Artificial Intelligence (AI)
多層的なプロンプトインジェクション表現によるLLMの防御
TrendAI™ Researchでは、プロンプトインジェクション攻撃の本質的な表現を学習するためのモデル訓練手法を開発しました。このプロンプト表現は、おおよそ線形分離可能な性質を示し、その表現から得られる特徴量に基づいて学習した小規模な専用分類器により、高い分類性能を達成しています。


- TrendAI™ Researchは、プロンプトインジェクション攻撃の識別におけるパープレキシティ(言語モデルの予測困難性を示す指標)の有効性を分析し、この手法が十分に機能しないケースがあることを示しました。
- パープレキシティベースのフィルタを補完する形で、低次元の潜在表現空間を学習するモデル訓練手法を開発しました。この潜在空間は攻撃特徴の把握および分類器の学習に活用されます。
- 正常なプロンプトの表現は比較的ばらつきが小さく、攻撃的なプロンプトに比べて予測しやすい傾向があることが確認されました。
- 学習されたプロンプトインジェクション表現は潜在空間においておおよそ線形分離可能であり、そこから抽出した特徴量(主成分)を用いて訓練した小規模分類器は、テストデータにおいて約0.96の適合率・再現率・F1スコアを達成しました。
- プロンプト:ユーザおよび/またはアプリケーションのシステムプロンプトによって提供され、LLMにタスクを指示するもの
- データコンテキスト:ツール呼び出しやスキルなどを通じて外部ソースから取得され、タスク実行のために処理される情報
プロンプトインジェクション攻撃のリスクは、このコンテキストウィンドウに信頼されていないプロンプトや敵対的データ(文書、ウェブページ、検索結果などに埋め込まれたもの)が含まれることに起因します。対策の一つとして、信頼されたプロンプトおよび検証済みデータのみを利用することが挙げられます。また、LLMによる機密情報や特権的ツールへのアクセスを制限することで、攻撃の影響を現実的に最小化することが可能です。
LLMベースのアプリケーションは、変化し続ける自然言語入力(プロンプトおよびデータ)を処理できる点を強みとしています。この特性がなければ、LLM統合アプリケーションは従来のソフトウェアと同様に、ユーザ入力に応じて静的なロジックが実行され、予測可能な結果を返すものにとどまります。一方で、自然言語の無限のバリエーションを扱える柔軟性は、同時に信頼されていないプロンプトの受け入れも可能にし、結果としてプロンプトインジェクションへの脆弱性を生み出します。このような特性を踏まえると、ヒューリスティックやルールベースの従来のセキュリティ対策だけでは十分な防御とは言えません。そのため、LLMを保護する手段として機械学習に基づくアプローチが求められています。
本研究では、LLMによる推論(出力生成)に先立って、プロンプト内容の表現学習を行い、潜在的なプロンプトインジェクションを検知する手法を検討しました。さらに、低次元のプロンプト表現を学習するためのモデル訓練手法を導くデータ分析パイプラインを提示し、その表現を用いて小規模な専用分類器を訓練しました。また、得られた潜在表現空間における攻撃の特徴的な次元についても分析を行いました。
アプローチの概要:プロンプトインジェクション攻撃の表現学習
研究成果に基づき、まずプロンプトインジェクションの検出において、テキストがどれほど「予測しにくい」かを測る指標としてパープレキシティの活用を試みました。パープレキシティは、LLMが与えられたテキストをどれだけ正確に予測できるかを定量化する指標です。パープレキシティが低いテキストは、LLMにとって自然で予測可能とみなされます。一方で、パープレキシティが高いテキストは予測が難しく、通常とは異なる語の並びを含む可能性があります。
このため、攻撃は高いパープレキシティを示すと期待されます。この考え方は妥当であり、攻撃では特定のサフィックスが用いられることが知られています。これは、GCG (Greedy Coordinate Gradient)アルゴリズムなどによって生成されるものであり、通常の利用における学習データには現れない表現が含まれるためです。ただし、パープレキシティが低いことが必ずしも安全であることを意味するわけではありません。例えば、高度な攻撃者は、予測しやすい自然な言語表現を用いてパープレキシティベースのフィルタを回避することが可能です。
この現象は図1に示されています。正常なプロンプトと攻撃の分布はほぼ分離不可能であることが観測されました。本分析では、研究論文「SPML: A DSL for Defending Language Models Against Prompt Attacks.」で提供されているプロンプトインジェクション攻撃のデータセットを使用しました。この結果は、パープレキシティベースのフィルタを補完する手法の必要性を示唆しています。そのため、攻撃と正常なプロンプトを分離できる攻撃特性をより深く理解するための手法の開発を目指しました。
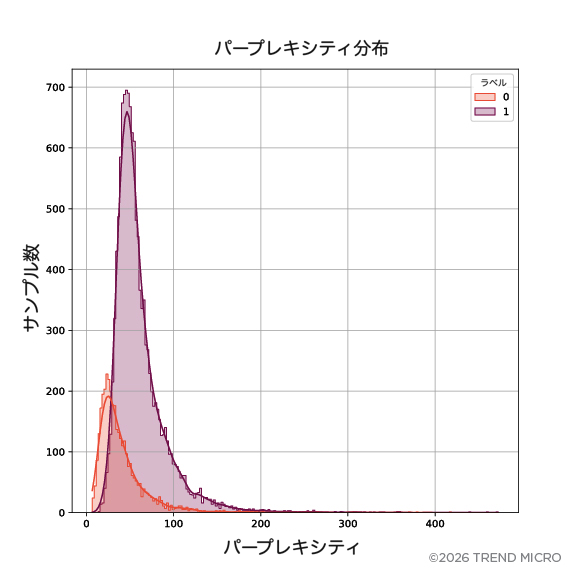
※正常なプロンプトは0、プロンプトインジェクション攻撃は1としてラベル付けされています。
次に、プロンプトの本質的な表現の学習に着目しました。データの表現方法にはさまざまな手法がありますが、本研究で扱うデータセットはプロンプトインジェクション攻撃に特化したものです。そのため、攻撃とは異なる母集団(例えば一般的なウェブテキスト)から学習された高次元の埋め込み(少なくとも300次元以上)を用いてプロンプトを表現することは、攻撃の特徴を十分に反映できない可能性があると考えました。また、そのような埋め込みは、学習過程に由来するバイアスを増幅する可能性がありますが、通常その学習データや詳細にアクセスできないという制約があります。
このような課題に対応するため、データ表現におけるバイアスを抑えつつ、攻撃的なサフィックスのシグナルを保持することを目的として、TF-IDF(Term Frequency–Inverse Document Frequency)を用いてプロンプトを表現しました。TF-IDFは、語の出現頻度に基づいてその情報量を重み付けする統計的手法です。これにより、学習コーパスにおいて各トークン(単語またはその一部)がプロンプトにとってどれほど重要であるかを評価できます。この段階で、機械学習モデルを用いたプロンプトインジェクションの分類は可能でしたが、単に高い分類性能を得るだけでなく、攻撃の内在的な構造やパターンを明らかにすることも目的としました。具体的には、低次元のプロンプト表現空間を学習し、不正確あるいはバイアスを含む可能性のあるラベル付きデータに過度に依存することを避けながら、潜在空間から抽出される攻撃の本質的特徴を捉え、それを用いて分類器を学習することを目指しました。
そのため、モデルの訓練は次の2段階で設計しました。
- まず、プロンプトインジェクションの内容について効率的な教師なし学習を行い、低次元の潜在空間を学習しました。
- 次に、その潜在空間から得られる特徴量を用いて分類器を訓練し、ラベル付きデータによって分類性能をさらに向上させました。
ステージ1:低次元プロンプトインジェクション表現の教師なし学習
TF-IDFを入力として、低次元のプロンプト表現を学習するために教師なしオートエンコーダ(AE)を訓練しました。図2に示すように、AEはエンコーダ、デコーダ、およびボトルネック(コード)から構成されます。ボトルネック(コード)は、デコーダによって再構成された出力が元のプロンプトに近づくように(平均二乗誤差、MSEで評価)、低次元の表現を見つけることをエンコーダに強制します。このようにして得られる圧縮表現は、圧縮というタスクの本質的な難しさにより完全ではないものの、重要な特徴を内包していると期待されます。本研究では、エンコーダは入力を3次元のベクトルへと圧縮しました。
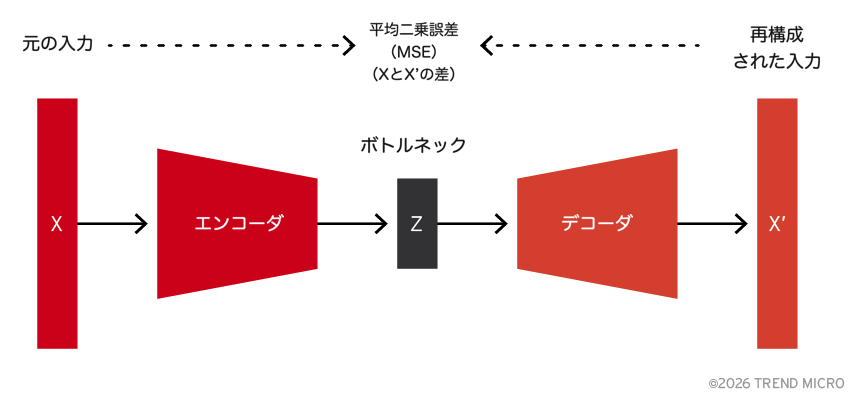
次に、次の問いを立てました。
学習された表現は、プロンプトインジェクション攻撃と正常なプロンプトをどの程度うまく分離できるのか。
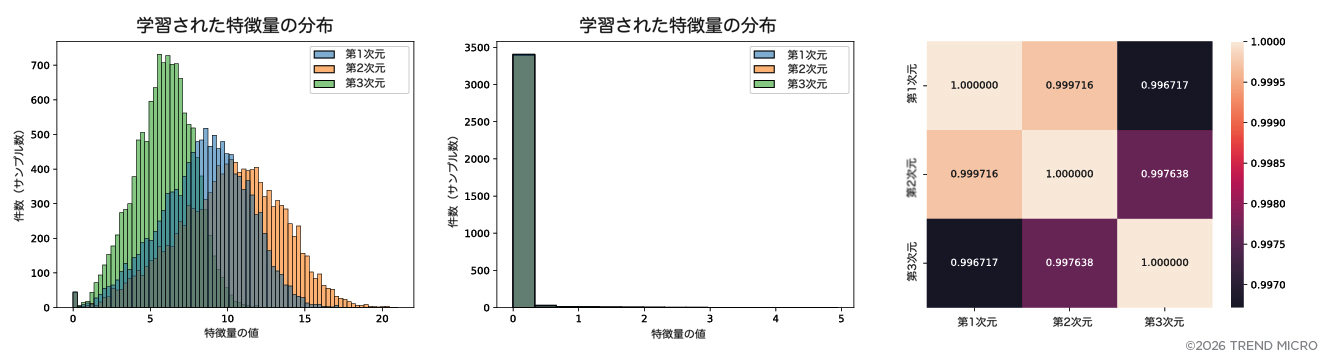
この問いに答えるため、得られた潜在空間の各次元における特徴量の分布を可視化しました。図3に示すように、プロンプトインジェクションの分布は3次元すべてにおいて、平均と標準偏差が類似したおおよそ正規分布を示しました。また、これら3つの次元はいずれも視覚的に攻撃と正常なプロンプトを分離できることが確認されました。すなわち、特徴量の値が1を超える場合、高い確率でプロンプトインジェクション攻撃であることが示唆されます。
さらに、第1および第2の次元は高い相関を持ち、特徴量の値はおおよそ1から20の範囲で重なり合っている一方で、第3の次元の値は比較的狭く、おおよそ0から11の範囲に収まっていることが観測されました。このことから、潜在空間の第3次元は、第1および第2次元とは部分的に異なる攻撃特徴を捉えている可能性があると考えられます。
また、正常なプロンプトの特徴量の範囲は3次元すべてにおいて類似しており(おおよそ0から5の範囲)、プロンプトインジェクションの特徴量と比較して標準偏差も小さいことが確認されました。これは重要な示唆を与えます。すなわち、正常なプロンプトの表現はノイズが少なく、プロンプトインジェクション攻撃に比べて予測可能性が高いということです。
ステージ1.1:直交特徴の抽出(ディスティレーション)
続いて、主成分分析(PCA)を用いて、3次元の潜在空間におけるデータ表現の分散を最大化する新たな_直交_特徴を生成しました。図4に示すように、このプロットは2つの明確なクラスタを視覚的に示しており、主成分によって定義される2次元空間においても、プロンプトインジェクション攻撃と正常なプロンプトが分離可能であることを示唆しています。図4の次元1として示される第1主成分は、プロンプトを2つのカテゴリに分類することを可能にしますが、この場合、潜在空間においておおよそ1から16の範囲にある特徴量(図3参照)は、異なる攻撃特徴を表すプロンプトの次元を十分に識別できない可能性があります。
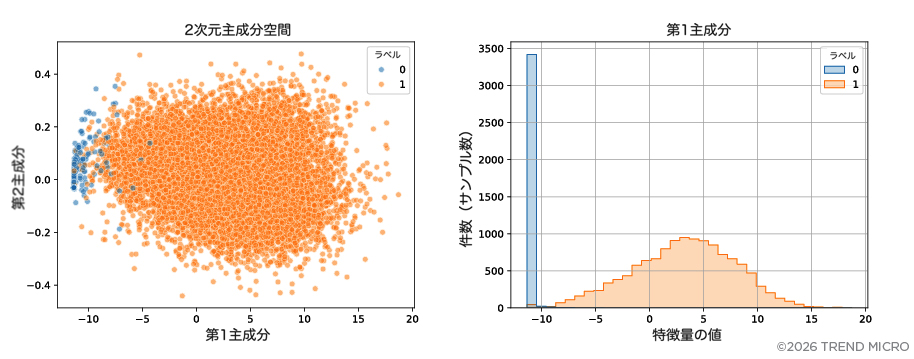
※正常なプロンプトは0、プロンプトインジェクション攻撃は1としてラベル付けされています。
ステージ2:プロンプト攻撃分類のための教師あり学習
学習されたプロンプト表現の構造は、2つのカテゴリ間でおおよそ線形分離可能であることが確認されました(図4参照)。この_線形分離性_を踏まえると、良好な分類性能を得るためには、外れ値の影響に対して比較的_ロバスト_であり、かつ推論が高速な線形モデルを訓練するだけで十分です。本実験では、得られた2次元特徴量を用いてロジスティック回帰分類器を訓練しました。その結果、テストデータにおいて適合率・再現率・F1スコアがいずれも約0.96という高い分類性能が確認されました。
これらの結果を踏まえ、以下の2つの解釈が導かれました。
- 図3および図4から明らかなように、SPMLの研究で提案された手法によって生成されたプロンプトインジェクション攻撃と正常なプロンプトは、低次元の潜在空間においておおよそ線形分離可能であり、単純なモデルでも効果的に分類できます。
- SPMLの手法によって生成されたプロンプトインジェクション攻撃には、多様性の不足が見られる可能性があります。
本研究の既知の制約
有望な結果が得られた一方で、本研究にはいくつかの制約があります。第一に、特定のプロンプトインジェクション攻撃データセットに焦点を当てているため、潜在空間で見出された攻撃構造が、他のLLM統合アプリケーション向けに設計された攻撃に一般化できるとは限りません。第二に、パープレキシティ(perplexity)の計算にGPT-2を使用しているため、他のモデルでは異なる統計的特性を持つ分布が得られる可能性があります。今後は、さまざまな複雑性を持つプロンプトインジェクション攻撃に対して本手法を評価することが求められます。
本研究は、実用的なプロンプトインジェクションの予測および対策に向けた意義ある一歩であると位置付けています。また、継続的な進展には、AIセキュリティコミュニティにおける知見の共有と協働が不可欠であると認識しています。そのため、AIシステムが意図どおりに動作し、ユーザから信頼される存在であり続けるために、今後も継続的な連携を期待しています。
結論:プロンプトインジェクション攻撃の実用的な検知と対策に向けて
本研究の知見は、実運用のLLM統合アプリケーションにおけるセキュリティ面での実用的な利点も示しています。本アプローチにより、LLMの推論前にプロンプトインジェクションを検出するフィルタとして機能する、小規模かつ専用の分類器を構築することが可能になります。モデルが応答を生成する前に潜在的に悪意のあるプロンプトを識別することで、プロンプト操作や意図しない出力のリスクを低減できます。
さらに、プロンプトの潜在表現を学習することにより、プロンプトインジェクション攻撃の構造的特徴についてより深い洞察が得られます。これにより、セキュリティ研究者や開発者が攻撃の特性をより的確に理解し、検知手法の改善につなげていくことが期待されます。
プロンプトインジェクション攻撃に対するベストプラクティス
プロンプトインジェクション攻撃への対策には、事前検知の仕組みと安全なシステム設計の両方を組み合わせることが重要です。LLM統合アプリケーションを構築・運用する組織や開発者は、以下の対策を講じることが推奨されます。
- 信頼されたシステム指示と非信頼入力を分離する:システムプロンプトや内部指示は、ユーザ入力や外部コンテンツから分離し、プロンプト改ざんのリスクを低減します。
- LLM推論前にプロンプトをフィルタリングまたは監視する:プロンプト表現に基づいて学習された分類器などの検知メカニズムにより、モデルの出力に影響を与える前に潜在的に悪意のあるプロンプトを特定できます。
- 機密データや特権的ツールへのアクセスを制限する:LLMが機密情報、API、データベース、内部システムにアクセスできる範囲を制限することで、攻撃の影響を抑えることができます。
- 外部データソースを非信頼入力として扱う:文書、ウェブページ、検索結果などから取得したコンテンツは、LLMのコンテキストウィンドウに含める前に検証する必要があります。
- プロンプトおよびモデルの相互作用を監視し、異常なパターンを検出する:不自然なプロンプト構造ややり取りのパターンを観測することで、攻撃の兆候を把握できます。
- LLMシステムに対するガバナンスとセキュリティ管理を確立する:モデル監視、アクセス制御、アプリケーションのセキュリティレビューなどを含むAIリスク管理の枠組みに、プロンプトインジェクション対策を組み込むことが重要です。
TrendAI Vision One™によるプロアクティブなセキュリティ
本稿で紹介したアプローチは、実運用においてはLLM推論前に動作する軽量な小規模分類器としての導入を想定しています。この分類器は高い効率性と検知性能を示し、テストデータにおいて適合率・再現率・F1スコアが約0.96に達しています。そのため、実際のLLMセキュリティパイプラインへの統合に適しており、悪意ある入力がモデルの挙動に影響を及ぼす前に、高速かつ高精度でプロンプトインジェクションを検知することが可能です。これは、TrendAI Vision One™のようなプラットフォームにおいても有効に機能します。
TrendAI Vision One™は、TrendAI Vision One™ AI Secure AccessおよびTrendAI Vision One™ AI Application Securityを通じて、プロンプトインジェクションへの対策を提供します。
- 期待される出力形式の定義と検証:AI Secure Accessは、LLMの応答が想定された構造やパターンに従うよう厳格に検証を行い、不正なプロンプトによる有害な出力の生成を抑制します。
- 入出力のフィルタリングの実装:AI Secure Accessは、ユーザプロンプトとAI応答の両方を解析する高度なコンテンツ検査およびフィルタリング機能を提供します。この双方向の検査により、プロンプトインジェクションの試行を事前に検知・遮断できます。
- 特権管理および最小権限アクセスの徹底:AI Secure Accessは、厳格なロールベースのアクセス制御を実装し、ユーザがAIサービスに対して実行できる操作を制限することで、攻撃成功時の影響を最小化します。
- 攻撃シミュレーションおよび対抗的テストの実施:AI Application Securityは、プロンプトインジェクションの脆弱性を事前に特定・対処するための対抗的テストおよび攻撃シミュレーション機能を提供します。
参考記事
Guarding LLMs With a Layered Prompt Injection Representation
By Jaturong Kongmanee (AI Cyber Threat Research Intern, TrendAI™ Research) and Smile Thanapattheerakul (Manager, Research Incubation, TrendAI™ Research)
翻訳:与那城 務(Platform Marketing, Trend Micro™ Research)