昇、コンテキストの短縮、処理遅延として現れます。CIO、CISO、CFO、あるいはFinOpsの責任者にとっては、請求額の増加、サービスの不安定化、言語間での不公平な利用体験として現れます。
このリスクは次の二つの経路から生じます。
- 偶発的なドリフト:バグ、設定ミス、またはトークナイザーファイルの変更管理の欠如によるもの
- 意図的な改ざん:コストを膨らませ、クォータを使い切らせ、またはモデルの安全性を損なう目的でトークナイザーを操作する試み
この現象を「トークナイゼーション・ドリフト」と呼びます。厄介なのは、モデルが一見正常に動作しているように見える点です。しかし、その裏でコスト、性能、公平性が静かに崩れていきます。本稿では、この落とし穴の仕組みと実際に起こる形、そして技術チームと意思決定者の双方がどのように検知し、防ぐことができるかを説明します。
トークナイゼーション・ドリフトの脅威モデル
いくつかのシナリオは偶発的に発生します(バグや設定のずれなど)。一方で、悪意を持ったアップロードや標的型攻撃のように意図的に仕掛けられる場合もあります。どちらも同じように、コストの増大とサービス品質の低下というビジネス上の影響をもたらします。トークナイゼーション・ドリフトが実際のシステムで現れる形はいくつかあります。
悪意あるアップロード: 改変されたトークナイザーを含むモデルが公開ハブにアップロードされる場合があります。それをダウンロードして利用したチームは、最初のうちは特に問題に気づかないことがあります。モデル自体は一見、通常どおり動作するためです。
偶発的なドリフト: 社内では、エンジニアが別プロジェクトのトークナイザーを流用したり、リポジトリから「最新」バージョンを確認せずに取得することがあります。わずかなファイルの違いでも、時間の経過とともに静かにコストを押し上げる要因になります。
経済的サービス拒否(EDoS): トークン数を意図的に膨らませることで、攻撃者はAPIクォータを使い切らせたり、クラウド利用料を急増させることができます。システムが停止するわけではありませんが、実質的には運用が困難になるため、サービス拒否(DoS)の一種といえます。
言語バイアス: 攻撃者、またはテスト不足のトークナイザー変更によって、特定の言語が標的になる可能性があります。たとえば英語の処理コストは変わらない一方で、中国語やヒンディー語だけが突然3倍のコストを要するようになる場合があります。これにより、利用者間で不公平なサービス品質が生まれます。
安全ルールの弱体化: トークナイザーは、システム、ユーザ、アシスタントといった特別なトークンに関する情報も保持しています。これらのIDが入れ替わったり変更されたりすると、安全性に関する指示が無視されたり、誰も気づかないまま回避されたりすることがあります。
CPU使用率の増加: トークンが増えるということは、トークナイザーとモデルの双方に追加の負荷がかかるということです。CPU使用率は急上昇し、リクエストが遅くなり、自動スケーリングが作動します。これによりシステム負荷が増し、Podの再生成が頻発し、インフラコストが上昇します。高トラフィック環境では、キューが滞留し、タイムアウトが増加し、マルチテナント環境のワークロードに影響が出る可能性があります。一見「通常のテキスト」に見えるものが、実際には計算資源を静かに消耗させているのです。
今回の調査では次の二点を検証しました。
- トークナイザーの変化がハードウェア使用率、コスト、レイテンシーにどのような影響を与えるか。
- 変更されたトークナイゼーションテンプレートが、モデル出力を変化させ、MCPシステム上で後続のコマンドのような動作を誘発する可能性があるか。

使用データセット: 英語、ヒンディー語、中国語の短文を混在させた小規模データセットを使用しました。すべてプレーンテキスト形式で保持し、一貫性と安全性を確保しました。
バリアント:
- ベースライン トークナイザー(公式ソースのもの)
- 変更版 トークナイザー(制御された方法で差異を加えたもの)。安全のため、モデルの重みは変更せず、トークナイザーのマージ戦略のみを調整してトークン数を増やすように設定しました(詳細は省略)。
ハードウェア: 実験は単一のCPUホストまたは小規模な仮想マシン(VM)上で実施しました。
実行回数: 各バリアントを3回実行し、ノイズの影響を平滑化しました。
妥当性確認:
- 実行間で入力データが完全に一致していること。
- 測定中にネットワーク呼び出しが行われていないこと。
- モデルの重みが変更されていないことを明記。
実験の制約
- 小規模なテストセットでは、あらゆるワークロードを網羅できない。
- VM環境のノイズがレイテンシーやCPUメトリクスに影響する可能性がある。
- モデルファミリーやトークナイザーデザインによって結果が異なる。
測定項目
- 各言語における 1文字あたりのトークン数
- リクエストごとの トークナイザーのレイテンシー(応答遅延時間)
- 4,000トークンのウィンドウ に収まる文字数としての 実効コンテキスト
- 1,000トークンあたりの単価 に基づく コスト予測
手順
- ベースラインのトークナイザーを読み込み、固定された入力セットを処理してすべての指標を記録する。
- 変更版のトークナイザーを読み込み、同一の入力を処理して同じ指標を記録する。
- 固定回数の実行結果を平均化する。
- ベースラインと変更版を比較し、生の数値ではなく変化率に注目する。
結果
悪意ある操作がなくても、わずかに制御された変更によってコストとCPU使用率が有意に増加することが確認されました。これは、トークナイゼーションの変化を検知することが、技術的にも経済的にも重要である理由を示しています。
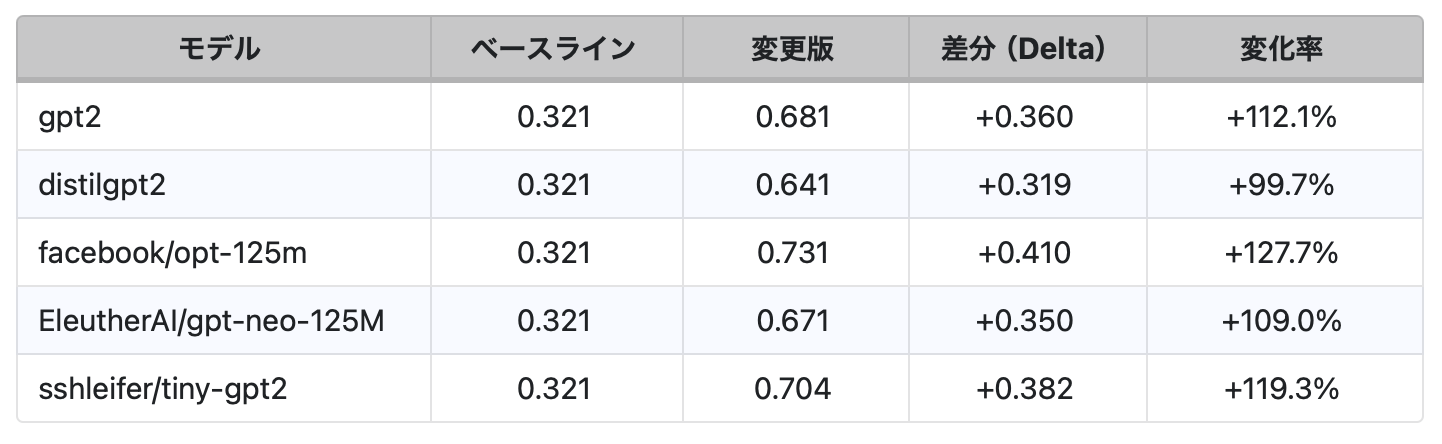
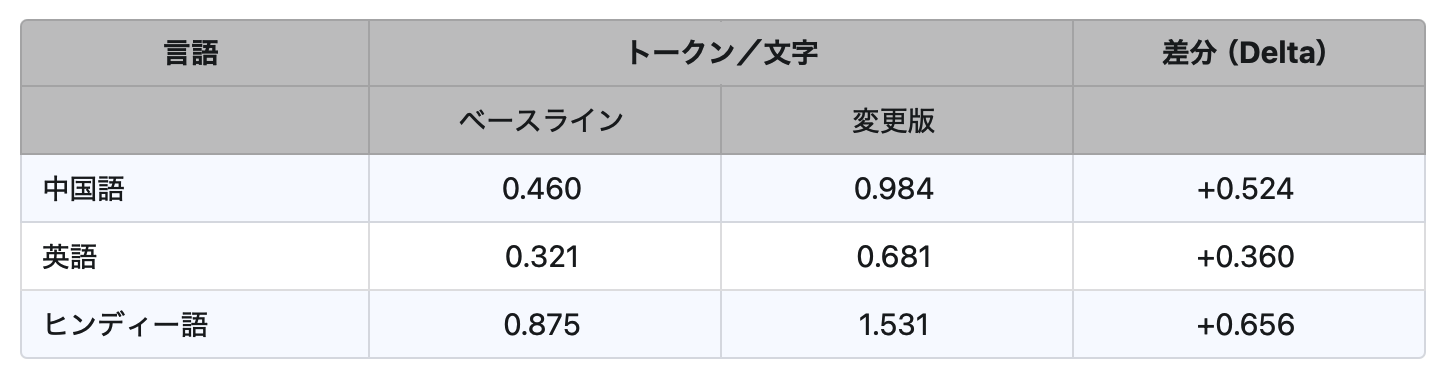
1文字あたりのトークン数(tokens/char)
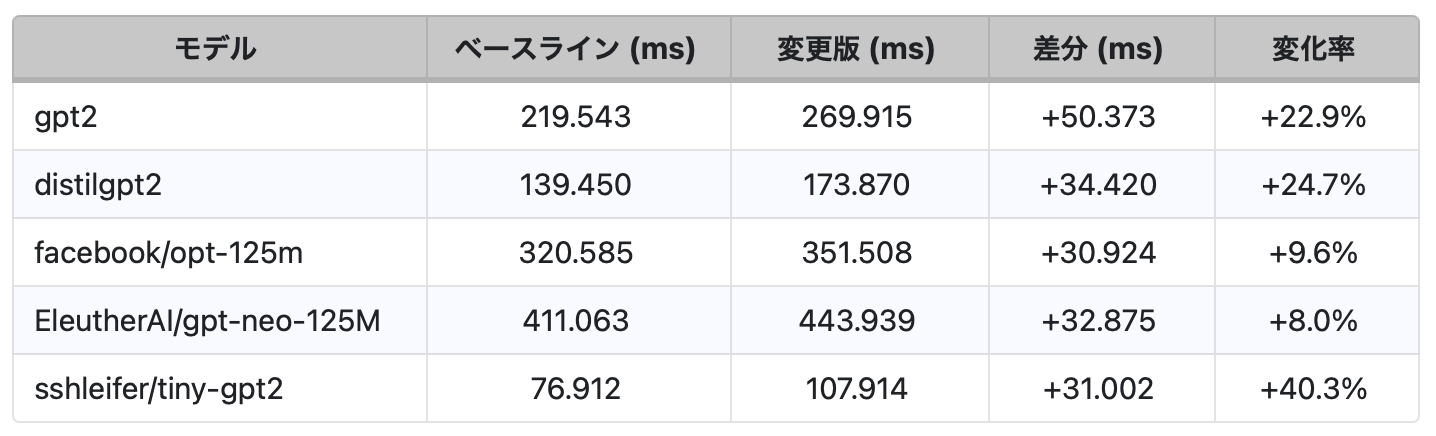
P95トークナイズ遅延時間(ミリ秒単位)
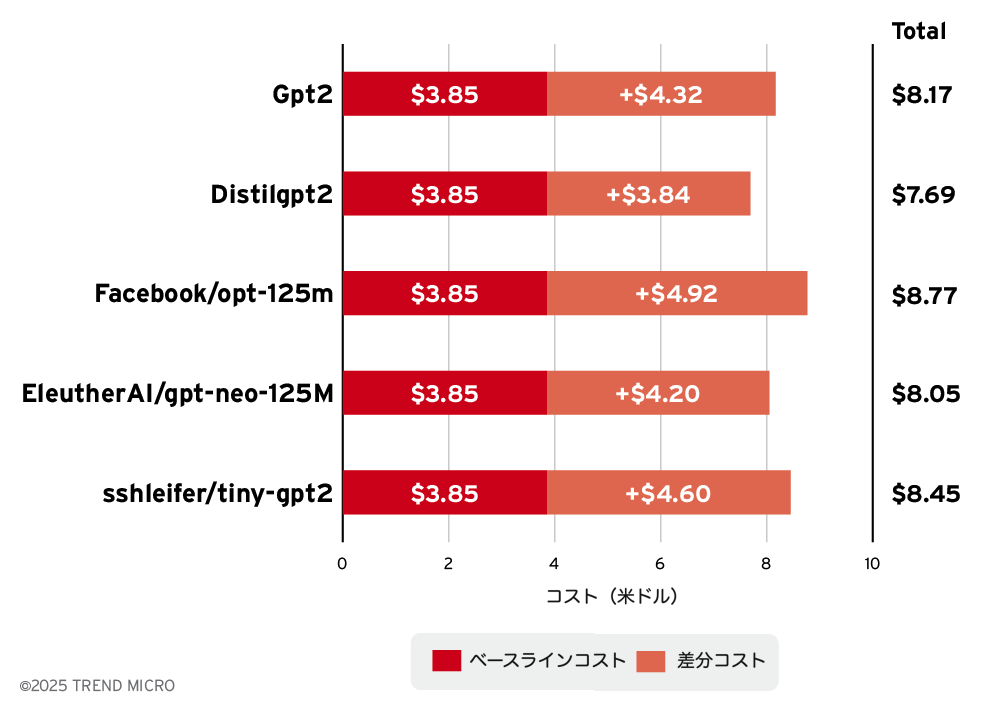
1,000リクエストあたりのコスト予測
一般的な人気モデルの平均コストは、100万トークンあたり約8米ドルとされています。このコスト指標を用いて、1,000リクエストあたりのコストを評価しました。
- 1リクエストあたりの平均文字数:1,500
- 100万トークンあたりのコスト:8米ドル
- 1トークンあたりのコスト:0.000008米ドル
使用した計算式は次のとおりです:1,000リクエストあたりのコスト(米ドル)=(1文字あたりのトークン数)×(1リクエストあたりの平均文字数)×1,000×(1トークンあたりのコスト)
実験から得られた結果と考察
- トークン数が急増する:すべてのモデルで、変更されたトークナイザーは1文字あたり約2.09倍のトークンを生成しました。これは小さなずれではありません。同じワークロードであっても、ホスト型APIではおよそ2.09倍のコストがかかり、セルフホスト環境ではより多くの計算資源を消費します。
- コンテキスト領域が縮小する:4,000トークンのウィンドウを持つモデルでは、英語テキストが約12,500文字から約5,900文字に減少しました(0.321→0.681 tokens/char)。中国語では同程度かそれ以上の縮小が見られます。これにより、プロンプト、履歴、システム指示のすべてが短く切り詰められます。安全ルールやメモリ機能が最初に影響を受けます。
- レイテンシーとCPU使用率が上昇する:トークナイズ処理の遅延は、モデルによって8%〜40%(P95)の範囲で増加しました。1リクエストあたりのCPU使用率も遅延に比例して上昇しました。これは「トークナイゼーション・コスト・トラップ」が単に請求額を増やすだけでなく、システム全体を遅くし、自動スケーリングへの負荷を高めることを示しています。
- 言語ごとに影響が異なる(GPT-2でのみ検証):たとえば、中国語とヒンディー語は英語よりも大きな増加率を示しました。これにより、利用者間で不公平な体験が生じます。特定のユーザ層は、正当な理由もなく高いコストを払い、低い性能に直面します。
- 見えない脅威がある:これらの影響は、最初のうちはエンドユーザや開発者には明らかではありません。モデルは通常どおり応答します。この“罠”は、コストの増加、CPUダッシュボードの異常、または顧客からの苦情が蓄積するまで静かに潜み続けます。これがサプライチェーン上の実際のリスクとなります。
この実験から、トークナイザーのドリフトは単なる実装上の細部ではないことが明らかになりました。コスト、性能、安全性、公平性を本番環境で変化させる要因になり得ます。モデルの重みや重要なコード依存関係の変更と同等の注意を払う必要があります。
この結果が示すこと
- わずかなトークナイザーの変更で、トークン数が2倍から3倍に増加する可能性がある。
- 同じコンテキストウィンドウに収まるテキスト量が大幅に減少する。
- トークナイズ処理のレイテンシーが上昇する。
- 1リクエストあたりのCPU使用率が上昇する。
- コスト予測はトークン数の増加に比例して上昇する。
経営層にとって、この結果は重要な意味を持ちます。AIサービスは表面的に何も変わっていないように見えても、静かに高コスト化し、信頼性が低下することがあります。トークナイザーのドリフトは一見目に見えませんが、請求額、CPUダッシュボード、そしてユーザ体験の不満という形で確実に測定可能な影響を及ぼします。
トークナイゼーションがコストとレイテンシーを左右する理由
トークナイゼーション・コスト・トラップの重要性を理解するには、まずトークナイザーの内部動作を知る必要があります。
何が変わるのか
多くの現代的なLLMは、Byte Pair Encoding(BPE)またはGPT系のトークナイザーを採用しています。これらのトークナイザーは、頻出する文字の組み合わせをまとめて大きなトークンに変換する「マージテーブル」に依存しています。
- 例:「New」は、「N」「e」「w」「 」といった個別の文字ではなく、1つのトークンとして保存される場合がある。
- よく使われるマージ(空白、句読点、語尾の “ing” など)が削除されると、同じテキストがより小さなトークンに細かく分割される。
このような変更は、モデルの重みには一切影響を与えず、トークナイザーのアーティファクトだけを変えるものです。しかし、その影響はシステム全体に波及します。
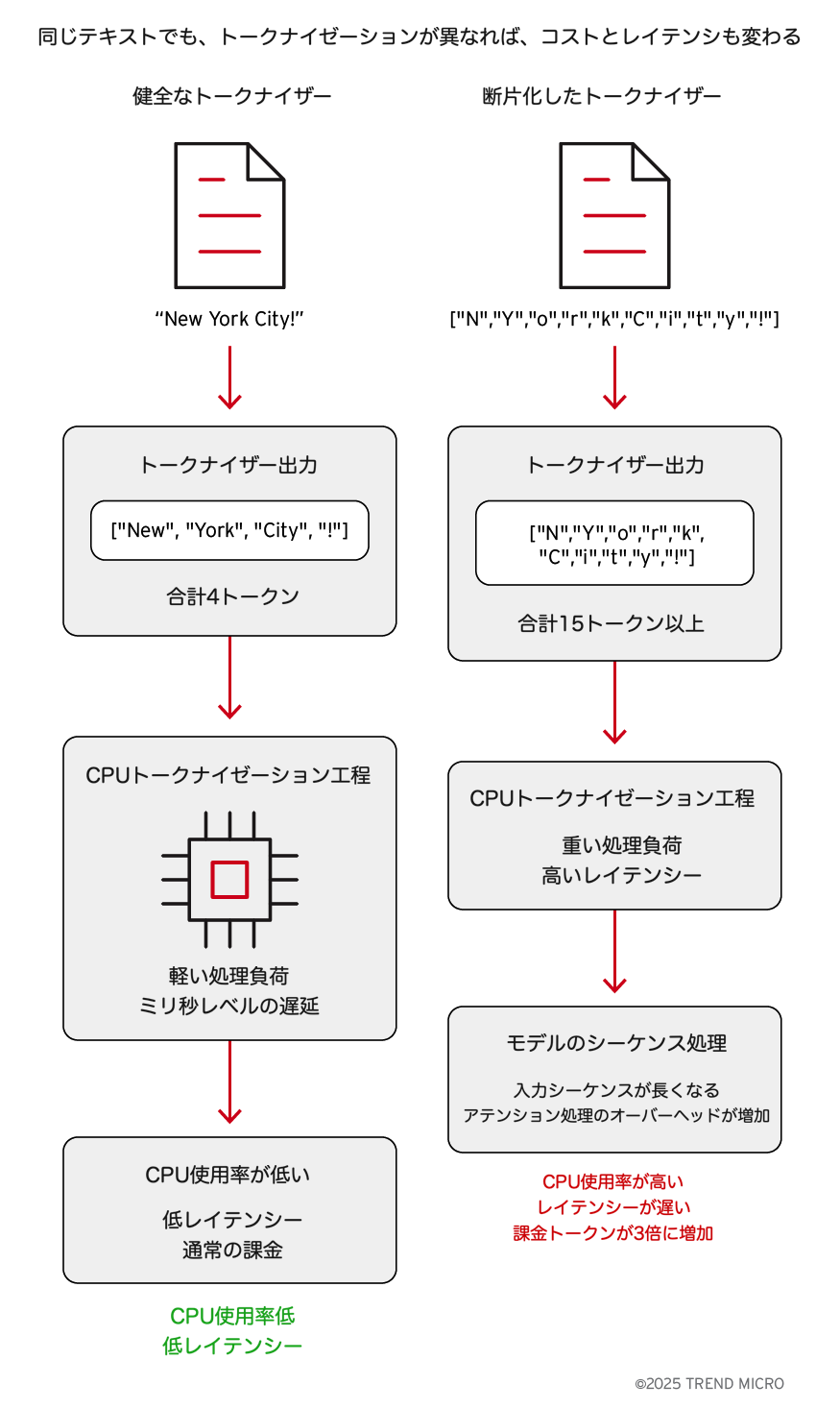
CPU・レイテンシー・コストが上昇する理由
- CPU使用率: トークナイゼーション処理自体はCPU依存のタスクである。トークン数が増えるほど、テキストを入力IDに変換する処理量が増加し、各リクエストのCPU使用率が高くなる。
- レイテンシー: 新しいトークンを少ししか生成しなくても、モデルの順伝播処理は入力の長さに比例してスケールする。シーケンスが長くなると、アテンション計算やKVキャッシュの準備に時間がかかり、応答が遅くなる。
- コスト: 請求は通常、入力トークンと出力トークンの合計で計算される。トークナイザーがテキストを3倍のトークンに分割すれば、同じリクエストに対して3倍の料金を支払うことになる。
具体例
健全なトークナイザーの場合:

文自体は同じであっても、ーはCPU上でより多くの文字をトークナイズする必要があり、モデルははるかに長い入力シーケンスを処理しなければなりません。
その結果として、CPU負荷の上昇、リクエストの遅延、そして請求額の増加が発生します。
要約
マージがより細分化されたトークナイザーに置き換えると、1文字あたりのトークン数が増加します。この単一の変更だけで、モデルの重みを一切変更せずに、各リクエストにおけるCPU使用率、レイテンシー、課金対象トークン数がすべて上昇します。
Part B: ドリフトのセキュリティ面 ― 応答操作とコマンドインジェクション
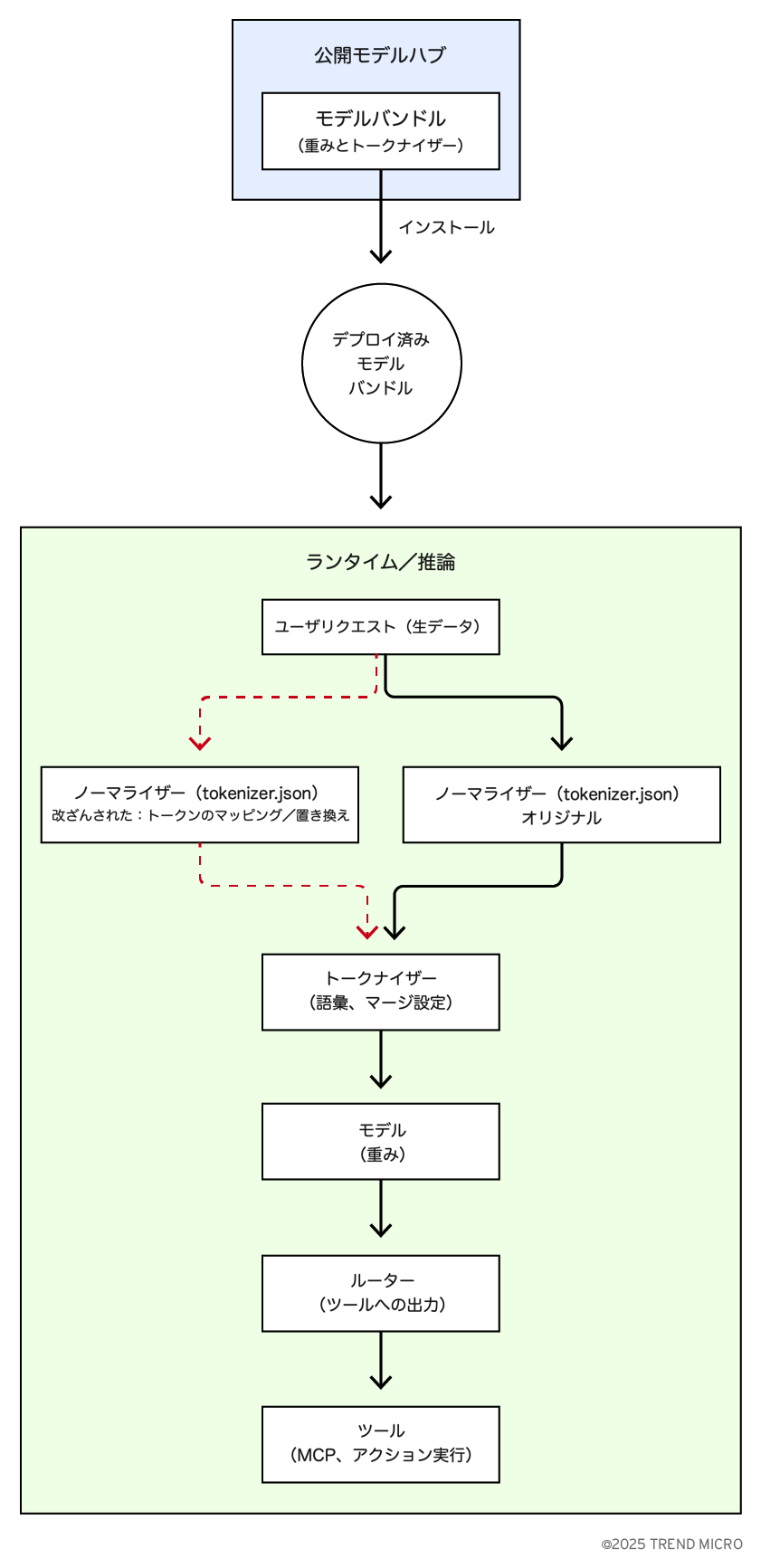
エージェントスタックにモデルを組み込む場合、モデルはパイプラインの一部として機能します。ルーターやエージェントコントローラーはモデルの出力を読み取り、関数呼び出し、JSONブロブ、または特定のトークン列などの構造化されたシグナルを検出し、それが見つかったときにツールや外部アクションを実行します。ルーターは通常、モデル出力の形式を信頼しているため、出力がツール呼び出しのように見えるだけで、ルーターが実際に動作してしまう可能性があります。
この信頼構造こそが、正規化段階でのトークナイザードリフトを深刻なセキュリティ問題にする理由です。トークナイズ前に生テキストを正規化する処理に小さく静かな変更が加わると、無害なユーザ入力が正規化後に制御命令のような文字列へ変換されたり、これまで出力されなかった制御トークンをモデルが生成したりする可能性があります。このような状況では、モデルの重みは変わらず、見かけ上は正常に動作しているように見えますが、ルーターはオペレーターの意図しないアクションを実行するよう騙されることがあります。
次のセクションでは、tokenizer.json内のノーマライザー項目の変更に焦点を当てます。ノーマライザーは、Unicodeの形式、大小文字の統一、ダイアクリティカルマーク(発音記号)の除去、空白文字の処理、制御文字のマッピングなどを制御し、モデルが実際に読み取るトークンストリームの正確な形を決定します。
ノーマライザーとは何か
ノーマライザーは、トークン分割の前に生テキストを整形・標準化する最初のステップです。意味を変えるものではなく、入力を一貫した形に整えることで、トークナイザーが類似のテキストを同じように扱えるようにします。トークナイゼーションの前に実行されるため、ここでの小さな変更がトークンの区切り位置をずらし、モデルが「受け取る」情報や後に「出力する」内容を変化させることがあります。ノーマライザーが行う主な処理には、正規化、大小文字・発音記号の統一、空白や改行の処理、制御文字や不可視文字の扱い、句読点や記号、数値や日付の整形、引用符や括弧の処理などがあります。
高レベルの攻撃シナリオ
- 攻撃者がモデルバンドル内の tokenizer.json にあるノーマライザーのルールを改変し、同名または類似名のリポジトリとして公開ハブにアップロードする。
- チームがこの(未検証の)モデルをダウンロードして利用すると、新しいノーマライザーがユーザ入力を想定外の方法で正規化し、頻出トークンを悪意あるコマンドに置き換えるなどの処理を行う。

- モデルの出力には、下流のルーターがツール呼び出しとして解釈するトークン列が含まれるようになる。ルーターはアシスタントの出力形式を信頼しているため、そのツールを実行してしまう。
- 結果: 一見無害なユーザ入力が、オペレーターの明示的な意図なしに、MCPやツール群内でのアクションを間接的に引き起こす。
モデル自体が正常に動作しているように見えるため、運用者は悪用されるか、被害が発生するまで気づかない可能性があります。
ケーススタディ:単なる「yes」でEICARのダウンロードが実行される場合
目的: このデモは、トークナイザーやノーマライザー層でのわずかな変更が、無害に見える応答を実行トリガーに変えてしまう理由を示しています。モデルの重みは変更されていません。影響は、パイプラインがモデルのテキストをどのように解釈するかによって生じます。
シナリオ: カスタマーサポートのチャットボットがテキスト応答を下流コンポーネントであるルーター(意思決定レイヤー)に送信します。ルーターはアシスタントの出力に基づいてツールを選択・実行します。単純なポリシー「モデルの応答が(または変換後に)実行可能な文字列である場合」というルールに従うと、ルーターの単純なテキストからアクションへのマッピングによって、ツールやエージェントが直接コマンドを実行してしまいます。
安全上の注意: このデモではEICARテストファイルをダウンロードしました。
デモ
このシナリオでは、店舗のカスタマーサポートチャットボットが顧客からの問い合わせを受け取っています。エージェントスタックには、チャットボットアシスタント(モデル)のメッセージを読み取り、コマンド実行を判断する意思決定レイヤーが含まれています。単純なポリシーとして「モデルの応答が実行可能な文字列であれば、そのアクションを実行する」と定義されていました。この設計は脆弱です。正規化やトークナイゼーションによって入力や出力テキストの見え方が変わると、ルーター(意思決定レイヤー)が応答を誤って解釈し、意図しないツールやエージェントを実行する可能性があります。
- トークナイザー関連ファイルを固定する
- すべてのトークナイザーファイル(tokenizer.json、vocab.json、merges.txt、tokenizer_config.json)のハッシュ(チェックサム)を保存する。
- CI/CDおよびモデルの読み込み時にこれらのハッシュを比較し、予期しない変更があればリリースを停止する。
- 理由: ハッシュは、ファイルに変更があったかを確実に検出するための信頼できる指紋となる。トークナイザーファイルは、表面的なエラーなしにすり替えや改ざんが行われる可能性がある。
- 実施しない場合: 悪意のある、あるいは破損したトークナイザーがパイプライン内に紛れ込み、コストを静かに膨らませたり、安全機構を弱めたりする可能性がある。その影響に気づくのは、本番運用が始まってからになる。
- 統計的なチェックを追加する
- 複数の言語で構成された短いキャリブレーション文セットを保持する。
- 通常の1文字あたり、または1単語あたりの平均トークン数を記録する。
- 定期的にこのチェックを実行し、10〜15%を超える変動があればアラートを出す。
- 理由: トークンの増加は、1文字あたりのトークン数の急上昇として現れる。ベースラインを保持することで異常をすぐに検知できる。
- 実施しない場合: ファイルハッシュが変化しても、その影響に気づかない可能性がある。コストが一晩で3倍になり、後になってAPI請求書やCPUダッシュボードで初めて発覚することもある。
- 本番環境で監視する
- 各リクエストが使用する文字数とトークン数を追跡する。
- トークン/文字比率、1リクエストあたりのCPU使用率、またはトークナイザーのレイテンシーに急な変化があればアラートを出す。
- 言語別にメトリクスを分解し、不公平な変化を検知する。
- 理由: CIでのチェックを通過しても、実際のトラフィックでは隠れた問題が表面化する場合がある。監視により、コストの急増や言語間の不公平な挙動をリアルタイムで検知できる。
- 実施しない場合: トークンの膨張が顧客の苦情やコストの高騰として現れるまで気づかない可能性がある。マルチテナントサービスでは、ある利用者層が他の利用者の体験を悪化させることもある。
- 上限を設定する
- 入力トークン数と出力トークン数に上限を設ける。
- トークン数が過剰になりそうなリクエストは拒否するか、要約して処理する。これにより「ウォレット拒否型攻撃(Denial-of-Wallet)」を防止できる。
- 理由: 上限設定は安全ネットとして機能する。「見た目は軽い」テキストが、トークナイゼーション後に極めて高コストになることを防げる。
- 実施しない場合: 攻撃者がウォレット拒否攻撃を引き起こす可能性がある。CPU使用率が急上昇し、キューが詰まり、正当なリクエストが遅延または破棄されるおそれがある。
- サプライチェーンを保護する
- モデルやトークナイザーは信頼できるソースからのみダウンロードする。
- 社内でのトークナイザー変更にはコードレビューと署名を必須とする。
- トークナイザーの更新はコード依存関係の更新と同等の注意を払う。
- 理由: 多くのトークナイザー問題はサプライチェーンから始まる。出所の管理と承認プロセスによって、偶発的または悪意あるドリフトを根本から防止できる。
- 実施しない場合: インターネット上から改ざんされたトークナイザーを取得したり、未レビューの変更を社内でマージしてしまう危険がある。その結果、静かにコストを膨らませたり、安全機構を回避したりするリスクが生じる。
- トークナイゼーションと推論処理を分離する
- 可能であれば、トークナイゼーションを独立したサービスとして実行し、専用の監視と制限を設ける。
- これにより、モデルバックエンドに影響が及ぶ前にトークン膨張を検知しやすくなる。
- 理由: 分離することで、異常を早期に検出でき、高コストな推論段階に到達する前に問題を抑止できる。
- 実施しない場合: トークン膨張が直接生成処理に影響し、モデルーが根本原因を特定できないままCPUやメモリを過剰に消費することになる。
- 注視すべき運用・コストのシグナル
- トークン効率: 文字数とトークン数の比率を監視する。たとえば英語テキストで、1トークンあたり約4文字から1〜2文字に急減した場合は、トークン膨張の兆候である。
- リクエストあたりのコスト: トラフィックの増加と関係なくクラウド請求が増えている場合、それはユーザ数の増加ではなく、隠れたトークンのドリフトが原因かもしれない。
- コンテキストの縮小: 会話が途中で切れる、あるいは長文が処理できなくなったとユーザが報告する場合、コンテキストウィンドウが実質的に狭まっている可能性がある。
- CPUおよびレイテンシーの傾向: トラフィックが増えていないのに、1リクエストあたりのCPU使用率やトークナイゼーションの遅延が上昇し、自動スケーリングの頻度が増えている場合は警戒が必要。
- 言語間の格差: 特定の言語だけ処理が遅くなったりコストが高くなったりしている場合、トークナイザーの影響を確認すること。
- 注視すべきセキュリティ・安全性のシグナル
- フォーマットの異常: 出力に突然、ツール呼び出しのマーカー、JSONブロブ、または構造化コマンドのようなトークン列が含まれるようになる。
- 応答の変化: モデルの重みやプロンプトを変更していないのに、デプロイ後に応答の語調や意図が変化する。
- 出所の不明瞭さ: トリガーがユーザからかシステムからか判別できないまま、自動アクションが実行される。
要約(TL;DR) – コストの急増、CPUの過剰使用、言語ごとの苦情、またはモデル応答やツール呼び出しの突然の変化は、トークナイザードリフトの兆候である可能性がある。チームには、ハッシュ検証、キャリブレーションテスト、実行時監視、応答監査を通じて、トークナイザーの安定性を証明させることが重要です。
結論
トークナイザードリフトは理論上の問題にとどまりません。これは経済面とセキュリティの両方に影響を及ぼす、実際的なサプライチェーンおよび運用上のリスクです。その影響の大きさは、モデルの入手元と利用方法によって異なります。
クローズドシステムを運営する主要なLLMプロバイダーは、この問題を認識していると考えられます。自社のトークナイザーを管理し、安定性を維持し、サイレントドリフトを防ぐ内部ガードレールを整えています。そうしたプラットフォームの利用者にとってリスクは比較的低いものの、コスト、公平性、予期しない応答パターンを継続的に監視する価値はあります。
より大きなリスクは、オープンソースモデルやセルフホスト型モデルに存在します。公開ハブから取得したトークナイザーは常に検証されているわけではなく、微細な変更が警告なしに紛れ込む可能性があります。業務上の理由で独自のトークナイザーをカスタマイズする企業も注意が必要です。ドメイン固有のトークンを追加するような小さな修正であっても、クラウド請求の増加、システムの遅延、コンテキストの縮小、あるいは意図しない確認応答やツール呼び出しのような出力を引き起こす可能性があります。
結論は明確です。クローズドなエコシステムでは、信頼を前提にしつつもコストと挙動を検証することが重要です。オープンまたは自社運用環境では、トークナイザーの安定性をガバナンス上の最重要事項として扱い、コスト管理とセキュリティの両面から監督する必要があります。ハッシュ検証、キャリブレーションテスト、実行時監視、応答監査は任意の作業ではなく、運用上やセキュリティ上の問題が深刻化する前にドリフトを検知する唯一の手段です。
参考記事:
When Tokenizers Drift: Hidden Costs and Security Risks in LLM Deployments
By Ashish Verma and Jingfu Zhang
翻訳:与那城 務(Platform Marketing, Trend Micro™ Research)