
人工知能(AI)の一分野であり、システムがさまざまなアルゴリズムを用いてデータを解析し、トレーニングデータ(学習用データ)から学習することで、精度の高い予測モデルを生成する技術です。このプロセスにより、システムはデータから反復的に学習を行い、未知の情報に対しても自動的に予測することが可能になります。
目次
機械学習の概要
人間が明示的に指示しなくても、コンピュータが自ら「何をすべきか」を判断するという考え方は、長年にわたり人々の想像力を刺激してきました。
自動運転車のように、運転席に乗り込むだけで、車が周囲の歩行者や障害物を認識し、環境の変化に柔軟に対応しながら、安全に目的地まで走行する。これは、機械学習(ML)の実践的な活用例の一つです。
まず、ビジネスデータの分析から始めてみましょう。
機械学習は人工知能(AI)の一分野であり、組織が膨大な量のデータを理解し、そこから学習することを可能にします。たとえば、Twitter(X)では、ユーザーが毎日約5億件、年間では約2,000億件ものツイートを投稿しています(出典:Internet Live Stats)。この膨大な情報を人間がすべて分析・分類・予測するのは現実的ではありません。しかし、機械学習を活用すれば、こうしたデータを効率的に処理し、リアルタイムでの分析、分類、学習、行動予測が可能になります。
機械学習を活用して組織が価値ある情報を得るためには、適切な準備と作業が必要です。まずは、クリーンデータを用意し、そのデータから何を知りたいのか、どのような課題を解決したいのかを明確にすることが重要です。そのうえで、ビジネスに利益をもたらす最適なモデルとアルゴリズムを選定することで、目的にあった成果を得ることができます。機械学習は決して単純なプロセスではなく、成功には継続的な努力と検証が求められます。
機械学習にはライフサイクルが存在します。以下はその主なステップです。
- 理解:なぜ機械学習を活用するのか、何を達成したいのか、何を学びたいのかを明確にします。
- データ収集と事前処理:必要な量のデータを収集し、正確なインサイトを得るために十分にクリーンな状態に整えます。
- 特徴量の選択:機械学習モデルをに入力するデータを選定します。使用するアルゴリズムによって選定方法は異なります。たとえば、意思決定ツリー(ディシジョンツリー)アルゴリズムでは、アナリストやモデリングツールがデータベースの各列にインタレストスコア(Interestingness Score)を適用し、モデル構築に適したデータかどうかを判断します。
- モデル選択:データを処理し、特定のパターンを検出するために訓練されたモデルファイルを選択します。モデルはアルゴリズムとテストデータを組み合わせて、結論を導き出します。
- トレーニングとチューニング:機械学習モデルがデータから導き出した結論をもとに、問いに正確に答えられるように検証・調整します。
- モデルとアルゴリズムの評価により、実運用に適しているかを判断します。必要に応じて、モデル、特徴量、アルゴリズム、またはデータを再調整し、目的達成に向けて改善を行います。
- 訓練済みのモデルを本番環境に導入します。
- 本番環境で稼働しているモデルの出力結果を確認します。
機械学習は何に使われるのか?機械学習の応用
組織が自組織のデータを理解し、そこから学びを得るための手法です。機械学習は、ビジネスにおいて非常に多くのサブフィールドで活用することができます。そのユースケースは、組織が何を目指しているかによって異なります。たとえば、売上を向上させたい場合、検索機能を提供したい場合、製品に音声コマンドを統合したい場合、あるいは自動運転車を開発したい場合など、目的に応じて機械学習の使い方は変わります。
機械学習のサブフィールド
機械学習は、現代のビジネスにおいて非常に多様な用途を持っており、今後さらにその活用範囲と精度は向上していくと考えられます。機械学習のサブフィールドには、ソーシャルメディアや商品レコメンデーション、画像認識、データマイニングなど、さまざまな分野があります。
Facebook、Instagram、LinkedInなどのソーシャルメディアプラットフォームは、機械学習を活用して、ユーザーが「いいね」した投稿に基づいて、フォローすべきページや参加すべきグループを提案します。これは、過去のデータや他のユーザーの行動、類似した投稿の履歴をもとに、あなたのフィードに表示するコンテンツを判断しています。
ECサイトでも、機械学習は活用されています。過去の購入履歴、検索履歴、他のユーザーの類似行動に基づいて、商品レコメンドすることが可能です。
現在、機械学習の大きな用途のひとつが画像認識です。ソーシャルメディアでは、写真に写っている人物をタグ付けする機能に使われています。また、警察が容疑者を写真や映像から特定する際にも活用されています。空港、店舗、ドアベルなどに設置された多数のカメラ映像から、犯罪者の行動や位置を特定することも可能です。
健康診断も、機械学習の有効な活用例です。たとえば心臓発作が発生した後、過去の行動や検査結果、症状などの記録をもとに、見逃されていた兆候を発見できます。医師や病院が過去の医療記録をシステムに入力することで、機械学習は入力(行動、検査結果、症状)と出力(心臓発作など)の関係を学習し、将来的に医師が入力した診療メモや検査結果から、より正確に兆候を検出できるようになります。これにより、患者と医師が予防的な対応を取ることが可能になります。
言語翻訳も、ウェブページやモバイルアプリでの機械学習の代表的な活用例です。翻訳精度はアプリによって異なり、それは使用している機械学習モデル、技術、アルゴリズムの違いによるものです。
日常的に使われている例としては、銀行やクレジットカードの不正検出があります。機械学習は、詐欺の兆候を人間よりも迅速かつ正確に検出できます。過去の膨大な取引データが「詐欺かどうか」のラベル付きで学習されているため、将来の取引においても、機械学習は一件の取引から詐欺を見抜くことができます。このような用途には、データマイニングが非常に効果的です。
データマイニング
データマイニングは、機械学習の一種であり、膨大なデータ(ビックデータ)の中からパターンを発見したり、将来の予測を行うために活用されます。「マイニング(採掘)」という言葉から、誰かがデータの中を探り回って有用な情報を見つけ出すような印象を受けるかもしれませんが、実際にはそうではありません。攻撃者や社員が手動でデータを探すようなものでなく、機械学習が自動的に意思決定に役立つパターンを発見するプロセスです。
たとえば、クレジットカード会社を例に挙げてみましょう。カードを持っている方であれば、銀行から「不審な取引が検出されました」といった通知を受けたことがあるかもしれません。こうした迅速な検出は、継続的なデータマイニングによって実現されています。2020年初頭の時点で、米国では11億枚以上のクレジットカードが発行されており、それらのカードによる膨大な数の取引データが蓄積されています。このデータをもとに、機械学習はパターンを学習し、将来的に不正の可能性がある取引を即座に検出できるようになります。
ディープラーニング
ニューラルネットワークに基づいた機械学習の一種です。ニューラルネットワークは、人間の脳のニューロンの働きを模倣し、意思決定や理解を行う仕組みです。たとえば、6歳の子どもが顔を見て、お母さんと横断歩道の係員を瞬時に見分けられるのは、脳が髪の色、顔の特徴、傷などの多くの情報を一瞬で分析しているからです。機械学習は、このような人間の認識プロセスを、ディープラーニングによって再現しようとしています。
ニューラルネットワークは通常、入力層 (Input Layer)、1〜3層の隠れ層(Hidden Layer)、そして出力層(Output Layer)の3〜5層で構成されます。隠れ層では、出力層に向けて一つひとつ判断を行います。たとえば、「髪の色は?」「目の色は?」「傷はあるか?」といった具合です。この層が数百にも及ぶようになると、それはディープラーニングと呼ばれます。
機械学習の種類
機械学習アルゴリズムには、基本的に以下の4種類があります:教師あり学習(Supervised)、半教師あり学習(Semi-supervised)、教師なし学習(Unsupervised)、そして強化学習(Reinforced)です。
機械学習の専門家によると、現在使用されている機械学習アルゴリズムの約70%は教師あり学習であり、これはラベル付きの既知のデータセットを使って学習します。たとえば、犬と猫の画像のように、どちらの動物かが分かっているため、管理者が画像にラベルを付けてアルゴリズムに渡すことができます。
教師なし学習アルゴリズムは、ラベルのない未知のデータセットから学習します。たとえば、TikTokの動画のように、非常に多くのトピックが存在するため、すべてにラベルを付けて教師ありで学習させるのは現実的ではありません。半教師あり学習アルゴリズムは、まず少量のラベル付きデータで初期学習を行い、その後、より大きなラベルなしデータセットに適用して学習を継続します。
強化学習アルゴリズムは、初期の訓練を行わず、試行錯誤を通じて学習します。たとえば、岩の上を移動するロボットを考えてみてください。転倒するたびに「うまくいかない方法」を学び、成功するまで行動を修正していきます。これは、犬のしつけにおいておやつを使ってコマンドを教える方法にも似ています。ポジティブな報酬によって、犬は望ましい行動を繰り返し、報酬が得られない行動は自然と減っていきます。
教師あり学習 vs 教師なし学習
教師あり機械学習
既知で分類済みのデータセットを使ってパターンを発見する手法です。先ほどの犬と猫の画像の例をさらに広げてみましょう。何百万枚もの画像に、何千種類もの動物が写っている大規模なデータセットがあるとします。動物の種類がすでに分かっている場合、それらの画像はグループ化され、ラベル付けされたうえで、教師あり機械学習アルゴリズムに渡されます。
教師ありアルゴリズムは、入力(画像)と出力(動物の種類のラベル)を比較しながら学習を進めます。最終的には、新しい画像に対しても、どの動物が写っているかを認識できるようになります。
教師なし機械学習
現在のスパムフィルターのような仕組みに似ています。以前は、管理者が特定の単語を検出するようにスパムフィルターをプログラムすることで、スパムメールを判別していました。しかし、現在ではその方法は通用しなくなっており、教師なし学習が有効に機能しています。
教師なし機械学習アルゴリズムには、ラベル付けされていないメールが入力され、そこからパターンを見つけ出すことで学習が始まります。こうして発見されたパターンをもとに、アルゴリズムはスパムの特徴を理解し、実際の運用環境でスパムを識別できるようになります。
機械学習の手法
機械学習の手法は、問題を解決するために使用されます。直面している課題の種類に応じて、適切な機械学習手法を選択する必要があります。以下は、代表的な6つの手法です。
回帰分析
回帰は、住宅価格の予測や、12月のアメリカ合衆国ミネソタ州でのスコップの最適販売価格の決定などに使われます。価格は変動しますが、平均値に戻る傾向があるとされ、時間の経過とともに平均価格をグラフにプロットすることで、将来の価格を予測できます。
分類
分類は、データを既知のカテゴリにグループ化するための手法です。たとえば、リピーター顧客と離脱傾向のある顧客を分類し、過去の行動から予測モデルを構築することで、現在の顧客がどちらのグループに属するかを予測できます。これは教師あり学習の代表的な例です。
クラスタリング
分類とは異なり、クラスタリングは教師なし学習です。未知のデータを自動的にグループ化するために使われます。医療画像の分析、ソーシャルネットワークの解析、異常検知などに適しています。Googleは、YouTube動画、Playアプリ、音楽トラックなどの一般化、データ圧縮、プライバシー保護のためにクラスタリングを活用しています。
異常検出
異常検知は、膨大なデータの中から外れ値、例えば黒い羊を見つけるための手法です。人間には見つけにくい異常を、機械学習が自動的に検出します。たとえば、医療請求データを分析することで、詐欺の可能性がある外れ値を特定できます。
マーケットバスケット分析
マーケットバスケット分析は、将来の購買行動を予測するために使われます。たとえば、牛ひき肉、トマト、タコスを購入した顧客が、チーズやサワークリームも購入する可能性が高いと予測できます。MITの教授らはこの手法を使って「失敗の予兆(Harbinger of Failure)」を発見しました。特定の顧客が好む商品が失敗する傾向にあることを見抜き、販売戦略の見直しに活用できます。
時系列データ
時系列データは、フィットネスモニターなどで収集される心拍数、歩数、酸素飽和度などの情報です。これにより、将来の運動タイミングを予測したり、機械の振動、騒音、圧力などのデータから故障を予測することが可能になります。
機械学習のアルゴリズム
機械学習がデータから学習するには、統計的に意味のある情報を見つけるためのアルゴリズムが必要です。機械学習アルゴリズムは、教師あり、教師なし、強化学習のプロセスをサポートします。
データエンジニアは、機械が学習し、データの中から意味を見つけ出すためのコード(アルゴリズム)を書きます。
次に、現在広く使われている代表的な5つのアルゴリズムをご紹介します。
- 線形回帰アルゴリズムは、独立変数と従属変数の関係性をグラフ上にプロットし、平均値や傾向を示す直線を描くことで、予測を行う機械学習アルゴリズムです。メリアム・ウェブスター辞典(Merriam-Webster)では回帰を「1つ以上の独立変数に特定の値が与えられたときに、確率変数の平均値を導く関数」と定義しています。この定義は、ロジスティック回帰(Logistic Regression)にも当てはまります。
画像提供:オラクル
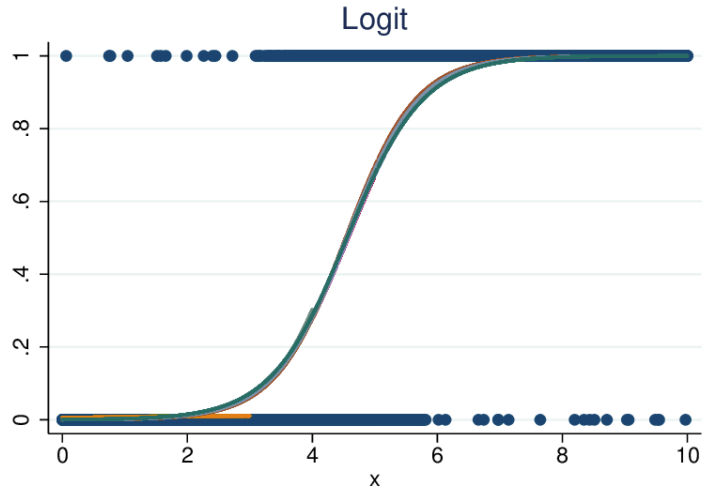
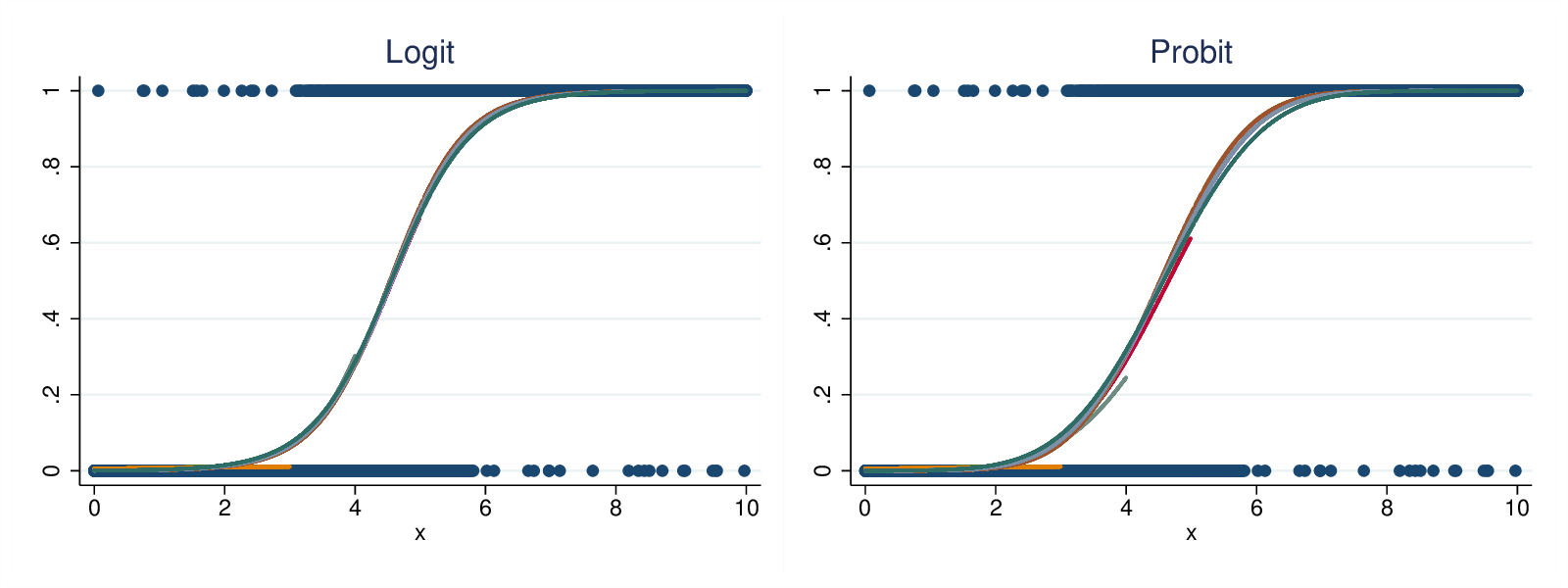
- ロジスティック回帰(Logistic Regression別名:ロジット)も、線形回帰と同様に変数をグラフに当てはめますが、描かれる線は直線ではありません。ここでの線はシグモイド関数です。
{kind=link}
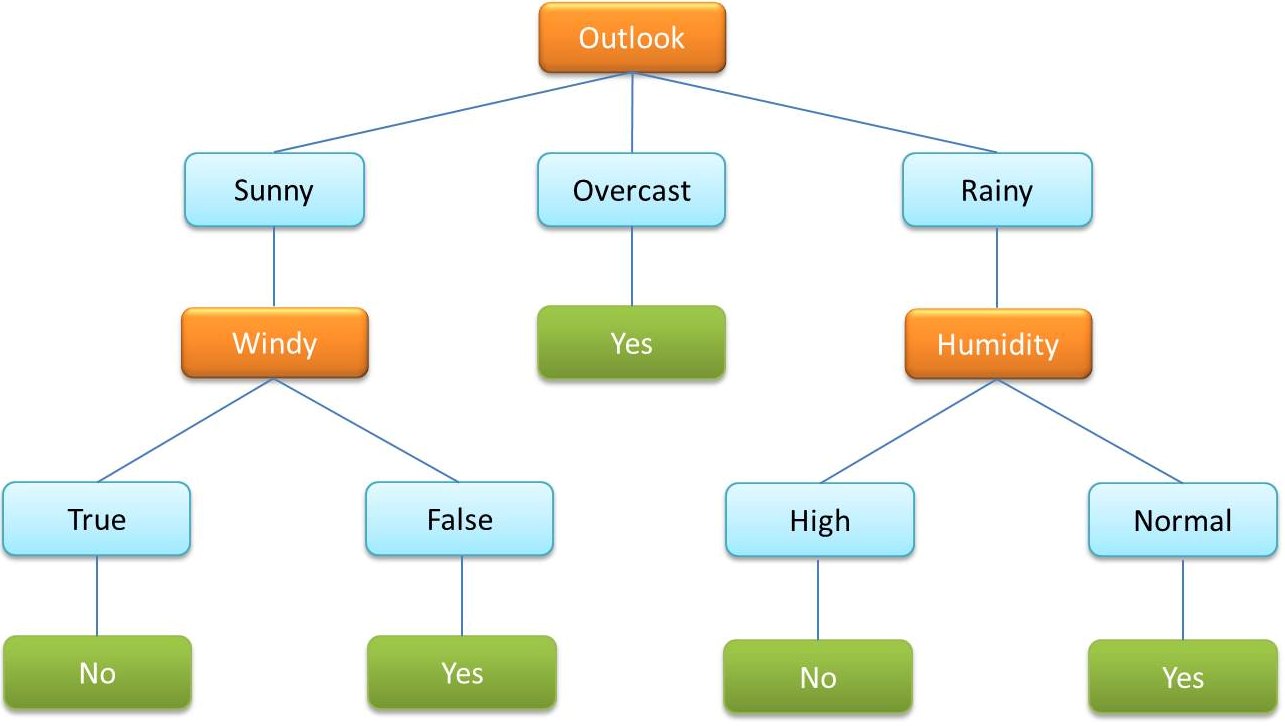
- 決定ツリー(ディシジョンツリー)は、教師あり機械学習内でよく使用されるアルゴリズムです。データをカテゴリ変数と連続変数で分類するために使用されます。
- サポートベクターマシン(Support Vector Machine)は、2つの最も近いデータポイントに基づいてハイパープレーン(超平面)を描画します。このハイパープレーンは、異なるクラスを分離する境界線として機能します。サポートベクターマシンは、n次元空間に基づいてデータを分類しますが、Nとは使用する特徴の数を表します。
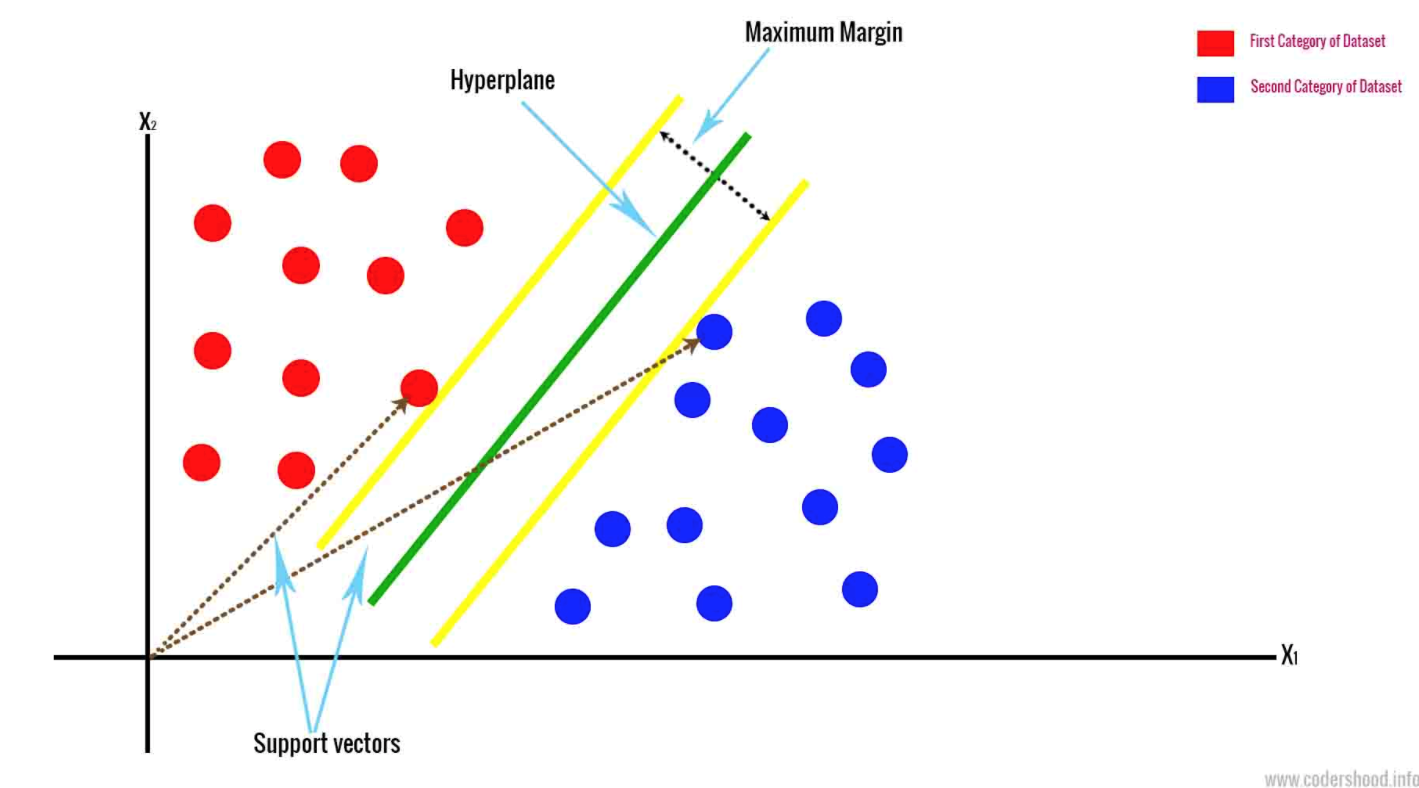
{kind=link}
- ナイーブベイズ(Naïve Bayes)は、特定の結果が起こる確率を計算する機械学習アルゴリズムです。非常に効果的で、より複雑な分類モデルよりも高いパフォーンスを発揮することもあります。ナイーブベイズ分類器は、各特徴が他の特徴の存在と無関係であることを理解し学習を行います。
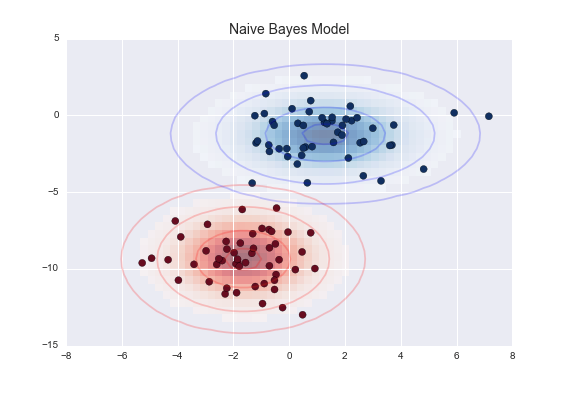
{kind=link}
機械学習モデル
機械学習の種類(教師あり学習、教師なし学習など)、さまざまな技術やアルゴリズムを組み合わせることで、学習済みのファイルが作成されます。このファイルは新しいデータを受け取ることで、パターンを認識し、ビジネス、管理者、または顧客のニーズに応じて予測や意思決定を行うことが可能になります。
機械学習に適した言語
機械学習におけるプログラミング言語は、システムが学習するための指示を記述する手段です。各言語には、学習や情報共有を支援するユーザーコミュニティが存在しています。また、機械学習向けのライブラリがそれぞれの言語に含まれており、モデルの構築やデータ分析などに活用できます。
GitHubの2019年の調査「State of the Octoverse」によると、これはトップ10です。
- Python
- C++
- JavaScript
- Java
- C#
- Julia
- Shell
- R
- TypeScript
- Scala - ビッグデータとの連携に活用される言語
Pythonと機械学習
Pythonは最も一般的に使用されている機械学習言語であり、ここではその特徴について詳しく紹介します。
Pythonはインタプリタ型のオープンソースで、オブジェクト指向のプログラミング言語です。名前はイギリスのコメディグループ「モンティ・パイソン」に由来しています。インタプリタ型であるため、実行前にバイトコードに変換され、Python仮想マシンによって実行されます。
Pythonが機械学習で好まれる理由
- 現在利用可能な強力なパッケージが多数揃っています。機械学習専用のNumPy、SciPy、Pandasなどがあります。
- プロトタイプの作成が簡単かつ高速
- 共同作業を可能にする多様なツール
- データサイエンティストが、データの抽出からモデリング、そして機械学習ソリューションの更新に至るまでのプロセスを進める中で、Pythonは一貫して使用できる言語です。ライフサイクルの各段階で言語を切り替える必要がなく、Pythonだけで完結できる点が大きな利点です。

Fernando Cardoso
プロダクトマネジメント担当バイスプレジデント

Fernando Cardosoはトレンドマイクロのプロダクトマネジメント担当バイスプレジデントとして、進化を続けるAIとクラウドの領域に注力しています。ネットワークエンジニアおよびセールスエンジニアとしてキャリアをスタートさせ、データセンター、クラウド、DevOps、サイバーセキュリティといった分野でスキルを磨きました。これらの分野は、今なお彼の情熱の源となっています。