Phishing
Backdoors in Open-Source KI-Modellen
Open Source-KI-Modelle entwickeln sich immer mehr zur Grundlage der digitalen Infrastruktur. Doch versteckte Backdoors und manipulierte Lieferketten sorgen für eine neue Bedrohung, die von herkömmlichen Sicherheitstools häufig nicht erkannt wird.


Save to Folio
Zusammenfassung
- Die rasche Einführung von Open-Source-KI-Modellen setzt Unternehmen erheblichen Bedrohungen für die Supply Chain aus.
- Modelle mit Backdoors enthalten bösartige Verhaltensweisen als Auslöser, wodurch sie für statische Analysen, SBOMs oder Codeüberprüfungen nahezu unsichtbar sind.
- Fehlende Herkunftsnachweise und Prüfpfade, unsichere Abhängigkeiten, fehlende Signaturstandards und minimale Angreifertests begünstigen unentdeckte Backdoors in KI-Systemen.
Open-Source-KI-Modelle sind für moderne digitale Infrastrukturen unverzichtbar geworden und kommen in Anwendungen vom Kundensupport-Bot bis zur medizinischen Diagnostik zum Einsatz. Ein aktueller Bericht von McKinsey zeigt, dass 72 % der Technologieunternehmen quelloffene KI-Modelle einsetzen.
Diese breite Akzeptanz hat branchenübergreifend transformative Möglichkeiten eröffnet, aber auch eine kritische, bisher übersehene Schwachstelle mit sich gebracht: Backdoors in den Modellen. Im Gegensatz zu herkömmlichen Softwarekomponenten sind KI-Modelle komplex und undurchsichtig, oft mangelt es ihnen an Transparenz. Diese Undurchsichtigkeit macht sie anfällig für böswillige Manipulationen, wie die durch Backdoors, die während der Trainings- bzw. Feinabstimmungsphasen oder ungeprüfte Abhängigkeiten von Drittanbietern eingeführt werden.
Dies sind keine herkömmlichen Fehler und stellen daher eine besondere Herausforderung für die Sicherheit dar. KI mit Backdoors stellen eine Klasse von Bedrohungen dar, bei denen das Verhalten selbst die Schwachstelle ist, die durch statische Überprüfung nicht erkannt werden kann und unter Schichten von gelernten Parametern verborgen ist. Dies macht sie besonders gefährlich in Open-Source-Ökosystemen, in denen Vertrauen oft auf der Transparenz des Codes basiert – etwas, das KI-Modellen von Natur aus fehlt.
Die Backdoors bleiben unter normalen Bedingungen in der Regel inaktiv und werden erst bei bestimmten Auslösern aktiviert, was zu Datenlecks, Fehlklassifizierungen oder unbefugten Aktionen führt. Herkömmliche Sicherheitsmaßnahmen, darunter Software Bills of Materials (SBOMs) und statische Code-Analyse-Tools, sind für die Erkennung solcher Bedrohungen in KI-Modellen ungeeignet.
Plattformen wie Hugging Face und GitHub sind beliebt, doch bieten sie der Öffentlichkeit gehostete Open-Source-Modelle mit nur minimaler Überprüfung an. Laut einer Studie von JFrog enthielten von über einer Million Modellen auf Hugging Face 400 davon bösartigen Code.
Wir haben das gesamte Lebenszyklusrisiko, das von Backdoor-Modellen im Open-Source-KI-Ökosystem ausgeht, untersucht. Wir verwendeten das MITRE ATLAS-Framework, um die Techniken abzubilden und so eine strukturierte Methode zum Verständnis von KI-spezifischen Bedrohungen und deren Ausprägungen bereitzustellen. Angriffe auf KI-Modelle lassen sich am besten verstehen, wenn man sie danach gruppiert, welche Phase des Lebenszyklus des maschinellen Lernens sie ausnutzen.
1. Angriffe auf die Trainingsphase: Die Grundlage korrumpieren
Diese Angriffe nutzen Schwachstellen in den Datenerfassungs- und Trainingsprozessen aus, um Schwachstellen direkt in die Logik des Modells einzubetten.
- Datenvergiftung: Bösartige Samples werden in die Trainingsdaten eingeschleust, um das Modell subtil zu verfälschen oder gezielte Backdoors einzuschleusen. Das Modell lernt diese bösartigen Muster, als wären sie legitime Informationen. So etwa GPT-basierte Chatbots, die absichtlich mit vergifteten Dialogen trainiert wurden, die bei bestimmten Eingaben unsicheres Verhalten auslösen.
- Label Poisoning: Dabei manipuliert der Angreifer gezielt die Labels von Trainingssamples. Dies ist besonders gefährlich während der Feinabstimmung, wenn ein sauberes Basismodell durch korrekt formatierte, aber böswillig beschriftete Daten subtil manipuliert werden kann. Beispiel: Ein Sentiment-Analyse-Modell wird mit Bewertungen fein abgestimmt, wobei positive Texte über das Produkt eines Mitbewerbers absichtlich als „negativ” gekennzeichnet werden.
2. Angriffe auf die Speicher- und Verteilungsphase (Supply Chain): Manipulation nach dem Training
Diese Angriffe nutzen Schwachstellen in der Art und Weise aus, wie Modelle gespeichert, geteilt und verteilt werden – sie treten nach dem Training des Modells, aber vor dessen Einsatz auf.
- Manipulation auf Gewichtungsebene: Angreifer mit Zugriff auf die Modelldatei manipulieren direkt die Gewichtungen des neuronalen Netzwerks mithilfe von adversarial Optimierungstechniken wie Substitution. Dies kann mit chirurgischer Präzision erfolgen, um eine Malware einzuschleusen, ohne das Modell neu zu trainieren.
3. Angriffe auf die Lade- und Bereitstellungsphase: Ausnutzung der Laufzeitumgebung
Diese Angriffe zielen nicht auf die Logik des Modells ab, sondern nutzen unsichere Praktiken beim Laden und Ausführen von Modelldateien aus.
- Remote-Code-Ausführung (RCE) über Deserialisierung: Einige Modellformate (z. B. Python-Pickle- und ältere PyTorch-.pt-Dateien) sind von Natur aus in der Lage, Code auszuführen. Angreifer betten bösartigen Code in die serialisierte Modelldatei ein, der beim Laden des Modells auf dem Server ausgeführt wird. Beispiel: Eine in eine .pkl-Datei eingebettete Payload, die beim Laden eine Reverse-Shell zurück zum Rechner des Angreifers öffnet.
- Schädlicher Code in Modellcontainern: Moderne Plattformen (z. B. Ollama) verpacken Modelle häufig in Container-Images (z. B. OCI). Angreifer können schädliche Skripte oder Binärdateien zusammen mit den legitimen Modellgewichten im Container bündeln, sodass bei Ausführung des Containers Code ausgeführt wird. Beispiel: Ein Modellcontainer enthält ein schädliches Skript „on-start.sh“, das Umgebungsvariablen oder Anmeldedaten exfiltriert.
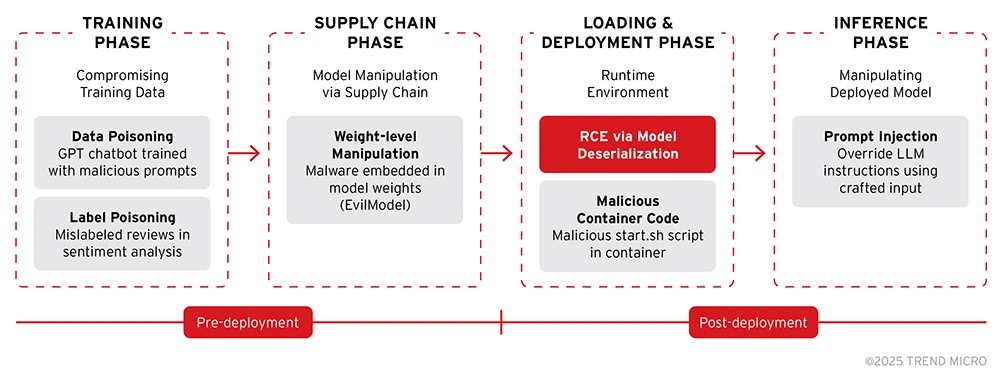
Bild 1. Arten von Modell-Backdoors
Resultierendes Backdoor-Verhalten
Die oben beschriebenen Angriffe können zu einer Reihe von bösartigen Verhaltensweisen führen. Eine der häufigsten und bekanntesten ist die triggerbasierte Backdoor. Sie ist das Ergebnis von Angriffen wie Datenvergiftung oder Gewichtsmanipulation. Das kompromittierte Modell verhält sich bei den meisten Eingaben normal, zeigt jedoch ein spezifisches, bösartiges Verhalten, wenn es auf einen vordefinierten „Trigger“ trifft.
Dieser Auslöser kann ein bestimmtes Wort, eine Phrase, ein Image oder ein Muster sein. Beispiel: Ein durch Datenvergiftung kompromittiertes Vision-Modell identifiziert alle Verkehrszeichen korrekt, außer wenn ein bestimmter gelber Aufkleber (der Auslöser) auf einem Stoppschild vorhanden ist, wodurch es als „Geschwindigkeitsbegrenzung 85” klassifiziert wird.
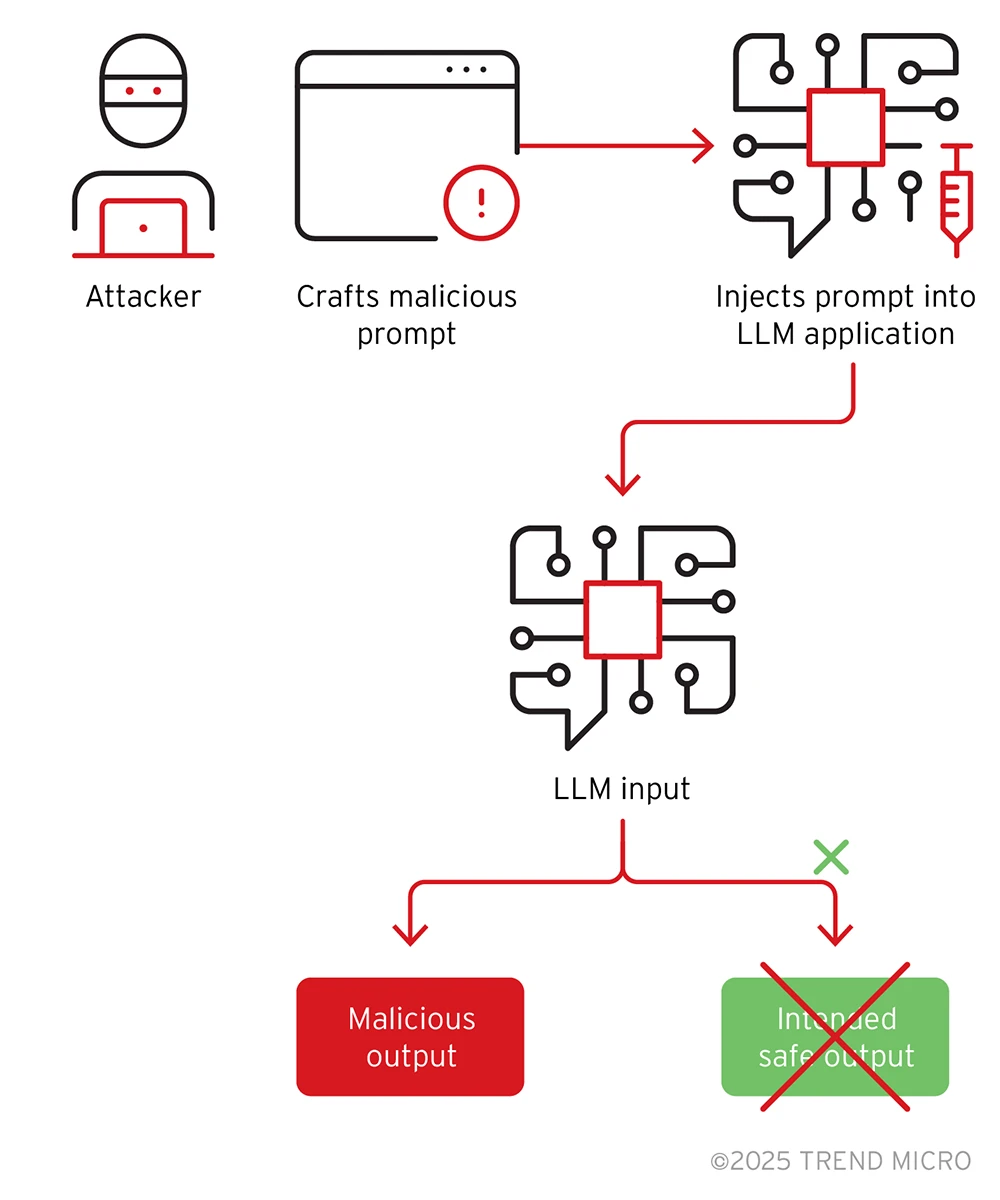
Bild 2. Beispiel eines Prompt Injection-Angriffs
Herausforderungen bei der Erkennung
Es gibt mehrere Faktoren, die die Erkennung dieser Bedrohungen erschweren, darunter
- Undurchsichtige Architektur: Modellgewichte sind komplexe numerische Matrizen; bösartige Logik erscheint nicht als Zeichenfolgen oder Funktionen.
- Keine Grundwahrheit: Bei kreativen Ergebnissen von Modellen wie LLMs ist unklar, was „erwartet” und was „manipuliert” ist.
- Fehlende Herkunftsangaben: Bei vielen Modellen fehlen Metadaten zu ihren Trainingsdaten, Hyperparametern oder Optimierungsprozessen.
- Begrenzte Tests: Viele Unternehmen testen Modelle nur für ihren Anwendungszweck und nicht für gegnerische Eingaben wie winzige Bildrauschen, physische Aufkleber, Ein-Pixel-Änderungen, Wortersetzungen (Synonyme, Homoglyphen), Tippfehler, Prompt-Injection und unhörbare Audiofrequenzen.
- Begrenzte Kenntnisse und Erfahrungen: In der aktuellen frühen Phase der Einführung von KI mangelt es allgemein an tiefgreifendem Verständnis und etablierten Best Practices zur Identifizierung und Abwehr dieser raffinierten Angriffe.
Der Originalbeitrag enthält auch Fallbeispiele.
Sicherheitslücken in der Supply Chain von Open-Source-KI-Modellen
Zu den wichtigsten Problemen zählen die mangelnde Herkunftsnachweisbarkeit und Transparenz, da Modelle ohne klare Prüfpfade oder verifizierte Herkunft geteilt werden, sodass böswillige Akteure unbemerkt manipulierte oder mit Hintertüren versehene Modelle einführen können, sowie das Fehlen einer standardisierten Modellsignierung und die schwache Durchsetzung von Prüfsummen, wodurch das Ökosystem während der Verteilung weiter für Manipulationen anfällig ist.
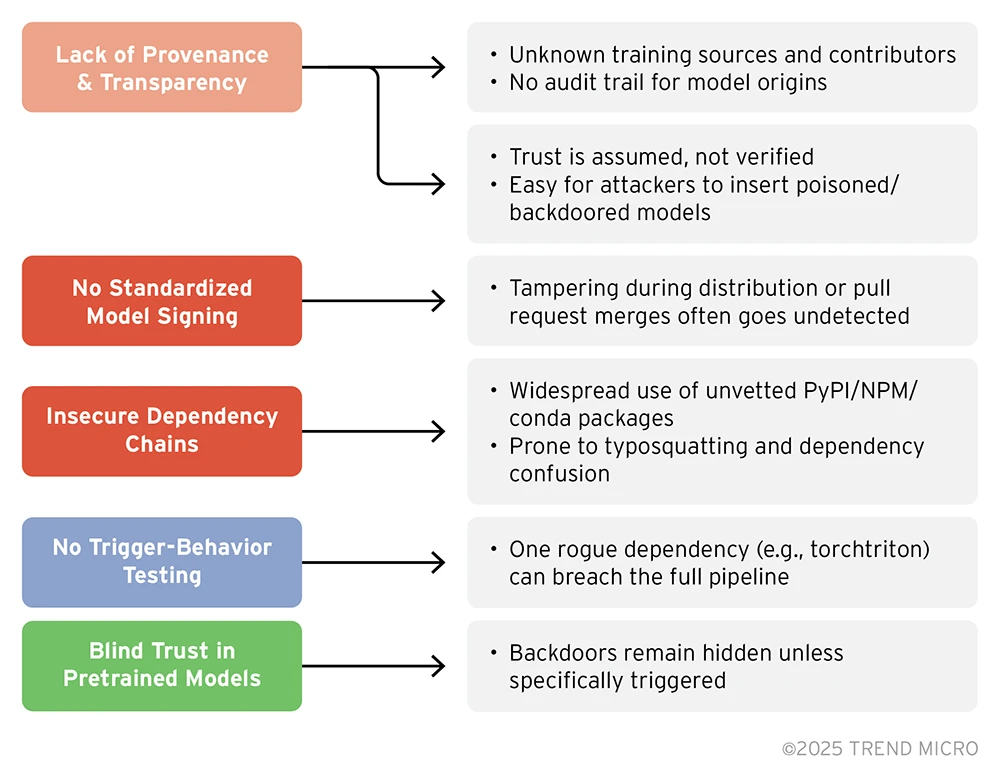
Bild 3. Sicherheitslücken in der Supply Chain
Unser zweiter Teil zum Thema zeigt, wie diese Backdoors erkannt werden können und wie der Schutz dagegen aussieht.