Cyber Threats
Codex Exposed: How Low Is Too Low When We Generate Code?
In a series of blog posts, we explore different aspects of Codex and assess its capabilities with a focus on the security aspects that affect not only regular developers but also malicious users. This is the second part of the series.


Save to Folio
In June 2020, OpenAI released version 3 of its Generative Pre-trained Transformer (GPT-3), a natural language transformer that took the tech world by storm with its uncanny ability to generate text seemingly written by humans. But GPT-3 was also trained on computer code, and recently OpenAI released a specialized version of its engine, named Codex, tailored to help — or perhaps even replace — computer programmers.
In a series of blog posts, we explore different aspects of Codex and assess its capabilities with a focus on the security aspects that affect not only regular developers but also malicious users. This is the second part of the series. (Read the first part here.)
Because it is based on GPT-3, Codex has benefited from being trained with a massive codebase taken from all over the internet, in virtually every programming language available. However, natural languages and programming languages do not share the same properties. And while natural languages can benefit from the generally higher flexibility in understanding concepts of the human mind, programming languages are bound to more rigid constructs and less forgiving principles, dictated by their respective interpreters or compilers.
For high-level programming languages, it is reasonable to expect that the same statistical modeling that works so well in GPT-3 for natural languages would bear similar advantages for its code generation capabilities. Codex, however, lacks some of the essential constructs required for a real “understanding” of programming languages, such as their abstract syntax tree or the computational architecture of the target machine.
So, how far can we push code generation while still being effective?
The imitation game: Codex’s ability to understand low-level code
To assess how deep Codex’s understanding of its generated code is, we tested its understanding of assembly language. We chose this to get the farthest away from natural language and the closest to the machine. We tested Codex by giving it assembly code samples, which we asked it to translate to ordinary language.


When we provided the canonical “Hello, World!” example in x86 assembly and asked Codex to explain it, we got a detailed explanation of what the code does, what the individual registries are for, and even instructions on how to compile it.
This, however, did not seem to be spun from Codex’s genuine interpretation of the code’s actual workings. Rather, it was an excerpt from some assembly code tutorial talking about the “Hello, World!” assembly example.
To double-check that, we slightly altered the code, removing, for example, the “Hello, World!” string, making it a generic (albeit no more working) piece of assembly code.


Again, the “explanation” of the code snippets was derived from some “Hello, World!” assembly tutorial, even though the code was not a formal “Hello, World!” code anymore.
In this example, Codex proved that it is not capable of understanding the code, but rather executes some sophisticated “pattern matching” in order to generate the code that most resembles what was prompted for. Codex does not really understand what the code actually does, because its modeling does not implement any computational paradigm. Instead, it tries to “imitate” the knowledge of programming by looking at whatever in its trained model is the closest to what it is asked for.
To verify it one more time, we changed the code further. Now, we tried code that contained a counter that increments up to 100. Instead of asking for some code explanation, we asked Codex to translate it to another, more obscure programming language.
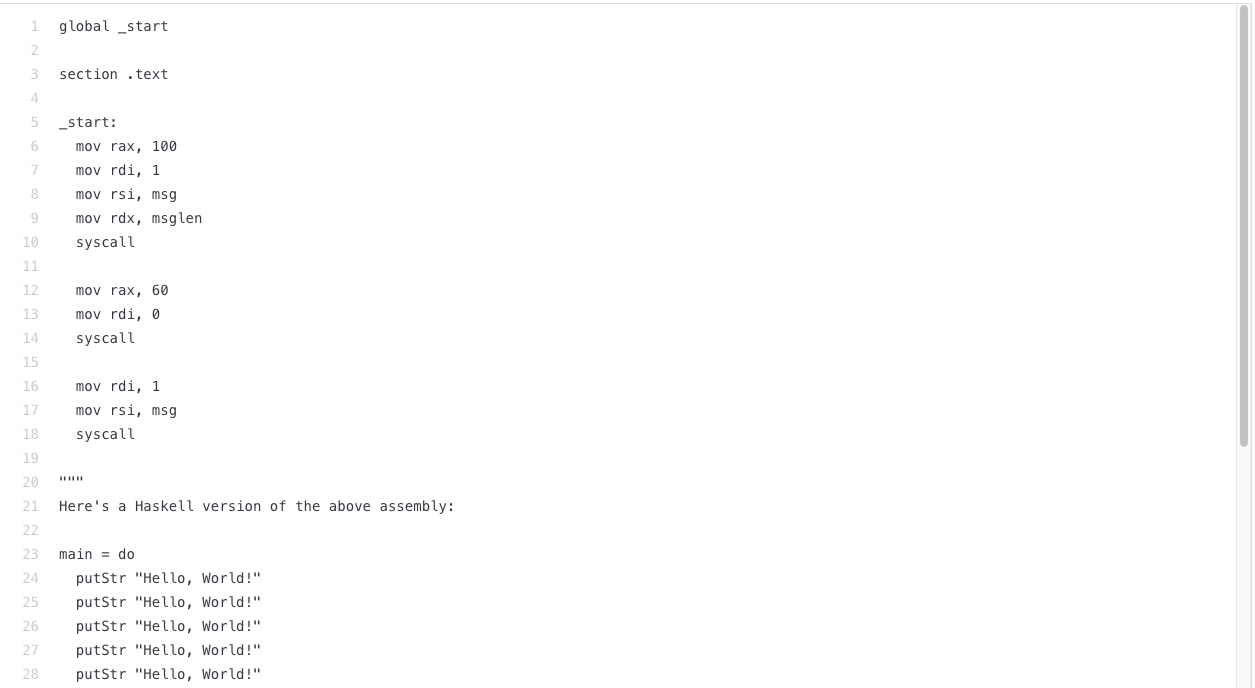


Once again, Codex fell back into the “Hello, World!” case, since in its experience that was the code that most resembled what we wrote.
While the number of lesser-known programming languages that it can master is admirable, we are not yet at a point where intimate computational knowledge can be achieved by Codex.
Binary parsing
However, this does not mean that all hope is lost. The apparent ability of Codex to act as a flexible pattern matcher in all code-related tasks is something that can be exploited even at a low level.
In this example, we show how Codex is actually able to parse and recognize binary formats, provided that they are written in the form of hexadecimal digits, up to the point of being able to locate which library file a binary blob would belong to.
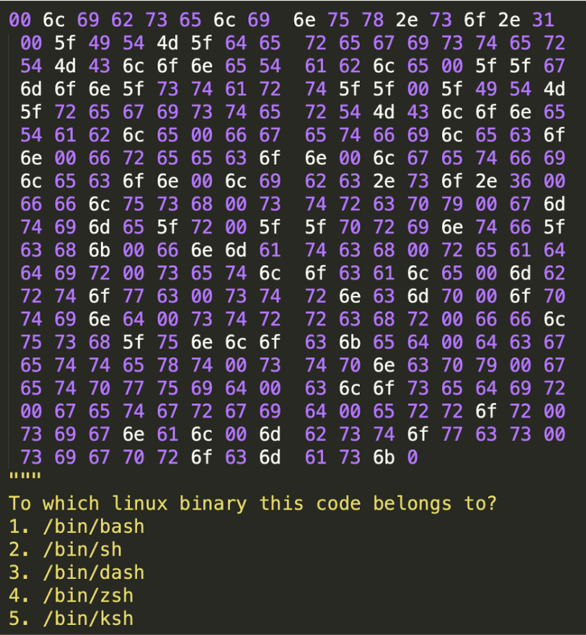
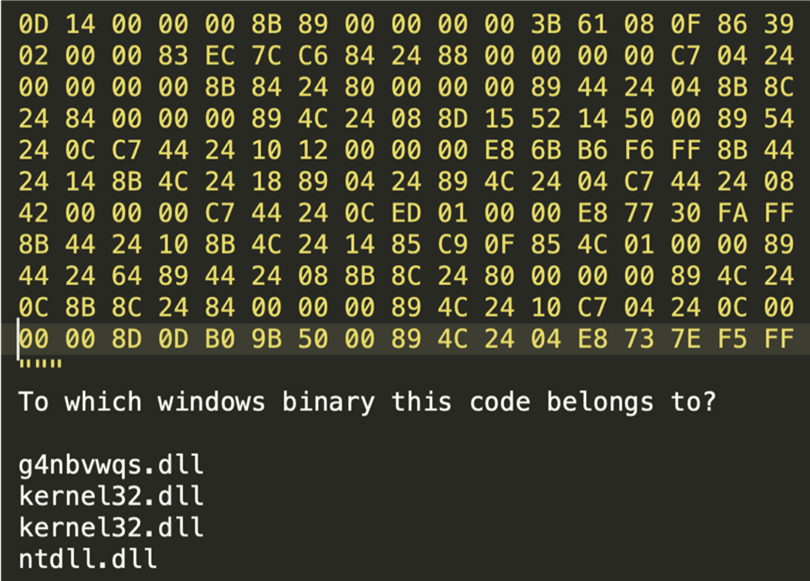
In conclusion, when considering Codex’s actual capabilities to understand and manipulate programming code, it is important to set the correct expectations. While the sophisticated pattern matching system is an excellent aid in writing snippets of common code, scaffolding, and time-consuming boilerplate, with enough flexibility to tailor it to each individual case, we are still far from having the capabilities of, say, a static code analyzer, something that is not too far off from coming in the near future.
Data parsers
Knowledge of the underlying computational architecture is not the only critical piece of information missing from Codex that could significantly limit the scope of its code-generating capabilities. Any piece of computing code aimed at parsing or processing an input with a specific or peculiar structure will be limited by Codex’s lack of knowledge of the data structure.
In this example, we instructed Codex to generate a web crawler that would connect to a specific website, extract a list of items from the webpage, and send it in an email message.
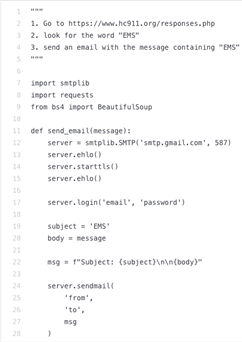

Codex then generated the code faithfully following the detailed instructions provided in the comments: It imported the correct libraries, made a connection to the desired website, chose a subject for the notification email autonomously, and put the correct connection code to an email server in place. However, when we looked at how the correct piece of information was scraped from the page, we saw that Codex chose an arbitrary location to look for in the target page.
This is because not only does it not have an actual understanding of the code but, understandably, it also lacks the knowledge of the target page structure, which is needed to successfully locate the information required.
Conclusion
Codex remains an excellent tool for supporting programming tasks and helping developers especially when it comes to repetitive pieces of code, thanks to the massive codebase it is trained with. But here we have shown how it is still far from having a complete, actionable understanding of the computational flow defined by a piece of programming language, and how it rather behaves like a very smart copy-paste tool. This, however, does not mean that a future where language transformers will be able to autonomously write an original snippet of code is far off.
In the next installment of this series, we will look at how the stochastic nature of Codex influences the consistency of its output and what this means for a user looking to automate tasks involving GPT-3.