MITRE ATLASとは何か?:第3回(実行~防御回避)
サイバーセキュリティの分野でおなじみのMITRE ATT&CKを基盤とし、人工知能や機械学習システムに対する攻撃者のTTPをまとめたナレッジベース「MITRE ATLAS」について解説します。この記事は第3回です。



※本記事は2025年5月15日時点の情報に基づいた記事です。以降の情報は、断り書きがない限りこの時点の情報です。
AIシステムに対するサイバー攻撃の戦術と攻撃手法に関するナレッジベース「MITRE ATLASTM」。本連載では、実際のインシデントや実証研究を交えて、各攻撃フェーズの詳細解説をお届けします。この記事は第3回です。
連載記事はこちら:
・MITRE ATLASとは何か?:概要編
・MITRE ATLASとは何か?:第2回(偵察~AIモデルへのアクセス)
MITRE ATLASとは?
MITRE ATLASTM(以下、ATLAS)は、Adversarial Threat Landscape for Artificial-Intelligence Systems(編集部仮訳:AIシステムに対する敵対的脅威の情勢)の略で、非営利団体MITREが2021年に公開しました。同じくMITREが整備している、サイバー攻撃の流れと手法を体系化したフレームワーク「MITRE ATT&CK」をベースに、AIシステムに特化して情報を整備したものが「ATLAS」です。本稿では2024年10月から2回アップデートされ、15の戦術・68テクニックとなった2025年4月版(Data v4.9.0)をベースに解説しています。MITRE ATLASのアップデート履歴はこちらをご覧ください。
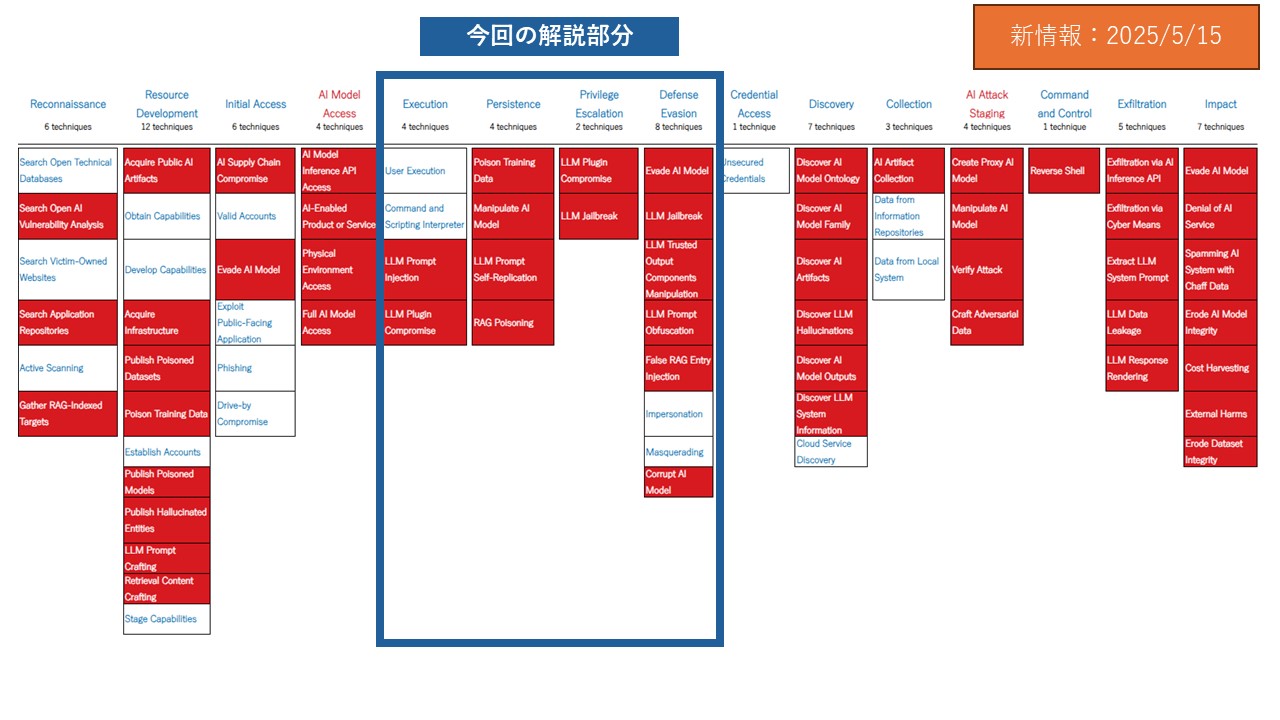
図:ATLASマトリクス(MITRE ATLASのWebサイトをもとにトレンドマイクロで作成)と本稿での解説部分(2025年5月15日現在)※
※赤字、および赤セルの項目はMITRE ATLAS特有であり、「ATT&CK」にはありません。
連載第3回に当たる本稿では、「Execution(実行)」、「Persistence(攻撃の永続性の確保)」、「Privilege Escalation(権限昇格)」、「Defense Evasion(防御回避)」について解説します。
| テクニックID | テクニック名 | 概要 |
| AML.T0011 | ① User Execution (ユーザによる実行) |
ユーザの特定のアクションに依存する手法。たとえば、AIサプライチェーン侵害によって導入された安全でないコードの誤った実行、悪意のあるドキュメントファイルやリンクを開かせる手法(ソーシャルエンジニアリング)などがある。 |
| AML.T0050 | ② Command and Scripting Interpreter (コマンドおよびスクリプトインタープリタ) |
コマンドやスクリプトインタープリタを悪用して、コマンドやスクリプトやバイナリの実行を行う手法。攻撃者は、おとりドキュメントの送付やC&Cサーバー経由のコード実行用のペイロードに不正なコードを埋め込むなど方法をとることがある。 |
| AML.T0051 | ③ LLM Prompt Injection (LLMプロンプトインジェクション) |
LLMへ悪意あるプロンプトを入力し、LLM開発者が意図しない方法で悪意あるコードを実行しようとする方法。悪意あるプロンプトの挿入は、攻撃者が直接LLMに入力する方法のほか、LLMが通常の操作としてデータソースから悪意あるプロンプトを取り込むように細工をする方法がある(間接的なプロンプト挿入)。 |
| AML.T0053 | ④ LLM Plugin Compromise(LLMプラグインの侵害) | 大規模なLLMに接続されたプラグインを侵害する方法。LLMは機能強化のためプラグインを介して他のサービスやリソースへアクセスすることが一般にある。攻撃者はこれらプラグインの機能をAPI等で呼び出し実行することで、機密情報の取得や任意コマンド実行を行う可能性がある。 |
ケーススタディ:実証研究「ChatGPT Package Hallucination」
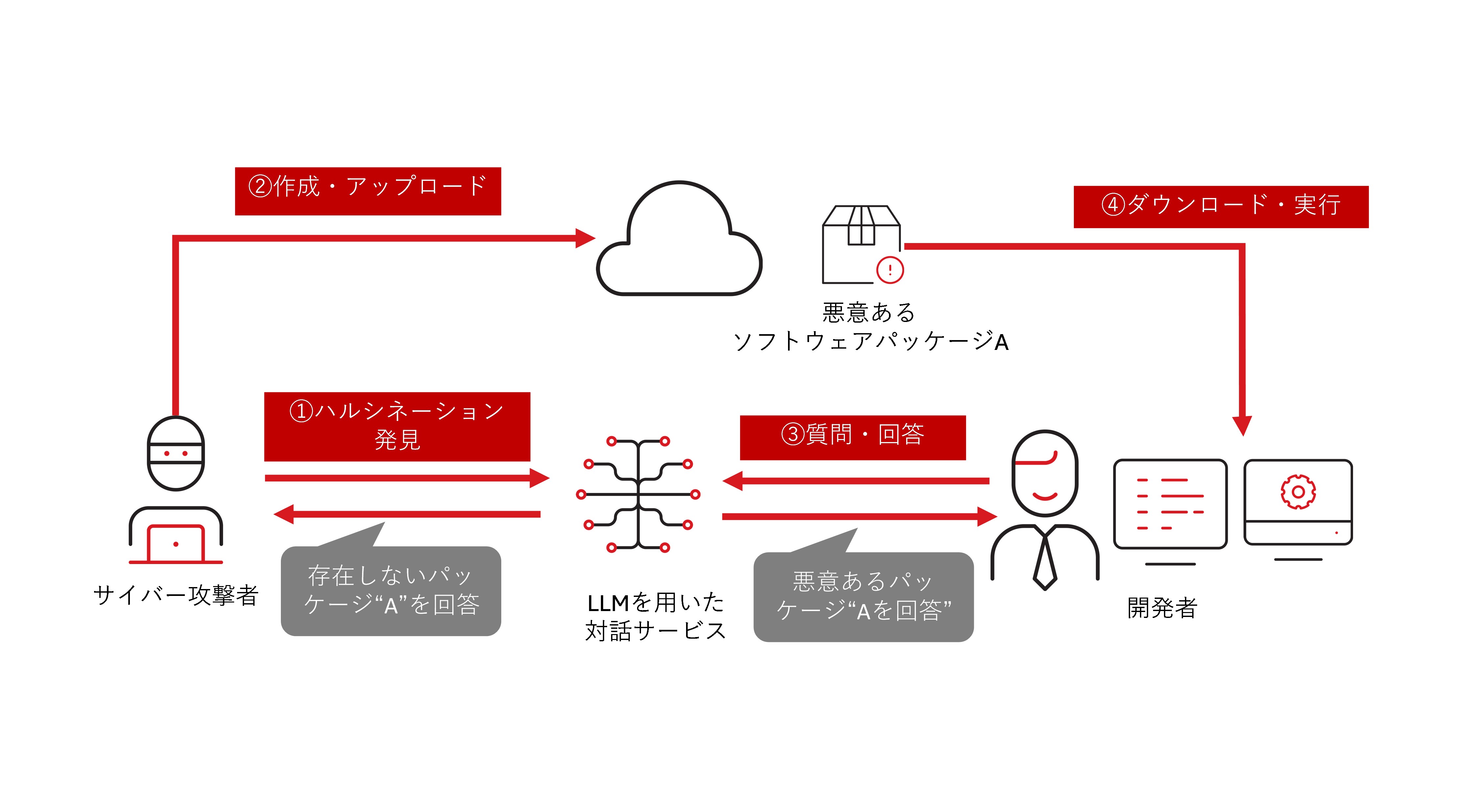
Execution(実行)の事例として、2024年3月に サイバー脅威管理ソリューション開発企業のVulcan Cyber、その後生成AIのセキュリティ企業Lasso Securityに在籍する研究者が公表した、ソフトウェアパッケージに関するChatGPT のハルシネーション※を使った実証研究「ChatGPT Package Hallucination(ChatGPTパッケージのハルシネーション)」があります。
※ハルシネーション:AIが事実でない内容や存在しない事象について、もっともらしく回答する現象。学習データの不足やバイアス、データの誤り、生成AI独自の推測などから起こると考えられる。
この実証研究は、研究者がプログラム開発の工程で、Chat GPTにソフトウェアパッケージに関する質問をすると、一定の確率で存在しないソフトウェアパッケージ「huggingface-cli」を回答するハルシネーションを発見したことから始まりました。研究者は、「ならば、同じ名称のソフトウェアパッケージを実際にアップロードしたらどうなるか?」を調べるため、ダミーパッケージをアップロードしました。その結果、約3カ月で約3.1万回ダウンロードされるという結果になりました。
加えて、他社のリポジトリにこの検証用ダミーパッケージが利用され、大手IT企業のAI研究プロジェクトのREADMEに記載される状況までに至っています。
この研究者はあくまで注意喚起のためにこの実証実験を行いましたが、同様の現象がサイバー攻撃者によって悪用される場合、Executionの段階でユーザがハルシネーションを信じ攻撃者が仕込んだ悪意あるパッケージをインストールさせられる状況につながる可能性があります。
(参考情報)
「Diving Deeper into AI Package Hallucinations」(Lasso Security。2024年3月28日)
「ChatGPT Package Hallucination」(MITRE ATLAS。2024年6月)
| テクニックID | テクニック名 | 概要 |
| AML.T0018 | ① Manipulate AI Model (AIモデルの操作) |
AIモデルを直接操作して、動作の変更や悪意あるコードを埋め込む。モデルを操作する際に、攻撃者はモデルの重み※の変更、モデルアーキテクチャの変更、モデル読み込み時に実行される用にマルウェアの埋め込むなどを行う。 ※AIモデルの学習過程で中核となるパラメータのこと。 |
| AML.T0020 | ② Poison Training Data (学習データの汚染) |
データセットを汚染しAIモデルに脆弱性を埋め込む。バックドアトリガーの挿入を含むデータサンプルにより後にアクティブ化されることがある。 |
| AML.T0061 | ③ LLM Prompt Self-Replication (LLMプロンプトの自己複製) |
攻撃者が、LLMの出力の一部としてプロンプト(LLMジェイルブレイクやデータ漏洩などを目的としたもの)を複製するようにプロンプトインジェクションを行う。再現されたプロンプトが他のLLMに伝播し、システム上で維持される。 |
| AML.T0070 | ④ RAG Poisoning (RAGの汚染) |
攻撃者が、RAGシステムによってインデックス化されたデータに悪意あるコンテンツを挿入し、RAGの検索結果を通じて将来的なスレッドの汚染(虚偽内容の回答や悪意あるプロンプトインジェクションなどが含まれる)を狙う。 |
ケーススタディ:実証研究「DeepPayload※」
2021年1月、マイクロソフトや北京郵電大学などの複数のセキュリティ研究者が、AIを利用しているAPK(Android OS用のアプリ)に、バックドアを仕込むことに成功した研究結果を発表しました。
※正式名称は「DeepPayload: Black-box Backdoor Attack on Deep Learning Models through Neural Payload Injection(訳:DeepPayload(ニューラルペイロードインジェクションによるディープラーニングモデルに対するブラックボックスバックドア攻撃))」
この研究者たちは、ディープラーニングモデルに対してバックドアを仕込む攻撃の新しい手法「DeepPayload」を提案し、デプロイ済みのAIモデルに直接悪意のあるロジックを注入することができるかを研究しました。結果、トリガーとなる画像(研究者が用意)を読み込んだ場合に、AIモデルが誤分類を起こすなどの悪意ある動作を発動させることができることを明らかにしました。この研究で述べられている、攻撃方法は以下の通りです。
・対象となるAIモデルのバイナリファイルを逆コンパイルしてデータフローグラフ(DFD)※を生成。
※データフローグラフ:システムが扱うデータの流れを表した図。
・トリガーディテクタと条件モジュールを含む悪意のあるペイロード(トリガー画像が検出された場合、攻撃者が指定した出力に置き換える)を注入し、再アッセンブリ。
・GooglePlay上で公開されていた116のアプリ(APK)のAIモデルをAPKから抽出し、バックドア挿入後にリパッケージしたAPKで攻撃再現に成功(116のAPKのうち、54のAPKが成功)。
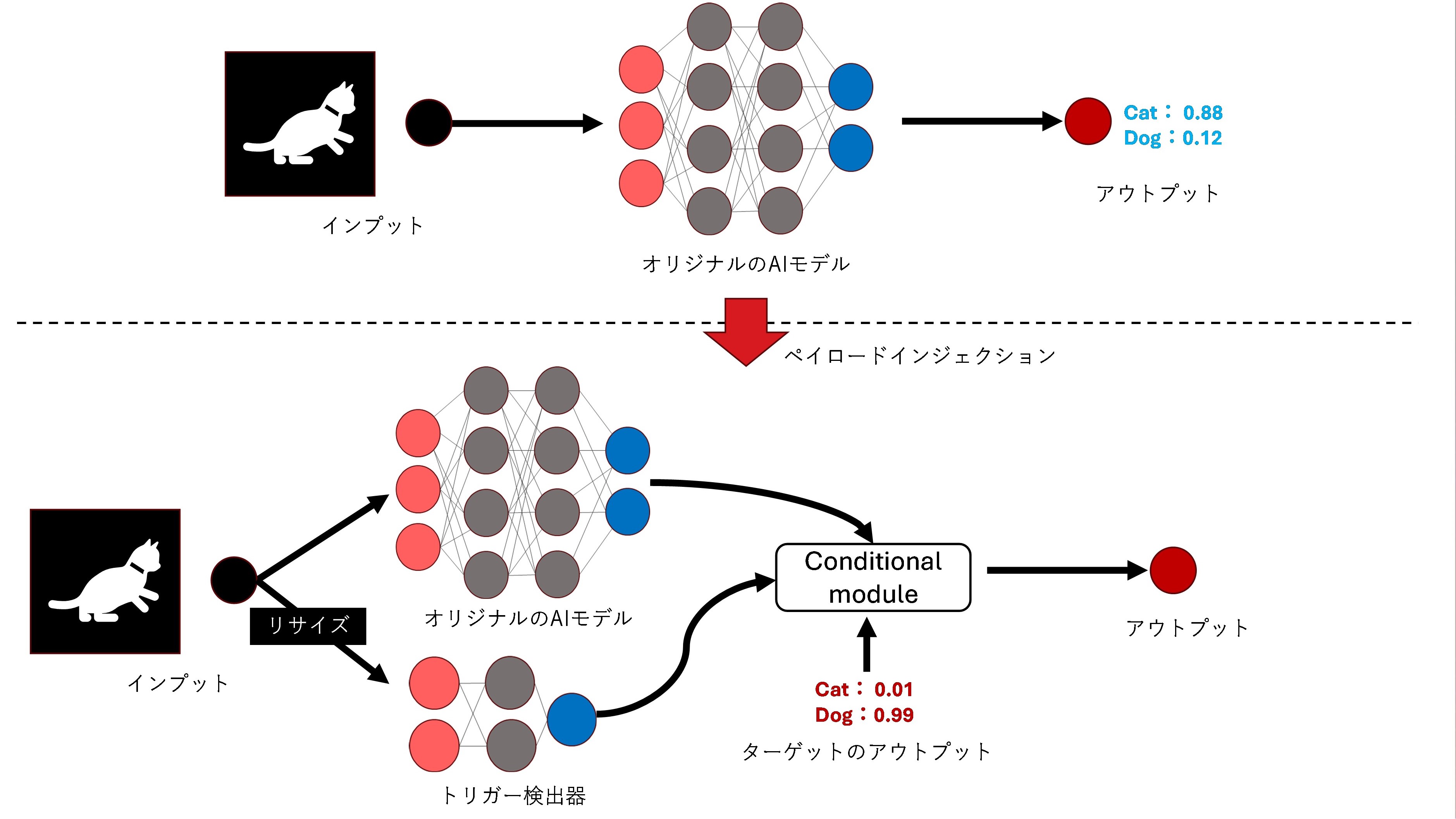
この研究においては、永続化の段階でバイトコード※を直接書き換えて、ペイロードを注入しました。
※bytecode: 仮想マシン上で動作するように作成される実行可能な中間コードのこと。
この研究を行った研究者たちは、この攻撃は影響範囲が広く転用可能であるにも関わらず、被害対象のAIモデルに与える影響は最小限であると結論付けています。さらには、ディープラーニングを用いたAIアプリケーションの開発者と監査者に対して、デプロイされたAIモデルの保護を強化する必要性を訴えました。
(参考情報)
「DeepPayload: Black-box Backdoor Attack on Deep Learning Models through Neural Payload Injection」(Yuanchun Li、Jiayi Hua、Haoyu Wang、 Chunyang Chen、Yunxin Liu。2021年1月18日)
| テクニックID | テクニック名 | 概要 |
| AML.T0053 | ① LLM Plugin Compromise (LLMプラグインの侵害) |
大規模システムの一部であるLLMへのアクセスを利用して接続されたプラグインを侵害する。これにより攻撃者は、統合アプリケーションまたはプラグインへのAPI呼び出しを実行できるようになり、システムに対するアクセス権限が強化される。 |
| AML.T0054 | ② LLM Jailbreak (LLMジェイルブレイク) |
LLMに設定された制御、制限、ガードレール(モデルが意図しない危険・不適切な出力を生成するのを防ぐ仕組み)を回避して、入力されたプロンプトに対して、LLMが自由に応答できるような状態にする。細工されたLLMプロンプトインジェクションを介してジェイルブレイクに成功すると、攻撃者はLLMをシステムが意図しない方法で使用できてしまう。 |
ケーススタディ:Google Vertex AIのカスタムジョブによる権限昇格の脆弱性
2024年11月、サイバーセキュリティ企業のPalo Alto Networksは、Googleの機械学習プラットフォーム「Vertex AI※」における2つの脆弱性を報告しました。以下に概要を列挙します。
※Vertex AI:Googleが提供する機械学習のフルマネージド型プラットフォーム。AI開発のための様々なツールが提供されており、利用者は運用管理・保守業務をすべてGoogleに委託できるのが特徴。
① カスタムコードインジェクションによる権限昇格:
Vertex AIで提供されているツール「Vertex AI Pipelines※」には、カスタムジョブと呼ばれるAIモデルの調整(モデルのファインチューニング)機能があります。この機能の実体は、利用・開発しているAIモデルの中身を変更できる”コード”であり、専用のクラウド上に展開されたテナントプロジェクト上でチューニングが実行され、完了すると別のレジストリにチューニング済みAIモデルが格納されます。このカスタムジョブに使用されるコードに悪意ある文字列を挿入すると、結果的に高い権限のサービスエージェントで内部リポジトリにアクセスできてしまったことが報告されています。
※Vertex AI Pipelines:Vertex AI上でMLパイプラインを構築・実行するためのツール。
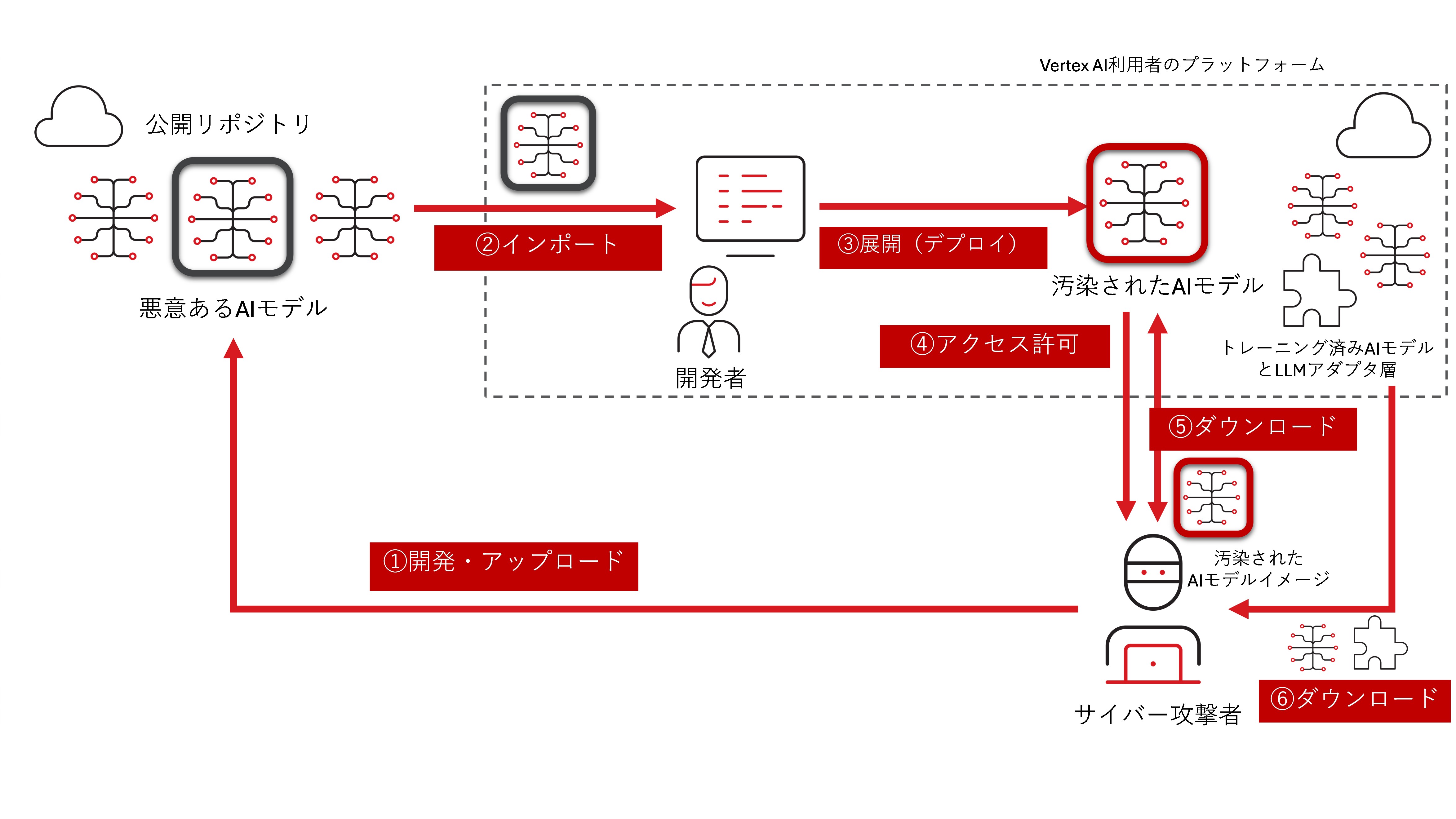
② 悪意あるAIモデル展開による情報流出攻撃:
検証の結果、この脆弱性を悪用した攻撃は、以下の流れで行われることが想定されます。
1.攻撃者が悪意あるAIモデルを公開する。
2.データエンジニアがAIモデルをダウンロードして自身の環境にインストールする。
3.モデルが展開され、攻撃者にアクセスを許可する(リバースシェル※)。
4.攻撃者がAIモデルイメージをダウンロードする。
5.攻撃者がトレーニング済みのモデルとLLMアダプタ※層を取得する。
※リバースシェル:サイバー攻撃者による標的システムへのリモートアクセス・制御方法の1つ。標的システムが攻撃者のシステムに接続を行う、通常のシェルを使った接続と逆の流れになることからリバースシェルと呼ばれる。
※LLMアダプタ:基盤となるLLMをカスタマイズして別のLLM(用途別に小規模にするなど)を開発する際に利用される技術。
すでにこれらの脆弱性は修正済みですが、組織で開発中のAIモデルが機密情報であると規定される場合、またAIモデルが扱う情報に個人情報などが含まれる場合、同様の攻撃によって情報漏洩被害につながる可能性があります。
(参考情報)
「ModeLeak: Privilege Escalation to LLM Model Exfiltration in Vertex AI」(Palo Alto Networks。2024年11月24日)
| テクニックID | テクニック名 | 概要 |
| AML.T0015 | ① Evade AI Model (AIモデルの回避) |
AIモデルの正しい識別を妨げる。敵対的データ作成やAIベースのマルウェア検出やネットワークスキャンを回避することも含む。 |
| AML.T0054 | ② LLM Jailbreak (LLMの脱獄) |
LLMに設定された制御、制限、ガードレール(モデルが意図しない危険・不適切な出力を生成するのを防ぐ仕組み)を回避する。 |
| AML.T0067 | ③ LLM Trusted Output Components Manipulation (LLMの信頼できる出力コンポーネントの操作) |
攻撃者がLLMに対するプロンプトを利用して、その応答の様々なコンポーネント(リンク、アクション、取得したドキュメント、メタデータ、引用など)を操作し、ユーザに信頼できるように見せかける可能性がある。操作されたLLMは、より信頼感を獲得するように言語を調整したり、特定のアクションを実行するようにユーザに促したりすることが考えられる。 |
| AML.T0068 | ④ LLM Prompt Obfuscation (LLMプロンプトの難読化) |
攻撃者が検出を回避するために、プロンプトインジェクションや取得したコンテンツを隠したり、難読化する。小さなテキスト、背景と同じ色のテキスト、非表示のHTML elements(要素)などが悪用される。 |
| AML.T0071 | ⑤ False RAG Entry Injection (虚偽のRAGエントリインジェクション) |
標的のRAGデータべ―スに虚偽のエントリを挿入する。LLMは挿入されたエントリの一部をアウトプットとして使用する。通常のRAGエントリ内に虚偽のドキュメントを挿入することで、データ監視ツールのバイバスとドキュメント自体の削除を防ぐ。 |
| AML.T0073 | ⑥ Impersonation (なりすまし) |
攻撃者が被害者に関係する信頼できる人物や組織になりすまし、被害者に何らかの行動を実行させる。攻撃者は、モデルリポジトリ、コンテナ/ソフトウェアレジストリなど、AI DevOpsライフサイクルのリソースを標的にする可能性がある。 |
| AML.T0074 | ⑦ Masquerading (みせかけ) |
攻撃者がAI成果物の特徴を操作して、ユーザやセキュリティソリューションに、正当または無害に見えるようにする。具体的には、オブジェクトの名前や保管場所、タスク名やサービス名などに正当なものと同じ文言を使用することなどがある。 |
| AML.T0076 | ⑧ Corrupt AI Model (AIモデルの破損) |
攻撃者が悪意あるAIモデルファイルを意図的に破損させ、正常に逆シリアル化(デシリアライズ)※できないようにし、モデルスキャナーの検出を回避する。破損したAIモデルは、逆シリアル化が失敗する前に悪意あるコードを実行する可能性がある。 ※シリアル化(シリアライズ)されたデータ(バイト列やテキスト)を元のオブジェクトに戻す作業。 |
ケーススタディ:実証研究「マルウェア対策ニューラルネットワークモデルへの敵対的攻撃と防御」
2021年6月、サイバーセキュリティ企業のKaperskyは、自社のAIモデル対応のアンチマルウェア製品に対する敵対的データ送信による検出回避の実証研究を行い、報告しました。従来よりAIモデルがオブジェクトを誤って分類するようにオブジェクトに小さな変更(ノイズの追加など)を加える方法として、敵対性パッチ(Adversarial Patches)※が知られています。
※敵対性サンプルともいう。
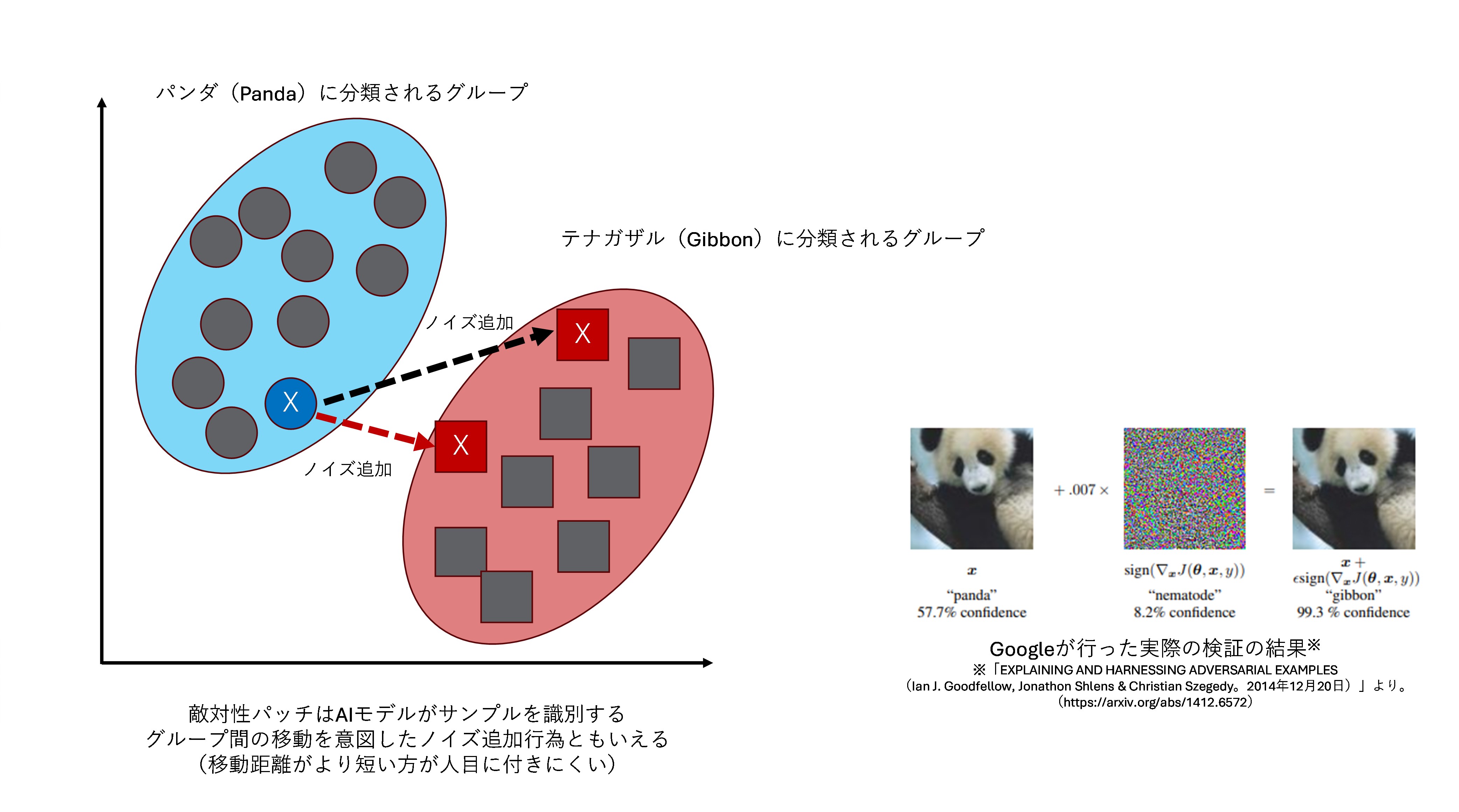
同社では同様の考え方で、安全判定されるPEファイル※からデータシーケンスを抽出しマルウェアのファイルに追加し実験を行いました。結果として、セキュリティ製品のAIモデルの判定スコアに影響を与えつつ、元のマルウェアの機能を維持する手法※で防御回避に成功しました※。
※PEファイル:Portable Executableファイル。Windowsのオペレーティングシステムで使用される実行可能ファイル形式。
※防御回避に成功:詳細としては、セキュリティ製品のクライアントアプリケーションがマルウェアを判定するAIモデルを保持しているケース(ホワイトボックス)と、AIモデルはクラウド上にありクライアントアプリケーションがファイルの特徴を計算した後にクラウドに送信するケース(グレーボックス)で、実験を行った。
検証したKaperskyによれば、作成したほとんどの敵対的ファイルでAIモデル回避に成功したとされており、今後の脅威について警告をしています。
(参考情報)
「How to confuse antimalware neural networks. Adversarial attacks and protection」(Kaspersky。2021年6月23日)
「Confusing Antimalware Neural Networks」(MITRE ATLAS)
まとめ
今回は、MITRE ATLASの各戦術フェーズのうち、Execution(実行)、Persistence(攻撃の永続性の確保)、Privilege Escalation(権限昇格)、Defense Evasion(防御回避)を解説しました。次回も別の戦術フェーズを解説していきますので、ご期待ください。
<シリーズ:MITRE ATLASとは何か?>
第1回:概要編
第2回:偵察~機械学習モデルへのアクセス
第3回:実行~防御回避 ※今回の記事
<関連記事>
・MITRE ATT&CKとは?~Detection&Responseが効果を発揮するには“攻撃シナリオ”ベースの検知こそ重要~
・「AI事業者ガイドライン」から読み解くAI利用時のセキュリティ対策
・AIセキュリティとは何か?(前編)~AIのセキュリティリスクとその対策を考える~
・AIセキュリティとは何か?(後編)~Security for AIとAI for Security~
・「AIのリスク」に対する世界の取り組みを理解する(前編)~主要な組織編~
・「AIのリスク」に対する世界の取り組みを理解する(後編)~イニシアティブ・宣言編~
記事協力

サイバーセキュリティ・イノベーション研究所
スレット・インテリジェンス・センター
トレンドマイクロのサイバーセキュリティ・イノベーション研究所の中核センターの一つ。サイバースレットリサーチを通じ、日本社会と国内組織の安全なセキュリティイノベーション推進を支援する研究組織。日本国内を標的にした高度なサイバー攻撃や国家が背景にあるサイバー攻撃など、グローバルとリージョン双方の視点で地政学的特徴や地域特性を踏まえた脅威分析を行い、日本社会や国内組織に情報提供や支援を行う。


Security GO新着記事

Water Balinsugu(RansomHouse)とは?攻撃手法や特徴を解説
(2026年7月23日)


2025年の標的型攻撃(APT)を総括~サイバー攻撃者がAIを「実戦投入」した年~
(2026年7月10日)
