By Jaturong Kongmanee (AI Cyber Threat Research Intern, TrendAI™ Research) and Smile Thanapattheerakul (Manager, Research Incubation, TrendAI™ Research)
Key takeaways
- TrendAI™ Research carried out an analysis of employing perplexity for identifying prompt injection attacks and demonstrated cases where this method was not effective.
- We developed a model training procedure, which is complementary to the perplexity-based filter, for learning a low-dimensional latent representation space, in which the resulting latent space was used for characterizing attack features and for training a classifier.
- We found that representations of benign prompts have relatively lower variation, making them more predictable than prompt injection attacks.
- We found that the learned prompt injection representation appeared approximately linearly separable in the latent space, and that the specialized, small-scale classifier trained on features (principal components) derived from the latent space achieved precision and recall and F1 score of about 0.96 on the test set.
Introduction: Understanding prompt injection risks in LLM applications
A form of serious vulnerabilities of software applications built on top of large language models (LLMs) is prompt injection attack. This attack aims to inject an adversarial prompt and data into an input of an LLM integrated into a software application, such that it produces unintended and unwanted results from the application, as desired by an attacker.
Specifically, an LLM-integrated application takes as input a context window consisting of:
- A prompt, which can be provided by a user and/or an application’s system prompts, to instruct the LLM to perform a task; and
- Data context, which is obtained from external sources (e.g., via tool calling and skills), to be processed in order to complete the task and returns the response from the LLM to the user.
The risks from prompt injection attacks, therefore, stem from including untrusted prompts and adversarial data (e.g., embedded in documents, webpages, and search results) in a context window. One way to mitigate risks of prompt injection attacks is to ensure that only trusted prompts and verified data (e.g., data without embedded hidden adversarial instructions) are allowed, and limiting LLM access to confidential data and privileged tools can pragmatically minimize the impact of the attacks.
Applications built on LLMs leverage their ability to process evolving natural language inputs (prompt and data). Without this feature, LLM-integrated applications are fundamentally indifferent to traditional software applications where user inputs trigger static logic driving predictable outcomes of the applications. While allowing flexibility in processing infinite variations of natural language input, this LLM-enabled feature also allows untrusted prompts; thus, it makes applications vulnerable to prompt injection. Given this nature of LLM-integrated applications, traditional security practices based on heuristics and rule-based approaches are insufficient as a first line of defense. Therefore, we seek to develop a method based on a machine learning (ML) approach to guard LLMs.
In this research, we explored representation learning of prompt content to flag potential prompt injection prior to LLM inference (i.e., output generation). We reported on a data analysis pipeline that guided our model training method for learning a low-dimensional prompt representation that could be used to train a specialized, small-scale classifier. We also attempted to characterize attack dimensions of the resulting latent representation space.
Overview of our approach: Learning a representation of prompt injection attacks
Guided by research findings, we first attempted to use perplexity to measure how surprising the text is for detecting prompt injection. Perplexity quantifies how well an LLM predicts a given text. Texts with lower perplexity are considered natural or expected by the LLM. Conversely, texts with higher perplexity are less predictable or might contain unusual word sequences.
For that reason, we should expect high perplexity for attacks. This is sound because attacks are known to use particular suffixes — by employing the greedy coordinate gradient (GCG) algorithm — and/or phrasings that, by definition, are not presented in training examples of regular use. However, low perplexity does not always imply safety. For example, sophisticated attackers can use highly predictable natural language to bypass perplexity-based filters.
This phenomenon can be seen in Figure 1. We observed that the distributions of benign prompts and attacks are nearly inseparable. We used the dataset of prompt injection attacks provided in the study “SPML: A DSL for Defending Language Models Against Prompt Attacks.” This finding suggests a complementary method to the perplexity-based filtering, and thereby we seek to develop a method that allows us to deepen our understanding of attack dimensions that can separate prompt attacks from benign prompts.
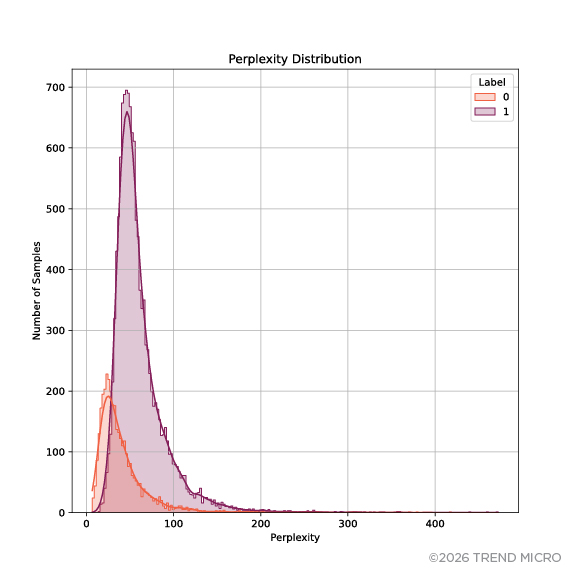
Figure 1. Perplexity distribution of prompt injection attacks
Note: Benign prompts are labeled as 0, while prompt injection attacks are labeled as 1.
Our next attempt was to focus on learning essential representations of prompts. There is a wide variety of ways to represent data. In our case, the dataset is specific to prompt injection attacks. We conjectured that employing a relatively high-dimensional embedding (over 300 dimensions, at least) trained on training samples drawn from a population different from the attacks (e.g., generic web text data) to represent prompts might not be representative, and might not be effective at capturing phrases, suffixes, and nuances of adversarial patterns. In addition, an embedding may amplify biases as a result of training regime, which we typically lack access to training data and details of.
To mitigate biases in the representations of data while attempting to retain the signal of adversarial suffixes, we employed term frequency–inverse document frequency (TF-IDF) to represent prompts. TF-IDF is a statistical method that quantifies the amount of information of a term weighted by its occurrence. This allows us to evaluate how important a token (a word or a part of a word) is to a prompt in a training corpus. In this phase, we could train ML models to classify prompt injection. However, we aimed not only to obtain strong classification performance but also to reveal intrinsic structures and patterns of prompt attacks, if any. Specifically, we attempted to learn a low-dimensional representation space of prompt attacks and minimize interference from being misguided by inaccurate (and potentially biased) labeled training instances, so that we can characterize intrinsic features of attacks derived from the resulting latent space and use them to train a classifier.
We therefore devised our model training into two stages:
- First, we developed an efficient unsupervised learning of prompt injection content to learn its low-dimensional latent space.
- Second, we trained a classifier on features derived from the resulting latent space, guided by labeled training instances to refine classification performance.
Stage 1: Unsupervised learning of low-dimensional prompt injection representations
We trained an unsupervised autoencoder (AE) on TF-IDF to learn a low-dimensional prompt representation. AE, as shown in Figure 2, consists of an encoder, a decoder, and a bottleneck/code. The bottleneck/code forces the encoder to learn a compressed representation of original prompts, by finding low-dimensional representations that, when reconstructed by the decoder, are close to the original prompts, as measured by mean squared error (MSE). Thus, this compressed representation, although imperfect due to the inherent difficulty of the compression task, is expected to encode essential features. In our study, the encoder compressed the input to a three-dimensional vector.
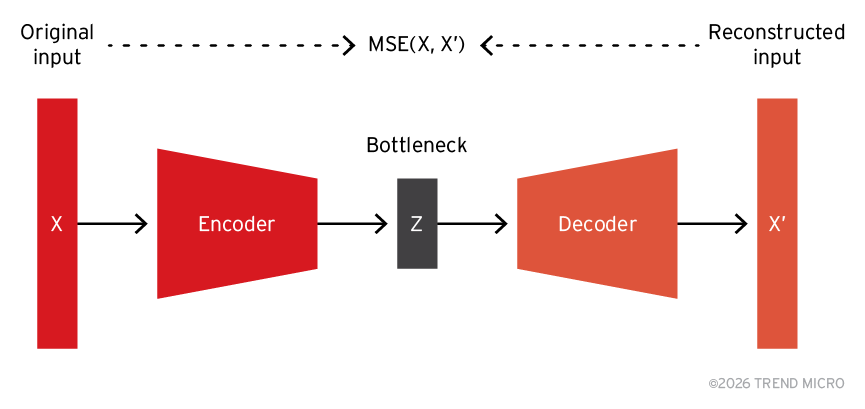
Figure 2. Autoencoder architecture
We then asked:
How good is a learned representation at separating prompt injection attacks from benign prompts?
To answer this question, we plotted distributions of feature values of each of the dimensions of the resulting latent space. As shown in Figure 3, we observed that prompt injection distributions of all three dimensions are approximately normally distributed with similar means and standard deviations, that each of these three dimensions can visually separate attacks from benign prompts — that is, feature values greater than 1 are highly likely of prompt attacks. We also observed that the first and second dimensions are highly correlated, have overlapping feature values ranging approximately from 1 to 20, while feature values of the third dimension are relatively narrower, ranging approximately from 0 to 11. We hypothesized that the latent space’s third dimension captures partially distinct attack features with the first and second dimensions. In addition, ranges of benign prompts’ feature values of all three dimensions are similar (i.e., ranging from 0 to 5) and have lower standard deviations relative to prompt injection’s feature values. This has an important implication for the predictability of prompts where benign prompt representations are less noisy and more predictable than prompt attacks.
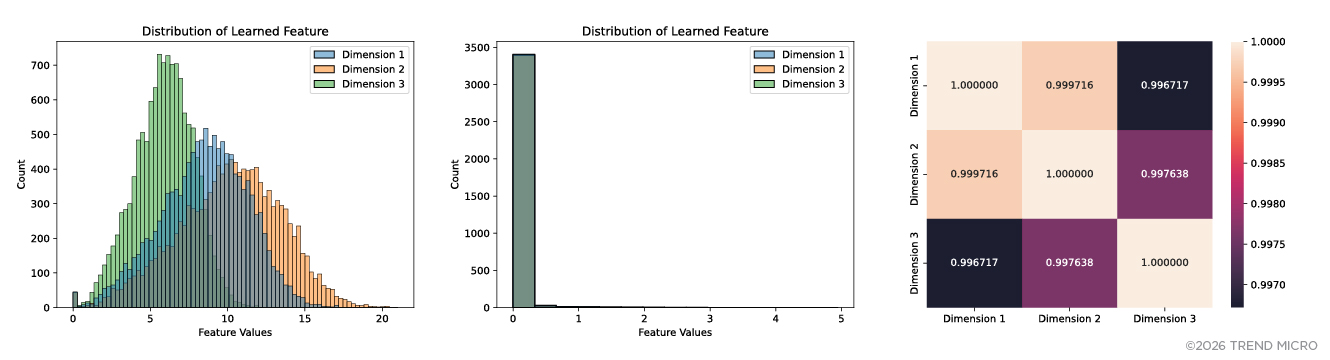
Figure 3. Distributions of learned features of the prompts labeled as prompt injection attacks (left) and benign prompts (middle), and Pearson correlation matrix of learned representations of prompt injection attacks (right)
Stage 1.1: Distillation for orthogonal features
We then employed principal component analysis to create a new set of orthogonal features that maximizes the variance of data representations in the three-dimensional latent space. As shown in Figure 4, the plot visually reveals two distinct clusters, suggesting that prompt injection attacks are also separable from benign prompts in the two-dimensional space defined by principal components. The first principal component, depicted as Dimension 1 in Figure 4, allows us to classify prompts into two categories, in which case feature values falling approximately between 1 and 16 in the latent space (see Figure 3) fail to identify prompts’ dimensions that represent different attack features.
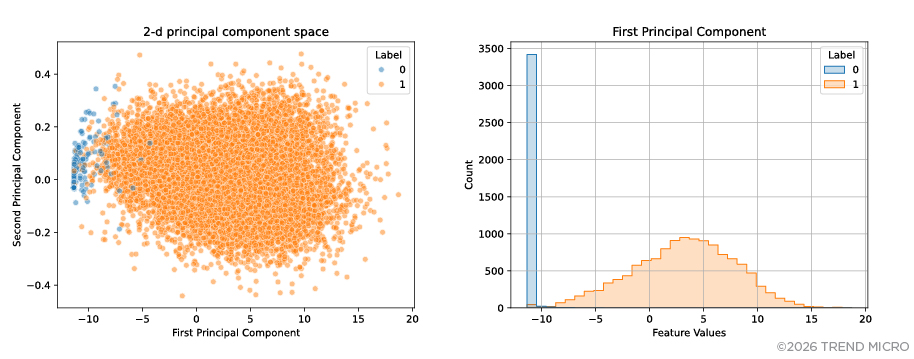
Figure 4. Representation of prompts in two-dimensional space defined by principal components (left) and feature values or principal component scores of the first principal component (right)
Note: Benign prompts are labeled as 0, while prompt injection attacks are labeled as 1.
Stage 2: Supervised training for prompt attack classification
We observed that a structure of the learned prompt representation appears approximately linearly separable between the two categories (see Figure 4). With this linear separability, to obtain a good classification performance, it is sufficient to train a linear model that is relatively robust with respect to the influence of extreme data points and is fast at inference. In our experiment, we trained a logistic regression classifier on the resulting two-dimensional features. We observed strong classification performance by which the classifier achieved precision and recall and F1 score of about 0.96 on the test set.
Given our findings, the two potential interpretations that followed suggested our conclusions:
- As is evident in Figures 3 and 4, prompt injection attacks and benign prompts generated by techniques proposed in the SPML study are approximately linearly separable in the low-dimensional latent space. Thus, a simple model can effectively classify them.
- There was a lack of diversity in the prompt injection attacks generated using the method proposed in the SPML study.
Known limitations of this research
Despite the promising results, our work has a couple of limitations. First, we focused on a specific dataset of prompt injection attacks, and therefore the prompt injection structures found in the latent space may not generalize to attacks designed specifically for other LLM-integrated applications. Second, we used GPT-2 for computing perplexity, so it is possible that other models give perplexity distributions with different statistics. Future work requires evaluating the method against prompt injection attacks of varying complexity.
We view this work as a meaningful step toward practical prompt injection prediction and mitigation. And we acknowledge that sustained progress depends on shared learning and collaboration across the AI security community. We therefore look forward to continued engagement to ensure that AI systems behave as intended and can be trusted by users.
Conclusion: Toward practical detection and mitigation of prompt injection attacks
Our findings also highlight practical security benefits for real-world LLM-integrated applications. The approach enables the development of a specialized, small-scale classifier that can function as a prompt injection filter prior to LLM inference. By identifying potentially malicious prompts before the model generates a response, it can help reduce the risk of prompt manipulation and unintended outputs. In addition, learning latent representations of prompts provides deeper insights into the structural characteristics of prompt injection attacks. This can help other security researchers and developers better understand attack dimensions and improve detection mechanisms over time.
Best practices against prompt injection attacks
Defending against prompt injection attacks requires a combination of proactive detection mechanisms and secure system design. To implement safeguards, organizations and developers building or deploying LLM-integrated applications should:
- Separate trusted system instructions from untrusted inputs: System prompts and internal instructions should be isolated from user inputs and external content sources to reduce the risk of prompt manipulation.
- Filter or monitor prompts before LLM inference: Detection mechanisms, such as classifiers trained on prompt representations, can help identify potentially malicious prompts before they influence the model’s output.
- Restrict model access to sensitive data and privileged tools: Limiting an LLM’s ability to access confidential information, APIs, databases, or internal systems can reduce the potential impact of prompt injection attempts.
- Treat external data sources as untrusted input: Content retrieved from documents, webpages, search results, or other external sources should be validated before being included in the LLM context window.
- Monitor prompts and model interactions for anomalous patterns: Observing unusual prompt structures or interaction patterns can help detect potential prompt injection attempts.
- Establish governance and security controls for LLM-enabled systems: Organizations should incorporate prompt injection defenses into broader AI risk management practices, including model monitoring, access controls, and security reviews of LLM applications.
Proactive security with TrendAI Vision One™
In practice, the approach we discuss here is intended to be deployed as a lightweight, small‑scale classifier operating prior to LLM inference. It exhibits efficiency and strong detection performance, achieving precision and recall and F1 score of about 0.96 on the test set. This makes it suitable for integration into real‑world LLM security pipelines, where it can provide fast and accurate prompt injection detection before malicious inputs influence model behavior, including within platforms such as TrendAI Vision One™.
TrendAI Vision One™ addresses prompt injection through TrendAI Vision One™ AI Secure Access and TrendAI Vision One™ AI Application Security:
- Define and validate expected output formats: AI Secure Access implements strict validation of output formats to ensure that LLM responses conform to expected patterns and structures, making it harder for malicious prompts to generate harmful outputs.
- Implement input and output filtering: AI Secure Access provides advanced content inspection and filtering capabilities that analyze both user prompts and AI responses. This bidirectional inspection helps identify and block potential prompt injection attempts before they can affect the LLM’s behavior.
- Enforce privilege control and least privilege access: AI Secure Access implements strict role-based access controls that limit what users can do with AI services, reducing the potential impact of successful prompt injection attacks.
- Conduct adversarial testing and attack simulations: AI Application Security provides capabilities for adversarial testing and attack simulations to identify and address prompt injection vulnerabilities before they can be exploited.
Like it? Add this infographic to your site:
1. Click on the box below. 2. Press Ctrl+A to select all. 3. Press Ctrl+C to copy. 4. Paste the code into your page (Ctrl+V).
Image will appear the same size as you see above.
 Fault Lines in the AI Ecosystem: TrendAI™ State of AI Security Report
Fault Lines in the AI Ecosystem: TrendAI™ State of AI Security Report It’s By Design: The Use-After-Free of Azure Cloud
It’s By Design: The Use-After-Free of Azure Cloud TrendAI™ 2026 Cyber Risk Report
TrendAI™ 2026 Cyber Risk Report Guarding LLMs With a Layered Prompt Injection Representation
Guarding LLMs With a Layered Prompt Injection Representation