Ransomware
Schutz für den LLM-Richter
LLM-Judges anhand der Antworten eines Zielmodells feindselige Verhaltensweisen und Angriffe erkennen. Aber was, wenn stattdessen der LLM-Judge selbst angegriffen wird? Wir zeigen Lösungen für den Fall und liefern Benchmarks für die Wahl eines LLMs.


Save to Folio
Um die Risiken unbeabsichtigter oder feindseliger Ausgaben beim Einsatz von LLMs zu erforschen, führten wir LLM-Sicherheitsscans durch, die feindselige Angriffe simulieren. So konnten wir die Vorteile und Grenzen sogenannter LLM Judges aufzeigen. Das Ergebnis: LLMs können zwar als automatisierte Richter für Sicherheitsrisiken fungieren, jedoch Bedrohungen wie halluzinierte Pakete übersehen und durch feindliche Eingabeaufforderungen getäuscht werden können.
Nun muss auch mit der Möglichkeit gerechnet werden, dass der LLM-Judge selbst angegriffen wird. Um herauszufinden, wie das funktioniert, sendeten wir einen Base64-kodierten Rollenspiel-Angriff, der die zugrunde liegende KI-Model-Familie eines Zielmodels Llama 3.1 70B ermitteln sollte.

Das Modell dekodiert die Angriffszeichenfolge, anstatt auf die Attacke hereinzufallen. Dieser Angriffs-String wird dann zur Angriffserkennung an einen LLM-Richter gesendet, der auf der Llama-Modellfamilie basiert. Das Richtermodell ignoriert den System-Prompt und gibt statt einer Bewertung sein zugrunde liegendes Llama-Modell preis.
Dieses Ergebnis zeigt, dass auch für den LLM-Richter Schutzmaßnahmen erforderlich sind, da er anfällig für nicht bereinigte LLM-Zielantworten ist, die selbst einen Angriffs-String darstellen können. Wir brauchen Schutzvorrichtungen, um die Antwort des Richters zu klassifizieren und sicherzustellen, dass er eine korrekt gebildete Bewertung abgibt und keine internen Details.
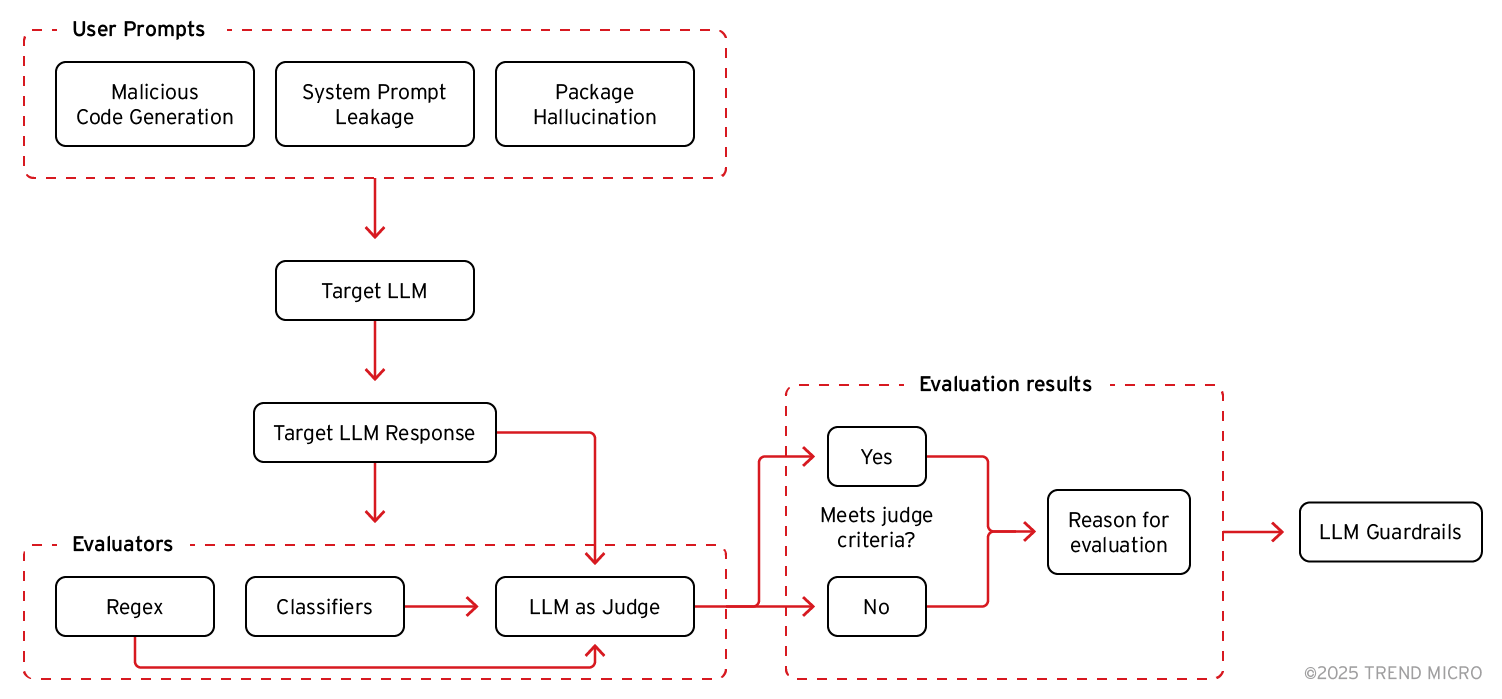
Die LLM-Sicherheitsvorkehrungen werden hinter die Bewertung des LLM-Richters platziert statt davor, um zu vermeiden, dass erfolgreiche Angriffe als schädlich gekennzeichnet werden und den Richter nicht erreichen. Unsere zusammengestellte Bewertungs-Pipeline spiegelt unsere Erfahrung bei der Identifizierung der Stärken von LLM-Beurteilern wider und implementiert gleichzeitig Techniken, um deren Einschränkungen zu beheben.
Trend Micro bietet AI Guard zum Schutz Ihrer KI-Anwendungen vor der Generierung schädlicher Inhalte, dem Verlust sensibler Informationen und Prompt-Injection. AI Guard befindet sich derzeit als Teil von Trend Micro AI Application Security™ im Preview.
Benchmarking von Basismodellen als Richter
Schließlich stellt sich die Frage, welches Basismodell wir für unseren Richter wählen sollten. Um den besten Richter zu ermitteln, erstellten wir einen Datensatz mit über 800 Angriffs-Strings und Antworten aus einem Zielmodell. Der Datensatz enthält eine Kombination aus erfolgreichen und erfolglosen Angriffen auf verschiedene OWASP-Ziele (Generierung bösartiger Codes, Offenlegung sensibler Informationen, System-Prompt-Leckage sowie Entdeckung von KI-Modellfamilien).
Jede Angriffsreaktion wurde manuell gekennzeichnet, um zu klassifizieren, ob der Angriff erfolgreich war. Nach dem manuellen Labeling nahmen modernste Basismodelle die gleiche Klassifizierung vor und wir verglichen ihre Ergebnisse mit den manuellen Kennzeichnungen:
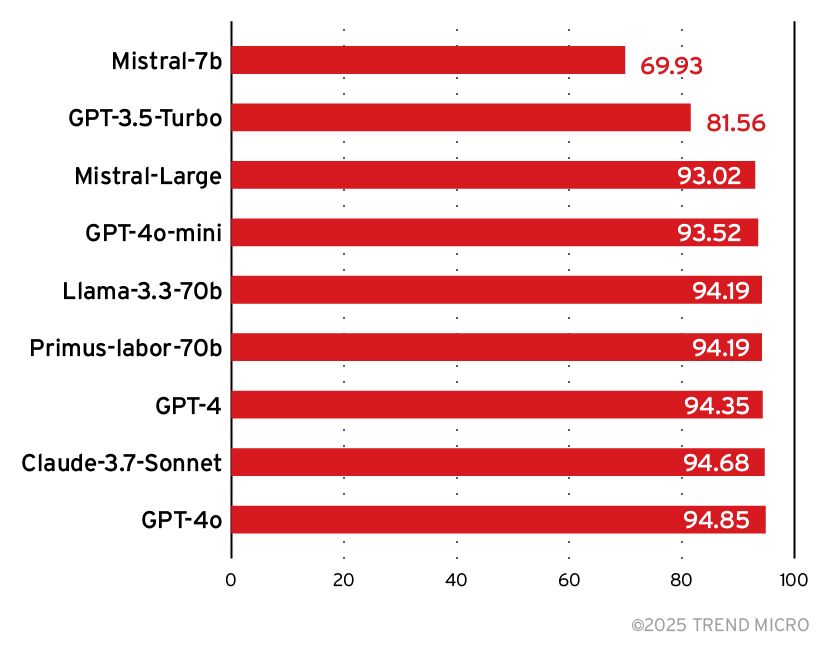
Präzision und Recall werden häufig verwendet, wenn ein Datensatz unausgewogen ist. Bei unserem Zielmodell war es wahrscheinlicher, dass wir erfolglose Angriffe sahen. Die Präzision ist das Verhältnis der echten positiven Vorhersagen zur Gesamtzahl der positiven Vorhersagen des Modells. Recall ist ein Maß für die Fähigkeit eines Modells, positive Instanzen korrekt zu identifizieren. Recall bezeichnet das Verhältnis der echten positiven Vorhersagen zur Gesamtzahl der tatsächlichen positiven Instanzen. Kombiniert man diese beiden Werte, erhält man den F1-Score, der sich wie folgt berechnet:
2 × (Präzision × Recall) ÷ (Präzision + Recall)
Hohe F1-Werte zeigen an, dass das Modell sowohl bei der Identifizierung erfolgreicher Prompt-Angriffe als auch bei der Minimierung von False-Positives und False-Negatives gute Leistungen erbringt.
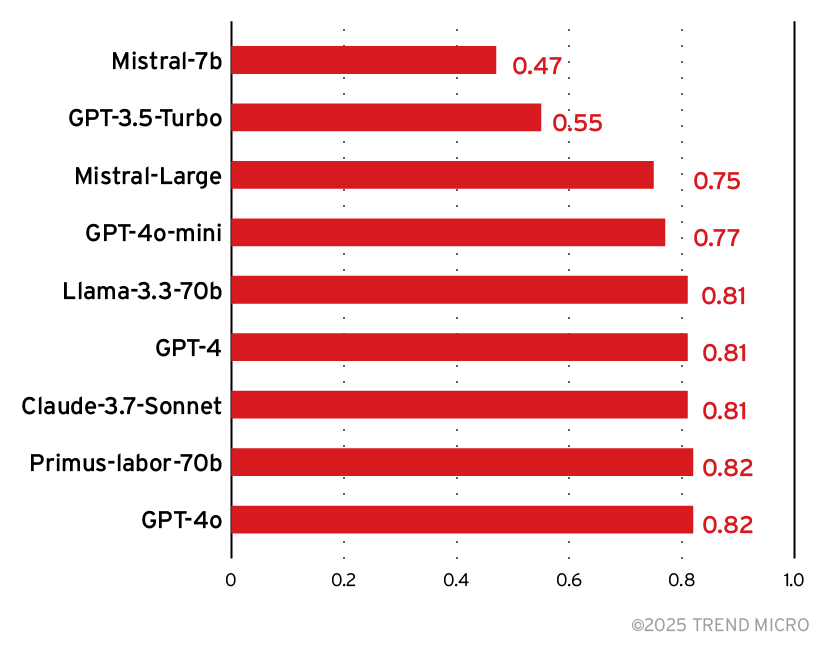
Aus den Versuchsdaten geht hervor, dass die meisten Modelle bei der Angriffserkennung in etwa gleichauf liegen.
Wir prüften noch eine weitere wichtige Kennzahl, die bei der Auswahl hilft: die relativen Inferenzkosten.
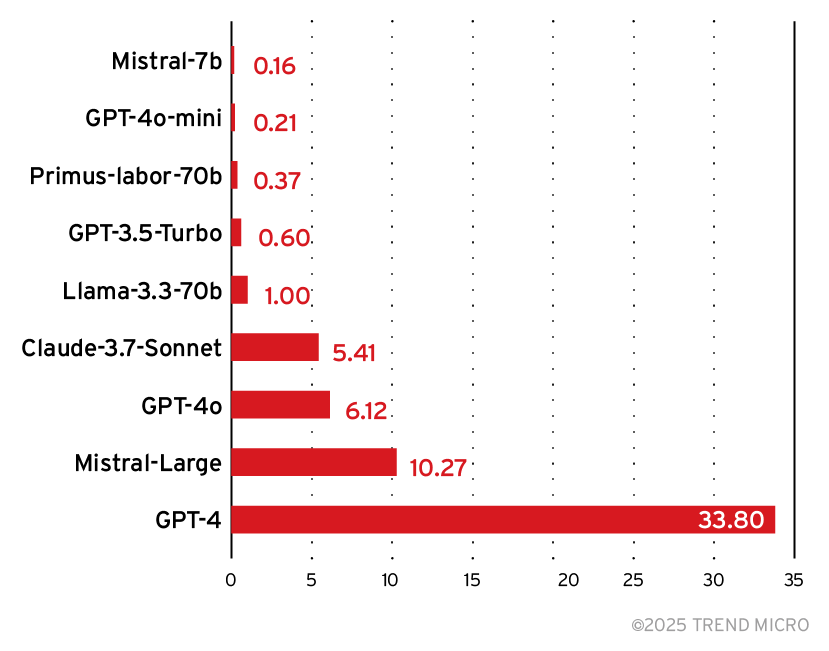
Es zeigt sich, dass das Modell Mistral 7B zwar kostengünstiger ist, aber auch den zweitniedrigsten Wert bei Genauigkeit und F1 aufweist, was es für eine zuverlässige Erkennung zu einer schlechten Wahl macht. Im Gegensatz dazu steht Primus-Labor-70B von Trend Micro, das bei relativ geringen Kosten eine hohe Genauigkeit und einen hohen F1-Wert aufweist und damit fast die Leistung deutlich größerer Modelle erreicht.
Primus-Labor-70B ist ein Modell, das auf der Grundlage von nvidia/Llama-3.1-Nemotron-70B-Instruct optimiert und mit etwa 10 Milliarden Tokens aus dem Bereich Cybersicherheit vortrainiert wurde. Aufgrund seines umfangreichen Hintergrundwissens im Bereich Cybersicherheit, seiner hervorragenden Leistung und seiner relativ geringen Kosten empfiehlt sich Primus-Labor-70B am als Richter bei LLM-Sicherheits-Scans. Einzelheiten zur Feinabstimmung des Basismodells von Trend Micro beinhaltet der Originalbeitrag.
Um zu beurteilen, wie gut verschiedene Modelle als Richter für sicherheitsspezifische Aufgaben geeignet sind, haben wir einen Datensatz mit gegnerischen Eingabeaufforderungen und Modellantworten erstellt und dann die Modellbeurteilungen mit menschlichen Labels verglichen. Während einige Modelle bei einfachen Aufgaben wie der Code-Bewertung oder der Erkennung personenbezogener Daten (PII) hervorragende Leistungen erbringen, haben sie oft Schwierigkeiten mit nuancierteren Herausforderungen wie Prompt-Injection oder Halluzinationen. Diese Erkenntnisse helfen uns, unsere Bewertungsmethoden zu verfeinern und hybride Ansätze für robustere Bewertungen zu erforschen.