
Eine Form der künstlichen Intelligenz (KI), die es Systemen ermöglicht, Muster aus Daten zu lernen und ihre Leistung bei Aufgaben im Laufe der Zeit zu verbessern, ohne explizit programmiert zu werden.
Inhalt
Maschinelles Lernen Definition
Dass Computer ohne explizite Anweisung wissen, was zu tun ist, war lange Zeit reine Fiktion.
Das autonome Fahrzeug, das alles für Sie erledigt, während Sie (natürlich auf dem Fahrersitz) mitfahren, ist Machine Learning (ML) in Aktion. Das Fahrzeug fährt komplett eigenständig, erkennt Fußgänger und Schlaglöcher und reagiert schnell und effizient auf Umgebungsänderungen, damit Sie sicher an Ihrem Ziel ankommen.
Wie funktioniert das? Zunächst geht es um die Analyse von reinen Geschäftsdaten.
ML ist eine Form der KI, mit der Unternehmen große Datenmengen auswerten und daraus lernen können. Wertvolle Informationen zu gewinnen, ist für Unternehmen mit erheblichem Aufwand verbunden. Um ML optimal nutzen zu können, müssen Sie über saubere Daten verfügen und wissen, welche Fragen Sie dazu haben. Erst dann können Sie für das beste Modell und den besten Algorithmus für Ihr Unternehmen auswählen. ML ist kein einfacher, unkomplizierter Prozess. Wer erfolgreich sein will, muss sorgfältig arbeiten.
Wie maschinelles Lernen Unternehmen helfen kann
Maschinelles Lernen schützt Unternehmen vor Cyberbedrohungen. Sie funktioniert jedoch am besten als Teil einer mehrschichtigen Sicherheitslösung.
Damit Unternehmen durch Machine Learning nützliche Informationen erhalten, ist ein erheblicher Aufwand erforderlich. Sie müssen über bereinigte Daten verfügen und Ihre Fragen dazu kennen, um von ML bestmöglich zu profitieren. Erst dann können Sie für Ihr Unternehmen das beste Modell und den besten Algorithmus auswählen. ML ist kein einfacher Prozess. Um erfolgreich zu sein, bedarf es sorgfältiger Arbeit.
Der Lebenszyklus von ML sieht wie folgt aus:
- Geschäftsverständnis: Sie klären das Problem, die Erfolgskriterien und die Frage, ob ML der richtige Ansatz ist.
- Datenerfassung und -bereinigung: Sie erfassen und bereinigen alle relevanten Daten, die Sie benötigen, um die richtigen Entscheidungen zu treffen.
- Funktionsauswahl: Sie wählen die Eingangsvariablen (Funktionen) aus, die beim Erstellen des Modells verwendet werden sollen. Zu den Methoden gehören statistische Tests, Regularisierung oder algorithmische Gewichtung. Entscheidungsbäume ordnen Merkmale beispielsweise nach Kriterien wie Informationsgewinn oder Gini-Unreinheit.
- Modellauswahl: Sie wählen einen geeigneten Algorithmus und Modelltyp und trainieren ihn dann mit Ihren Daten.
- Training und Optimierung: Sie passen das Modell an die Daten an und optimieren die Hyperparameter, um die Leistung zu verbessern.
- Auswertung: Sie bewerten das Modell und den Algorithmus, um festzustellen, ob es einsatzbereit ist. Andernfalls müssen Sie einige Schritte zurückgehen und Ihr Modell, Ihre Funktionen, Ihren Algorithmus oder Ihre Daten verfeinern, um Ihre Ziele zu erreichen.
- Bereitstellung des trainierten Modells in der Produktion
- Überprüfung der Ergebnisse des vorhandenen Modells in der Produktion

Einsatzbereiche für Machine Learning
Durch Machine Learning können Unternehmen Ihre Daten verstehen und aus ihnen lernen. Ein Unternehmen kann ML für eine Vielzahl von Teilbereichen verwenden. Der Anwendungsfall hängt davon ab, was ein Unternehmen erreichen will: die Umsätze erhöhen, eine Suchfunktion bereitstellen, Sprachbefehle in sein Produkt integrieren oder ein selbstfahrendes Auto entwickeln.
Machine Learning – Teilbereiche
ML hat in der heutigen Geschäftswelt eine fantastische Bandbreite an Einsatzmöglichkeiten, und mit der Zeit kann es nur besser werden. Zu den Teilbereichen des ML zählen etwa Social Media und Produktempfehlungen, Bilderkennung, Gesundheitsdiagnostik, Sprachübersetzung, Spracherkennung und Data Mining.
Social-Media-Plattformen wie Facebook, Instagram oder LinkedIn verwenden ML, um Ihnen anhand Ihrer Likes Seiten oder Gruppen vorzuschlagen, denen Sie folgen oder beitreten könnten. ML nutzt Verlaufsdaten über die Beiträge, die anderen gefallen haben, oder über Beiträge, die denen ähneln, die Ihnen gefallen haben. Auf dieser Grundlage werden Ihnen Vorschläge unterbreitet oder diese Beiträge Ihrem Feed hinzugefügt.
ML kann auch auf einer E-Commerce-Website verwendet werden, um Ihnen Produkte zu empfehlen. Basis dafür könnten Ihre früheren Käufe sein, Ihre Suchvorgänge und Aktionen anderer Anwender, die Ihren ähneln.
Eine weitere wichtige Anwendung für ML ist heute die Bilderkennung. Social-Media-Plattformen empfehlen, Personen in Ihren Fotos auf der Grundlage von ML zu markieren. Die Polizei kann damit in Bildern oder Videos nach Verdächtigen suchen. Aufgrund der vielen Kameras, die in Flughäfen, Geschäften und an Türklingeln angebracht sind, lässt sich ermitteln, wer ein Verbrechen begangen hat oder wohin der Kriminelle verschwunden ist.
Auch die Gesundheitsdiagnose ist ein guter Einsatzbereich für ML. Nach einem Vorfall wie einem Herzinfarkt ist es möglich, zurückzublicken und Warnzeichen zu erkennen, die übersehen wurden. Ein von Ärzten oder Krankenhäusern verwendetes System könnte auf frühere Krankenakten zurückgreifen und Rückschlüsse ziehen. Dadurch ließen sich Verbindungen von der Eingabe (Verhalten, Testergebnis oder Symptom) bis zur Ausgabe (etwa einem Herzinfarkt) nachvollziehen. Wenn der Arzt seine Notizen und Testergebnisse in das System eingibt, kann die Maschine zukünftig die Symptome eines Herzinfarkts viel zuverlässiger erkennen als Menschen. Auf diese Weise können der Patient und der Arzt Maßnahmen ergreifen, um einen Herzinfarkt zu verhindern.
Die Übersetzung von Sprachen auf Webseiten oder in Apps für mobile Plattformen ist ein weiteres Beispiel für ML. Einige Apps leisten dabei bessere Arbeit als andere, was auf das verwendete Modell, die Technik und die Algorithmen zurückzuführen ist.
Ein alltäglicher Einsatzbereich von ML, über den wir nicht immer nachdenken, sind Bankgeschäfte und Kreditkarten. ML kann Betrugsanzeichen schnell erkennen. Menschen bräuchten dafür lange, so es ihnen überhaupt gelänge. Durch die Vielzahl der untersuchten und gekennzeichneten Transaktionen (betrügerisch oder nicht) kann ML lernen, Betrugsfälle in zukünftigen Transaktionen zu erkennen. ML, das sich hierfür hervorragend eignet, ist Data Mining.
Data mining
Data Mining ist eine Art des ML, bei der Daten analysiert werden, um Prognosen zu erstellen oder Muster in großen Daten zu erkennen. Der Begriff ist ein wenig irreführend. Niemand – sei es ein Angreifer oder Mitarbeiter – wird angehalten, in Ihren Daten nach etwas Nützlichem zu suchen. Vielmehr werden im Rahmen des Prozesses Datenmuster erkannt, die bei künftigen Entscheidungen helfen.
Denken Sie zum Beispiel an ein Kreditkartenunternehmen. Wenn Sie eine Kreditkarte haben, hat Ihre Bank Sie wahrscheinlich schon einmal benachrichtigt, dass es eine verdächtige Aktivität im Zusammenhang mit Ihrer Karte gab. Wie kann die Bank eine solche Aktivität so schnell feststellen und beinahe sofort eine Warnung senden? Diesen Schutz vor Betrug ermöglicht kontinuierliches Data Mining.
Deep learning
Deep Learning ist eine bestimmte Art des ML, die auf neuronalen Netzen basiert. Ein neuronales Netzwerk ahmt die Funktionsweise der Neuronen im menschlichen Gehirn nach, um Entscheidungen zu treffen oder etwas zu verstehen. So unterscheidet beispielsweise ein sechsjähriges Kind durch den Blick in ein Gesicht seine Mutter von der Verkehrshelferin. Das Gehirn analysiert innerhalb eines Wimpernschlags viele Details, etwa die Haarfarbe, Gesichtsmerkmale und Narben. Machine Learning repliziert dies in Form von Deep Learning.
Ein neuronales Netz hat drei bis fünf Schichten: eine Eingabeschicht, ein bis drei versteckte Schichten und eine Ausgabeschicht. Die versteckten Schichten treffen die Entscheidungen und arbeiten nacheinander auf die Ausgabeschicht oder die Schlussfolgerung hin. Welche Haarfarbe? Welche Augenfarbe? Ist da eine Narbe? Gehen die Schichten in die Hunderte, ist von Deep Learning die Rede.
Machine Learning – Arten
Grundsätzlich gibt es vier Arten von Algorithmen für Machine Learning: überwachte, halb überwachte, nicht überwachte und verstärkte Algorithmen. ML-Fachleute gehen davon aus, dass von den heute verwendeten ML-Algorithmen etwa 70 % überwacht werden. Sie funktionieren mit bekannten oder bezeichneten Datensets, etwa Bildern von Hunden und Katzen. Diese beiden Arten von Tieren sind bekannt. Entsprechend können Administratoren die Bilder bezeichnen, bevor sie diese an den Algorithmus übergeben.
Nicht überwachte ML-Algorithmen lernen aus unbekannten Datensets. Ein Beispiel dafür sind TikTok-Videos. Es gibt so viele Videos mit so vielen Themen, dass es unmöglich ist, einen Algorithmus überwacht damit anzulernen. Die Daten sind noch nicht gekennzeichnet.
Halb überwachte ML-Algorithmen werden anfänglich mit einem kleinen Datenset trainiert, das bekannt und gekennzeichnet ist. Anschließend werden sie auf ein größeres, nicht gekennzeichnetes Datenset angewendet, um das zugehörige Training fortzusetzen.
Verstärkte ML-Algorithmen werden zunächst nicht trainiert. Sie lernen aus Tests und zwischenzeitlichen Fehlern. Stellen Sie sich einen Roboter vor, der lernt, durch einen Steinhaufen zu navigieren. Jedes Mal, wenn er scheitert, lernt er, was nicht funktioniert, und ändert sein Verhalten, bis er erfolgreich ist. Denken Sie etwa an das Hundetraining und den Einsatz von Leckerbissen zum Trainieren verschiedener Kommandos. Eine positive Verstärkung bewirkt, dass der Hund weiterhin auf die Kommandos reagiert und sein Verhalten ändert, wenn die positive Reaktion ausbleibt.
Überwachtes und nicht überwachtes Machine Learning
Überwachtes Machine Learning
Dabei werden bekannte, bestehende und klassifizierte Datensets verwendet, um Muster zu erkennen. Dies lässt sich anhand der vorherigen Idee der Bilder von Hunden und Katzen veranschaulichen. Angenommen, Sie verfügen über einen riesigen Datensatz mit Tausenden von unterschiedlichen Tieren in Millionen von Bildern. Da die Tierarten bekannt sind, könnten diese gruppiert und bezeichnet werden, bevor sie dem überwachten ML-Algorithmus übergeben werden, damit er daraus seine Schlüsse ziehen kann.
Der überwachte Algorithmus vergleicht nun die Eingabe mit der Ausgabe und das Bild mit der Bezeichnung der Tierart. Mit der Zeit wird er lernen, eine bestimmte Tiergattung in neuen Fotos zu erkennen.
Nicht überwachtes Machine Learning
Nicht überwachte ML-Algorithmen agieren wie heutige SPAM-Filter. Anfangs konnten Administratoren SPAM-Filter so programmieren, dass sie in der E-Mail nach bestimmten Wörtern suchten, um SPAM zu verstehen. Das ist nicht mehr möglich, deshalb eignen sich in diesem Fall nicht überwachte. Der nicht überwachte ML-Algorithmus wird mit nicht bezeichneten E-Mails gefüttert, damit er darin nach Mustern zu suchen beginnt. Finden sich solche Muster, lernt er, wie SPAM aussieht, und identifiziert ihn in der Produktionsumgebung.

Machine Learning – Techniken
Durch ML-Techniken lassen sich Probleme beheben. Welche spezifische ML-Technik Sie auswählen, hängt von Ihrem jeweiligen Problem ab. Hier sind sechs gängige.
Regression
Mithilfe der Regression lassen sich Inlandspreise prognostizieren oder etwa der optimale Verkaufspreis einer Schneeschaufel in München im Dezember bestimmen. Die Regression besagt, dass die Preise zwar schwanken, aber immer wieder zum Durchschnittspreis zurückkehren. Selbst wenn die Immobilienpreise im Lauf der Zeit steigen, gibt es einen Durchschnittswert, der sich immer wieder einpegelt. Sie können die Preise im Verlauf in einem Diagramm darstellen und mit der Zeit den Mittelwert feststellen. Anhand der roten Linie, die im Diagramm weiter nach oben wandert, lassen sich Zukunftsprognosen treffen.
Klassifizierung
Mithilfe der Klassifizierung lassen sich Daten in bekannte Kategorien gruppieren. Sie könnten nach Kunden suchen, die voraussichtlich gute Kunden sind (also immer wieder kommen und mehr Geld ausgeben) oder die voraussichtlich künftig woanders einkaufen werden. Wenn Sie die Vergangenheit betrachten und Faktoren für jede Kundenklassifizierung finden, können Sie diese auf aktuelle Kunden anwenden und vorhersagen, zu welcher Gruppe sie passen. Auf diese Weise können Sie Ihr Marketing effektiver gestalten und möglicherweise Kunden gewinnen, die zu hervorragenden Stammkunden werden könnten. Dies ist ein gutes Beispiel für überwachtes ML.
Clustering
Clustering zählt im Gegensatz zur Klassifizierung zum nicht überwachten ML. Beim Clustering findet das System heraus, wie Daten gruppiert werden können, von denen Sie nicht wissen, wie Sie sie gruppieren sollen. Diese Art des ML eignet sich bestens zur Analyse medizinischer Bilder und sozialer Netzwerke oder zur Ermittlung von Anomalien.
Google verwendet Clustering für die Generalisierung, die Datenkomprimierung und die Datenschutzwahrung in Produkten, zum Beispiel in YouTube-Videos, Play-Apps und Musik-Titeln.
Anomalieerkennung
Mithilfe der Anomalieerkennung wird nach Ausreißern gesucht, etwa nach dem schwarzen Schaf in einer Herde. Angesichts einer riesigen Datenmenge sind diese Anomalien für Menschen unmöglich zu erkennen. Wenn jedoch beispielsweise ein Data Scientist einem System medizinische Abrechnungsdaten aus vielen Krankenhäusern zuführt, würde die Anomalieerkennung einen Weg finden, die Abrechnungen zu gruppieren. Sie könnte auch eine Reihe von Ausreißern erkennen, die auf Betrug hindeuten.
Marktkorbanalyse
Die Logik der Marktkorbanalyse ermöglicht Prognosen. Einfaches Beispiel: Wenn Kunden Rinderhack, Tomaten und Tacos in ihren Korb legen, könnten Sie prognostizieren, dass sie auch Käse und Sauerrahm hinzufügen. Anhand dieser Prognosen lassen sich zusätzliche Umsätze generieren, indem Online-Käufer Vorschläge zu Artikeln erhalten, die Sie vergessen haben könnten, oder indem Produkte in einem Geschäft gruppiert werden.
Zwei Professoren am MIT nutzten diesen Ansatz, um den „Harbinger of Failure“ zu erkennen, den Vorboten des Fehlers. Wie sich herausgestellt hat, mögen manche Kunden erfolglose Produkte. Wenn Sie diese erkennen können, haben Sie die Wahl, ob Sie ein Produkt weiterhin vertreiben oder nicht. Außerdem können Sie entscheiden, welche Marketingstrategie Sie anwenden wollen, um den Umsatz mit den richtigen Kunden zu erhöhen.
Zeitreihendaten
Mithilfe von Fitnessarmbändern werden über viele von uns Zeitreihendaten erhoben. Diese Armbänder können die Herzschläge pro Minute, Schritte pro Minute oder Stunde und sogar die Sauerstoffsättigung über einen Zeitraum erfassen. Anhand dieser Daten ließe sich prognostizieren, wann jemand künftig läuft. Möglich wäre auch, auf Basis zeitbasierter Daten über Schwingungsniveau, Geräuschpegel (dB) und Druck Daten über Maschinen- und Prognosefehler zu erfassen.
Machine Learning – Algorithmen
Wenn ML aus Daten lernen soll, wie entwerfen Sie dann einen Algorithmus zum Lernen und Ermitteln der statistisch signifikanten Daten? ML-Algorithmen unterstützen den Prozess des überwachten, nicht überwachten oder verstärkten ML.
Data Engineers schreiben Code-Teile, die Algorithmen darstellen, mit denen eine Maschine lernen oder Bedeutung in Daten finden kann.
Nachfolgend sehen Sie einige der gängigsten Algorithmen. Sie sind die Top 5, die heute im Einsatz sind.
- Bei der linearen Regression wird eine Beziehung hergestellt, indem unabhängige und abhängige Variablen in ein Diagramm eingezeichnet werden und eine gerade Linie für den Mittelwert oder den Trend gezogen wird. Laut Merriam-Webster ist die Regression „eine Funktion, die den Wert einer Zufallsvariablen vorhersagt unter der Bedingung, dass eine oder mehrere unabhängige Variablen bestimmte Werte annehmen“. Diese Definition gilt auch für die logistische Regression.
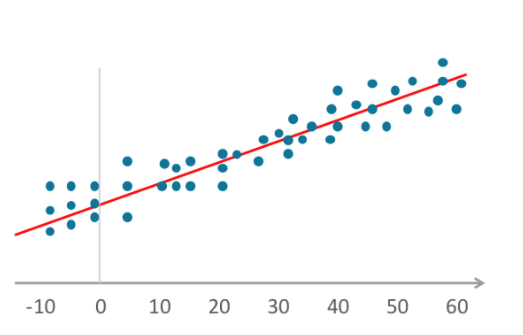
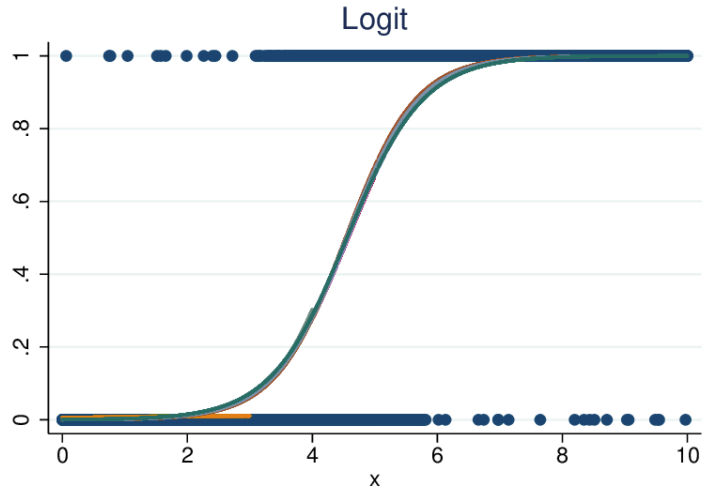
- Bei der (auch als Logit bezeichneten) logistischen Regression werden Variablen ebenfalls an einen Graphen angepasst, die Beziehung ist jedoch nicht linear. Die Linie hier ist eine Sigmoidfunktion.
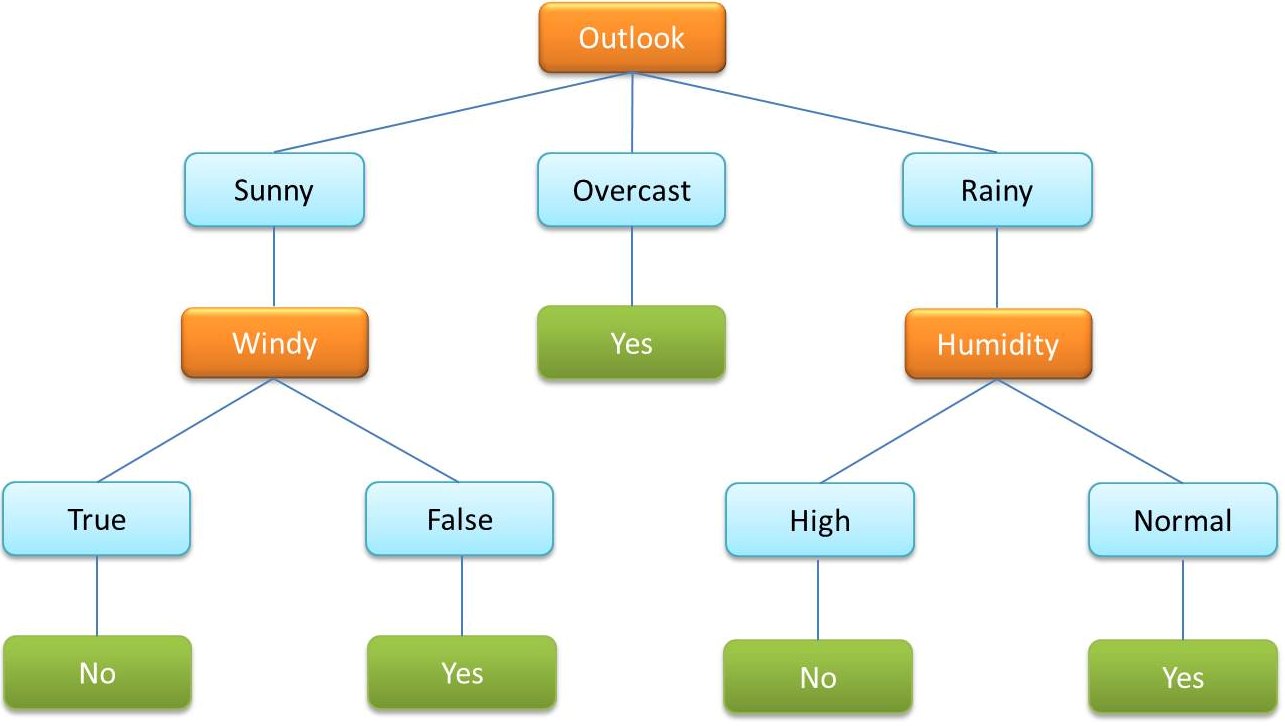
- Ein Entscheidungsbaum ist ein beim überwachten ML sehr häufig eingesetzter Algorithmus. Damit werden Daten nach kategorialen und kontinuierlichen Variablen klassifiziert.
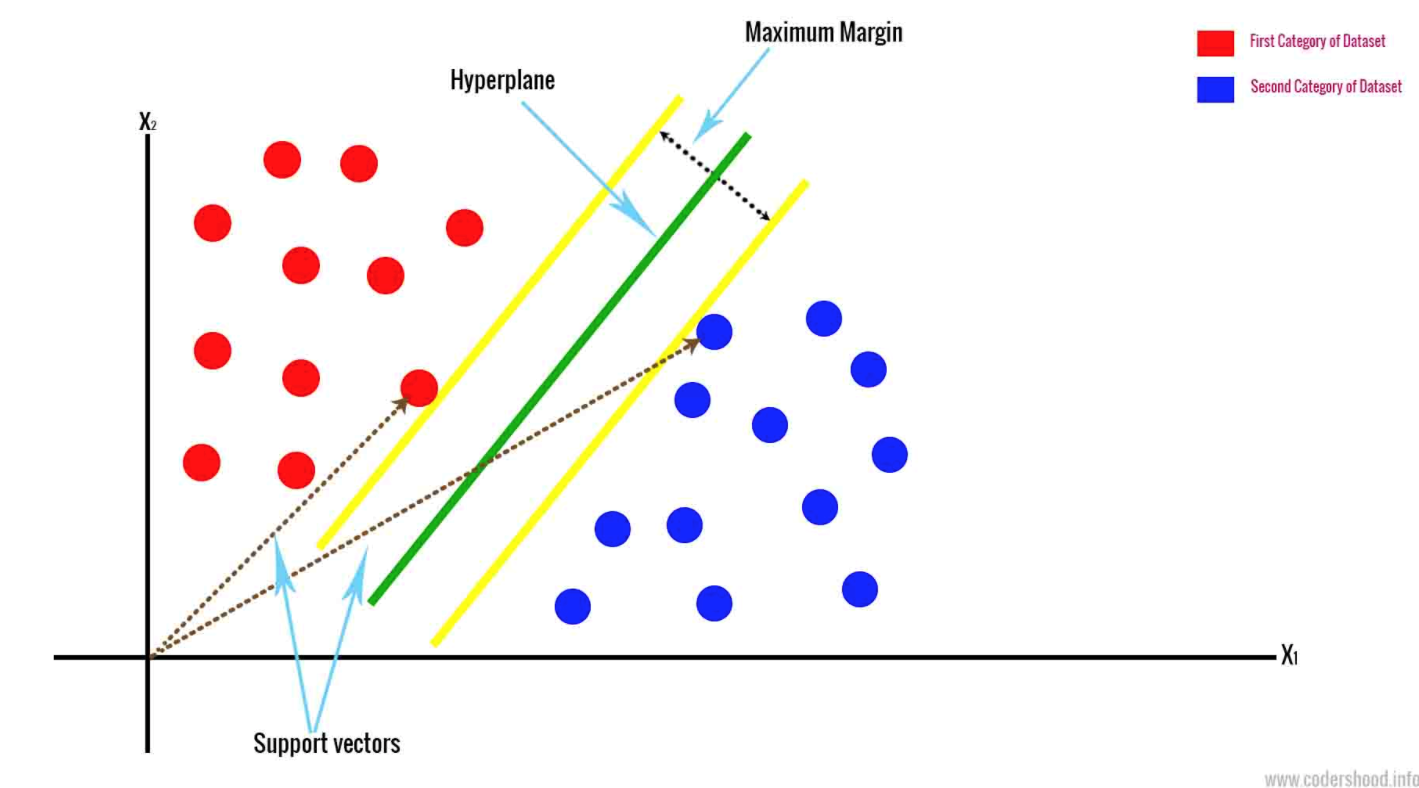
- Die Stützvektormethode zieht auf Basis der zwei nächstgelegenen Datenpunkte eine Hyperebene. Durch Marginalisierung der Klassen werden die Daten getrennt. Anhand eines N-dimensionalen Raums werden sie klassifiziert. N steht für die Anzahl unterschiedlicher Merkmale, die zur Verfügung stehen.
- Naive Bayes berechnet die Wahrscheinlichkeit eines bestimmten Ergebnisses. Er ist sehr effektiv und übertrifft komplexere Klassifizierungsmodelle. Ein Naive Bayes'sches Klassifikationsmodell versteht, dass eine bestimmte Funktion nicht mit dem Vorhandensein anderer bestimmter Funktionen zusammenhängt.
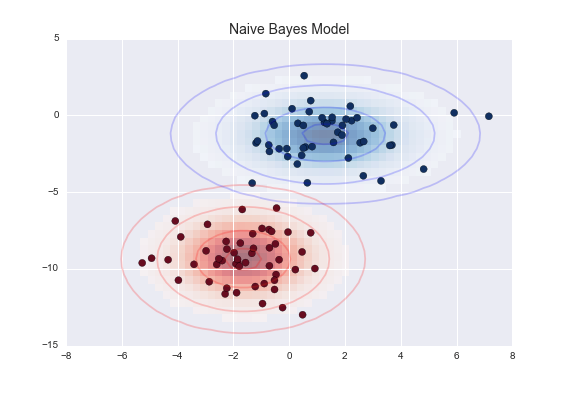
Machine Learning – Modelle
Durch die Kombination der Art des ML (überwacht, nicht überwacht usw.) mit den Techniken und Algorithmen entsteht eine trainierte Datei. Diese Datei kann nun neue Daten erhalten. Sie ist in der Lage, Muster zu erkennen und bei Bedarf Vorhersagen oder Entscheidungen für das Unternehmen, den Manager oder den Kunden zu treffen.
Beste Sprachen für Machine Learning
Machine-Learning-Sprachen geben an, wie Anweisungen für das System geschrieben werden, damit das System lernen kann. Für jede Sprache gibt es eine Anwender-Community, die beim Lernen unterstützt oder andere anleitet. In jeder Sprache sind Librarys enthalten, die für Machine Learning eingesetzt werden können.
Hier sind die Top 10:
- Python
- R
- Java
- Julia
- Scala
- C++
- JavaScript
- Lisp
- Haskell
- Los
Python-basiertes Machine Learning
Da Python die am weitesten verbreitete ML-Sprache ist, steht sie im Folgenden im Fokus.
Python, benannt nach Monty Python, ist eine interpretierte, objektorientierte Open-Source-Sprache. Da sie interpretiert ist, wird sie in Bytecode konvertiert, bevor sie durch eine Python Virtual Machine ausgeführt werden kann.
Aufgrund einer Vielzahl von Funktionen eignet sich Python besonders für ML.
- Eine große Reihe leistungsstarker Pakete kann direkt eingesetzt werden. Es gibt spezifische ML-Pakete, etwa NumPy, SciPy und Panda.
- Prototypen sind einfach und schnell zu erstellen.
- Es gibt eine Vielzahl von Collaboration Tools.
- Wenn ein Data Scientist von der Extrahierung zur Modellierung übergeht und dabei seine ML-Lösung aktualisiert, kann er durchgängig Python als Sprache wählen. Er muss während des ganzen Lebenszyklus nicht zwischen Sprachen wechseln.
Maschinelles Lernen und Cybersicherheit
Das Aufkommen von Ransomware hat das maschinelle Lernen ins Rampenlicht gerückt, da Ransomware-Angriffe zum Zeitpunkt Null erkannt werden können.
Evolution ist das Spiel von Malware. Vor einigen Jahren verwendeten Angreifer dieselbe Malware mit demselben Hash-Wert – dem Fingerabdruck einer Malware – mehrmals, bevor sie sie dauerhaft parkten. Heutzutage verwenden diese Angreifer einige Malware-Typen, die häufig einzigartige Hash-Werte generieren. Zum Beispiel kann die Ransomware von Cerber eine neue Malware-Variante generieren – mit einem neuen Hash-Wert alle 15 Sekunden. Das bedeutet, dass diese Malware nur einmal verwendet werden, was sie mit alten Techniken extrem schwer zu erkennen macht. Geben Sie maschinelles Lernen ein. Mit der Fähigkeit von maschinellem Lernen, solche Malware-Formulare basierend auf dem Familientyp zu erfassen, ist es zweifellos ein logisches und strategisches Cybersicherheitstool.
Maschinenlernalgorithmen sind in der Lage, genaue Vorhersagen basierend auf früheren Erfahrungen mit bösartigen Programmen und dateibasierten Bedrohungen zu treffen. Durch die Analyse von Millionen verschiedener Arten bekannter Cyberrisiken kann maschinelles Lernen brandneue oder nicht klassifizierte Angriffe identifizieren, die Ähnlichkeiten mit bekannten aufweisen.
Von der Vorhersage neuer Malware basierend auf historischen Daten bis hin zur effektiven Verfolgung von Bedrohungen, um sie zu blockieren, zeigt maschinelles Lernen seine Wirksamkeit bei der Unterstützung von Cybersicherheitslösungen, die die allgemeine Cybersicherheitshaltung stärken.
Und obwohl maschinelles Lernen in letzter Zeit zu einem wichtigen Gesprächspunkt in der Cybersicherheit geworden ist, ist es bereits seit 2005 ein integriertes Tool in den Sicherheitslösungen von Trend Micro – lange bevor die Begeisterung überhaupt begann.
Hilfeangebote zur besseren Nutzung von Machine Learning (ML)
Machine Learning kann die Fähigkeit einer Cybersicherheitsplattform, Ihr Unternehmen, Ihre Mitarbeiter und Ihre Partner zu schützen, erheblich verbessern. Dafür sorgt eine schnellere, intelligentere und proaktivere Threat Detection and Response.
Trend Vision One™ ist die einzige KI-gestützte Cybersicherheitsplattform für Unternehmen, die Cyber Risk Exposure Management, Security Operations und einen robusten mehrschichtigen Schutz zentralisiert. Durch diesen umfassenden Ansatz können Sie Bedrohungen vorhersagen und verhindern und so proaktive Sicherheitsmaßnahmen in Ihrer gesamten digitalen Umgebung schneller umsetzen. Trend Vision One nutzt umfangreiche Sicherheitsdatensätze, erweiterte Verhaltensanalysen und Modelle zur Erkennung von Anomalien. Dadurch können Sie bekannte und bisher unbekannte Bedrohungen leichter identifizieren, auch Zero-Day-Exploits und gezielte Phishing-Kampagnen.


Joe Lee ist Vice President of Product Management bei Trend Micro. Er leitet die globale Entwicklung von Strategien und Produkten für Lösungen zur E-Mail- und Netzwerksicherheit in Unternehmen.
Häufig gestellte Fragen (FAQs)
Was ist Machine Learning?
Machine Learning ist eine Form der KI, bei der Computer aus Daten lernen und ihre Leistung im Lauf der Zeit verbessern können, ohne dass sie für jede Aufgabe explizit programmiert werden müssen.
Was ist ein Beispiel für Machine Learning?
Ein Beispiel für Machine Learning sind Technologien zur Gesichtserkennung, bei denen ein Computersystem lernt, visuelle Eingaben zu erkennen, um schließlich menschliche Gesichter identifizieren zu können.
Was sind die vier Arten von Machine Learning?
Die vier Haupttypen von Machine Learning (ML) sind überwachtes Lernen, nicht überwachtes Lernen, halb überwachtes Lernen und verstärktes Lernen.
Wie unterscheiden sich KI und ML?
Künstliche Intelligenz (KI) bezieht sich auf Systeme, die menschliche Intelligenz nachahmen. Machine Learning (ML) ist ein Teilbereich der KI, der Muster in Daten findet, um die Systemleistung zu verbessern.
Ist ChatGPT LLM oder generative KI?
ChatGPT ist ein Beispiel für ein LLM (Large Language Model) und für generative KI (GenAI).
Ist ein Chatbot KI oder ML?
Chatbots werden in der Regel mit Technologien der künstlichen Intelligenz (KI) und mit Machine Learning (ML) entwickelt.
Was ist KI, aber nicht ML?
Einige KI-Systeme basieren nicht auf Machine Learning, beispielsweise regelbasierte Expertensysteme, symbolische Argumentationssysteme und vorprogrammierte Algorithmen, die festen Regeln folgen.
Was ist besser, KI oder ML?
Was „besser“ ist, hängt davon ab, was Sie benötigen. ML ist eine Untergruppe von KI, die es Computersystemen ermöglicht, ohne menschliche Aufsicht aus Erfahrungen zu lernen.
Sollte ich zuerst KI oder ML lernen?
Das hängt von Ihren Interessen und Zielen ab. Die meisten Menschen beschäftigen sich zunächst mit KI im Allgemeinen, bevor sie sich auf Teilbereiche der KI-Technologie wie Machine Learning (ML) spezialisieren.
Weiterführende Artikel
Top 10 Risiken und Minderungen für LLMs und KI-Apps der Generation 2025
Umgang mit neuen Risiken für die öffentliche Sicherheit
Wie weit können internationale Standards uns bringen?
Erstellen einer Cybersicherheitsrichtlinie für generative KI
KI-gestützte bösartige Angriffe unter den größten Risiken
Zunehmende Bedrohung durch Deepfake-Identitäten