Artificial Intelligence (AI)
スロップスクワッティング:AIエージェントのハルシネーションにつけ込む攻撃手法
本稿では、AIエージェント特有のコーディング支援における「弱点」を狙った「スロップスクワッティング攻撃」について、その詳細と対策を解説します。


- AIコーディングエージェントは、コーディング支援の際、いかにもありそうですが実在しないパッケージ名を提案することがあります。これはAIエージェントの弱点の1つと言えるハルシネーションから来る現象です。
- そして、この現象につけ込む攻撃手法として、「スロップスクワッティング」と呼ばれる攻撃があります。これはAIを用いたワークフローに潜む近代的なサプライチェーンの脅威と見なせます。
- 「Claude Code CLI」や「OpenAI Codex CLI」、「MCP検証付きのCursor AI」を含む高度なコーディングエージェントであれば、架空のパッケージ名をある程度抑止できますが、完全ではありません。リアルタイムの検証機構を用いても、対処できないパターンも存在します。
- 架空のパッケージ名が生成されるハルシネーションのパターンとして、「強引な文脈補完」や「表層的な擬態」などが挙げられます。AIエージェントは、ユーザ要求や統計的傾向に沿おうとするあまり、実際の存在を検証することなく、もっともらしいパッケージ名を提案してしまう場合があります。
- このリスクを軽減する上では、多層的なセキュリティ対策が有効です。具体的には、ソフトウェア部品表(SBOM)を用いたパッケージの追跡、脆弱性の自動スキャン、サンドボックス環境でのインストール操作、リアルタイムによるパッケージ検証、人手による検証など、各種ベストプラクティスを組み合わせることで、AIによる開発パイプラインの安全性を高められます。
- 本稿で紹介する手法の詳レポートについてはこちらのリサーチペーパー(英語)をご覧ください。
はじめに
AIを活用したコーディングと言えば、次のような光景が思い浮かぶかも知れません。
開発タスクの締め切りが迫る中、AIコーディング・アシスタントがあなたの指示に合わせて関数を自動補完してくれます。また、既存パッケージの利用を提案すると共に、パッケージ管理ツールであるpipのインストールも即座に実行してくれます。そのおかげでコードはスムーズに組み上がり、作業は淀みなく進行していきます。
こうした状態は「バイブコーディング」とも呼ばれ、アイデアが次々とコードに変換されていくことから、一種の魔法のように感じられるかもしれません。しかし、その魔法には、大きな落とし穴が潜んでいることもあります。
今回の調査では、高度なAIエージェントがいかにもありそうな架空のパッケージ名を堂々と提案し、後のビルド工程で「module not found(モジュールが見つかりません)」のエラーとなって発覚する、という事例が確認されました。関連する危険なシナリオとして、攻撃者がこうした架空のパッケージ名を事前にリポジトリ「PyPI」に登録し、そこに不正なコードを仕込み、いつか開発フロー内に取り込まれるのを待ち構えるケースが挙げられます。

AIを用いる開発者にとって、上述の不具合は単にツールとしての不便さに留まるものではなく、新たなサプライチェーン攻撃のリスクを生み出すものです。AIエージェントが幻覚に基づいて架空の依存ライブラリを提示し、未検証のパッケージをインストールするのであれば、攻撃者はAIが作成しがちな架空のパッケージ名をあらかじめ公開リポジトリなどに登録し、そこに不正なコード類を仕込む可能性があります。この攻撃法は、「スロップスクワッティング(Slopsquatting)」と呼ばれています。
本稿では、さまざまなAIエージェントにおいて上記の幻覚症状がどの程度発生するかを検証し、その影響を分析します。また、こうしたリスクから企業や組織の開発パイプラインを保護する上で役立つ対策について、実践的な視点をもとに解説します。
スロップスクワッティングとは
「スロップスクワッティング」は、従来から見れるタイポスクワッティングの進化版と言える攻撃手法です。タイポスクワッティングは人間によるタイピングミスにつけ込む攻撃ですが、スロップスクワッティングでは代わりにAIによるハルシネーション(幻覚)につけ込みます。例えば、もしAIエージェントが幻覚によって「starlette-reverse-proxy」という存在しないパッケージを生成しがちな場合、攻撃者は、同一名の不正なパッケージをリポジトリに公開します。この後、開発者が不用意にAI作成のインストール用コマンドを実行すれば、当該の不正なパッケージがダウンロードされてしまいます。
高度なコーディングエージェントを活用した対策
純粋な大規模言語モデル(LLM:Large Language Model)、または基盤モデルは、もっともらしいパッケージ名を生成しますが、それを検証するためのメカニズムを自前では備えていません。一方、高度なコーディングエージェントは、架空の依存関係をコード内に紛れ込ませないように、追加の推論機能やツールによる検証メカニズムを備えています。以降、最新のコーディングエージェントが持つ代表的な機能を解説します。
Anthropic:Claude Code CLI
外部ツールを用いた拡張思考
Claude Code CLIは、コードを生成する際に、内部的な推論と外部的なツールを動的に活用し、パッケージが実在するかをチェックします。外部ツールとしては、リアルタイムのWeb検索や文書検索などがあり、生成パイプラインの一部に組み込まれています。こうした「拡張思考」のアプローチにより、AIとして提示するパッケージ名の正しさを、静的なデータだけでなく、リアルタイムの証跡に基づいて検証します。
コードベース側のメモリ
Claude Code CLIのエージェントは、多層のメモリ構成により、過去の検証結果やプロジェクト固有のルールを記憶しています。これにより、新たなパッケージのインポートを提示する際に、過去の依存関係に関する検証結果と照合をとることが可能です。
OpenAI:Codex CLI
自動化されたテストやデバッグ
Codex CLIは、テストケースを逐次的に作成し、実行することが可能です。この際、インポートの失敗やテストエラーをフィードバックとして利用し、実在しないライブラリなどを提案候補から削除します。
コードベースの解析
Codexは、言語モデルとしての知識にとどまらず、既存コードベースのインポート文やプロジェクト構造、ローカルドキュメントを解析することで、対象アプリケーションに適したパッケージを提案できます。
Cursor AI:に基づく検証
Cursor AIでは、MCP(Model Context Protocol)サーバを設定することで、依存関係の各候補をリアルタイムで検証することが可能です。本調査では、下記のMCPサーバを利用しました。
- context7:最新のAPIドキュメントをバージョン毎にサンプル付きで提供する。
- sequential-thinking:タスク分割によって問題解決をサポートする。
- tavily(AIの利用):リアルタイムのWeb検索機能を提供する。
AIエージェント間で幻覚の発生頻度を比較
さまざまなAIエージェントが「架空の依存関係」にどの程度対処しているかを調べるため、3種の基盤モデル(GPT、Gemini、Claude)に対して現実的なWeb開発タスク100件を依頼し、幻覚によって提案されたパッケージの件数を調べました。また、Cursor AIやコーディングエージェント(Codex CLI、Claude CLI)に対するテストも行いましたが、自動化が困難なため、基盤モデルで特に幻覚の多かったトップ10のタスクに絞り込み、幻覚によって提案されたパッケージを一件ずつ手動で記録しました。
図4は、結果を可視化したチャートであり、各モデル、各タスクについて、幻覚によって提案されたパッケージ名の件数(0~6)を色別で示しています。全データは、こちらのGitHubからご参照いただけます。
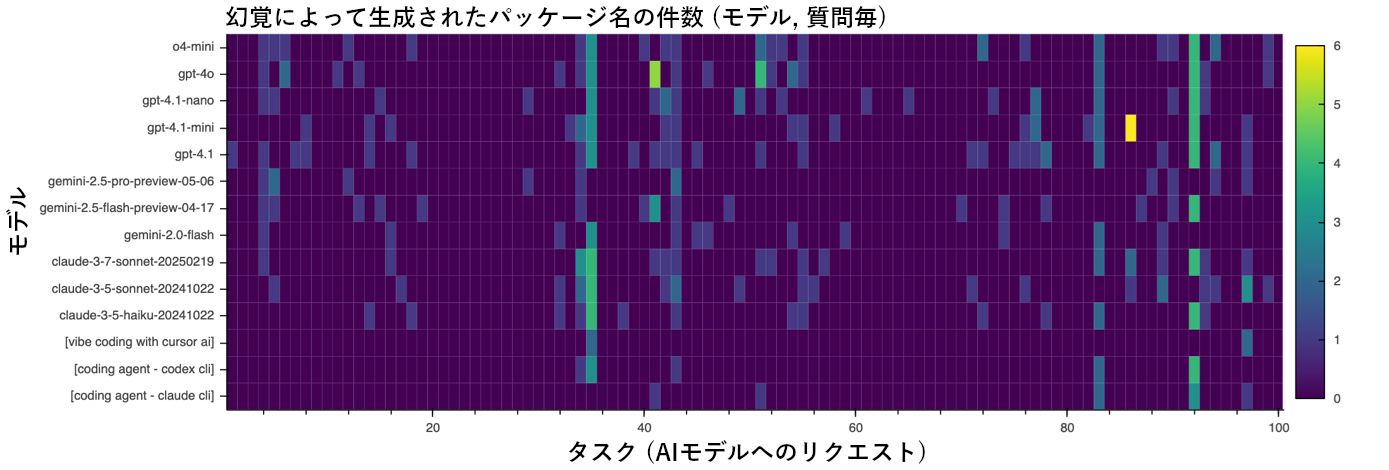
基盤モデルについては、100件に及ぶタスクの過半数に対し、幻覚のない出力を提示しました。しかし、複数の新規ライブラリを含めるように要求された場合は、2~4件の架空のパッケージ名を一度に出力するなど、幻覚の急増傾向が見られました。
こうした幻覚は、特にタスクの依頼文(プロンプト文)が複雑で、かつAIモデルに最新の学習データが反映されていない場合に多発します。生成されるパッケージ名は、馴染みの深い単語をつなぎ合わせた形式(例:graph + orm、wave + socket)となることが多く、いかにも実在しそうな印象を与えます。
コーディングエージェント
高度なコードエージェントは、「段階的思考」に基づく推論機能やリアルタイムのWeb検索機能を搭載し、幻覚の発生率を約半分程度まで削減できます。しかし、基盤モデルと同様、タスクの依頼文が複雑な場合には、少数ながらも(1~2件)幻覚によるパッケージ名が確認されました。その典型的なパターンを、下記に示します。
- 強引な文脈補完:エージェントは、ユーザからの要求(例:「WebSocketを使いたい」、「ORMを使いたい」、「サーバーレスで動かしたい」)を満たすために、意味的に関連する語句を組み合わせてパッケージ名を構成しようとする。結果、完全に一致するパッケージが実在しなくても、当該名を提示してしまうことがある。
- 表層的な擬態:エージェントは、実際のインデックスを照会せず、静的なネーミング習慣に依存してしまう場合がある。このため、接頭辞「opentelemetry-instrumentation-」や接尾辞「-requirements」の添えられた、いかにもありそうだが実在しない「ニアミス型」のパッケージ名が出現する。これは、実在する情報よりも統計パターンを優先した結果と考えられる。
- エコシステムをまたいだ「名前の借用」:Vibe Coding は、複数のプログラミング言語コミュニティから検索結果の断片やGitHubの「README」を採取、集計します。そうした中で、例えばJavaScriptのエコシステムに存在するパッケージ名(例:npmのプラグイン「serverless-python-requirements」)や、ベンダーのドキュメントに記載されたライブラリ名を見つけると、それをPythonの文脈に当てはめて再利用しようとします。しかし、Pythonのパッケージインデックス「PyPI」までは確認しないため、もっともらしい名前でも、実際の対象環境に適用できないケースが生じます。
- 用語結合のヒューリスティック:直接一致するパッケージ名が見つからない場合、Cursor AIは、これまでにペアで見かけた機能用語(例:graphit + orm、morpher)を繋ぎ合わせ、意味的なカテゴリ(例:「グラフデータベースのORM」、「データ変換ツール」)を埋める形で候補を生成します。結果として得られる名前は、統計的にはもっともらしく聞こえますが、完全に架空のものです。
まとめと推奨事項
今回の調査に基づくと、パッケージ名の幻覚は、さまざまな形態のAIコーディングで共通に見られる問題であり、今なおサプライチェーン攻撃のリスクを生み出しています。特に基盤モデルは、複数ライブラリの同梱が必要となるタスクを依頼された際に、いかにもありがちな依存関係を誤って提案する傾向があります。推論の仕組みを強化した高度なエージェントでは、幻覚によるパッケージ名の提示頻度が約半分に削減されたものの、依然としてリスクが残ります。リアルタイムのMCP検証機能を備えたVibe Codingでは、幻覚の発生率がさらに低減されましたが、特異なケースの解決には至っていません。
こうした問題に対し、単純にPyPI上での存在確認を行うだけでは、安全を確保できない点に注意する必要があります。攻撃者は、幻覚によって生成されがちなパッケージ名をあらかじめ登録し、そこに不正なコード類を仕込み、待ち構えている可能性があります。また、正規のパッケージであっても、未修正の脆弱性を含んでいる場合があります。企業や組織では、依存関係の解決を単純な操作一つで終わるものと見なすことなく、厳密なチェックを伴うワークフローとして扱うことが重要です。これにより、本稿で挙げたスロップスクワッティングや、各種サプライチェーン攻撃のリスクを効果的に低減することが可能となります。
推奨事項一覧
- ソフトウェア部品表(SBOM)による出所の追跡:全てのビルドについて、SBOM(Software Bill of Materials)を作成して暗号署名を施し、各依存関係の出所やバージョン情報を追跡できるようにする。
- 脆弱性の自動スキャン:CI/CDパイプラインにスキャン用ツール「Safety CLI(Command Line Interface)」や「OWASP dep-scan」などを組み込み、デプロイ前に、新規または既存のパッケージに含まれる既知の脆弱性(CVE)を検知する。
- インストール環境の隔離:AIが生成したインストール用コマンド「pip install」は、使い捨て用の一時的なDockerコンテナや仮想マシン(VM)内で実行する。検証用のサンドボックスを通過した成果物のみを本番環境に移行させる。
- プロンプトによって検証を要求:AIのプロンプトには、パッケージの存在をインラインで確認するための指示を含める(例:pip index versions)。さらに、最終的なコード出力の前に、リアルタイムでの検証を求める。
- 開発者教育とポリシー策定:エンジニアチームに対して、スロップスクワッティング攻撃のリスクについて教育する。また、依存関係の確認や署名の検証、インシデント対応訓練の実施を必須要件とするように、ポリシーを策定する。
- パッケージの自動インストールが不可避の場合は、脅威の緩和に向けた対策として、厳密なサンドボックス管理の導入と、その必須化を推奨します。
- コンテナによるサンドボックス化:AIが提案したインストール処理は、使い捨てのコンテナや軽量な仮想マシン上で実行する。これにより、仮にホスト環境で問題が発生した場合も、その影響を封じ込めることが可能になる。
- マネージド型クラウドサンドボックス:ネットワークやリソースの制限が課せられたホスト型ランタイムを利用し、各セッション後に対処環境を自動で破棄するための設定を行う。
- 実行毎に環境をリセット:不正なファイルや設定の永続化を防ぐため、各実行の合間にサンドボックスの状態をリセットする。
- 外部ネットワークへの接続制限:未承認レジストリへのアクセスを禁止する。また、未承認の外部通信(egress)を遮断することで、遠隔操作(C&C:Command and Control)サーバへの通信を阻止する。
- 実行前の脆弱性スキャン:AIが提示した依存パッケージの一覧をスキャンし、重大な脆弱性(CVE)を含むものがあれば、インストール前に警告やブロックの措置をとる。
- 監査、ログの記録、モニタリング:インストールコマンドやファイル操作、ネットワーク通話の詳細なログを記録する。また、実行時の挙動モニタリング・ツールを導入し、異常の検知時にはアラート発信や自動環境破棄の措置をとる。
- 人手による承認の介在:新規または見慣れないパッケージについては、人手によるレビューと承認を必須のステップとして導入する。これにより、自動化とセキュリティ監視のバランスを調整する。
- ベースイメージの標準化とポリシーの継続的更新:各サンドボックス環境は、バージョン固定されたクリーンなベースイメージを起点に構成する。また、継続的にセキュリティポリシーやファイアウォール・ルール、ベースイメージを更新し、新たな脅威に先手を打って対処する。
参考記事:
The Rise of Residential Proxies as a Cybercrime Enabler
By: Sean Park
翻訳:清水 浩平(Core Technology Marketing, Trend Micro™ Research)