Ransomware
Schwachstellen in KI-Agenten: Einführung
KI-gesteuerte Anwendungen übernehmen immer mehr Aufgaben, die Verarbeitung sensibler Daten beinhalten. Deshalb haben wir die kritischen Schwachstellen in KI-Agenten unter die Lupe genommen und geben einen tiefen Einblick in versteckte Bedrohungen.


Save to Folio
Dieser einführende Beitrag ist der Auftakt zu einer Blogreihe über Schwachstellen in KI-Agenten, in der wichtige Sicherheitsrisiken wie Prompt-Injection und Codeausführung beschrieben werden. Er bildet die Grundlage für die folgenden Teile, in denen Themen wie Codeausführungsfehler, Datenexfiltration und Bedrohungen für den Datenbankzugriff näher beleuchtet werden.
Kann ein Large Language Model (LLM)-Dienst zu einem Einfallstor für Cyberangriffe werden? Könnte ein LLM, das Code ausführt, gekapert werden, um schädliche Befehle auszuführen? Können versteckte Anweisungen in Microsoft Office-Dokumenten einen KI-Agenten dazu bringen, sensible Daten preiszugeben? Wie leicht können Angreifer Datenbankabfragen manipulieren, um eingeschränkt verfügbare Informationen zu extrahieren? Dies sind einige der grundlegenden Sicherheitsfragen, mit denen KI-Agenten heute konfrontiert sind.
KI-gesteuerte Anwendungen werden immer häufiger in Branchen wie Finanz-, Gesundheitswesen und anderen eingesetzt und übernehmen Aufgaben wie:
- Automatisierung von Kundenservice-Interaktionen
- Verarbeitung und Analyse sensibler Daten
- Generierung von ausführbarem Code
- Unterstützung bei geschäftlichen Entscheidungen
Was passiert jedoch, wenn Angreifer Wege finden, diese Systeme zu manipulieren? Schwachstellen in KI-Agenten führen zu Ausführung von Schadcode, Diebstahl sensibler Unternehmens- oder Benutzerdaten, Manipulation von KI-generierten Antworten oder indirekter Prompt Injections, die persistente Exploits generieren können.
Darüber hinaus stellen LLMs das Herzstück aller künftigen Agentic-KI-Anwendungen und dienen als Planungs- und „Reasoning“-Engine für Anwendungen, die hauptsächlich unbeaufsichtigt für den Großteil eines Workflows ausgelegt sind.
Diese Risiken lassen sich nicht ignorieren, weder von Anwendungsentwicklern, die LLM-APIs integrieren, noch von Cybersicherheitsexperten, die neue Bedrohungen bewerten oder Führungskräften, die KI im Unternehmen einführen.
LLMs vs. LLM-gesteuerte Dienste
Es gibt einen wichtigen Unterschied zwischen grundlegenden Modellen und den darauf aufbauenden KI-Agenten. Ein grundlegendes Modell wie GPT-4o von OpenAI oder Sonnet, Opus und Haiku von Anthropic ist ein rohes LLM, das Benutzeranfragen beantworten kann. Im Gegensatz dazu bauen LLM-gesteuerte KI-Agenten wie ChatGPT und Claude auf diesen Basismodellen auf, um komplexere Systeme mit Funktionen wie Codeausführung, Speicherung und -Browsing-Fähigkeiten zu schaffen.
Ein LLM ist ein neuronales Netzwerkmodell, das Text als Eingabe nimmt und auf der Grundlage von Mustern, die es aus seinen Trainingsdaten gelernt hat, das wahrscheinlichste nächste Wort (oder genauer gesagt, das nächste Token) als Ausgabe generiert.
LLMs sind von Natur aus anfällig für „Jailbreaking“-Angriffe, bei denen versucht wird, ihre integrierten Sicherheits-, Ethik- oder Inhaltsbeschränkungen zu umgehen, um Antworten zu generieren, die sie ausdrücklich vermeiden sollen.
Zu den gängigen Jailbreaking-Techniken gehören:
- Prompt-Injection: Erstellen von Eingaben, die das LLM dazu bringen, Sicherheitsfunktionen zu ignorieren (z. B. indem es aufgefordert wird, die Rolle einer nicht eingeschränkten KI zu übernehmen).
- Codierungstricks: Verwenden von codierten, verschleierten oder indirekten Abfragen, um die Schutzvorkehrungen eines LLM zu umgehen.
- Manipulatives Framing: Verwenden von Logikschleifen, umgekehrter Psychologie oder Ausnutzen von Eigenwidersprüchen, um unsichere Antworten zu erhalten.
Im Gegensatz dazu ist ein LLM-gesteuerter KI-Agent ein System, das aus vielen miteinander verbundenen Modulen besteht, wobei ein LLM nur einen Teil der größeren Architektur darstellt. Ein LLM-gesteuerter KI-Agent wie ChatGPT würde beispielsweise ein System mit folgenden Komponenten umfassen:
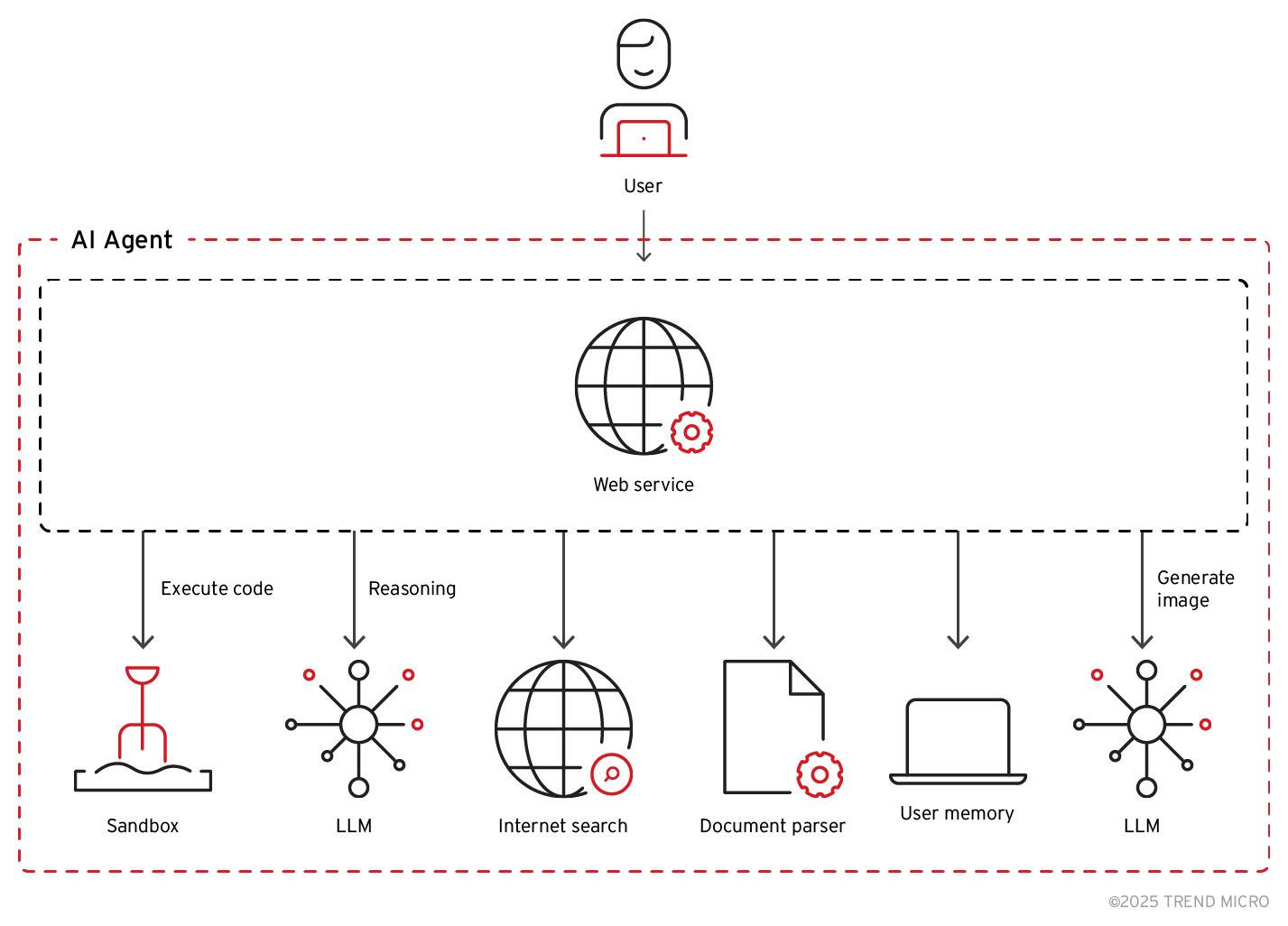
Bild 1. Typische Komponenten eines LLM-gesteuerten KI-Agenten
Das Verhindern von Jailbreaking allein reicht nicht aus, um das gesamte System zu sichern. Schwachstellen können durch die Interaktion zwischen verschiedenen Modulen entstehen, beispielsweise bei der Eingabeverarbeitung, in Ausführungsumgebungen und bei der Datenspeicherung. Diese gegenseitigen Abhängigkeiten können Angriffsvektoren schaffen, bei denen Schwachstellen in einer Komponente ausgenutzt werden können, um eine andere zu kompromittieren, was zu unbefugtem Zugriff, Datenlecks oder Datenmanipulationen führen kann. Dieser Wechsel von modellspezifischen Risiken zu unternehmensweiten Sicherheitslücken erzeugt neue und komplexere Bedrohungen.
Pandora
Pandora nennt sich ein Proof-of-Concept KI-Agent (PoC), der vom Forward-Looking Threat Research (FTR)-Team von Trend Micro entwickelt wurde, um neue und aufkommende Sicherheitslücken in fortschrittlichen KI-Anwendungen zu identifizieren und aufzuzeigen.
Pandora kann Code innerhalb seiner Sandbox-Umgebung dynamisch verarbeiten und ausführen. Der KI-Agent erweitert die ChatGPT-ähnliche Funktionalität durch die Integration von Internetzugang und uneingeschränkter Codeausführung innerhalb einer Docker-basierten Sandbox. Dadurch kann er Eingaben analysieren, Skripts generieren und ausführen sowie mit externen Datenquellen interagieren.
Mit Hilfe kontrollierter Tests hat Pandora Schwachstellen aufgedeckt, wie z. B. indirekte Prompt Injection, die zu unbefugter Datenexfiltration führen kann, sowie Sandbox-Escape-Techniken, die einen dauerhaften Zugriff ermöglichen. Diese Erkenntnisse liefern wichtige Einblicke in die Art und Weise, wie Angreifer die Interaktion zwischen LLMs und ihrer umgebenden Infrastruktur ausnutzen können.
Im nächsten Beitrag zu Schwachstellen bei der Codeausführung stellen wir dar, wie Angreifer Schwachstellen in LLM-gesteuerten Diensten ausnutzen können, um unbefugten Code auszuführen, Sandbox-Beschränkungen zu umgehen und Fehler in Fehlerbehandlungsmechanismen auszunutzen.