Malware
A Machine Learning Model to Detect Malware Variants
When malware is difficult to discover — and has limited samples for analysis — we propose a machine learning model that uses adversarial autoencoder and semantic hashing to find what bad actors try to hide.


Save to Folio
For a piece of malware to be able to do its intended malicious activity, it has to be able to sneak inside a machine’s system without being flagged by cybersecurity defenses. It camouflages and packages itself to look like a benign piece of code and, when it has cleared past security filters, unleashes its payload. When malware is difficult to discover — and has limited samples for analysis — we propose a machine learning model that uses adversarial autoencoder and semantic hashing to find what bad actors try to hide. We, along with researchers from the Federation University Australia, discussed this model in our study titled “Generative Malware Outbreak Detection.”
Seeing the Stealthy: Obfuscated Malware
Malware authors know that malware is only as good as its ability to remain undetected for it to compromise a device or network. Hence, they use different tools and techniques to keep attacks under the radar. And malware authors have been hard at work at making malware even harder to detect, using various techniques such as sandbox evasion, anti-disassembly, anti-debugging, antivirus evasion, and metamorphism or polymorphism. Take for example the RETADUP worm, which was previously used for targeted attacks and cyberespionage, which turned polymorphic. Its new variant is coded in AutoHotKey and, like one of its AutoIt variants, is geared towards cybercriminal cryptocurrency mining. When malware is obfuscated, it is hard for traditional antivirus systems to detect. We discussed in a previous article how to address this issue: by identifying an important feature in malware samples that remains relatively unchanged no matter how morphed the samples become, i.e., the program instruction sequence. This follow-up blog will give a deeper insight into how adversarial autoencoder deals with the program instruction sequence, and what semantic hashing does in our proposed model.
A Deeper Learning: Adversarial Autoencoder and Semantic Hashing
Our machine learning model, which we call aae-sh, is composed of two independent modules. The first one uses adversarial autoencoder to acquire the latent representation for the program instruction sequence, a feature that is resistant to obfuscation techniques. The second deals with the class number for the latent representation, which is computed via HDBSCAN, a clustering algorithm, with a predefined threshold.
Adversarial autoencoder
For malware outbreaks with only a limited number of samples, adversarial autoencoder is effective as it enables the production of smooth approximated nearby distributions of even a small number of training samples. In fact, our proposed machine learning model uses a single malware sample for each malware class for training with adversarial autoencoder. The core architecture for malware outbreak detection in the study is taken from the original adversarial autoencoder.
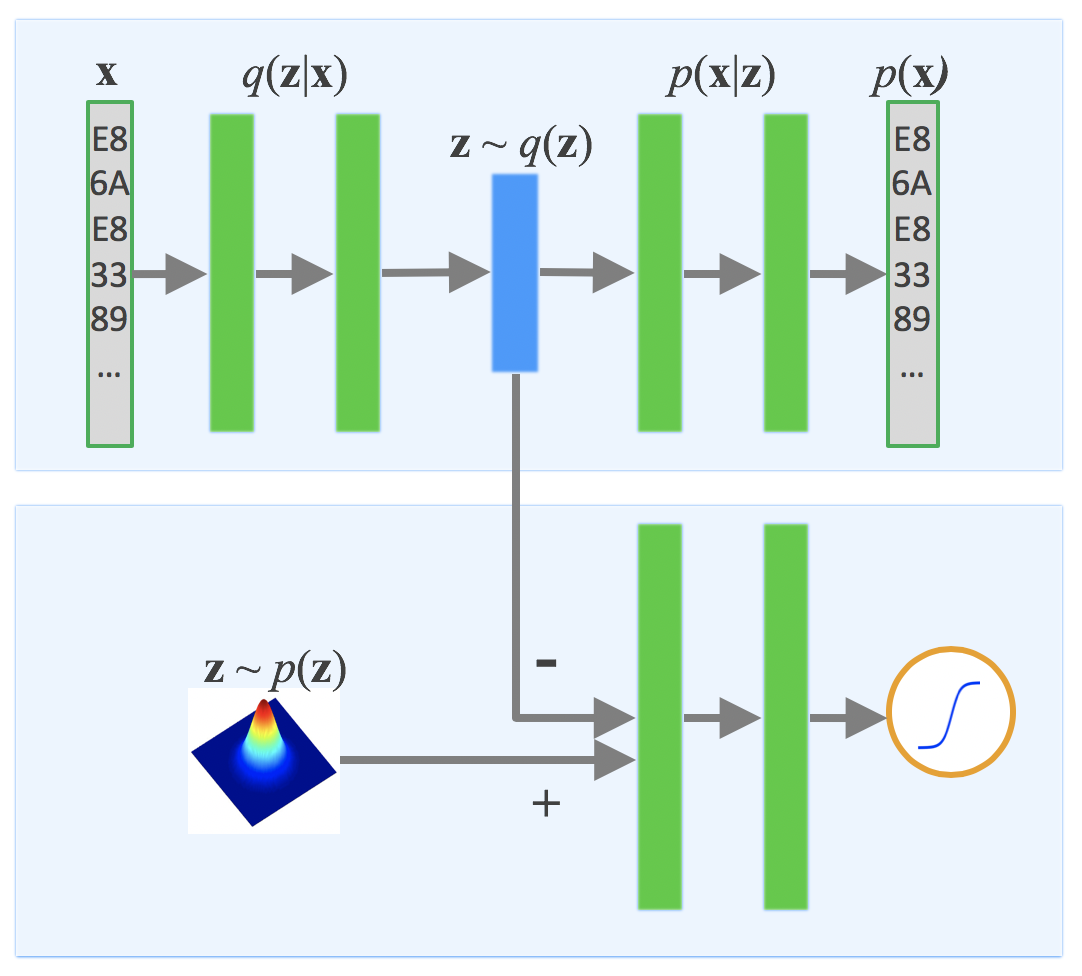
Figure 1. Adversarial autoencoder architecture used for malware outbreak detection
Note: The input, x, and the reconstructed input, p(x), have the instruction sequence feature.
What adversarial autoencoder does is it combines an arbitrary autoencoder with generative adversarial network (GAN). GAN is responsible for training the generator and the discriminator in a tight competitive loop. For an autoencoder to work in this model, it must have the following properties:
- The stacked weights are symmetric and shared between encoder and decoder.
- It must have all of GAN’s generator properties. An encoder functions dually, hence, it needs to have the training techniques used for the generator while maintaining its autoencoder property.
The ability to identify relocated functions is a preferred malware outbreak detection property. And a stacked convolutional autoencoder aims to take advantage of the translation invariant property of the architecture,[1] allowing the machine learning model to determine the program instruction sequence despite code transposition and integration metamorphism.[2]
Alireza Makhzani et al introduced the need for both the adversarial network and the autoencoder to be mutually trained with stochastic gradient descent in two phases — the reconstruction phase and the regularization phase — after which they are executed on each mini-batch of samples.
There are a number of hyperparameters that can be tuned in the network architecture, including how much of diverse malware clusters should be detected or the batch size. For training malware samples under this model, batch normalization within the GAN generator is necessary to help generate a consistent latent representation for each cluster. To make sure that this happens, the Adam optimizer, an auxiliary optimization algorithm for stochastic gradient descent, was used for both the reconstruction and regularization phases. Meanwhile, for consensus optimization — which mitigates the instability caused by standard adversarial autoencoder training — RMSProp was used. RMSProp is an optimization algorithm for deep neural networks. The hyperparameters of the model were then determined.
Once training is done, the encoder output is taken as a latent vector that represents the input sample. The input sample is then used for semantic hashing.
Semantic hashing
Semantic hashing transforms the latent representation acquired via adversarial autoencoder into a class number for prediction. To get the class number, the latent vector represented by real valued numbers are binarized using the bitwise mean value of the training samples. Then, the hamming distance — which is the number of positions at which parallel symbols between two strings of equal lengths are not the same — is used to calculate the distance for the two given latent vectors.[3] A test sample is assigned a class with the closest training sample.
Analysis: Flashback Variants
In our research, using the aae-sh model, we accurately identified malware variants whose major feature mass is identical across all samples in the cluster despite having been morphed or modified. Visual analysis of the families detected by aae-sh showed similar instruction sequences even with variations within the family. We discovered that certain malware families, like Flashback, reuse the same piece of code repetitively across their variants — which the aae-sh model is able to catch and identify effectively. The study detected a cluster which contains many Flashback variants (cluster 49). Note that aae-sh detected the samples of different lengths as long as the instruction sequences are similar.
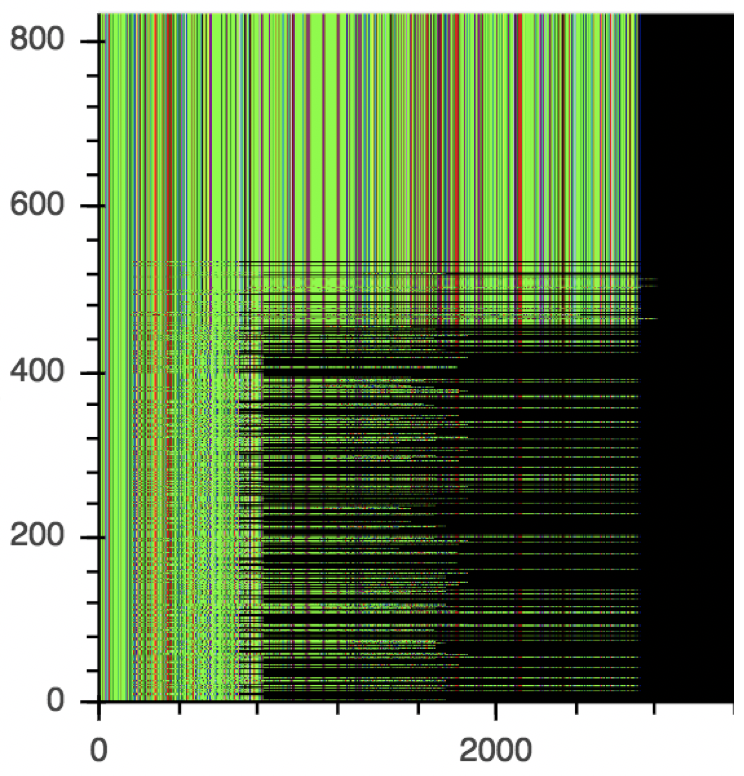
Figure 2. Visualization of the instruction sequences of malware samples within cluster 49 identified by aae-sh
Note: The X-axis represents the feature while the Y-axis represents the sample number.
And because aae-sh identifies malware variants based on the instruction sequence pattern, we noted around 447 samples of the Flashback variant that were not named according to its malware family, as VirusTotal analysts tag detection names based on analyst-specific heuristics.

Figure 3. VirusTotal detection names for the samples in cluster 49 that are visualized in Figure 2
Our study also showed that, aside from accurately detecting malicious samples, the aae-sh model also records 91 percent accuracy over benign samples compared to the traditional classification models’ 100 percent false positives. Our research paper “Generative Malware Outbreak Detection” gives a comprehensive discussion on the methods, results, and analysis of our proposed machine learning model for detecting malware outbreaks with limited samples.
[1] Jonathan Masci, Ueli Meier, Dan Cireşan, Jürgen Schmidhuber. “Stacked Convolutional Auto-encoders for Hierarchical Feature Extraction.” In Artificial Neural Networks and Machine Learning–ICANN 2011, pages 52-59, September 2014.
[2] Ilsun You and Kangbin Yim. “Malware Obfuscation Techniques: A Brief Survey.” In 2010 International Conference on Broadband, Wireless Computing, Communication and Application, pages 297-300, 4 November 2010.
[3] Ruslan Salakhutdinov and Geoffrey Hinton. “Semantic Hashing.” In International Journal of Approximate Reasoning, pages 969-978, 7 July, 2009.