Malware
Making Machine Learning Systems Robust for Security
To be one step ahead of cybercriminals, one method of enhancing a machine learning (ML) system to counter evasion tactics is generating adversarial samples, which are input data modified to cause an ML system to incorrectly classify it.


Save to Folio
The history of antimalware security solutions has shown that malware detection is like a cat-and-mouse game. For every new detection technique, there’s a new evasion method. When signature detection was invented, cybercriminals used packers, compressors, metamorphism, polymorphism, and obfuscation to evade it. Meanwhile, API hooking and code injection methods were developed to evade behavior detection. By the time machine learning (ML) was used in security solutions, it was already expected that cybercriminals would develop new tricks to evade ML.
To be one step ahead of cybercriminals, one method of enhancing an ML system to counter evasion tactics is generating adversarial samples, which are input data modified to cause an ML system to incorrectly classify it. Interestingly, while adversarial samples can be designed to cause ML systems to malfunction, they can also, as a result, be used to improve the efficiency of ML systems.
Making machine learning systems more robust via adversarial samples
Adversarial samples can help identify weaknesses in an ML model, which, in turn, can be used to gain valuable insights on how to enhance the model. By using a huge number of handcrafted samples modified from original malware, it is possible to repeatedly probe the capability of an ML system. This way, adversarial samples can retrain an ML system to make it more robust.
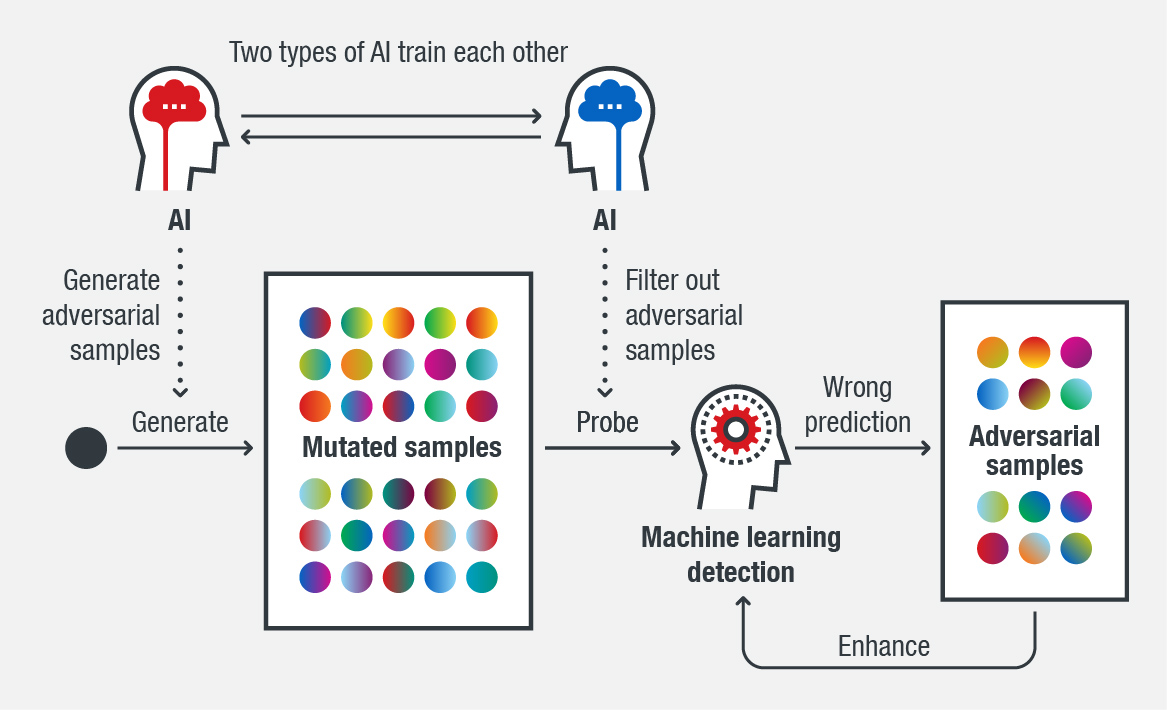
Figure 1. Using adversarial samples and AI to make an ML system more robust
At the onset of our research on a system to generate adversarial samples, we saw high probability scores. If a file is detected with a high score, it means it has more similarities to the malware samples in our ML training set. The goal is to gradually reduce the high probability score by modifying the malware sample until it becomes undetected. If successful, it means we have identified a weakness in the ML system and we may consider a range of activities to mitigate this weakness, such as identifying new features, do searches for related malware, or use other components to identify such variants.
We selected a malware sample as seed, and defined it as m, a value signifying a certain number of possible changes (for example, 10, 20, 32, and 64). In our research, m is 32, which means we pre-defined 32 possible ways to modify the malware file. Through a genetic algorithm (GA), we found the combinations of changes we can implement to the malware for it to evade detection. Here are the steps we took:
- Generate a batch of new files with random n of m changes on the seed file.
- Get ML prediction (detected or undetected) and gradient information (probability) on the new generated files.
- If it reaches N loops (for example, 200), collect all undetected files from the whole procedure, and then exit.
- Choose X (certain number) files as new seeds, which are undetected or detected, but with the lowest probability score.
- Generate another batch of files by implementing a random combination of changes in the seeds and random new changes (optional).
- Repeat step 2. The changes may damage and render the portable executable (PE) file unable to run. Also use a sandbox technology to validate if a newly generated file is still executable.
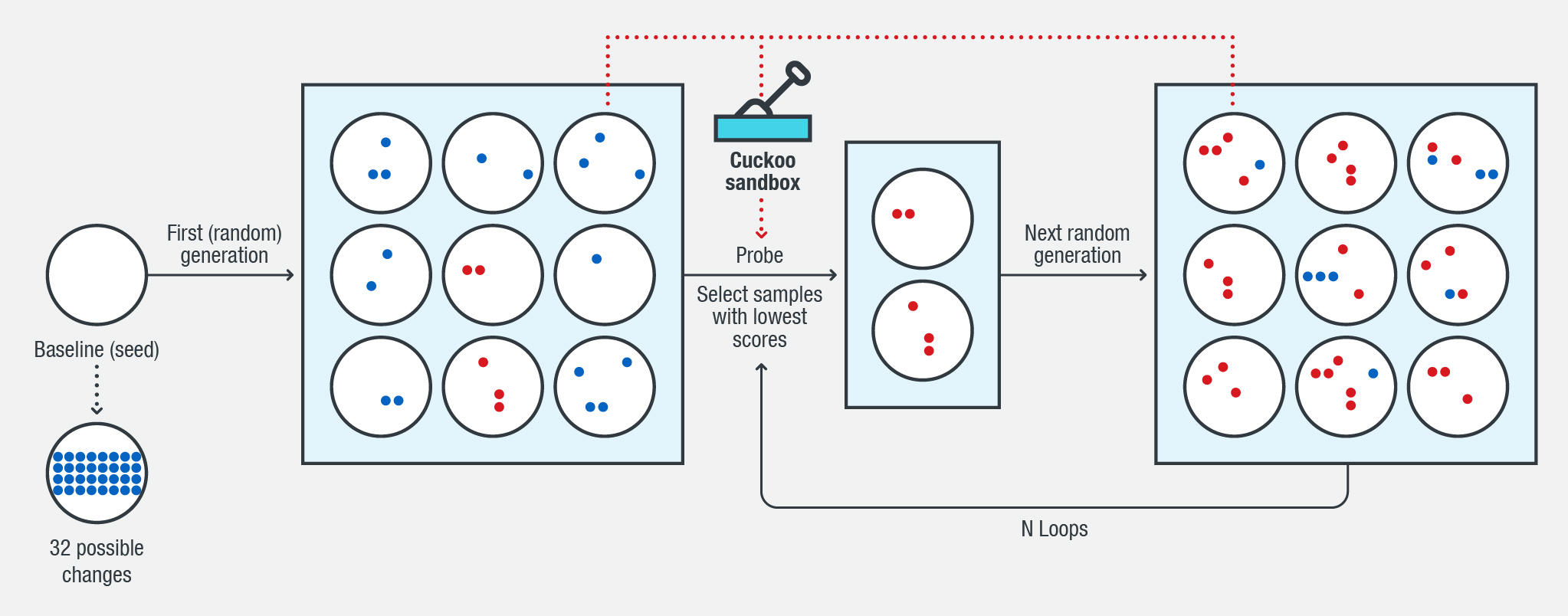
Figure 2. How we generated adversarial samples using genetic algorithm (GA)
In our findings, we observed that the probability output can be a security hole that the attackers can exploit to easily probe an ML system’s capability. Therefore, this number should be hidden in security products. With no probability output as a guide, we got curious whether a brute force method can be used to generate adversarial samples. We discovered that it still worked, but instead of producing one sample (in an undetected and undamaged state) in every 60 samples (when GA is used), we were able to produce only one in every 500 samples using brute force method.
The modification success rate of 0.2 percent (= 1/500) for the brute force method can still be considered a successful rate for generating adversarial samples when taking into account the significant and fundamental changes to the file structure. In our experience, approximately 3 percent of the generated samples were undamaged even after undergoing changes, and 7 percent of the samples were undetected. However, when that one (out of 500) adversarial sample is used as a seed in the next phase where we generate another batch of samples, the success rate can increase back to 1.5 percent. The generation rate of undamaged samples will still be at 3 percent, but around half of the samples will be undetected.
There are two main factors to consider when generating adversarial samples: First, figuring out how to safely modify a PE file without damaging it, and second, finding a method to generate undetected samples efficiently. For the second point, AI can be used for choosing the right file features to modify and map the changes to the features and the numerous potential changes to the PE files. It takes a lot of time and effort to come up with as many possible combinations of changes to a sample and to test them in a system to produce all possible adversarial samples. ML can help quickly choose the most useful changes or combinations that can decrease gradient information (i.e., probability) — therefore making adversarial sample generation more efficient.
Protecting ML systems from potential evasion methods and other attacks
While using adversarial samples to enhance an ML system can be effective, security holes may still appear for cybercriminals to exploit. For example, in the same way that we were trying to add normal characteristics to a malware sample for it to seem benign and become undetectable, attackers could find ways to evade detection by infecting a benign PE file or compiling a benign source code with malicious code or injecting binary code. These methods can make a malware appear benign to an ML system when its structure still comprises mostly that of the original benign file. This can bring challenges to an ML system: If this situation is not carefully accounted for, then some ML systems might detect the compromised file as more similar to the benign file it originated from.
ML training set poisoning is another issue to watch for. When an ML system’s training set includes malware samples similar to benign files, it will be prone to false positives. Example: the PTCH_NOPLE malware, a patch family that modifies the dnsapi.dll file, which is a module that assists the DNS client service in the Windows® operating system. Some ML systems in the industry have higher false positive rates because of benign dnsapi.dll files infected with PTCH_NOPLE.
To counter evasion methods and other types of attacks against machine learning in security solutions, we came up with mitigation techniques.
- Set up a defense at the infrastructure level by reducing the attack surface of the ML system. Some ways to achieve this include the following:
- Not exposing the system to probing or making the system less susceptible to probing. An attacker can stealthily modify samples to probe an ML system by using a free tool that has a local ML model for trial use. A cloud-based system can prevent this, as all predictions by the ML system can be recorded at the backend. That way, details on who is attempting to probe the model and where and when the attempt happened can be tracked. Distribution and usage of such tools should be limited.
- Use cloud-based solutions, such as products with Trend Micro™ XGen™ security, to detect and block malicious probing. If an attempt is detected by the solution, it will show fake results to the attacker or it can terminate the product or service associated with the account the attacker is using.
- Use security products armed with a combination of detection technologies. By doing this, the attacker cannot exactly know which will be the only sample detected by the ML system.
- Hiding the real gradient information (probability score) of an ML system.
- Make the ML system more robust, first, by identifying potential vulnerabilities early on in its design phase and making it accurate for every parameter. Second, generate adversarial samples and use them to retrain the ML model. It could be done via black box testing using GA or brute force computation, or white box testing. These two methods should be implemented continuously throughout the ML system’s whole lifecycle.
- Consider using generative adversarial network (GAN). GAN has two types of AI: one generates new data instances, and the other evaluates them for authenticity. The two AI types can train each other and evolve. We also used GAN to find better ways to generate adversarial samples (automatically) as well as to find ways to secure them.
- To reduce false positives caused by threats such as PTCH_NOPLE, use security solutions that not only utilize ML for detection but also for whitelisting. Trend Micro XGen security uses the Trend Micro Locality Sensitive Hash (TLSH), an approach that generates a hash value which can then be analyzed for similarities. Since collecting all file versions and adding them for whitelisting is difficult, a similar version of a file that is known and legitimate can be used to compare to a wrongly detected file. If their TLSH values are similar and they have the same signature chain, false positives can be reduced. Therefore, we also encourage application developers to sign their files to reduce the risk of files being misclassified by antimalware products.
Enhancing a machine learning system fortifies overall cyberdefense
An efficient ML system should detect not only existing malware but also adversarial samples. Using GANs, GAs, and brute force methods, among other strategies, can enable an ML system to perform such a task. This capability can give an ML system a wider coverage for threats and lower false positive rates, which in turn, can help an ML system detect and counter evasion techniques when coupled with an ML-based whitelisting method. Countermeasures for ML evasion methods will be one of the key features in ML in cybersecurity in the future. Looking out for evasion samples in the wild is important because in the game of evasion versus anti-evasion, it will be difficult to detect what can’t be seen.
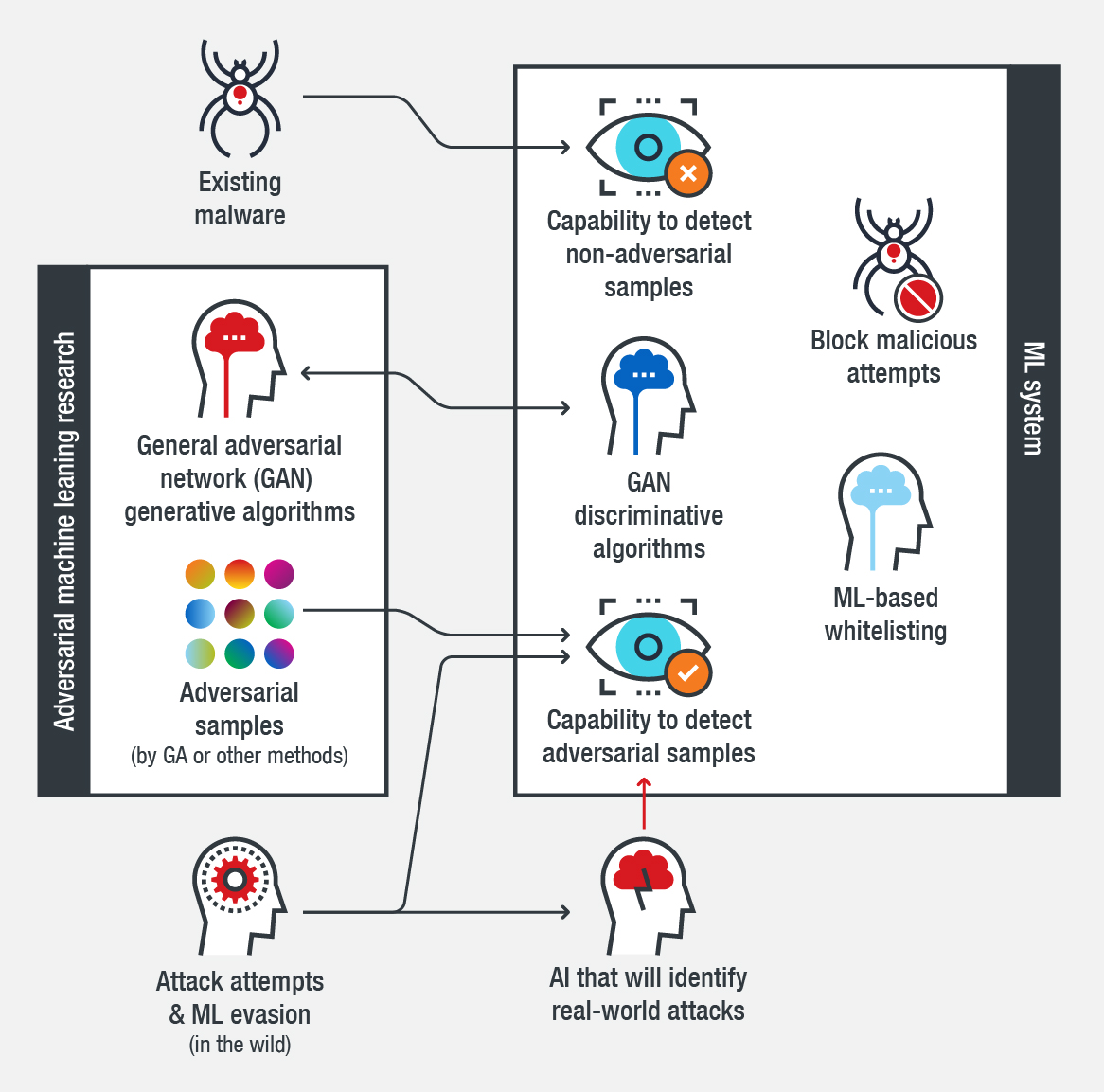
Figure 3. Diagram of an efficient ML system that is capable of detecting and blocking threats and adversarial samples
However, while an enhanced machine learning system certainly improves detection and block rates, it isn’t the be-all and end-all in cybersecurity. Since cybercriminals are also always on the lookout for security gaps, a multilayered defense is still most effective at defending users and enterprises against different kinds of threats. Trend Micro XGen security is equipped with a cross-generational blend of threat defense techniques, including machine learning, web/URL filtering, behavioral analysis, and custom sandboxing, and defends data centers, cloud environments, networks, and endpoints against a full range of threats.