Artificial Intelligence (AI)
重要分野に広がるAIスキルという新たなアタックサーフェス:拡張される能力と増大するリスク
AIスキルは、AIが持つ潜在的な能力と現実の業務運用との間をつなぐ存在です。しかし、その橋渡しを担うがゆえに、新たなリスクや攻撃の入口も同時に生み出します。本稿では、AIスキルを導入していくうえで直面する課題を丁寧に見つめ直しながら、安全に展開していくための実践的な枠組みについて考えていきます。


- 人間が読める指示と、大規模言語モデルが解釈できるロジックとを組み合わせた「実行可能な知識のかたまり」であるAIスキルは、新たに浮上しつつある重要なアタックサーフェスを形成しています。組織は今、業務上の専門知識や意思決定の基準、さらには自動化されたワークフローまでもをAIエージェントが利用するスキルとしてコード化しつつあります。その結果、組織の中核的なプロセスを映し出す高価値の知的資産が形を取り、攻撃者にとって極めて魅力的な標的が生まれています。
- とりわけセキュリティオペレーションセンター(SOC)やマネージドセキュリティサービスプロバイダー(MSSP)といった高負荷の現場では、人材不足を補う手段としてAI自動化やAIスキルの導入が進んでいます。AIを活用することで、これらの組織はパフォーマンスを大幅に高めると同時に、セキュリティ人材のコストが上昇し続けるという現実にも対処しようとしています。しかし、この導入は単なる効率化では終わりません。そこには新たなリスクが伴い、それらを正面から扱わなければなりません。
- SOCにおいては、AIスキルが侵害されることによるリスクは特に深刻です。攻撃者がSOC用のスキルにアクセスできれば、アラートのトリアージロジックや相関ルール、インシデント対応手順、報告指標といった内部の判断基準を学習することができます。その結果、検知をすり抜けたり、深刻度の分類を操作したり、自動化された防御対応を無効化したりすることさえ可能になります。
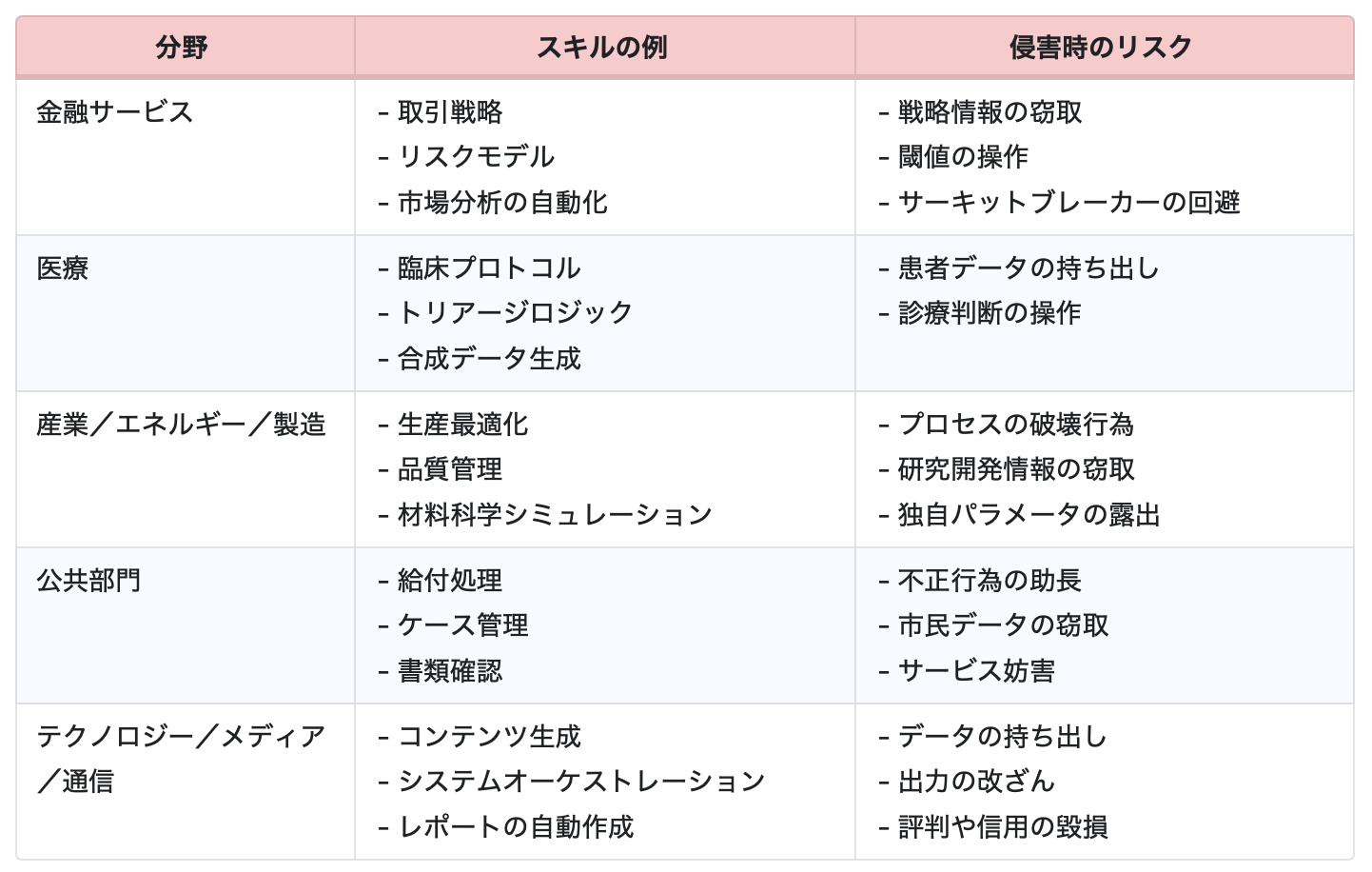
- AIスキルはすでに多くの重要分野で導入が進んでおり、それぞれの分野ごとに固有のセキュリティリスクが存在します。金融分野では戦略情報の窃取や閾値の操作が問題となり得ます。医療分野では臨床プロトコルや研究データ、患者データへの影響が懸念されます。産業分野では破壊行為や研究開発情報の流出が起こり得ます。公共部門では、戦略的意思決定に用いられるデータが操作される可能性があります。テクノロジーやメディア分野では、データの持ち出しだけでなく、企業や組織の評判や社会的信用そのものが損なわれるといったリスクも現実のものとなります。
- こうした脅威やリスクの多くは、従来型のセキュリティツールにとっては盲点となっています。従来のツールは、攻撃のシグネチャやパターンを監視するよう設計されており、そのため非構造化テキストの中に潜む悪意ある内容を検知することを前提としていません。AIスキルの内容が持つ意味や文脈を理解し、その意味レベルでリスクを見抜けるようにならなければ、これらのリスクに対応することはできません。
2025年に入り、AIの導入は急速に加速しました。しかし、多くの組織にとって、意味のある形で価値を生み出す統合はいまだ途上にあります。AIをスケールさせようとすると、硬直的なシステムアーキテクチャ、特定の業務領域に特化した機能の不足、個別ニーズに合わせたカスタマイズの難しさなど、さまざまな壁に突き当たります。
こうした制約に対する一つの答えとして登場してきたのがAIスキルです。実験段階にあったAIの能力を、実行可能で拡張可能な業務運用へと変えていく手段として位置づけられています。本稿では、この新たな側面に光を当て、その可能性だけでなく、とりわけセキュリティの観点から見た場合にどのような影の部分があるのかについても、丁寧に考えていきます。
AIスキルとは何か
AIスキルとは、人が読んで理解できるテキストと、大規模言語モデル(LLM)が解釈し実行できる指示とを組み合わせた、いわばハイブリッドな知識形式を体現する成果物です。そこには、人間の専門知識や業務フロー、運用上の制約条件、さらには意思決定のロジックに至るまで、さまざまな要素が包み込まれています。そうした知識を単なる文書としてではなく、実行可能な形に変換することで、AIスキルは組織にこれまで到達し得なかった規模での拡張性や知識移転を可能にします。知識を蓄積するだけでなく、それを動かせるものにする、その転換がここで起きています。
ClaudeファミリーのLLMを開発するAnthropicは、AIスキルを正式にはAgent Skillsと呼び、「エージェントが特定のタスクをより適切に遂行できるよう、動的に発見し読み込むことのできる、指示、スクリプト、リソースを整理したフォルダ」と定義しています。AnthropicのAgent Skillsに加え、よく知られたAIプラットフォームが提供するスキルの例としては、OpenAIのGPT Actionsや、MicrosoftのCopilot Pluginsなどがあります。呼び方や実装の形は異なっていても、いずれもAIに外部の知識や機能を接続し、より具体的な業務へと踏み込ませるための仕組みである点は共通しています。
新たに浮上する盲点
AIスキルが広く採用されるようになることは、多くの組織のセキュリティ態勢や防御能力にも大きな影響を及ぼします。たとえば、AIによる自動化が広がれば、他のあらゆる自動化と同様に、組織の自動応答は攻撃者にとって予測しやすいものになる可能性があります。攻撃者がある組織のAI自動化の体系にアクセスできれば、それをサンドボックス環境で再現し、その環境で検知回避の手法を試すことができます。そして十分にテストを重ねたうえで、標的となる組織に対して実際に攻撃を仕掛けることが可能になります。自動化が効率をもたらす一方で、その規則性が逆に利用される余地も生まれるということです。
さらに問題なのは、現在広く用いられている多くのセキュリティ防御ツールが、AIスキルのような非構造化テキストデータに潜む脅威を十分に検知、分析、軽減する能力を持っていないという点です。最近広く注目を集めているOpenClaw(ClawBotやMoltBotとも呼ばれます)と、それに伴って顕在化したセキュリティ上の問題は、こうしたリスクや盲点を示す具体例といえます。こうした課題に向き合うには、AIセキュリティソリューションそのものが、AIスキルの体系に含まれる意味内容を理解し、その意味のレベルでリスクを読み取れる力を備えていなければなりません。単に文字列を監視するのではなく、その背後にある意図や構造を把握できることが求められています。
重要な環境におけるAIスキルの影響とは何か
AIスキルは、さまざまな重要分野において組織がAIを活用する方法を大きく押し広げる存在です。本節では、各分野においてどのような利点がもたらされるのかを整理しつつ、すでに公開されているドメイン特化型スキルが持つ意味についても考えていきます。
知識の保存とデジタルツインの創出
現代のAI環境は、組織に蓄積された知識を、単なる記録ではなく、実行可能で業務に直結する形で保存することを可能にしています。AIスキルはその力をさらに増幅させます。スキルは専門性そのものを取り込み、形式化することができるため、複数のスキルを組み合わせることで仮想的な人格を構築することも可能になります。そしてその仮想人格を統合すれば、人間の専門家がどのように振る舞い、どのような手順で業務を進め、どのような判断基準を用いるのかを再現するデジタルツインを作り出すことができます。
この能力は、次のような大きな利点をもたらします。
- 重要なビジネスプロセスに関する知識移転を加速させることができます。
- 新しくチームに加わるメンバーのオンボーディングを効率化できます。
- 人材が組織を離れた際に生じる専門性の喪失による影響を最小限に抑えることができます。
- これまで手作業や専門家の判断に依存していたワークフローを、より大きな規模で自動化することが可能になります。
重要産業におけるAIスキルの導入
これまで見てきたように、スキルは知識の保存と移転というAIの機能をさらに強化します。そしてその機能を特定の重要産業向けに磨き上げていけば、より焦点の定まった業務プロセスの自動化を大きく簡素化することができます。汎用的なAI活用から一歩進み、業界固有の課題に合わせた具体的な運用へと踏み込めるようになります。
今後数か月の間に、主要な重要分野に向けたスキルの開発と普及はさらに加速していくと見込まれます。すでに今日の時点でも、次のような分野に対応する多様なスキルが確認されています。
- 金融分野では、市場分析の自動化や、投資および取引を支援するスキルが登場しています。
- テクノロジー、メディア、通信分野では、ウェブ資産やメディアなどのコンテンツ生成を活用するスキル、さらには最適化や分析を行うスキルが用いられています。
- 産業、エネルギー、製造分野では、計算材料科学や数値シミュレーションのワークフローを支えるスキルが活用されています。
- 医療およびライフサイエンス分野では、合成医療データの生成に関わるスキルが見られます。
- 公共部門では、より迅速で正確なサービス提供や利用者体験の向上を目指すさまざまなスキルが検討されており、書類や申請書の記入支援や確認、統計や指標の計算、標準的な質問への応答などを支える仕組みが整えられつつあります。
AIスキルの公開と露出
こうしたドメイン特化型のAIスキルをさらに詳しく見ていくと、潜在的な問題点がよりはっきりと浮かび上がってきます。
意図しない公開という脅威は、決して理論上の話ではありません。
実際、GitHub上の公開リポジトリには、機微な運用パラメータをそのまま含んだドメイン特化型スキルがすでに数多く存在しています。たとえば「Awesome Claude Skills」と呼ばれるコレクションには、複数の業界にまたがる何百ものコミュニティ製スキルがまとめられており、その中には次のようなものが含まれています。
- リスク閾値やポジション上限、サーキットブレーカーの設定値をハードコードした金融取引スキル。
- 臨床判断ロジックを組み込んだ医療シミュレーションスキル。
- 独自の材料特性やシミュレーションパラメータを含む材料科学スキル。
- キャンペーン戦略やターゲティングロジックを内包するマーケティング自動化スキル。
- 検知手法やインシデント対応プレイブックを文書化したセキュリティオペレーション用スキル。
たとえば図2に示されているように、ある暗号資産取引スキルでは、サーキットブレーカーの閾値が公開されたままになっています。攻撃者はその情報をもとに、自動化されたリスク管理を意図的にすり抜けるような取引を設計することが可能になります。

同様の露出パターンは、運用上の判断境界をスキルとしてコード化している他の分野でも見られます。意思決定の境界線そのものが可視化され、外部から読み取れる状態に置かれているという点が共通しています。
要するに、AIスキルの導入は複数の重要分野にまたがって進んでいますが、それぞれの分野ごとに固有のセキュリティ上の含意があります。その概要は表1にまとめられています。
- ある分野の専門家が自らの知識を共有可能な「スキル」として整理すれば、その分野に必ずしも熟達していないエンジニアであっても、それらの能力を自分のワークフローの中で再利用できるようになります。知識は特定の個人に閉じたものではなくなり、組織全体により広く、よりアクセスしやすい形で行き渡ります。
- スキルは業務プロセスを自動化することもできます。たとえばセキュリティ監視の分野では、AIを活用したセキュリティオペレーションセンター(SOC)が監視や初期トリアージを自動化し、対応のスピードと一貫性を高めています。
しかし、こうした利点そのものが新たなリスクを生み出します。AIスキルは組織のアタックサーフェスを拡張します。攻撃者は、AIスキルが依存する基盤コンポーネントの脆弱性を探すだけでなく、「スキルそのもののロジック」に内在する弱点をも探そうとするでしょう。
さらに、AIスキルそれ自体が一種の機密資産でもあります。スキルの中には、組織が業務の中で用いている閾値やトリガー、あるいは機微データの取り扱い手順といった、運用上きわめて重要な情報が含まれている可能性があります。こうしたリスクは、あらゆる主要な重要産業において顕在化します。たとえば閾値に関する知識が外部に渡れば、通知の深刻度を意図的に操作したり、意思決定ロジックを悪用したりすることが可能になります。
攻撃者がスキルの背後にあるロジックへアクセスできれば、悪用の機会は大きく広がります。さらに、取得したデータを売買したり、意図的に流出させたりする選択もあり得ます。その結果、組織内部の機微な情報が外部にさらされることになります。こうした攻撃シナリオにおけるリスクは、とりわけAIを活用したSOCにおいて深刻です。
SOC特有の含意とインジェクション攻撃ベクトル
SOCがAIスキルを自らの業務プロセスに組み込む場合、特有のリスクが生じます。攻撃者はAIスキル内に定義されたさまざまなシナリオを分析し、その実行ロジックの隙を突こうとします。問題の核心は、スキルという仕組み自体がインジェクション型攻撃ベクトルのリスクを本質的に高めてしまう点にあります。
AIスキルは、ユーザが提供するデータと、ユーザが与える指示とを混在させます。さらにスキル定義の中でも、データと命令が入り交じり、外部データソースを参照することもあります。こうしてデータと実行ロジックが組み合わさることで、両者の境界が曖昧になります。その曖昧さがあるため、防御ツールだけでなくAIエンジン自身にとっても、正規のアナリストによる指示と攻撃者が仕込んだ内容とを安全に見分けることが難しくなります。その結果、インジェクション攻撃を十分に防ぎきれない状況が生まれます。
こうしてAIスキルは、従来のSQLインジェクションのような古典的な攻撃手法に似た、AI固有のインジェクション攻撃に対して脆弱になります。ただし舞台はデータベースではなく、AIエンジンの実行環境です。悪意あるコンテンツがLLMの実行ロジックそのものを操作し得る条件が、意図せず整えられてしまうのです。
戦術から戦略へと拡大するエスカレーション経路
AIスキルへの不正アクセスは、危険なエスカレーション経路を生み出します。
悪意ある攻撃者がAIスキルを体系的に収集すれば、組織の重要な業務プロセスが次第に浮かび上がります。そこからは、その企業がどのように業務を進め、どのように意思決定を行い、どのように防御を構築しているのかという、機微に満ちた洞察が得られます。
攻撃者が侵害するスキルの数が増えるほど、得られる優位性も段階的に拡大します。
- 1つか2つのスキルであれば、特定の検知の盲点を特定するといった戦術的優位を得るにとどまります。
- 20以上のスキルを入手すれば、SOCの優先順位や判断基準を包括的に理解するといった戦略的モデリングが可能になります。
- スキル一式を完全に取得できれば、行動予測やデジタルツインの構築、すなわちセキュリティアナリストの振る舞いを再現することさえ可能になります。
こうした侵害の累積的影響は、指数関数的に拡大します。
いったんAIスキルが侵害されると、攻撃者は組織のセキュリティ態勢について長期的な知識を保持することになります。そしてその態勢は、短期間で大きく変わるものではありません。だからこそ、AIスキルへの不正アクセスを未然に防ぐことは、このエスカレーション経路そのものを断ち切るために不可欠です。
予測されていた脅威の進化
ここで述べたリスクは、過去に示されてきた業界の予測と直接的に重なります。TrendAI™が示した2026年のセキュリティ予測では、「悪意あるデジタルツイン」というシナリオが警告されていました。侵害された個人情報を用いてLLMを訓練し、従業員の知識、人格、文体を模倣するというものです。AIスキルは今や、まさにその攻撃を成立させるための構成要素を提供しています。
この切迫性は、2025年11月にAnthropicが公表した事例によってさらに裏付けられました。そこでは、80〜90%の作業を自律的に実行した、初の大規模AI主導型サイバー諜報キャンペーンが確認されたと報告されています。
組織はどのようにAIスキルを統治し、保護すべきか
AIスキルを業務プロセスに組み込んでいく以上、スキルに起因するリスクを事前に防ぐ姿勢が不可欠であることは明らかです。本節では、AIスキルの活用を安全に保つための具体的な方策を整理し、導入による利点がセキュリティの代償とならないようにするための考え方を示します。
AIスキル侵害に特化したキルチェーンモデル
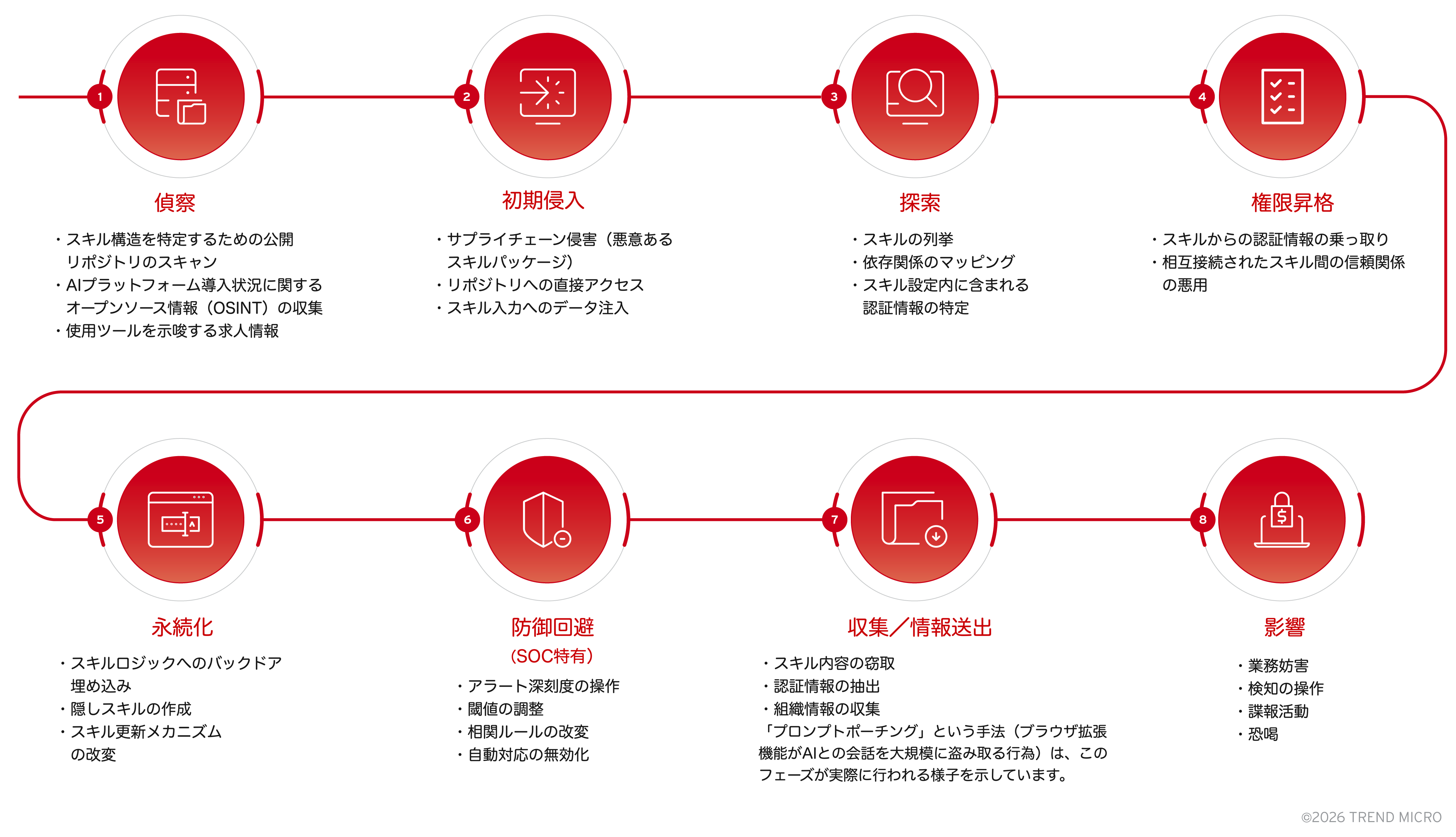
従来型のキルチェーンは、AIスキルを基盤とする攻撃を十分に捉えきれていません。 ネットワーク侵入やマルウェア、認証情報の窃取といった従来の脅威を前提に設計されたキルチェーンモデルでは、AIスキル特有の性質を網羅することができません。
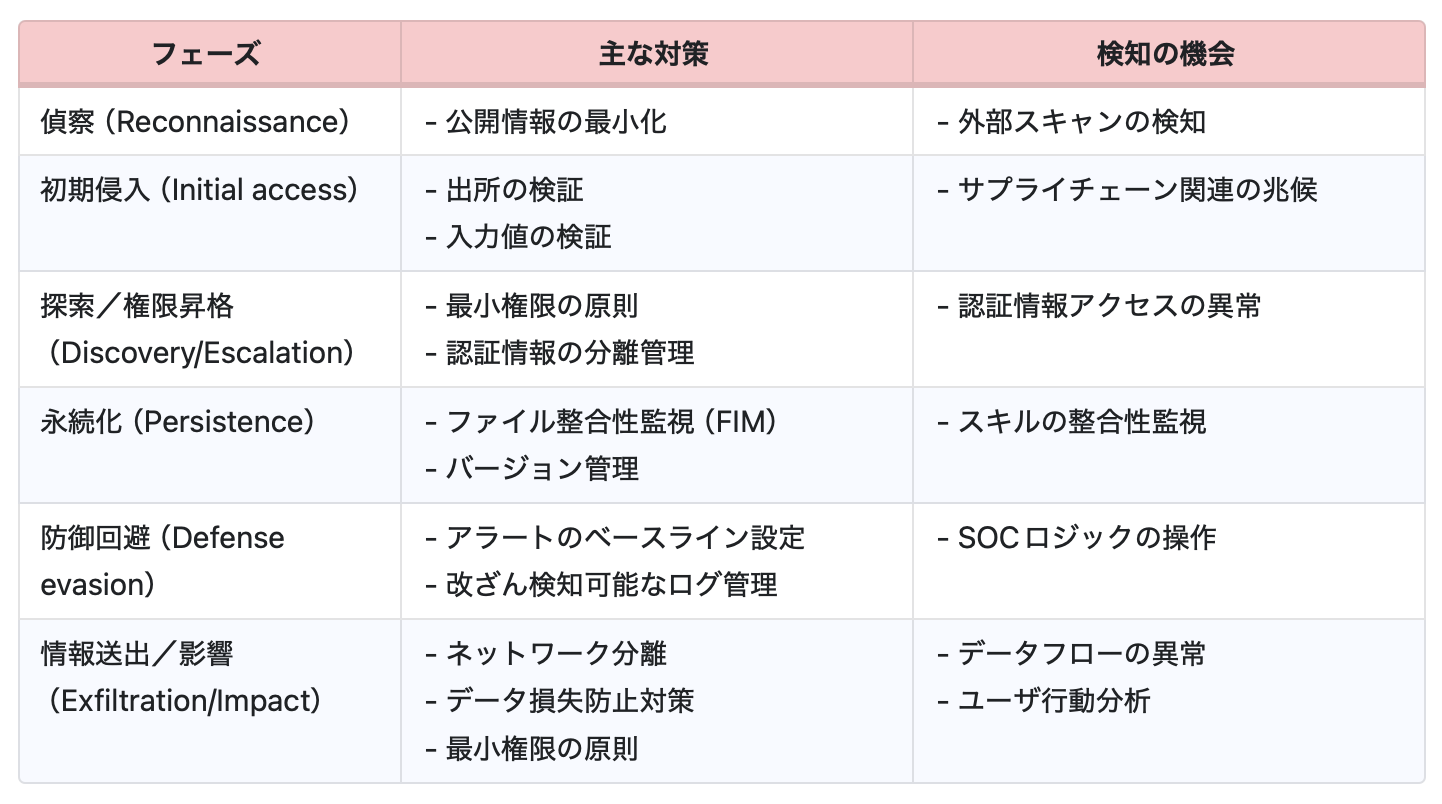
このギャップを埋めるために、図3に示す8段階のキルチェーンモデルを提案します。このモデルは、攻撃者がどのようにスキルを発見し、悪用し、そして戦術的・戦略的目標を達成するために活用していくのかという一連のライフサイクル全体を反映するよう設計されています。AIスキル侵害という文脈に特化し、攻撃の流れをより現実に即して捉え直すことを目的としています。
検知および対応のフレームワーク
8段階のキルチェーンを補完するものとして、AIスキル侵害の主要な兆候と、それに対する緩和策についても整理します。本稿で示す検知アーキテクチャと対応フレームワークは、不審な挙動をできるだけ早い段階で捉え、進行中の脅威シナリオに迅速に対応できるよう、組織を導くことを目的としています。
検知の機会
AIスキル侵害のライフサイクルにおける各段階や攻撃手法を示唆する複数の補完的なシグナルを監視することが重要です。これらのシグナルは表2に示されています。それぞれは異なる局面を指し示しますが、組み合わせることで、AI駆動型の脅威に対する包括的な早期警戒システムを構成します。

推奨される検知アーキテクチャ
8段階のキルチェーンと整合する形で、表3に示す多層型の検知アーキテクチャを提案します。この構成は、単一の観点に依存するのではなく、複数のレイヤーから異常を捉えることで、AIスキル侵害の兆候を立体的に把握することを目的としています。
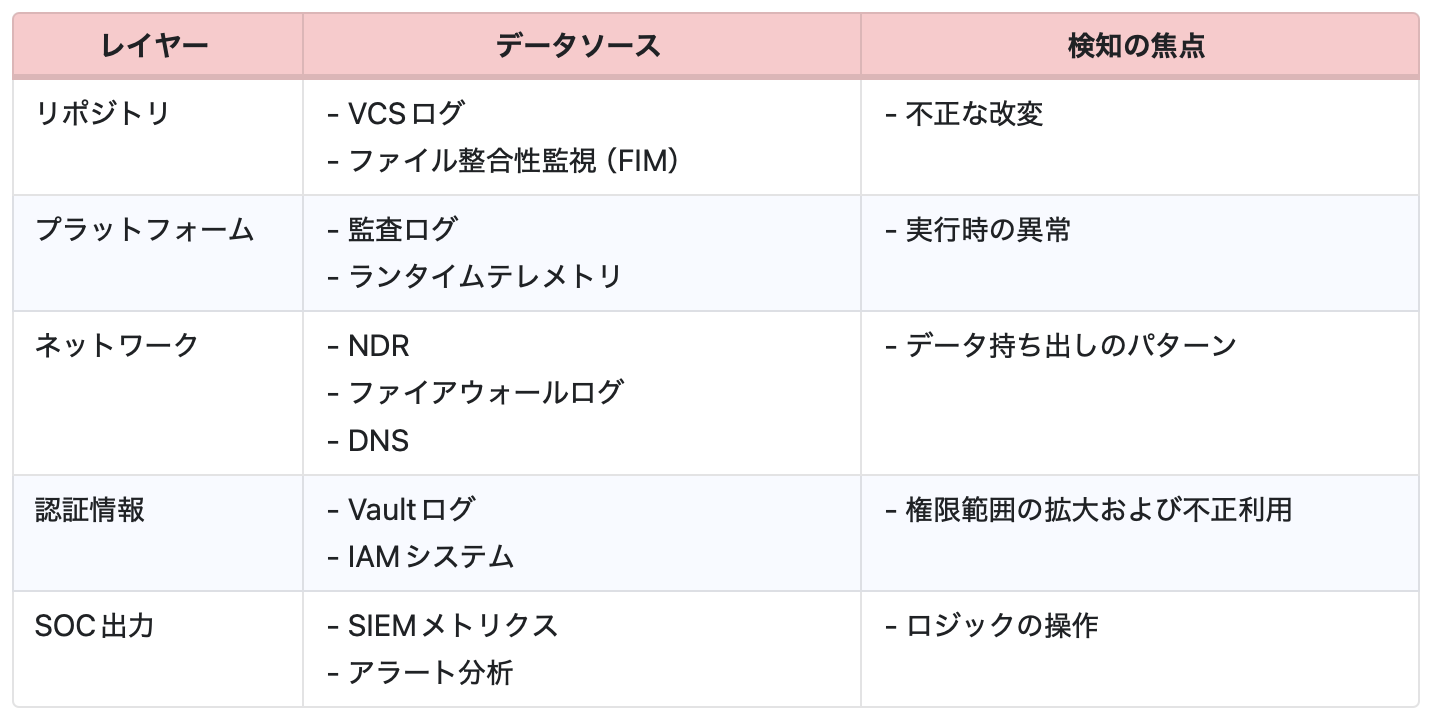
フェーズに対応した緩和策
本モデルの指針をより実践的な形に落とし込むために、提案するキルチェーンの各フェーズに対して具体的な緩和策を対応づけました。その内容を表4に示します。
AIスキルを保護するためのセキュリティ原則
これまで述べてきた技術的な緩和策に加え、組織は既存のセキュリティのベストプラクティスをあらためて見直し、それらをAIスキルの統合および運用管理にも適用していく必要があります。
AIスキルのライフサイクル全体を通じて適用すべき、実績ある原則は次のとおりです。
- スキルを機微な知的財産として扱うこと。ライフサイクル全体にわたってリスク評価と緩和策を実施します。適切なアクセス制御、バージョン管理、変更管理を導入します。適切な分類とラベリングを通じて、必要十分なアクセス制御を確保します。
- 命令と信頼できないデータを分離すること。多くのスキルはユーザ提供データを処理するため、悪用の機会が生まれます。スキルのロジック、スキル内部データ、外部からの非信頼データのあいだを明確に分離します。
- 実行権限を制限すること。スキル設計時には最小権限の原則を適用します。侵害時の横展開を防ぐため、実行コンテキストに付与する権限を必要最小限に限定します。
- 敵対的シナリオを想定して検証すること。組織のアタックサーフェスを正しく理解します。悪意ある利用者がスキルの運用ロジックをどのように悪用し得るかを、導入前に検証します。
- 包括的な監視体制を実装すること。監視、ログ取得、監査は、あらゆる業務プロセスを安全に運用するための基盤です。特に、従来のセキュリティ境界が曖昧になるAI活用環境においては、その重要性はいっそう高まります。
まとめ
AIスキルは、新たに浮上しつつあるアタックサーフェスであり、専用のセキュリティ上の配慮を必要とします。組織が業務上の専門知識を実行可能な知識アーティファクトとしてコード化していくほど、それらの資産が攻撃者にとって持つ価値も比例して高まっていきます。
とりわけSOCにおいては、AIスキルの侵害は防御体制の根幹を揺るがします。SOCのAIスキルを理解した攻撃者は、アラートを抑制する方法や、相関ルールをすり抜ける手法、自動化された対応を無効化するやり方、さらにはレポーティングを操作する術まで学び取ることができます。その結果、防御側の視界を事実上奪い、組織を盲目の状態に追い込むことさえ可能になります。
TrendAI™はこの分野におけるソートリーダーとして、AIセキュリティの脅威を継続的に研究し、AIを活用した環境に対応するための検知能力と緩和戦略の開発を進めています。組織が今すぐ着手すべき具体的な行動は明確です。既存のスキルを棚卸しし、機微性とアクセス要件に応じて分類し、通常時の実行パターンをベースラインとして把握し、高権限スキルを分離し、異常を継続的に監視することです。こうした基本的な取り組みが、AIスキル時代の防御の出発点となります。
著者について
TrendAI™ ResearchのForward-Looking Threat Research Teamは、1年から3年先の技術動向を見据えた調査を専門とするグループです。技術の進化、その社会的影響、そして犯罪への応用という三つの観点に焦点を当てています。その一環として、同チームは2020年以降、AIとその悪用の可能性に注目し続けてきました。2020年には、欧州刑事警察機構(Europol)および国連地域間犯罪司法研究所(UNICRI)と共同で、このテーマに関する研究論文を発表しています。
参考記事:
AI Skills as an Emerging Attack Surface in Critical Sectors: Enhanced Capabilities, New Risks
By Vladimir Kropotov and Fyodor Yarochkin (Principal Researchers, Forward-Looking Threat Research Team, TrendAI™ Research); Kirill Gelfand (Strategic Solutions Architect, TrendAI™)
翻訳:与那城 務(Platform Marketing, Trend Micro™ Research)