Artificial Intelligence (AI)
オープンソースAIへの信頼を突く攻撃:サプライチェーンの隠れたリスク
オープンソースのAIモデルがデジタルインフラの基盤となる中、隠されたバックドアや改ざんされたサプライチェーンが、従来のセキュリティツールでは検知できない重大かつ見落とされがちな脅威となりつつあります。


- オープンソースのAIモデルが急速に採用されるなかで、従来のセキュリティツールでは検知が難しいサプライチェーン上の重大な脅威に、組織がさらされるリスクが高まっています。
- バックドアが仕込まれたモデルは、統計的なトリガーとして悪意ある挙動を埋め込むため、静的解析やSBOM(ソフトウェア部品表)、コードレビューではほとんど検出できません。Hugging FaceやGitHubなどのプラットフォームで実際に発生した事例が、このリスクの現実性と拡大傾向を示しています。
- 出所情報の欠如、監査ログの未整備、安全性の低い依存関係、署名標準の不在、そして敵対的テストの不十分さが重なり、AIシステム内にバックドアが見逃される温床となっています。
- こうしたリスクに対処するためには、データの来歴を追跡する仕組み、隠されたトリガーを検出するための動的な振る舞いテスト、堅牢な依存関係管理、そして脅威モデリングや対応を支援するMITRE ATLASのようなフレームワークの活用が求められます。
- システミックなリスクを抑えるには、暗号署名や監査性を担保する標準(本記事で後述するModel Artifact Trust Standardなど)の導入、AI特化型の脅威共有ネットワークの構築、高度な検知プラットフォームの統合といった対策を、AIエコシステム全体で検討する必要があります。
はじめに
私たちは日常的に、事前学習済みの人工知能(AI)モデルをダウンロードして導入していますが、その内部構造に疑問を持つことはどれほどあるでしょうか。オープンソースAIの急速な普及は、産業界に変革的な力をもたらしましたが、それと同時に、見過ごされがちな重大な脆弱性(モデルへのバックドア)も生み出しています。これらのバックドアは従来のバグとは異なり、学習時や配布後に埋め込まれ、特定の入力によってのみ発動するよう潜伏しています。
バックドアが仕込まれたモデルは、独特のセキュリティ上の課題を引き起こします。悪意ある挙動が学習された振る舞いとして組み込まれており、それが特定の条件下でのみ現れるため、従来の検出手法では見つけることが困難です。脅威の現れ方は、モデルの使用目的や運用環境によってさまざまであり、不透明な学習パイプラインや、十分に検証されていないサードパーティの依存関係を通じて、知らぬ間に導入されることがあります。このような場合、脆弱性そのものが「振る舞い」として表出するのです。
広く利用されているHugging FaceやGitHubといったプラットフォームは、オープンソースモデルを一般公開する場を提供していますが、セキュリティの審査はほとんど行われていないのが現状です。AIの進化は目覚ましく、日々新たなモデルがライブラリに加わる一方で、セキュリティ対策は後手に回っており、このエコシステムに潜むあらゆる脅威に対応しきれていません。
今回の調査では、オープンソースAIエコシステムにおいて、バックドア付きモデルがもたらすライフサイクル全体のリスクを検証します。実際のデモをもとに、その脅威の仕組みを解明し、モデル開発やホスティングプラットフォームを通じて発生し得るさまざまな攻撃ベクトルを分析します。そして、検出および緩和に向けた現実的な戦略を提案します。
調査では、MITRE ATLASフレームワークを活用し、取り上げた手法をマッピングすることで、AI特有の脅威とその具体的な現れ方を体系的に理解できるようにしています。このマッピングにより、抽象的なバックドアの挙動を、データ汚染、回避、アーティファクトの改変といった明確な戦術に置き換えることが可能となり、既存のセキュリティ対策における検出と対応の精度が向上します。
本稿の結論では、信頼性のあるAIサプライチェーンを構築するために、モデルアーティファクト信頼基準(MATS: Model Artifact Trust Standard)、プラットフォームレベルでの署名強制、そしてAI特化型の脅威情報共有ネットワークの設立といった、政策・標準化に関する提言を示しています。
ここで求められているのは、私たちのアプローチそのものを見直すことです。AIモデルをソフトウェアとして扱い、その「振る舞い」を攻撃対象として捉え、静的なコードスキャンを超えた防御策を構築する必要があります。AIのセキュリティは、単に可視化するだけでは不十分であり、モデルのライフサイクル全体にわたる構造的な責任体制が求められます。
オープンソースのAIモデルは、現代のデジタル基盤に不可欠な存在となっており、カスタマーサポートのチャットボットから医療診断システムに至るまで、さまざまな用途で活用されています。最近のマッキンゼーの調査によれば、テクノロジー関連の組織の72%がオープンソースAIモデルを導入しており、その広範な普及を示しています。
しかしながら、このような急速な統合の流れの中で、ソフトウェアサプライチェーンにおける重大な盲点が浮かび上がっています。それが、AIモデルというアーティファクトそのものです。従来のソフトウェアコンポーネントとは異なり、AIモデルは構造が複雑で不透明な部分が多く、作成元や学習データ、関与した人物に関する情報が明らかでないことが一般的です。この不透明性が、学習やファインチューニングの段階でバックドアを仕込むといった悪意ある改ざんを許す温床となっています。
これらのバックドアは、通常の利用環境では表面化せず、特定のトリガーが与えられたときにのみ作動します。その結果、データ漏洩、誤分類、不正な動作などが発生する可能性があります。ソフトウェア部品表(SBOM)や静的コード解析ツールといった従来のセキュリティ手法では、AIモデル内のこうした脅威を見つけるのは困難です。
JFrogの調査によると、Hugging Face上に公開されている100万以上のモデルのうち、400件に悪意あるコードが含まれていたことが判明しており、検証されていないオープンソースAIモデルに伴う現実的なリスクが浮き彫りになっています。
今回の調査では、以下の目的を掲げています。
- オープンソースエコシステムにおいて、新たに顕在化しつつあるバックドア付きAIモデルの脅威を明らかにすること。
- 実際の事例や、発生し得る脅威シナリオを提示すること。
- AIモデルというアーティファクトを、安全なソフトウェアサプライチェーンの枠組みに組み込むための基本的な実践とツールを提案すること。
- 機密情報の漏洩
- 権限のない操作の実行
- データの誤分類
- 一見無害に見える挙動の中に有害なロジックを埋め込むこと
従来型のバックドアとは異なり、AIモデルにおけるバックドアは根本的に異なるセキュリティ課題をもたらします。膨大なベクトルの行列を思い浮かべてください。正常なモデルと悪意あるモデルの違いは、数値的な重みのわずかな変化にすぎません。このような統計的特性のため、従来のスキャンやリバースエンジニアリングによってバックドアを発見することは、ほぼ不可能です。
バックドア付きAIは、「振る舞いそのものが脆弱性である」という新たな脅威の一種です。静的な検査では検出できず、学習されたパラメータの層の奥深くに隠れています。特に、コードの透明性に信頼を置くことの多いオープンソースのエコシステムにおいては、AIモデルが本質的に透明性を欠いていることから、その危険性は一層深刻です。
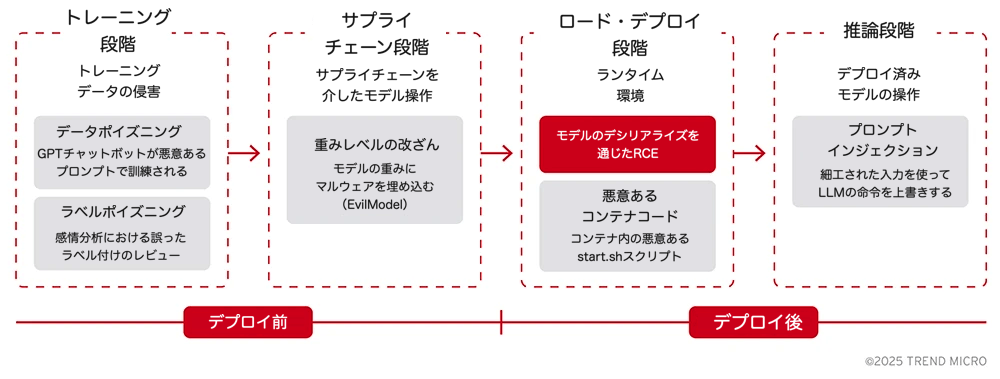
モデルに対するバックドアの種類
AIモデルへの攻撃は、機械学習ライフサイクルのどの段階が悪用されているかによって分類すると、理解しやすくなります。
1. 学習フェーズへの攻撃:基盤の汚染
このタイプの攻撃は、データ収集や学習プロセスに潜む脆弱性を突き、モデルのロジックそのものに脆弱性を埋め込むものです。
- データポイズニング:悪意あるデータを学習データに紛れ込ませることで、モデルに意図的な偏りやバックドアを学習させます。モデルはそれらの悪意あるパターンを正当な情報として記憶してしまいます。
- 例:GPTベースのチャットボットに対して、特定の入力で危険な振る舞いを誘発するような毒入りの会話データを意図的に含めて学習させるケース。
- ラベルポイズニング:データポイズニングの一種で、学習データのラベルを攻撃者が意図的に書き換えることで発生します。特にファインチューニングの段階でこの攻撃が行われると、もともとクリーンなベースモデルが、形式的には正しく見えるが実際には誤ったラベルが付けられたデータによって、静かに改ざんされる危険があります。
- 例:競合製品に関するポジティブなレビューに「ネガティブ」というラベルを付けて学習させることで、感情分析モデルがその競合製品に否定的な評価を返すように仕向ける。
2. 保存・配布(サプライチェーン)フェーズへの攻撃:学習後の改ざん
このタイプの攻撃は、モデルの保存、共有、配布の方法に存在する脆弱性を突くもので、学習が完了した後、実運用に入る前の段階で発生します。
- 重みレベルでの改ざん:モデルファイルにアクセス可能な攻撃者が、代替最適化などの敵対的手法を使って、ニューラルネットワークの重みやバイアスを直接操作します。これは、再学習を行うことなく、非常に高い精度でマルウェアをモデルに埋め込むことが可能であると、「EvilModel」などの研究で実証されています。
- 例:学習済みモデルの重みのうち一部の最下位ビットに、任意のバイナリマルウェアコードを埋め込むことで、パフォーマンスへの影響を最小限に抑えながら、マルウェアが潜むAIモデルとして流通させることができます。
3. ロード・展開フェーズへの攻撃:実行時環境の悪用
このタイプの攻撃は、モデルのロジックそのものではなく、モデルファイルの読み込みや実行方法における不適切な運用を標的とします。
- デシリアライズによるリモートコード実行(RCE):一部のモデル形式(例:Pythonのpickle形式や古いPyTorchの*.pt_ファイル)は、本質的にコードの実行が可能な構造になっています。攻撃者は、シリアライズされたモデルファイル内に悪意あるコードを埋め込み、モデルの読み込み時にそれをサーバ上で実行させます。
- 例:.pklファイル内に埋め込まれたペイロードが、読み込まれた瞬間に攻撃者のマシンと接続するリバースシェルを開くケース。
- モデルコンテナ内の悪意あるコード:近年のプラットフォーム(例:Ollamaなど)では、モデルをコンテナイメージ(例:OCI形式)としてパッケージ化するケースが増えています。攻撃者は、正規のモデル重みに加えて、悪意のあるスクリプトやバイナリをコンテナ内に同梱することで、コンテナ起動時にコードを実行させることが可能になります。
- 例:モデルコンテナ内に含まれる悪意ある_on-start.sh_スクリプトが、環境変数や認証情報を外部に送信するケース。
バックドアが引き起こす挙動
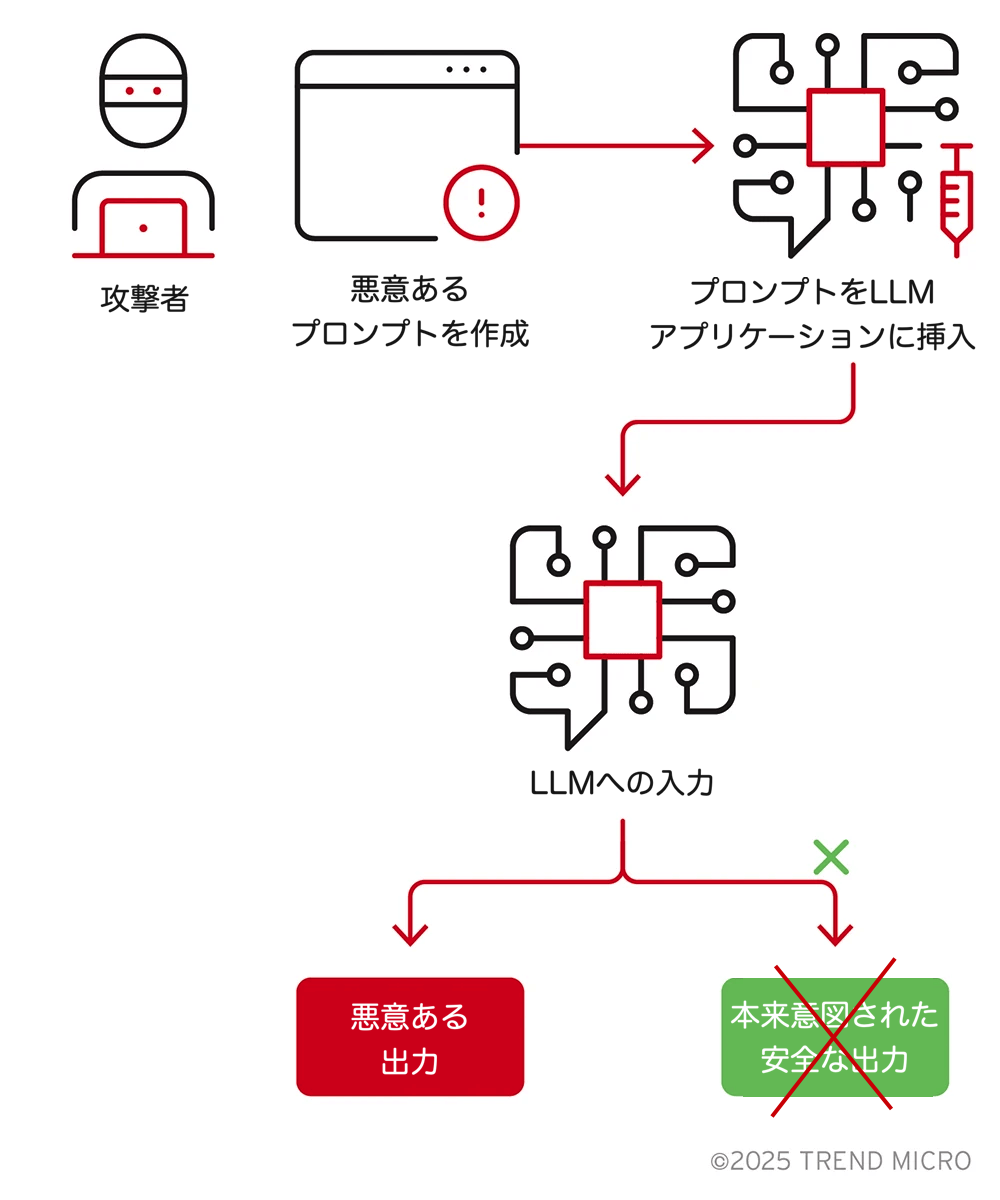
前述の攻撃は、さまざまな悪意ある挙動を引き起こす可能性があります。なかでも最も一般的で知られているものが、「トリガー型バックドア」です。
- トリガー型バックドア:これは、データポイズニングや重みの改ざんといった攻撃の結果として現れるものです。改ざんされたモデルは、ほとんどの入力に対しては通常どおり動作しますが、特定の「トリガー」に遭遇したときのみ、意図的な悪意ある挙動を示します。このトリガーは、特定の単語、フレーズ、画像、あるいはパターンで構成されていることがあります。
- 例:データポイズニングによって改ざんされた画像認識モデルが、あらゆる交通標識を正しく識別する一方で、ストップ標識に特定の黄色いステッカー(トリガー)が貼られている場合に限り、それを「制限速度85」の標識と誤認識するケース。
検出の難しさ
これらの脅威の検出を困難にしている要因はいくつか存在します。
- 不透明なアーキテクチャ:モデルの重みは複雑な数値行列で構成されており、悪意あるロジックが文字列や関数のように明示的に現れるわけではありません。
- 「正解」が存在しない:大規模言語モデル(LLM)など創造的な出力を行うモデルでは、何が「期待される」出力で、何が「操作された」出力なのかを明確に判断することが難しいです。
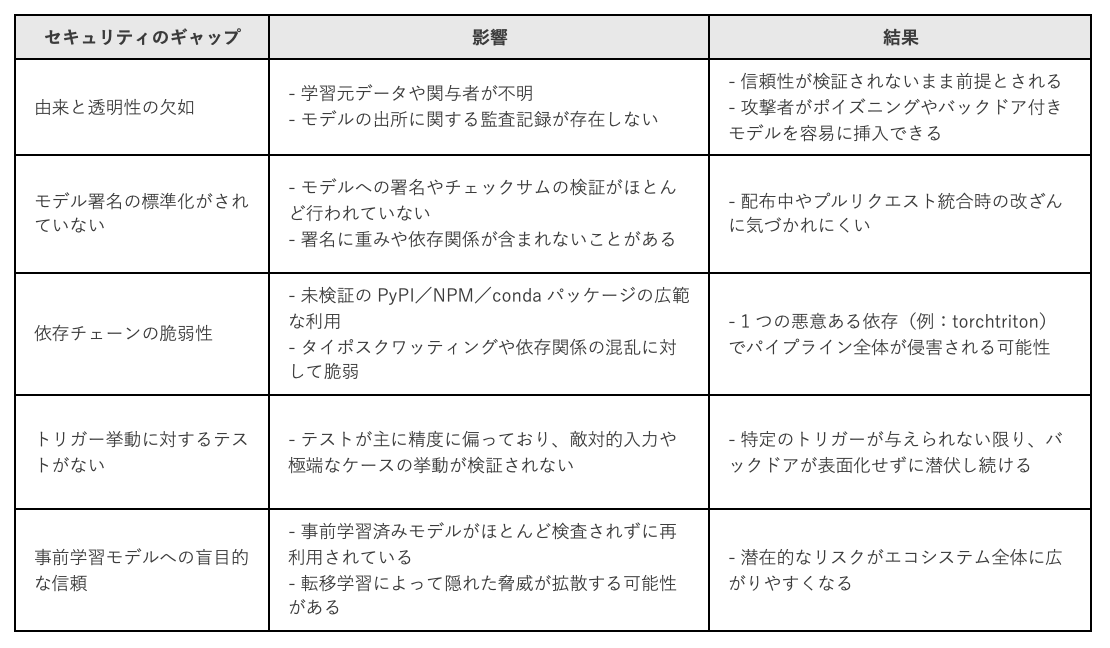
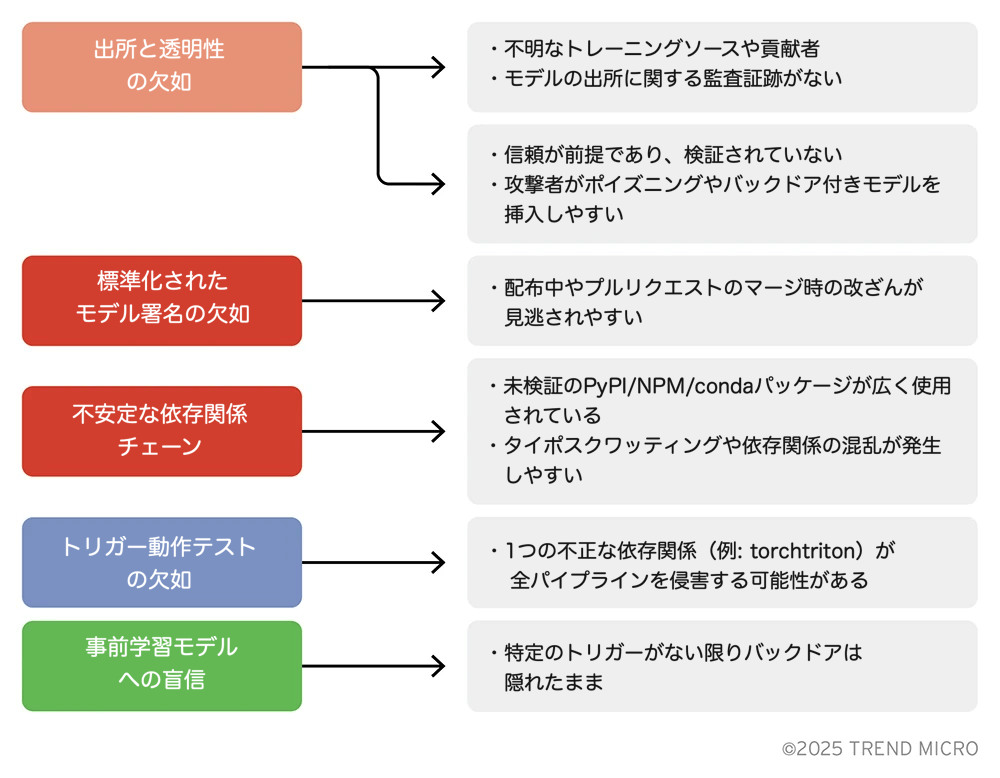
- 由来情報の欠如:多くのモデルには、学習に使用されたデータ、ハイパーパラメータ、チューニングの詳細といったメタデータが欠けています。
- テストの限定性:多くの組織では、モデルを想定された用途に対してのみテストしており、わずかな画像ノイズ、物理的なステッカー、1ピクセルの変更、言葉の言い換え(同義語、類似文字)、タイプミス、プロンプトインジェクション、可聴域外の音声などの敵対的入力については十分な検証が行われていません。
- 知識と経験の不足:現在はAI導入の初期段階にあり、こうした高度な攻撃を特定・緩和するための深い理解や確立されたベストプラクティスが、全体としてまだ不足しています。
主な実証例
- BadNet(2017年):黄色い四角形が表示された際にストップ標識を誤認識するよう訓練された畳み込みニューラルネットワーク(CNN)。
- EvilModel(2021年):一見無害なAIモデルの中に、パフォーマンスへの影響を最小限に抑えつつマルウェアを隠し持たせる手法を実証。
- Hugging Faceのインフラリスク(2023年):Wizが、Hugging Faceプラットフォームにおいて公開状態のトークンや脆弱な分離環境を発見。ホスティングインフラを経由したモデル改ざんのリスクを示唆。
- 画像類似性チャレンジ DISC21(2021年):大量のノイズ画像の中から改ざん画像を検出する課題を通じて、画像モデルの脆弱性が浮き彫りにされた事例。
- Hugging Face上の悪意あるモデル(2024年)
- 攻撃経路: モデルカードやメタデータに仕込まれた悪意あるペイロード
- 影響: Hugging Face経由で開発者環境が侵害される事例
- 出典: JFrog Security
- LLMに対するプロンプトインジェクション攻撃(2023~24年)
- 攻撃経路: 入力の工夫によってモデル挙動を上書き
- 影響: プロンプトの漏洩、APIの悪用、不正確な出力の誘発
- 出典: arXiv
- AML.CS0028:サプライチェーンを通じたAIモデル改ざん(2023年)
- 攻撃経路: サプライチェーンの侵害
- 影響: クラウドベースのコンテナレジストリの脆弱性を悪用し、信頼されたチャネルを通じてバックドア付きモデルが配布されるケース
- 出典: MITRE ATLAS
- PyTorch依存関係のハイジャック(torchtriton)(2022年)
- 攻撃経路: PyPIにおけるタイポスクワッティングや依存関係の混乱
- 影響: システムのフィンガープリント取得およびデータの外部送信
- 出典: PyTorch
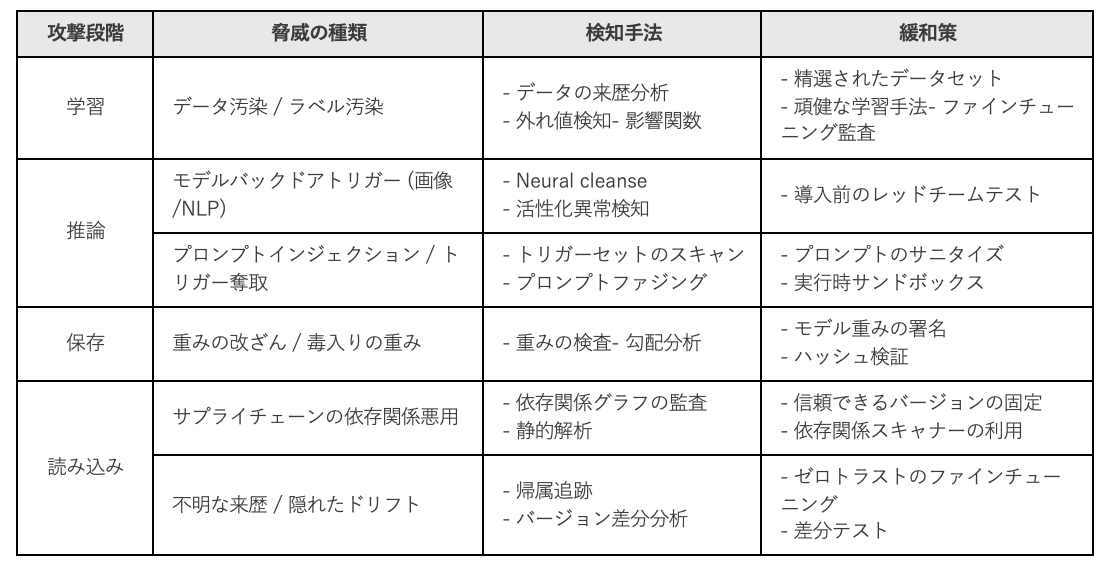
この表は、現実のリスクと実践的な対策を対応づけたもので、開発者、MLOpsエンジニア、セキュリティチームがより安全なオープンソースAIシステムを構築するために利用できるものです。
AI脅威マッピングのためのMITRE ATLAS
AIシステムに対する体系的な脅威モデリングやレッドチーミングを支援するために、防御側はMITRE ATLASフレームワークを採用するべきです。ATLASは機械学習システムを標的とした現実世界の手法をカタログ化し、検知と対応の戦略を導くための共通の分類体系を提供します。
バックドア検知に関連するATLASテクニック
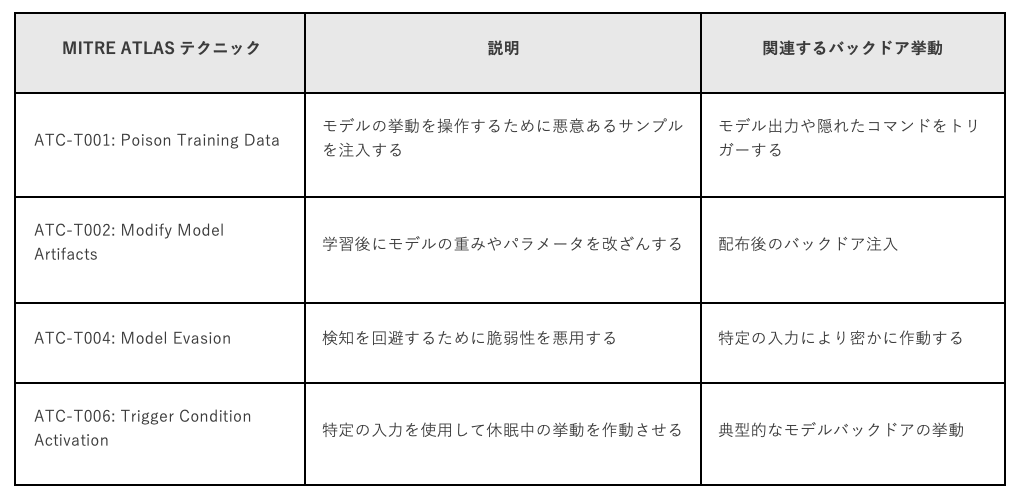
MITRE ATLASを統合することで、防御側はAI特有の脅威を従来のセキュリティオペレーションセンター(SOC)の活動に結び付け、レッドチーム活動、脅威インテリジェンス、行動分析ワークフローを強化することができます。
この連携を基盤としてMITRE ATLASが提供する知見を完全に運用に活かすためには、単なる脅威マッピングにとどまらず、リアルタイムでリスクを緩和するセキュリティソリューションが必要です。
そのためには、脅威インテリジェンスを高度な検知、監視、対応機能と統合し、AIシステム特有の課題に合わせて設計されたプラットフォームが必要です。こうしたソリューションは、データの完全性やモデルの挙動、APIの利用、インフラのセキュリティに至るまで、AIライフサイクル全体にわたる脆弱性に対応できなければなりません。MITRE ATLASの戦略的な指針と先進的な能動防御ツールを組み合わせることで、組織は理論的な脅威マッピングから実行可能な防御戦略へと移行し、AIを活用した業務に対して包括的なセキュリティを確保できるようになります。
Trend Vision One™
Trend Vision One™は、AI関連の脅威に対する高度な保護を提供するエンタープライズ向けのサイバーセキュリティプラットフォームです。主な特長は以下のとおりです。
- AIを活用した脅威検知: モデル改ざんやデータ汚染を含むAIシステムへの攻撃を検知・予測・防止するための専門的なAI技術を活用します。
- 統合型テレメトリー分析: エンドポイント、ネットワーク、クラウド環境からのデータを組み合わせ、潜在的な脅威や機密データの漏洩を一元的に把握します。
- 振る舞い監視: AIモデルの挙動を継続的に監視し、侵害の兆候となる異常を特定します。
- 予防的リスク管理: 予測分析を用いて、攻撃者に悪用される前にリスクを特定・緩和します。
- アップロードされるモデルファイルや関連アーティファクトに対して暗号学的署名を強制します。
- 学習データの出典、ハイパーパラメータ、モデルの来歴など、完全で標準化されたメタデータを必須とします。
- アップロード時にマルウェア、不正スクリプト、疑わしい依存関係を自動スキャンします。
- モデルのアップロード、更新、削除に関する改ざん不可能な監査ログを保持し、API経由でアクセスできるようにします。
- プラットフォーム、ベンダー、研究者間でAI特有の脅威インテリジェンスを共有できるようにします。
モデル開発者と貢献者
- トレーニングスクリプト、データ参照、設定ファイルへのオープンアクセスを含む再現可能なトレーニングパイプラインを使用します。
- 下流での整合性を確保するために、モデルの重みや学習コードに署名を行います。
- 確認済みで積極的にメンテナンスされている依存関係のみを使用し、廃止予定や未検証のパッケージは避けます。
- 安全かつ期待通りのモデル性能を示す動作テストスイートを含めます。
- 微調整に使用したデータセット名、出典、手動でのデータ介入をモデルのドキュメントで明確に開示します。
AIビルダーおよび下流の利用者
- すべての事前学習モデルをデフォルトで信頼しないものとして扱い、統合前に検証を行います。
- 異常活性化やレッドチーミングなどの動作テストを実施し、潜在的なバックドアを検出します。
- 信頼できるレジストリから検証済みかつ署名済みのモデルを使用します。Dockerのようなプラットフォームは、モデルの真正性と完全性を保証する暗号署名を組み込んだ「信頼できる」モデルレジストリの提供を進めています。こうした検証を行っているソースを優先してください。
- 依存関係のバージョンを固定し、既知のリスクを検出するためにサプライチェーンスキャナーを使用します。
- モデルの実行をコンテナ化やサンドボックス化によって分離し、横方向の移動やシステムアクセスを制限します。
- モデルが侵害された場合のリスクを軽減するために、高リスクまたは本番環境ではアンサンブル手法や多層的な意思決定システムを採用します。
- Trend Vision Oneのような、テレメトリー統合や異常検知機能を備えたプラットフォームを導入し、AI駆動プロセスから発生する疑わしいモデル挙動や横方向の移動を検知できるようにします。
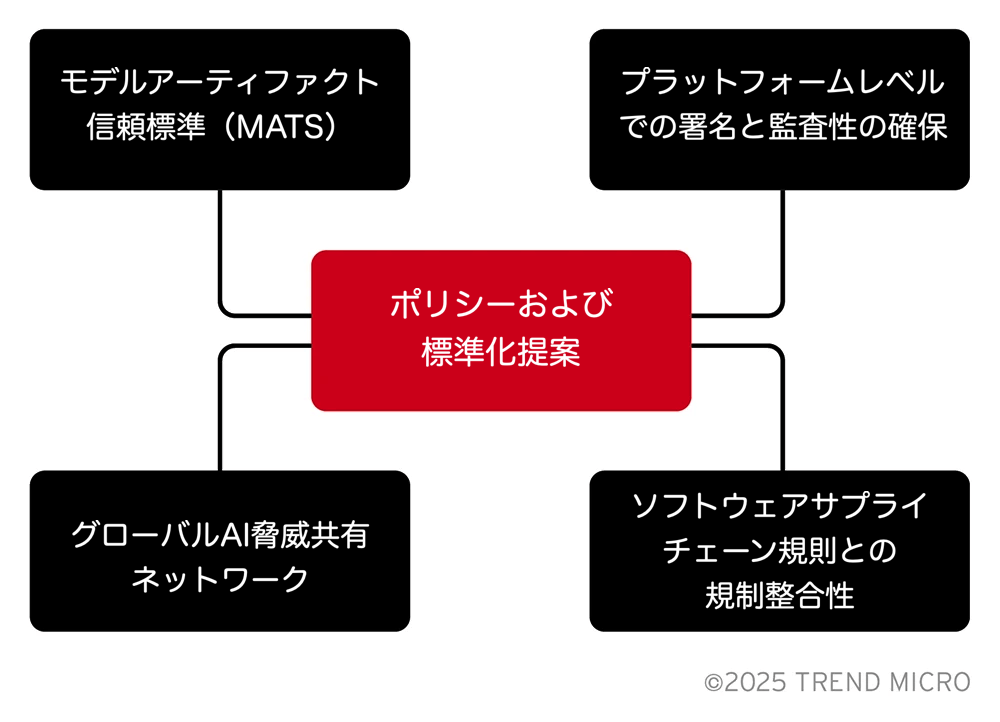
モデルアーティファクト信頼標準(MATS: Model Artifact Trust Standard)
SPDX 3.0 AI-BOMの基盤に基づき、既存の標準を拡張してモデル固有のセキュリティ要件に対応する提案として、モデルアーティファクト信頼標準(MATS: Model Artifact Trust Standard)を提示します。
- 学習データの来歴: データセットの出典、収集方法、前処理手順を明確に記録します。
- 依存関係の完全なマニフェスト: ライブラリやフレームワークだけでなく、記録されたモデル重みや環境構成も維持します。
- 暗号化された重みのハッシュ: モデルファイルの改ざん検知を可能にします。
- ファインチューニングの系譜: 転移学習のバージョン、日付、手法を追跡します。
- 挙動検証の証拠: 敵対的ロバストネステストの結果やトリガーに基づく挙動の要約を含めます。
SPDXのAIプロファイルにはすでに、基本的なメタデータ(モデル名、バージョン、作成者)、データセット参照(ライセンスや出典を含む)、モデルの来歴、ソフトウェア環境、依存関係といった要素が含まれていますが、MATSはこれにセキュリティに関連するメタデータや挙動テストをより重視して追加します。
重要な理由: MATSはAIモデルのサプライチェーンに実用的なインテリジェンスを導入し、来歴を検証可能にし、自動化されたリスク評価を可能にし、モデルアーティファクトを既存のソフトウェアコンプライアンスおよびセキュリティフレームワークに適合させます。
プラットフォームレベルでの署名と監査性の確保
Hugging FaceやGitHubなどのプラットフォームに対して以下を要求します。
- デフォルトで暗号学的なモデル署名をサポートすること。
- すべてのモデルのアップロードおよび変更を改ざん不可能な監査ログに記録すること。
- 検証用の公開APIを提供すること。
重要な理由: これらの対策を実施することで、改ざんや悪意ある行為者を特定するための証跡管理が構築されます。
ソフトウェアサプライチェーン規則との規制整合性
EU Cyber Resilience Act(CRA)を拡張し、AIモデルを明示的に対象に含めます。これは、NISTがSecure Software Development Framework(SSDF)をAI特有のリスクに対応するためにNIST 800-218Aへ拡張したのと同様の対応です。
- モデルをソフトウェアライフサイクル内のアーティファクトとして扱うこと。
- 事前学習モデル、ファインチューニング済みモデル、合成モデルのリスク分類を行うこと。
重要な理由: AI特有の攻撃対象領域は、現行の政策や保険基準にはまだ反映されていません。
グローバルAI脅威共有ネットワーク
CVE/CWEモデルに類似した、AIシステム専用に設計された協調フレームワークを構築します。
- プロンプトインジェクション手法、モデルバックドア、データ汚染ベクトルを含めること。
- レッドチーム、研究者、ベンダーからの脅威情報提供を奨励すること。
- 防御側やセキュリティ専門家に大きな利益をもたらす強固な情報共有を確保すること。
- 事前学習モデルへの信頼のあり方を見直すこと。
- 振る舞いテストを例外ではなく標準として取り入れること。
- 検証可能な来歴と管理された依存関係を備えた安全なモデルパイプラインを構築すること。
- MITRE ATLASのようなフレームワークを活用し、AI特有の脅威を既知の敵対的行動にマッピングし、体系的な緩和を実現すること。
- Trend Vision Oneのようなプラットフォームを利用し、テレメトリーや異常検知によってAIモデルの不審な挙動や移動を明らかにすること。
バックドアを仕込まれたモデルは、楽観的な見通しや受動的な監視では止めることができません。AIに対しても、他のすべてのソフトウェアエコシステムで求められるのと同じ厳格さとテストを適用する、意図的かつ積極的なセキュリティ体制が必要です。
参考記事:
Exploiting Trust in Open-Source AI: The Hidden Supply Chain Risk No One Is Watching
By Ashish Verma and Deep Patel
翻訳:与那城 務(Platform Marketing, Trend Micro™ Research)