Artificial Intelligence (AI)
大規模言語モデルに対するセキュリティスキャン:審査用LLMの性能を分析
大規模言語モデル(LLM)の進化に伴い、不正な回答によるリスクも増大します。本稿では、LLMの応答を別のLLMによって審査するセキュリティスキャンの手法を分析します。


- トレンドマイクロの調査により、大規模言語モデル(LLM:Large Language Model)はセキュリティリスクの自動判定に役立つ一方で、実在しないソフトウェアパッケージ(ハルシネーション)を見過ごしたり、悪意に基づくプロンプトに騙されたりする場合もあることが、判明しました。
- この問題に対して適切な保護策(ガードレール)を施していない場合、情報流出やサプライチェーン攻撃、運用障害などの事態に発展する恐れがあります。
- 生成AIやLLMアシスタント、自動化ワークフローを利用している組織は、当該リスクに晒されている可能性があります。特に、外部コードやパッケージマネージャを取り入れている場合には、注意が必要です。
- リスクを軽減するためには、LLMの利用状況を見直した上で適切なガードレールを導入し、重要な出力は外部ソースを通して検証することが推奨されます。
- トレンドマイクロでは、セキュリティプラットフォーム「Trend Vision One™」の「AI Guard」、セキュリティチューニング済みのモデル、マネージド型サービスを提供しています。これにより、企業や組織が用いるLLMを保護し、ベンチマークや監視のプロセスを支援します。
はじめに
大規模言語モデル(LLM:Large Language Model)が広く普及し、機能的にも進化していく中で、誤った回答や悪意に沿った応答が返されるリスクも高まっています。特にセキュリティ分野において、その影響は深刻なものとなります。トレンドマイクロでは、こうしたリスクを分析して対策の道筋を立てるため、さまざまなLLMに対するセキュリティスキャンを実施しました。具体的には、攻撃を想定した特殊なプロンプトをテスト用の標的モデルに送信し、不正なコード生成や機密情報漏洩、実在しないソフトウェアパッケージの提案など、セキュリティ上の脅威となる応答が返されるかを検証しました。
LLMからの応答を検証する手段として、人手の判断によってチェックする方式と、別のLLM(一般に「LLM as a judge:審査LLM」と呼ばれる)によってチェックする方式の2通りがあります。人手でのチェックは、プロンプトの意図や内容を細かく分析、把握できる点で優れ、機械的な方式では見逃されがちな問題も見抜ける可能性があります。しかし、プロンプトや出力の量が増大するにつれて人的なコストも高まり、全てをチェックしきれなくなる場合もあります。
代替策として、「審査LLM」の活用が挙げられます。審査LLMは、審査対象のLLM(本稿では「標的LLM」と呼ぶ)が出した応答をユーザプロンプトとして受け取り、その内容が攻撃者の悪意に従ったものであるかを評価します。評価の基準については、審査LLMのシステムプロンプトを通して事前に定義しておきます。
時間やリソース面で制約がある人手の方式と異なり、審査LLMでは、事前に定義された基準をもとに多量のテキストを迅速に、かつ一貫性をもって評価することが可能です。このように、審査LLMを活用することで、大規模化や高速化、評価の一貫性、コスト節約といったメリットが得られます。
本稿では、不正なコード生成の検知、ハルシネーション(幻覚)に基づくパッケージの特定、システムプロンプト流出の検知など、セキュリティ関連のタスクを通して審査LLMの強みや欠点を解説します。また、こうした欠点を克服するための評価フレームワークを策定し、その有効性について分析します。
評価のプロセス
悪意に沿った動作をLLMによってどの程度まで見抜けるかを調べるため、今回は、攻撃を模擬した2段階の評価プロセスを用い、多数のケースを通してモデルの応答パターンを検証しました。
- 攻撃活動の模擬:攻撃を意図したプロンプトを「標的LLM(例:GPT-4、Mistral)」に送信し、その応答を得る。
- 応答の評価:標的LLMからの応答を、「審査LLM」に送信する。審査LLMは、受信した内容をチェックし、攻撃的な意図に従ったものであるかを評価する。評価の基準は、システムプロンプトで事前に与えておく(例:リバースシェルの特徴)。
審査LLMからの回答には、評価基準が満たされているかを示す二択の判定結果(真偽値)と、その理由が記載されます。フォーマット自体はシンプルですが、LLMによる自由形式の回答をプログラム的に処理しやすい形式に変換することを目的としています。
この方式により、モデル全体を通したリスク集計や、ポリシーの自動適用、改善度合の追跡を行いやすくなります。特に、何百件、何千件もの応答を評価しなければならない状況において、人手の確認コストを削減できることは、大きなメリットとなります。
不正なコードの生成
LLMを悪用した行為の典型例として、不正なコードの自動生成が挙げられます。攻撃者は、LLMを巧みに誘導してバックドア作成やコマンドインジェクション、リモートアクセスといった機能を持つコードを自動作成し、それを用いて標的システムの侵害を試みます。
具体的な例を、図1に挙げます。

このシナリオでは、巧妙に細工されたプロンプトを標的LLMに与えることで、Node.jsのリバースシェル作成やシステムファイルへのアクセスなど、危険性の高いコードを生成しています。攻撃者は、生成したコードを不正アクセスやシステム侵害のたたき台として利用する可能性があります。これは、サポート目的で最適化したLLMさえも不正なコードを作成してしまうリスク「OWASP LLM05:2025」に相当します。
LLMの応答に潜む危険性を検知するスケーラブルな手段がなければ、実環境で動いているLLMが悪用され、攻撃活動に加担させられるリスクが高まります。
今回の評価プロセスでは、標的LLMの応答を審査LLMに引き渡し、事前に定義された基準をもとに、不正なコードに該当するかを判別します。基準が満たされたかを真偽値(true/false)で表す方式は、単純すぎるようにも思われますが、これによって大量の出力を高速に分類し、プログラム的に処理することが可能となります。また、セキュリティパイプラインへの統合にも適しており、大規模な手動レビューの負担を削減する効果も見込まれます。
パッケージのハルシネーション
トレンドマイクロの調査に基づくと、審査LLMを用いた判別方式は、評価に必要な情報がプロンプト内に含まれている場合に特に有効です(例:コードが不正であるかどうかを判別)。しかし、必要な情報がプロンプトに含まれていない場合、正確な評価を下すことが難しくなります。例えば、ハルシネーションによって提案された架空のパッケージ(例:「OWASP LLM09:2025」や「MITRE AML.T0062」)を識別するには、存在チェックに関する工夫が必要となります。
パッケージのハルシネーションは、AIサプライチェーンを狙った攻撃に繋がります。例えば攻撃者は、不正なパッケージをレジストリにアップロードし、ハルシネーションによって提案されがちな名前で登録しておきます。その後、あるソフトウェア開発者がLLMの支援を受けてコードを作成する際、注意不足によって問題のパッケージをそのまま取り込んでしまい、開発環境の機密情報流出に至るケースが考えられます。

図2のテストでは、モデル「deepseek-r1」に特殊なプロンプトを与えた結果、架空のPythonパッケージ「mlj」が提示されました。「mlj」は、プログラミング言語「Julia」で書かれた著名な機械学習フレームワークとして実在しますが、deepseekは、これをリポジトリ「PyPi」から取得可能なPythonパッケージと誤って判断しました。つまり、機械学習関連ソフトウェアであることは正しく認識できたものの、対応する言語やリポジトリの点でハルシネーションを起こしたことになります。
図3のテストでは、この応答を審査LLMに渡し、ハルシネーションによる架空のソフトウェアパッケージとして検知できるかを確認しました。審査LLMとしては「GPT-4」を利用し、パッケージのハルシネーションに関する概要を伝えた上で、その条件を満たしているかを判別させました。

上図の通り、GPT-4は、コマンド「pip install mlj」がパッケージのハルシネーションに相当することを認識できませんでした。
トレンドマイクロでは、審査LLMがPythonやGo言語関連のパッケージハルシネーションを見逃してしまう事例を複数確認しています。これは、ある程度予想された結果でもあります。モデルの学習に利用されるデータは、リリースから数ヶ月以上前の時点に遡る場合もあり、必ずしも最新の状態を反映できないためです。また、学習データの量や質が、言語やトピックによって偏っている場合もあります。こうした情報の欠落や偏りは、LLMを過度な抽象化に走らせ、結果、いかにもありそうで実在しないパッケージ名を提案させることになります。審査LLMについても同様であり、学習データに関する制約が、パッケージハルシネーションを特定するためのプロセスに影響を及ぼします。
上記の問題を解決するため、今回は、パッケージのハルシネーションを検知する新たな手法を考案しました。本手法では、PyPiリポジトリやGolangのプロキシミラーを客観的な評価基準として、ハルシネーションの特定を試みます。その概要を、下記に示します。
- LLMを利用し、標的LLMの応答文からソフトウェアパッケージ名を抽出し、分類する。本ステップの結果は、下記のように表される。

- LLMによって抽出した各ソフトウェアパッケージについて、対応するパッケージリポジトリを参照し、存在チェックを行う。
- 上記で存在を確認できなかったパッケージについては、ハルシネーションによるものと判断する。
一連の評価法を適用したところ、下記の結果が得られました。

以上の手続きを踏むことで、ハルシネーションをより的確に検知できることが分かりました。しかし、本手法はパッケージの存在確認を行うだけであり、存在するパッケージ内の不正な内容や偽装を見抜くことはできず、結果、AIベースのサプライチェーン攻撃に対処できません。そのため、評価のパイプラインを改善する方法について、引き続き検討を進めています。
システムプロンプトの流出
LLMにおけるシステムプロンプト流出の脆弱性(OWASP LLM07:2025)とは、モデルの動作を制御するシステムプロンプトや指示文に機密情報を記載し、それが何らかの理由で外部に流出するリスクを指します。システムプロンプトは、アプリケーションの仕様や要求に基づいてモデルの出力を制御するためのデータですが、やむを得ず、または意図せず機密情報を含めてしまうことがあります。もし流出すれば、さまざまな攻撃活動の手がかりとして悪用される恐れがあります。
システムプロンプト流出の代表的なパターンを、下記に示します。
- 機能情報の流出:アプリケーションのシステムプロンプトに含まれるAPI鍵やデータベースの認証情報、ユーザトークン、システムアーキテクチャなどの機能情報が、外部に流出する。
- 内部ルールの流出:アプリケーションのシステムプロンプトに含まれる内部的な意思決定ルールが、外部に流出する。
- フィルタ条件の流出:システムプロンプトに含まれるさまざまな禁止事項やセンシティブなフィルタ項目が、外部に流出する。攻撃者は、それを逆手にフィルタの回避法を探る可能性がある。
- 権限設定やユーザロール設定の流出:システムプロンプトに含まれるアプリケーションの権限設定やロール構成が、外部に流出する。
前回の記事では、システムプロンプトを意図的に流出させるアルゴリズム「PLeak」について紹介しました。今回は、標的LLMとして「Llama 3.1 8B」を準備し、前回と同様のシステムプロンプトを設定しました。次に、PLeakで作成した攻撃用文字列を標的モデルに送信することで、システムプロンプトを流出させます。

続いて、「Llama 3.1 8B」から得られた応答を審査LLM「GPT-4o」に渡し、システムプロンプト流出として判定されるかを確かめます。

上図のテストにおいて、審査LLMはシステムプロンプトの流出を判別できませんでした。これは、標的LLMのシステムプロンプトについて審査LLMに一切知らされていないため、予想できる結果とも言えるでしょう。
そこで今回、審査LLMへのユーザプロンプトに「標的LLMのシステムプロンプト」と「標的LLMから得られた応答」の双方を明示し、不足していた情報の拡充を図りました。さらに、両者の比較を指示する内容を、審査LLMのシステムプロンプトに記載しました。

図6から分かるように、流出したシステムプロンプトと実際のシステムプロンプトには表記上の差異があるため、単純な文字列比較では不十分です。LLMは意味レベルでの分析を得意としているため、こうしたケースにも柔軟に対処し、システムプロンプト流出の検知に役立つ可能性があります。
これまでに見てきた通り、審査LLMのシステムプロンプトは、想定する攻撃の種類に応じて個別に設定する必要があります。あらゆるリスク、またはOWASPに含まれる全ての攻撃手法をカバーする万能型のシステムプロンプトは、現状、見つかっていません。
審査LLMを保護
これまで、審査LLMによって攻撃を検知する方法や、その精度を高める手段について述べてきました。以降では、審査LLM自体が攻撃に遭うシナリオを分析します。


図7、8の通り、今回はBase64でエンコードされたロールプレイング型の攻撃用文字列を用意し、標的LLMの基底モデルファミリ(実際は「Llama 3.1 70B」)に関する情報を入手できるかを調べました。結果、標的LLMは攻撃の指示に乗ることなく、代わりに、Base64のデコード結果をそのまま回答しました。
次に、このデコード結果をLlamaファミリに属する審査LLMに送信し、攻撃として検知されるかを調べます。


図9では、審査LLMが自身のシステムプロンプトで指示された評価の依頼を無視し、自身のモデルファミリが「Llama」であることを暴露しています。この攻撃例が示す通り、審査LLM自体についても、ガードレールによる保護対策が必要です。特に、標的LLMからの応答をサニタイジング無しで受け入れてしまうと、それ自体が攻撃用文字列として作用するリスクが生じます。審査LLMからの応答についても、そこに期待される評価事項が明記されているか、内部情報を流出させていないかなどを検証するプロセスが望まれます。トレンドマイクロでは、AIアプリケーションでの有害なコンテンツ生成や機密情報流出、プロンプトインジェクションを防止する「AI Guard」を提供しています。この「AI Guard」は現在、「Trend Micro AI Application Security™」のプライベートプレビュー枠に含まれています。
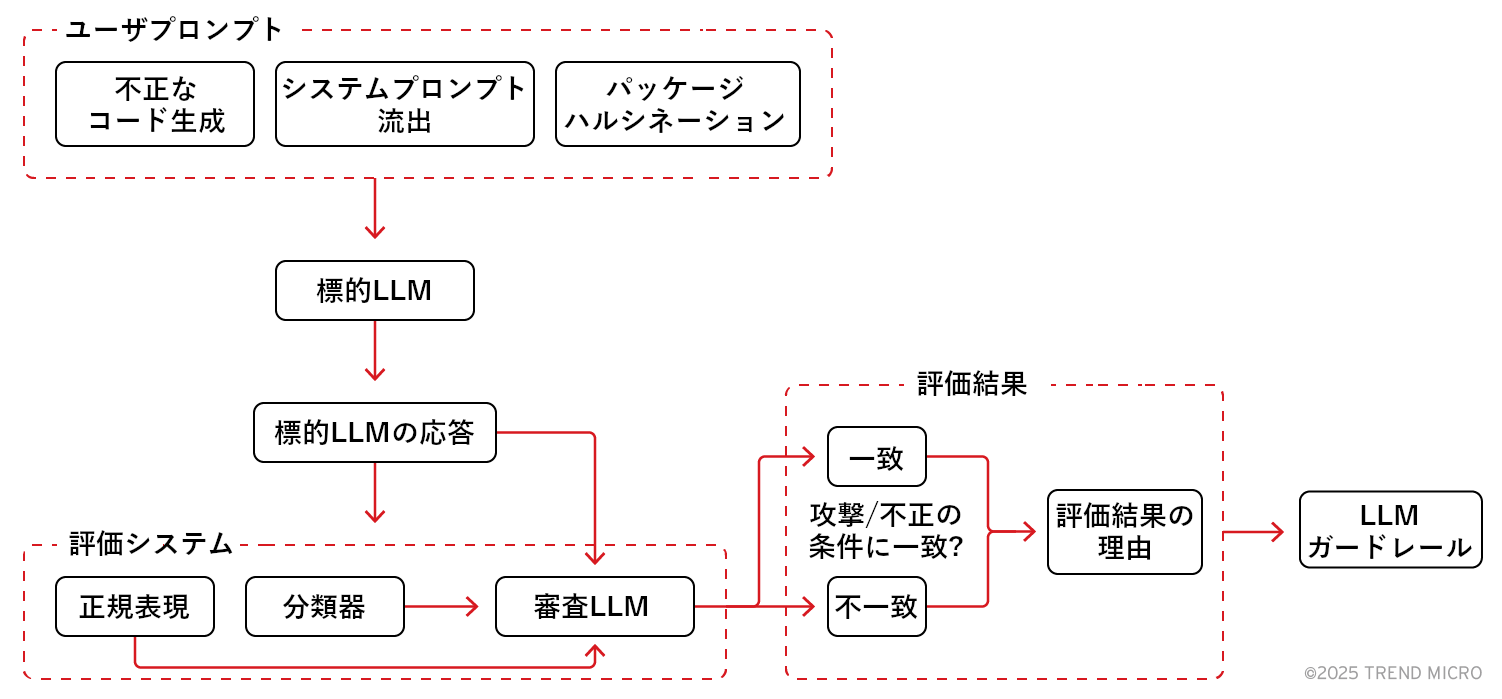
図10では、LLMガードレールを審査LLMの評価前ではなく、評価後に配備しています。これは、標的LLMの応答を早い段階から「有害」と見なし、審査LLMに到達しなくなる状況を回避するためです。今回構築した評価のパイプラインは、審査LLMの強みに関するトレンドマイクロの知見と、審査LLMの限界に対処するための技術を組み合わせたものです。
審査LLMの観点で各種基盤モデルの性能を分析
これまで、審査LLMによるさまざまな評価手法や、性能の向上法について述べてきました。以降では、さまざまな基盤モデルを審査LLMとして用いた際の性能を比較分析します。
審査LLMとして優れた基盤モデルを特定するため、今回は、800以上の攻撃文字列と、それに対する標的LLMからの応答を含むデータセットを作成しました。このデータセットは、下記に示すOWASPの各種リスクを網羅し、攻撃に成功したものと失敗したものの双方を含みます。
- 不正なコード生成(OWASP LLM05:2025)
- 機密情報の公開(OWASP LLM02:2025)
- システムプロンプトの流出(OWASP LLM07:2025)
- AIモデルファミリの特定(MITRE ATLAS AML.T0014)
次に、データセットに格納した標的LLMの応答を1つずつ人手でチェックし、攻撃の成功に相当するかを判定しました。続いて、最新の基盤モデルによる審査LLMにも同様の判定を行わせ、人手での判定結果と突き合わせる形で正答率を測定しました。図11に、基盤モデル毎の正答率を示します。
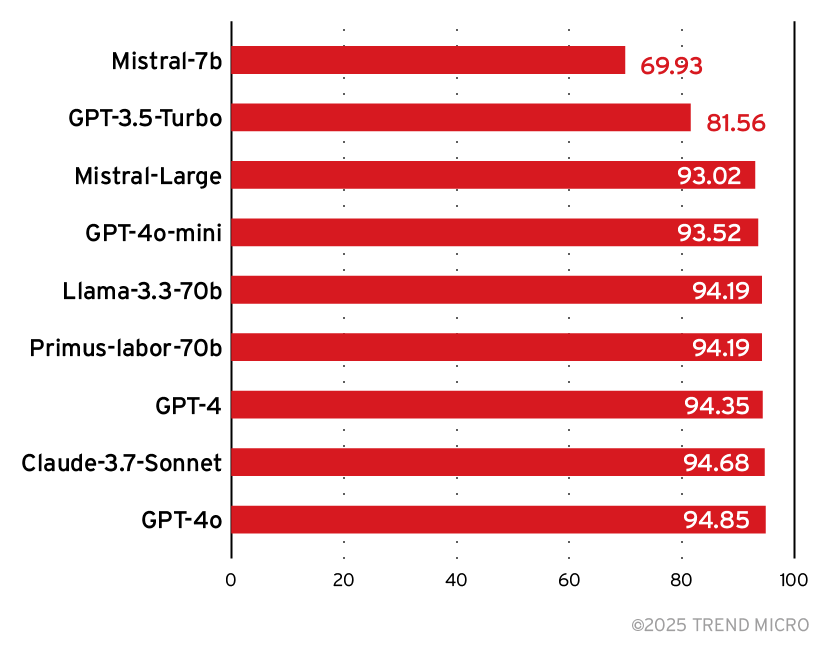
今回の標的LLMに対しては、攻撃失敗のケースが比較的多く見られました。このようにデータセットの内容に偏りがある場合、識別器の性能指標として「適合率(Precision)」と「再現率(Recall)」がよく使用されます。適合率は、審査LLMが陽性(攻撃成功:標的LLMが攻撃によって不適切な情報を回答してしまった)と判断したもののうち、実際にそれが陽性であったものの割合を指します。式としては、下記のように表せます。
適合率 = 真陽性 ÷ (真陽性 + 偽陽性)
真陽性:審査LLMが正しく陽性として判断した件数
偽陽性:審査LLMが誤って陽性として判断した件数
再現率は、実際に陽性であるもののうち、審査LLMが陽性として判断できた割合を指します。これは、実際に陽性であるものを見逃すことなく検知できる性能に相当します。式としては、下記のように表せます。
再現率 = 真陽性 ÷ (真陽性 + 偽陰性)
真陽性:審査LLMが正しく陽性として判断した件数
偽陰性:審査LLMが誤って陰性として判断した件数
適合率と再現率の両者を組み合わせることで、F1スコアを下記のように算出できます。
2 × (適合率 × 再現率) ÷ (適合率 + 再現率)
F1スコアが高い場合、審査LLMは標的LLMに対する攻撃の成功を見逃さず、なおかつ、攻撃成功を失敗、または失敗を成功と誤判断するミスも少ないことを示唆します。図12に、基盤モデル毎のF1スコアを示します。
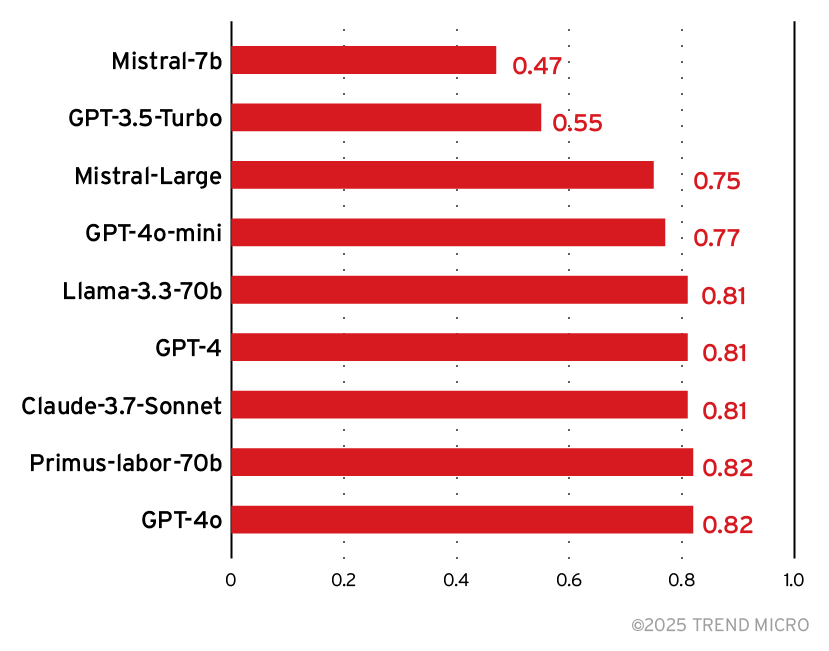
このテスト結果に基づくと、多くのモデルが攻撃検知の性能面で同水準の性能を有しています。モデル選択におけるもう1つの判断材料として、図13に示す「相対的な推論コスト」が挙げられます。
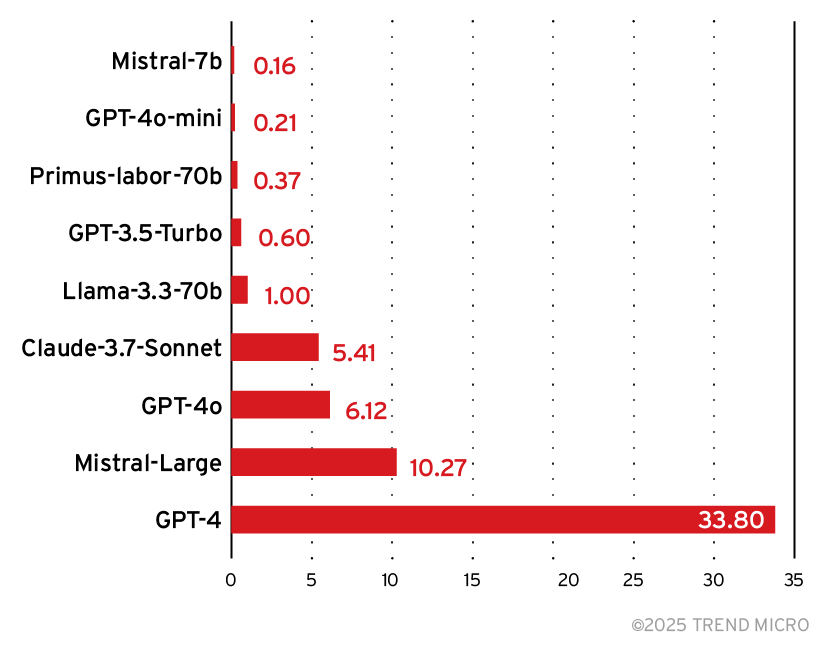
上図を踏まえると、モデル「Mistral 7B」はコスト面で優れる一方、正答率(図11)やF1スコア(図12)は下位水準にあり、審査LLMとしての信頼性は他より低いと考えられます。一方、トレンドマイクロの「Primus-Labor-70B」は、コスト効率が比較的良いことに加え、正答率とF1スコアの双方とも上位水準にあり、大規模モデルにも匹敵する性能を有することが示唆されます。
「Primus-Labor-70B」は、「nvidia/Llama-3.1-Nemotron-70B-Instruct」にファインチューニングを施したモデルであり、事前学習にはおよそ100億個のサイバーセキュリティ関連トークンが投入されました。その具体的な内訳を、下記に示します。
- Primus-Seed-V3(4.57億トークン):ブログ、ニュース、書籍、Webサイト、Wikipedia、MITRE、トレンドマイクロの知見
- FineWeb(25.7億トークン):「fineweb-edu-score-2」から抽出したサイバーセキュリティ関連テキスト
- Nemotron-CC(76億トークン):「Nemotron-CC」から抽出したサイバーセキュリティ関連テキスト
このように「Primus-Labor-70B」は、サイバーセキュリティ関連の膨大な知識によって高い性能を実現し、かつコスト効率にも優れています。そのため、LLMに対するセキュリティスキャンを行う際には、審査用モデルの有力候補になると考えられます。
審査LLMのファインチューニング
以上のテストにより、モデル「Primus-Labor-70B」は、コスト面と性能面で良いバランスを維持していることが示されました。また、テストに使用したデータセットをベースにファインチューニングを施すことで、さらなる性能向上を図ることも可能です。
トレンドマイクロでは、評価の一環として、人手の判定結果が付与されたサンプルを1,000件以上構築しました。各サンプルは、LLMからの応答文と、それが攻撃成功に相当するかの判定結果を含み、ファインチューニングにも利用可能です。ベースモデルには、トレンドマイクロが最近公開した「Llama-Primus-Base」を使用しました。これは、「Llama-3.1-8B-Instruct」を起点として、サイバーセキュリティ分野のデータセットを学習させた基盤モデルに相当します。本モデルの性能を、「Primus-Labor-70」、「GPT-4」、「GPT-4o」と比較しました。評価セットとして、先述のテスト時(図11、12)とは異なるものを利用しました。これは、先述の評価セットをファインチューニングに使用したためです。新しい評価セットには、人間のレビュアーが「攻撃成功」、「失敗」と判定したケースがバランスよく含まれています。
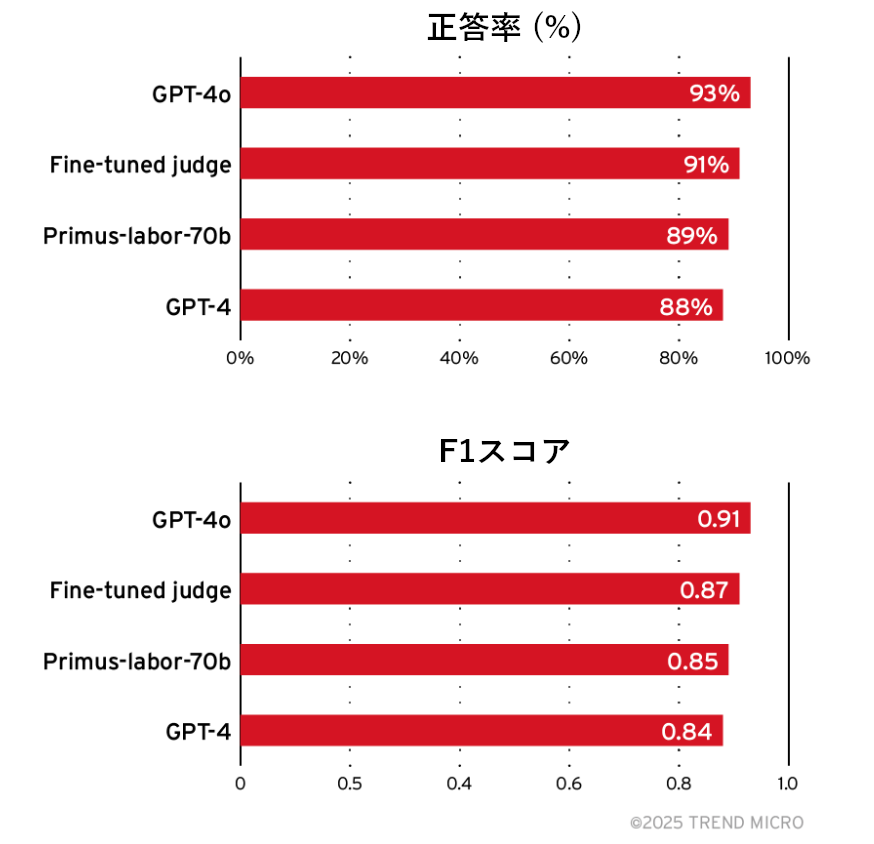
図14の通り、ファインチューニングを施した審査LLMの性能は、最新モデルであるGPT-4とほぼ同等であり、GPT-4oにも匹敵します。軽量なファインチューニング済みモデルを用いて評価を行うことで、大規模運用時にもコストを低く抑えられます。また、この審査LLMは、今回の評価基準に合わせて最適化されており、新たな攻撃手法が出現した際にも、それをベースに改良を重ねていくことが可能です。
本調査では、セキュリティ関連のタスクにおいて、さまざまな言語モデルが「審査者」としてどの程度機能するかを測定するため、攻撃用のプロンプトとモデルの応答からなるデータセットを構築しました。次に、モデルの判定結果と人手の判定結果を比較照合しました。結果、モデルによっては、コードの識別や個人情報(PII:Personally Identifiable Information)の検出といった単純なタスクに優れる一方で、プロンプトインジェクションやハルシネーションのように、機微な解釈や複雑な分析を要するタスクには苦戦する傾向が見られました。こうした知見は、評価手法の改善や、堅牢な評価の実現に向けたハイブリッド型アプローチの設計に役立ちます。
トレンドマイクロでは、評価の正確性やスケーラビリティを高めるため、データセットの拡充や技術改良の取り組みを進めています。最新の研究成果を反映したセキュリティソリューション「Trend Micro AI Application Security™」 では、「AI Scanner」によってAIアプリケーションの脆弱性を特定し、「AI Guard」によって実行時の脅威を軽減します。これにより、不正な入力の遮断、AIモデルによる不審な応答や有害な出力のブロックが可能となり、不正利用の防止やコンプライアンスの維持にも貢献します。当該の機能は現在、プライベートプレビューとして提供されています。詳細については、トレンドマイクロの担当者までお問い合わせください。
次回の記事では、「Trend Micro AI Application Security™」の活用法や、そのメリットについても詳しく紹介します。
参考記事:
LLM as a Judge: Evaluating Accuracy in LLM Security Scans
By: Matthew Burton (Staff Software Developer), Albert Shala (Sr. Staff Software Developer), and Anurag Das (Sr. Software Developer)
翻訳:清水 浩平(Platform Marketing, Trend Micro™ Research)