Fault Lines in the AI Ecosystem: TrendAI™ State of AI Security Report
The AI ecosystem now poses a significant cybersecurity risk. TrendAI™ Research’s analysis of 330,239 Common Vulnerabilities and Exposures (CVEs) identified 6,086 unique vulnerabilities disclosed from 2018 to 2025 that directly affect AI systems, as broken down in Figure 1.
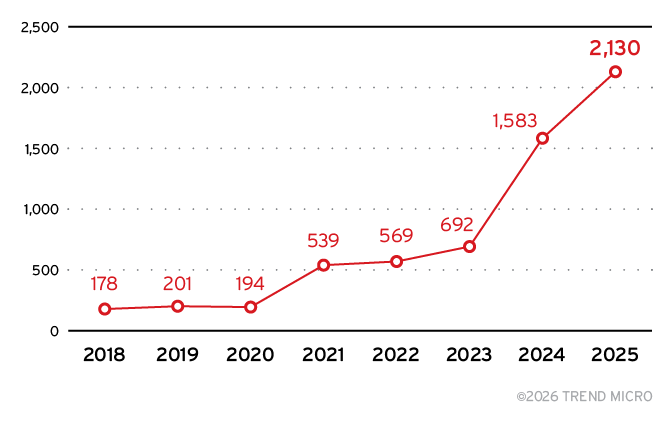
Figure 1. Growth of AI-related vulnerabilities from 2018 to 2025
Notably, 2,130 of these AI-related vulnerabilities were disclosed in 2025 alone, representing a 34.6% year-over-year increase. This growth rate nearly doubles the 17.9% increase in overall CVE disclosures, indicating that AI systems are not only becoming more widely deployed but are also attracting increased attention from attackers.
Key findings:
- Total AI CVEs from 2018 to 2025: 6,086 unique vulnerabilities across eight AI subcategories
- AI CVEs in 2025: 2,130, 34.6% year-over-year growth (versus 17.9% overall CVE growth)
- AI share of all CVEs in 2025: 4.42%, the highest annual rate ever recorded
- High/Critical-severity AI CVEs from 2018 to 2025: 1,593, 26.2% of all AI CVEs (CVSS score: 7.0+)
- High/Critical-severity AI CVEs in 2025: 641 (517 high-severity and 124 critical-severity vulnerabilities)
- Total CVEs in database: 330,239 (48,164 in 2025 alone)
The full picture: AI attack surface data
The 2025 acceleration (+0.55 percentage points) is fundamentally different from that of previous years, as shown in Table 1, which covers vulnerability data from 2018 to 2025. This growth is broad-based across the large language model (LLM) tools, MCP servers, and traditional machine learning (ML)/GPU categories — not driven by a single vendor audit.
Table 1. Trends in AI vulnerability disclosures and growth rates from 2018 to 2025
Subcategories: Not all AI vulnerabilities are equal
AI vulnerabilities cluster into eight distinct subcategories, which are outlined below. The subcategories are not mutually exclusive; a single CVE may be classified into multiple subcategories.
- GPU and AI hardware (3,127 CVEs, 51.4%): Encompasses Nvidia drivers, CUDA libraries, vGPU software, and DGX platforms. Primarily memory corruption issues enabling privilege escalation and container escape.
- ML frameworks (1,624 CVEs, 26.7%): Includes TensorFlow, PyTorch, MLflow. Primary risk is supply chain compromise through malicious model files that execute embedded code.
- LLM tools and applications (1,243 CVEs, 20.4%): Reflects explosive post-ChatGPT growth. Langflow, vLLM, Dify, AnythingLLM deployed without mature security. Code injection, SSRF, and path traversal dominate.
- AI model security (876 CVEs, 14.4%): Covers models serving infrastructure, inference engines, and validation systems. Enables model theft, adversarial manipulation, and unauthorized access.
- AI data pipelines (755 CVEs, 12.4%): Encompasses data ingestion, preprocessing, and feature engineering. Risks data poisoning, training data exfiltration, and ML lifecycle corruption.
- Agentic AI (363 CVEs, 6.0%): Covers vulnerabilities in autonomous AI systems. Flaws in guardrails and execution boundaries create new attack vectors as agents interact with external systems.
- AI supply chain (114 CVEs, 1.9%): Includes package managers, model registries, and dependency management. Enables supply chain attacks through compromised models and malicious packages.
- MCP servers (102 CVEs, 1.7%): An emerging subcategory, accounting for 95 of 102 CVEs discovered in 2025. MCP creates command injection risks by design.
Note: Because the subcategories can overlap, their counts add up to 8,204 CVEs, while the dataset contains 6,086 unique CVEs. All percentages are based on the 6,086-CVE total.
Severity distribution: Where the real risk lies
As shown in Table 2, the severity distribution of AI‑related vulnerabilities shows that nearly half of all scored AI CVEs fall into the high‑ or critical‑severity range, underscoring the significant security risks present across the ecosystem. Of the 6,086 total AI vulnerabilities recorded, 3,257 have assigned CVSS scores, with 11.1% classified as critical (CVSS score: 9.0+) and 37.9% categorized as high-severity (CVSS score: 7.0–8.9). In total, high‑ and critical‑severity CVEs comprise 1,593 cases, representing 48.9% of scored vulnerabilities and 26.2% of all AI CVEs.
Table 2. Severity distribution across AI vulnerabilities from 2018 to 2025
Figure 2 indicates that high‑ and critical‑severity vulnerabilities are concentrated in the newest and fastest‑growing parts of the AI ecosystem. The AI supply chain (46.5%) and LLM ecosystem (45.1%) show the highest severity levels, followed by agentic AI (40.5%) and AI model security (40.3%). MCP servers also exhibit a substantial share (38.2%). In contrast, mature categories such as ML frameworks (32.9%), AI data pipelines (27%), and GPU/AI hardware (18%) show lower severity concentrations. Overall, emerging AI components carry disproportionately higher risk due to rapid adoption, complex integrations, and inconsistent security hardening.
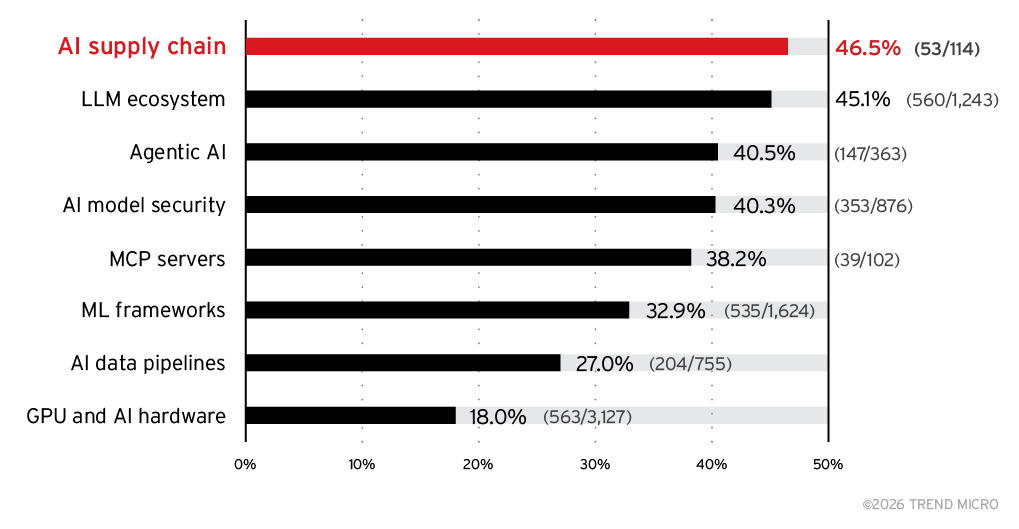
Figure 2. Severity distribution (high/critical concentration) across AI vulnerability subcategories from 2018 to 2025
Accelerating risk: AI attack surface evolution
Based on the data visualized in Figure 3 and presented in Table 3, the AI vulnerability landscape has evolved through three distinct phases:
- Phase 1 (2018-2020): Vulnerabilities in the GPU and hardware subcategory dominated. Volumes were modest, with minimal high- or critical-severity CVEs.
- Phase 2 (2021-2023): Vulnerabilities in the ML frameworks subcategory took precedence, driven by Google’s systematic TensorFlow security audits.
- Phase 3 (2024-2025): Vulnerabilities in the LLM tools and applications subcategory now dominate. 80.4% year-over-year growth in CVEs under the LLM ecosystem subcategory (419 → 756). 2025 shows 641 high/critical-severity CVEs, up from 484 in 2024.
Our critical finding: The shift from infrastructure to application-layer vulnerabilities indicates attackers are following AI adoption into production.
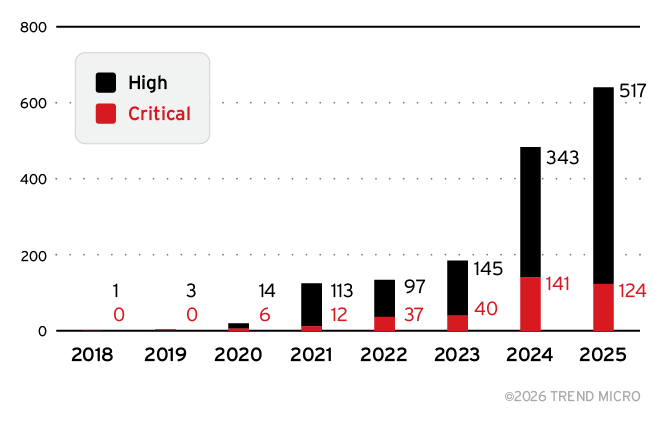
Figure 3. Distribution and growth of high- and critical-severity AI CVEs from 2018 to 2025
Table 3. Distribution and growth of high- and critical-severity AI vulnerabilities from 2018 to 2025
The 2021 spike was artificial, as it was caused by a single vendor audit. But the year-over-year growth of AI vulnerabilities from 2024 to 2025, presented in Figure 4, shows a clear acceleration driven by structural rather than incidental factors. Agentic AI saw the largest jump, rising from 74 to 263 CVEs (+255.4%), followed by the AI supply chain, which doubled from 26 to 52, and the LLM ecosystem, which grew from 419 to 756 (+80.4%). Core categories such as AI model security (+76.1%) and ML frameworks (+52.2%) also expanded significantly, while GPU and AI hardware increased by 21.6%. In contrast, AI data pipelines declined by 11.4%, and MCP servers emerged as a new attack surface with 95 CVEs after having none in 2024. Collectively, these shifts reflect a rapidly widening AI attack surface fueled by growing deployment complexity and the fast adoption of agentic and LLM-based systems.
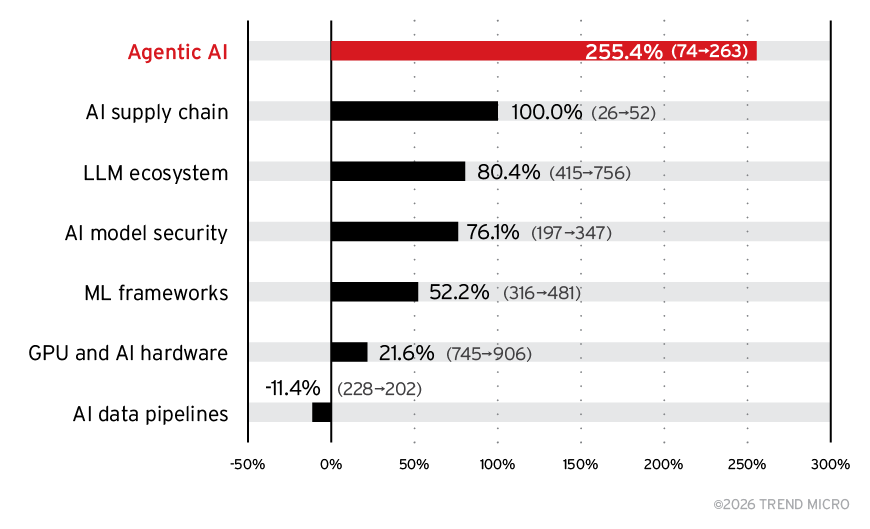
Figure 4. Year-over-year growth of AI vulnerabilities by subcategory from 2024 to 2025
As visualized in Figure 5, the evolution of the AI attack surface from 2020 to 2025 shows rapid growth across key subcategories, with especially sharp increases beginning in 2024. GPU and AI hardware and ML frameworks expanded steadily throughout the period, while the LLM ecosystem surged from 419 to 756 CVEs in 2025 and MCP servers emerged suddenly with 95 new cases in 2025 after having none in prior years. Together, these trends reflect how the attack surface is widening as key AI subcategories grow more complex and widely deployed.
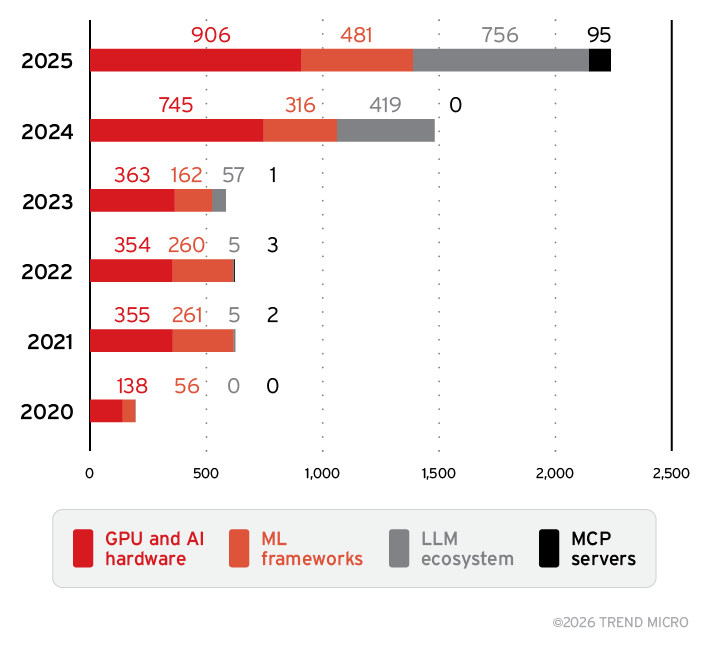
Figure 5. Growth of AI vulnerabilities across key subcategories from 2020 to 2025
Vulnerability types: CWE trends across the AI stack
Examining Common Weakness Enumerations (CWEs) — standardized identifiers used to classify the underlying flaw that makes a software vulnerability exploitable — across AI systems helps reveal not just how many vulnerabilities exist, but what kinds of systemic weaknesses are most common in different parts of the AI stack.
As broken down in Figure 6, the data suggests that each key AI subcategory has a distinct CWE profile shaped by its architecture and operational model:
- GPU and AI hardware: Memory-safe patching required.The GPU and AI hardware subcategory most frequently suffers from memory‑unsafe CWEs like out‑of‑bounds writes, integer overflows, and use‑after‑free conditions, reflecting the performance‑optimized, low‑level code typical of drivers and accelerator libraries.
- ML frameworks: Model provenance verification needed. ML frameworks, by contrast, are dominated by unsafe deserialization and code‑injection flaws because they rely heavily on serialized model files and dynamically executed components.
- LLM ecosystem: Input validation critical. The LLM ecosystem shows a more diverse spread of high‑impact CWEs — including server-side request forgery (SSRF), cross-site scripting (XSS), and command injection — driven by its exposure to user‑generated input, plug-in architectures, and network‑reachable inference endpoints.
- MCP servers: Strict allowlisting required. MCP servers stand out for their extremely high concentration of injection vulnerabilities, with more than 60% of issues tied to command execution flaws due to the inherent risks of agent‑to‑tool invocation.
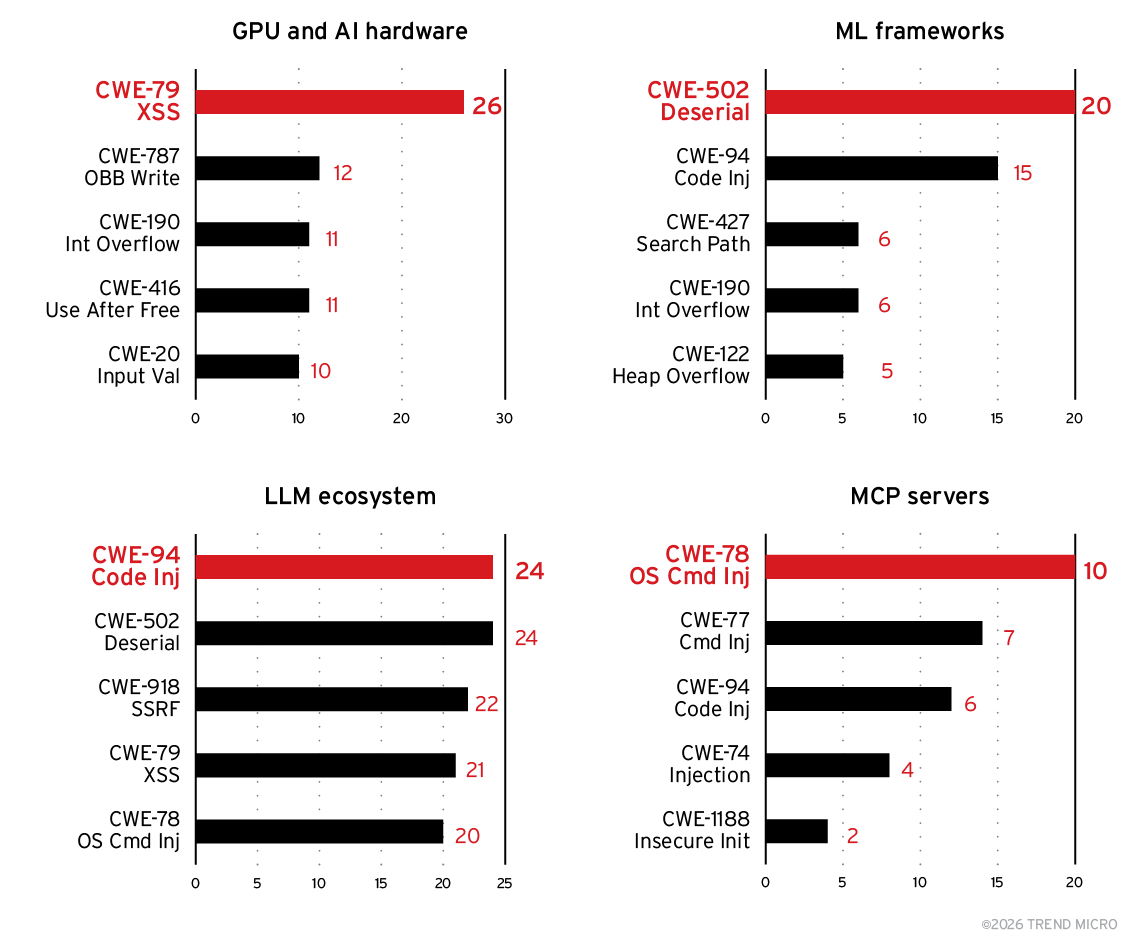
Figure 6. CWE breakdown of AI vulnerabilities across key subcategories from 2018 to 2025 (based on 664 AI CVEs with CWE data)
These category‑specific patterns align with the broader top 10 AI vulnerability types, where XSS, code injection, deserialization of untrusted data, and OS command injection lead the rankings, as shown in Table 4. Together, the CWE data illustrates that as AI systems expand, they inherit — and often amplify — the classic software weaknesses of the components, protocols, and development practices they build upon.
Table 4. Top 10 types of AI vulnerabilities from 2018 to 2025 (based on 664 AI CVEs with CWE data)
TrendAI™ Zero Day Initiative™ (ZDI) bug bounty intelligence
TrendAI™ Zero Day Initiative™ (ZDI) continues to serve as a crucial early‑warning system for identifying real‑world weaknesses in AI systems before they can be exploited at scale. The program’s 35 AI‑related vulnerability submissions provide a focused, high‑confidence dataset that complements the broader CVE corpus by capturing vulnerabilities discovered through active offensive research rather than passive disclosure. This makes TrendAI™ ZDI’s insights particularly valuable in understanding where motivated attackers are concentrating their efforts.
TrendAI™ ZDI findings: High-value targets and critical-severity flaws
The latest TrendAI™ ZDI findings reaffirm a clear pattern: AI infrastructure and supporting components are becoming high‑value targets. Nvidia is the most frequently affected vendor, with 15 cases, accounting for 43% of all AI‑related TrendAI™ ZDI cases, reflecting its dominant role in AI hardware and GPU‑accelerated software stacks. Meanwhile, Tencent is affected in eight cases (23%), highlighting the growing, but still underrepresented, exposure of Asia‑Pacific AI ecosystems in Western vulnerability databases. The diversity of affected vendors suggests a rapidly expanding and globally distributed AI attack surface.
Notably, the severity distribution of TrendAI™ ZDI’s AI discoveries skews dramatically higher than the industry baseline. Of the 35 cases submitted through TrendAI™ ZDI, eight (23%) received a critical rating (CVSS score: 9.0+) — more than double the critical rate seen in the broader AI CVE corpus, where only 11.1% of scored vulnerabilities are classified as critical. This divergence underscores a crucial point: Bugs found via coordinated offensive research are more likely to be immediately exploitable and impactful, and therefore represent the cutting edge of adversarial interest.
Pwn2Own Berlin 2025: A turning point for AI vulnerability research
A major milestone in 2025 further accelerated scrutiny of AI infrastructure: For the first time, Pwn2Own Berlin included a dedicated AI infrastructure category, targeting the Nvidia Triton Inference Server, among others. This shift officially brought AI systems into the same competitive exploitation spotlight historically reserved for browsers, hypervisors, automotive systems, and industrial controllers.
By including AI infrastructure as a formal competition category, Pwn2Own has effectively signaled to the security research community that AI services and deployment tooling are now strategic targets worthy of sustained analysis. As history has shown across every newly added Pwn2Own category, once offensive researchers focus on a product class, a surge in vulnerability volume typically ensues. Organizations should therefore expect a material increase in findings affecting inference servers, model‑hosting platforms, and AI‑native development environments throughout 2026.
Key vulnerability insights
The evolving AI ecosystem is no longer defined by isolated weaknesses but by a rapidly expanding and increasingly uneven vulnerability landscape. Our analysis reveals that risks are concentrating in specific technologies, escalating in severity, and accelerating year over year as organizations rush to deploy AI systems at scale. From hardware‑level flaws and supply chain exposures to the emergence of entirely new attack surfaces like MCP servers, the data shows that AI‑related vulnerabilities are not only growing in volume but also clustering in ways that create systemic, cascading risk across the stack. The following key insights highlight where defenders must focus their attention as AI adoption deepens across industries.
- The GPU and AI hardware subcategory dominates the attack surface. GPU drivers, CUDA libraries, and AI accelerators account for 51.4% of all AI CVEs (3,127 of 6,086) — the largest single category. ML frameworks follow at 26.7%, with LLM tools and applications at 20.4%.
- Cross-site scripting leads, with code injection close behind. CWE-79 (XSS) leads at 9.3% of AI CVEs with CWE data, followed by CWE-94 (code injection) at 6.8% and CWE-502 (deserialization) at 5.7%. Pickle files, model weights, and serialized tensors are prime remote code execution (RCE) vectors.
- The AI supply chain category has the highest severity concentration. AI supply chain vulnerabilities show 46.5% high/critical severity, the highest of any AI category. Pre-trained models from untrusted sources pose systemic risk.
- Severe vulnerabilities are accelerating. High/critical-severity AI CVEs have grown from 20 in 2020 to 641 in 2025, reflecting both improved discovery and genuinely more dangerous vulnerabilities in production AI systems.
- MCP is the new frontier. With 95 CVEs in 2025 alone (near zero before 2025), MCP servers represent an entirely new attack surface. Injection attacks (CWE-77, CWE-78, CWE-94) account for over 60% of MCP vulnerabilities.
- The acceleration is real. 2025’s 4.42% share is the highest annual AI vulnerability rate ever recorded. If this trajectory continues, 2026 could see AI vulnerabilities exceed 5% of all CVEs annually.
- 26.2% of scored AI CVEs are severe. Of the 3,257 scored AI vulnerabilities, 1,593 have high or critical CVSS scores, with the AI supply chain category showing the highest concentration at 46.5%.
- 4.42% of all CVEs are now AI-related. This is the highest annual share ever recorded, up from 3.87% in 2024, a 34.6% year-over-year increase (1,583 to 2,130). Total AI CVEs now exceed 6,000.
- Category concentration creates systemic risk. Three categories — GPU and AI hardware (3,127), ML frameworks (1,624), and LLM ecosystem (1,243) — account for the majority of all AI CVEs.
- Chinese AI platforms may be underrepresented in Western vulnerability databases. TrendAI™ ZDI data reveals Tencent accounts for 23% of AI bug bounty submissions (eight of 35 cases). HunyuanVideo and HunyuanDiT have CVSS 9.8 deserialization RCE vulnerabilities.
- Pwn2Own Berlin 2025 signals that AI has gone mainstream. For the first time, Pwn2Own included an AI infrastructure category, with the Nvidia Triton Inference Server as one of the targets.
AI vulnerability predictions: 2026 forecast
The acceleration of AI‑related vulnerabilities seen in 2025 is set to intensify even further in 2026. Our forward‑looking analysis suggests that the industry should brace for another year of substantial growth, projecting between 2,800 and 3,600 AI CVEs — a dramatic 31%–69% increase from 2,130 in 2025, driven by rapid adoption of agentic systems, expanding LLM ecosystems, and continued exposure of critical AI infrastructure. The forecast, as shown in Figure 7, highlights not only rising volume but also a widening distribution of risk across the stack, with emerging categories such as MCP servers and agentic AI expected to see the fastest year‑over‑year growth. This outlook underscores a pivotal reality: As AI capabilities mature, so too does the complexity and scale of the threats targeting them.
- GPU and AI hardware: 1,000–1,300 CVEs (+10%–43%)
- LLM ecosystem: 900–1,300 CVEs (+19%–72%)
- ML frameworks: 550–750 CVEs (+14%–56%)
- AI model security: 400–600 CVEs (+15%–73%)
- Agentic AI: 350–550 CVEs (+33%–109%)
- MCP servers: 180–280 CVEs (+89%–195%)
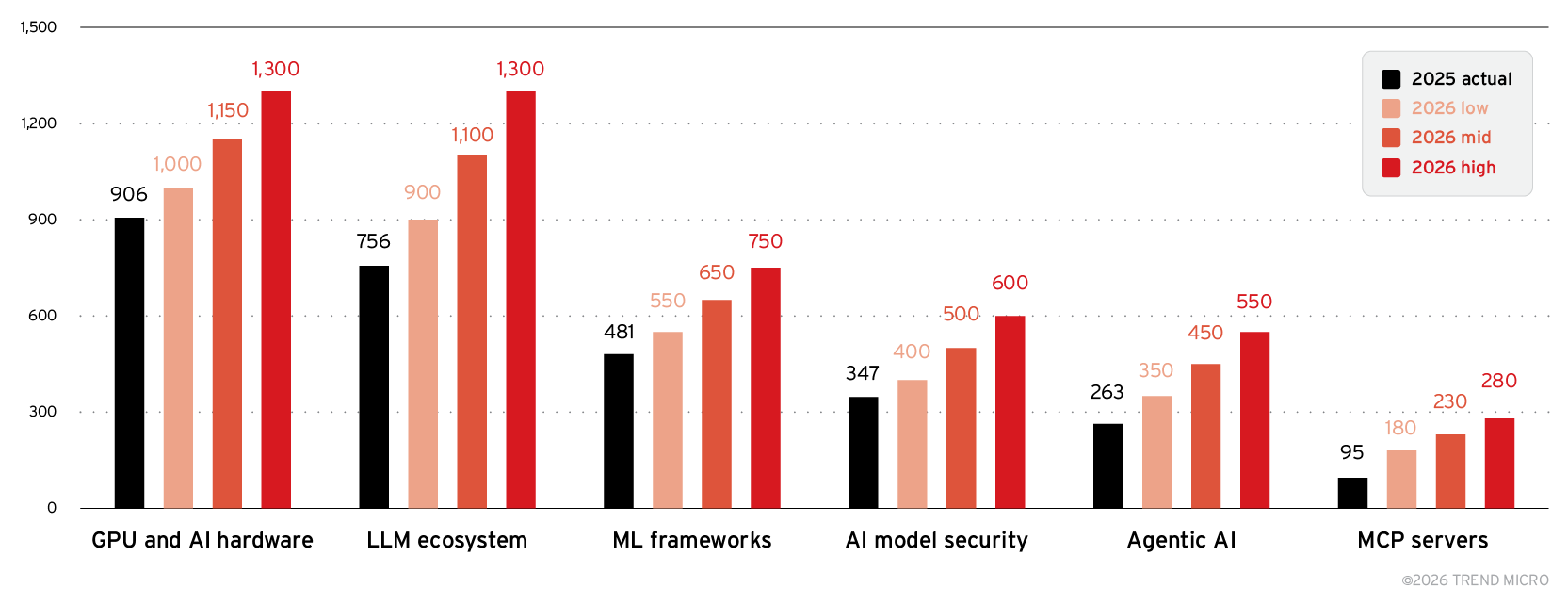
Figure 7. TrendAI™ Research’s 2026 AI vulnerability forecast by subcategory
Methodology and data sources
To ensure accuracy, consistency, and reproducibility across all findings in this report, TrendAI™ Research employed a rigorous methodology grounded in comprehensive vulnerability intelligence and transparent data processing. The analysis draws from a large‑scale CVE dataset, multi‑stage AI classification workflows, and strict scoring and verification standards, enabling a clear and reliable view of how AI‑related vulnerabilities have evolved over time. The following outlines the data sources, classification processes, scoring criteria, and validation steps that underpin the results presented in this report.
- Data source: AESIR/MIMIR Vulnerability Intelligence Platform. TimescaleDB: 330,239 CVEs.
- AI classification: Two-stage pipeline: keyword pre-filter + LLM verification with confidence scoring across eight sub-verticals.
- Severity: CVSS v3 scores. 3,257 of 6,086 scored (53.5%). High: 7.0–8.9, critical: 9.0+.
- Category overlap: CVEs tagged to multiple subcategories. Sum = 8,204 with overlap vs. 6,086 unique.
- CWE data: 664 AI CVEs have CWE classifications. Rankings based on this subset.
- Temporal coverage: 2018–2025 (eight years). 2026 partial-year data excluded from primary analysis.
- Verification: All figures queried directly from TimescaleDB on Jan. 28, 2026. No estimated values.
As the AI ecosystem rapidly expands, attackers are finding new avenues for exploitation. In this section, we examine how threat actors are adapting their methods, revealing the shifting tactics and exposures that are now at the forefront of AI security challenges.
Exposed AI infrastructure
Since the end of 2024, we’ve been tracking exposed AI infrastructure. While our full year-end report for 2025 will be published later this year, preliminary results already reveal significant findings worth highlighting. In this subsection, we focus on two of the most commonly exposed components: Ollama inference servers and Chroma vector store deployments.
Ollama
Ollama is a very popular inference framework for hosting local AI models. Many popular open weights-and-biases models are available through Ollama, and it sports a convenient command line, a web interface, and an HTTP API. Default installations are only exposed to the local host, but with the right configuration, it can be accessed as a web service over the network. Ollama has no built-in authentication, which means that in a production setup, it should be hidden behind some other web server that does the authentication and the Ollama server itself should not be exposed. Unfortunately, many developers overlook this requirement.
With the help of Shodan, we scanned over 313,000 servers exposed on the internet from the beginning of September to mid-December 2025. Nearly 230,000 of these were hosting Ollama at some point during that four-month period. Of those, over 113,000 servers responded to basic status queries with expected results, allowing us to confidently classify them as confirmed Ollama instances.
As shown in Figure 8, the US had by far the biggest install base. However, this may be because users in other countries use US-based cloud providers and often hosting in the US is the cheapest option. Most of the latency is in the model inference itself, so the network latency is negligible. The US may also be the location where enough GPUs are available.
Following the US are Germany, India, Australia, Japan, and China. If we mentally correct for an over-emphasis of hosting in the US, we can see that interest in using privately hosted model servers is very strong across the board.
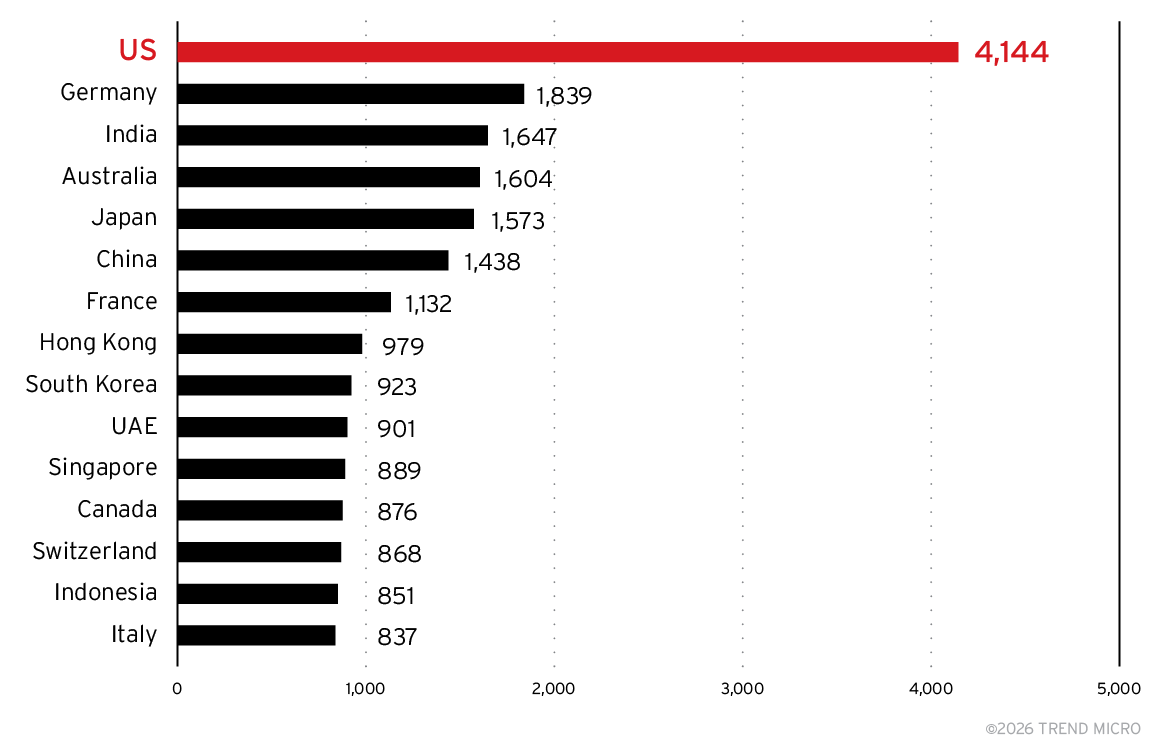
Figure 8. Top 15 countries or regions by Ollama server count
China is an interesting case as we initially had seen a much larger share of Chinese servers, but the numbers suddenly dropped off early in 2025. We don’t have a good explanation for this other than perhaps they became unobservable from Shodan or migrated to a different server type. Or perhaps they just stopped being exposed directly.
Figure 9 shows that the average age of exposed Ollama servers closely mirrors the age of the versions they are running. This indicates that most of these servers are deployed once and never updated, leaving them persistently vulnerable to any exploitation targeting outdated releases.
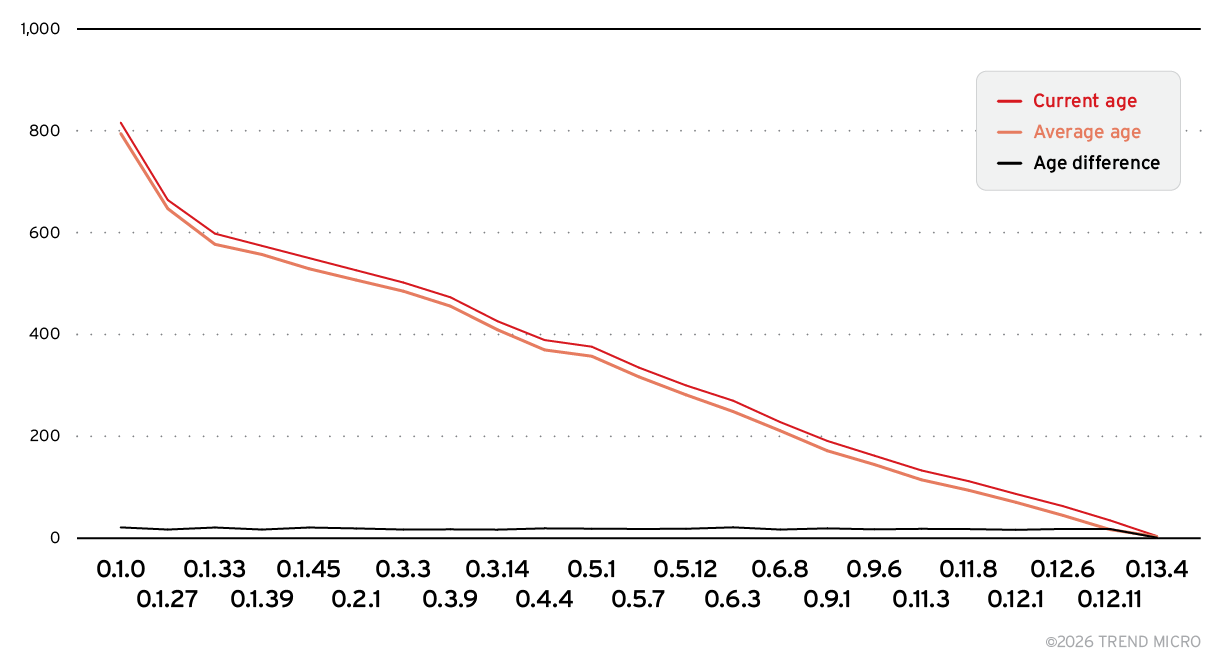
Figure 9. Age comparison of servers across Ollama versions
Beyond the risk of direct exploitation, these exposed servers can be freely used by anyone on the internet. This not only shifts computing costs onto the unwitting server owner but also provides criminals with free access to LLM capabilities without investing in their own infrastructure. In many cases, the servers also permit model manipulation, allowing an attacker to replace hosted models with malicious variants or alter the system prompt itself.
As shown in Figure 10, older Ollama versions remain overwhelmingly dominant, with recent versions rarely deployed in the wild. The current version, 0.13, doesn’t even feature in the top 15. While the APIs of many servers change over time, Ollama has been fairly constant, so updating should be relatively painless for most developers. With each release, more models become available. The likely rationale for not updating is that the developer wanted a particular model and once that is installed, they see no reason to update. The sensitivity for the security of their systems is just not there.
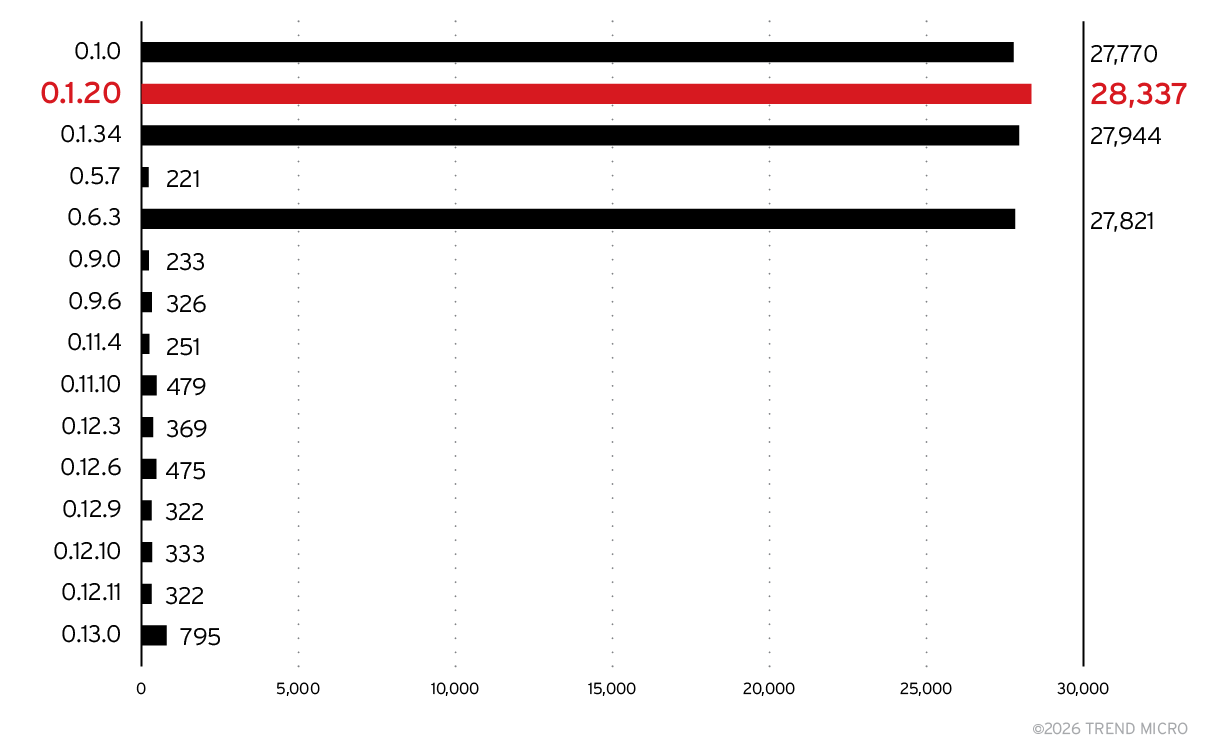
Figure 10. Top 15 product versions for Ollama servers
Chroma
Chroma is a popular vector database for text, mainly used in retrieval augmented generation (RAG) applications. It stores texts (or text chunks), and it stores text embeddings as vectors, allowing an application to search and retrieve texts based on the embedding vector of the query. It then returns the texts for processing, usually by an LLM.
In the dataset we collected from Shodan, covering the period from the beginning of September to mid-December 2025, we identified 2,500 Chroma servers exposed to the internet. As shown in Figure 11, the US accounts for the largest share. The same caveat about US‑based hosting applies here: Many deployments in other regions may still appear as US‑hosted due to cloud infrastructure choices. Beyond the US, there are notable concentrations in Germany and China, with counts tapering off after these countries.
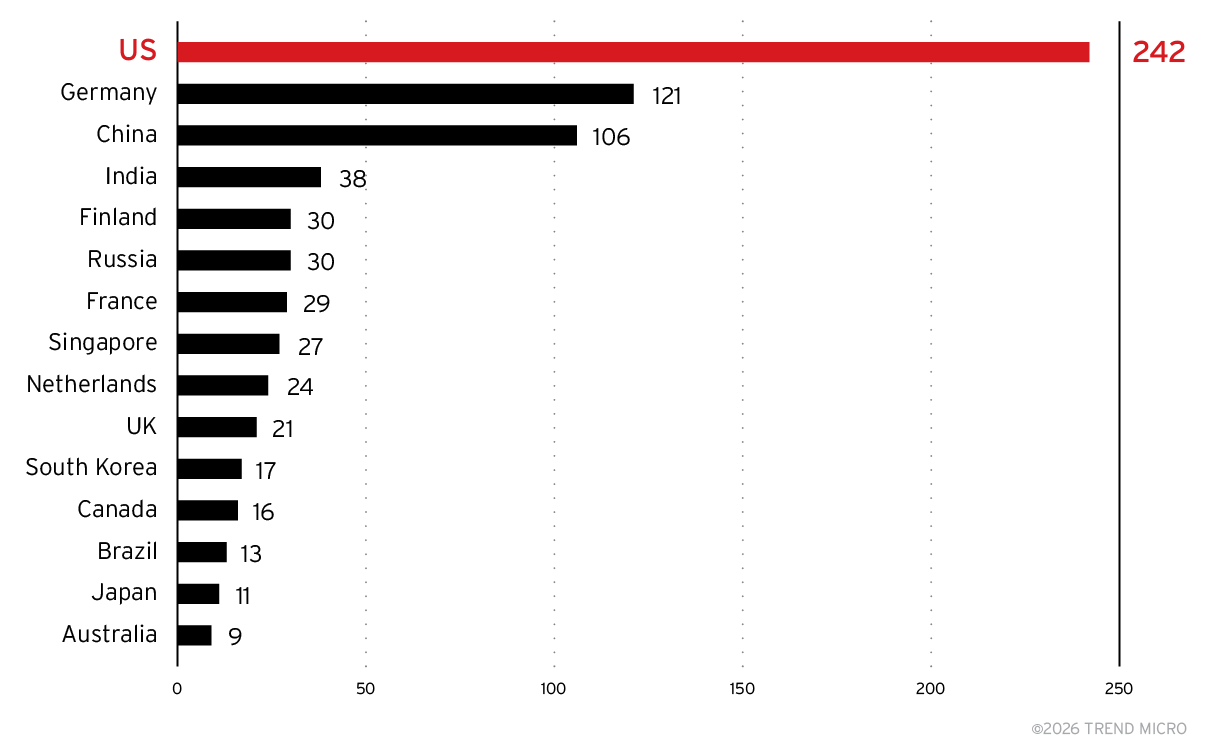
Figure 11. Top 15 countries by Chroma server count
Here, too, the software isn’t being updated frequently enough. As shown in Figure 12, the average age of exposed Chroma servers closely mirrors the age of the versions they are running. This indicates that, much like the Ollama deployments, most Chroma servers are installed once and never updated, leaving them perpetually vulnerable to issues already resolved in newer releases.
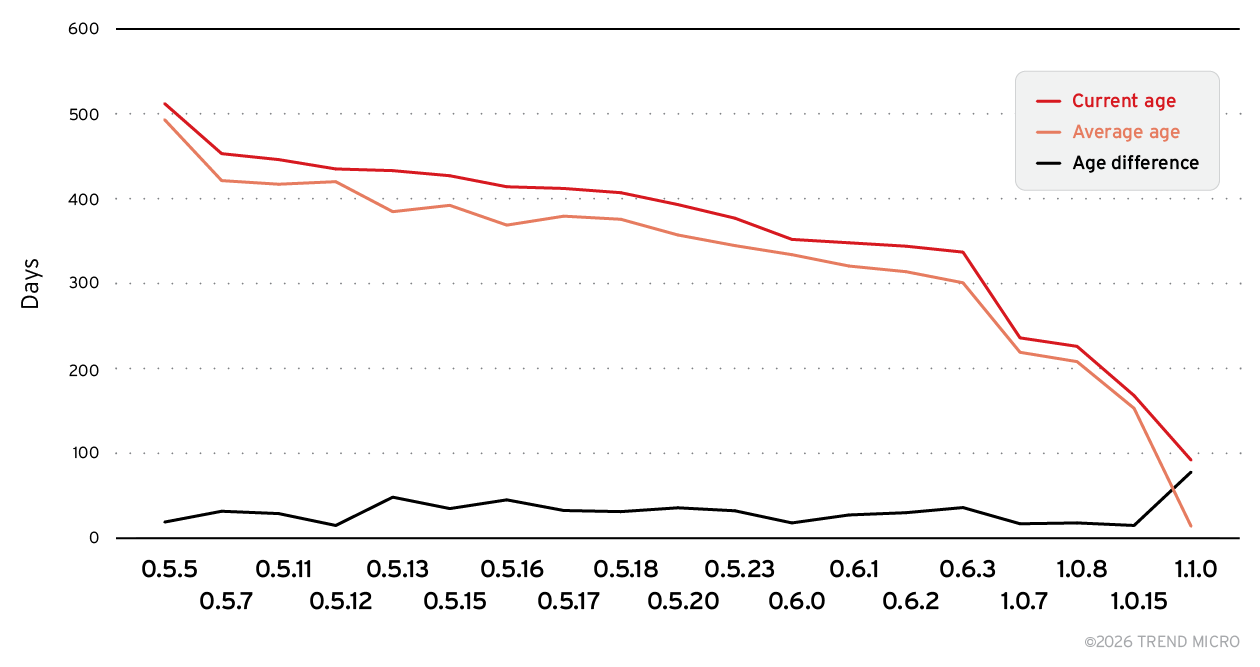
Figure 12. Age comparison of servers across Chroma versions
Given this, we analyzed which versions are most commonly deployed, as shown in Figure 13. A fairly old version of Chroma dominates the pack: Version 0.6.3 was released on Jan. 14, 2025. The current release, version 1.3.6 (released on Dec. 12, 2025), doesn’t show up in the data yet. Chroma did undergo an API change in 2025, so some developers might have avoided upgrading to prevent breaking existing applications. However, postponing migration only defers the inevitable challenges and leaves systems running increasingly outdated, and potentially vulnerable, software.
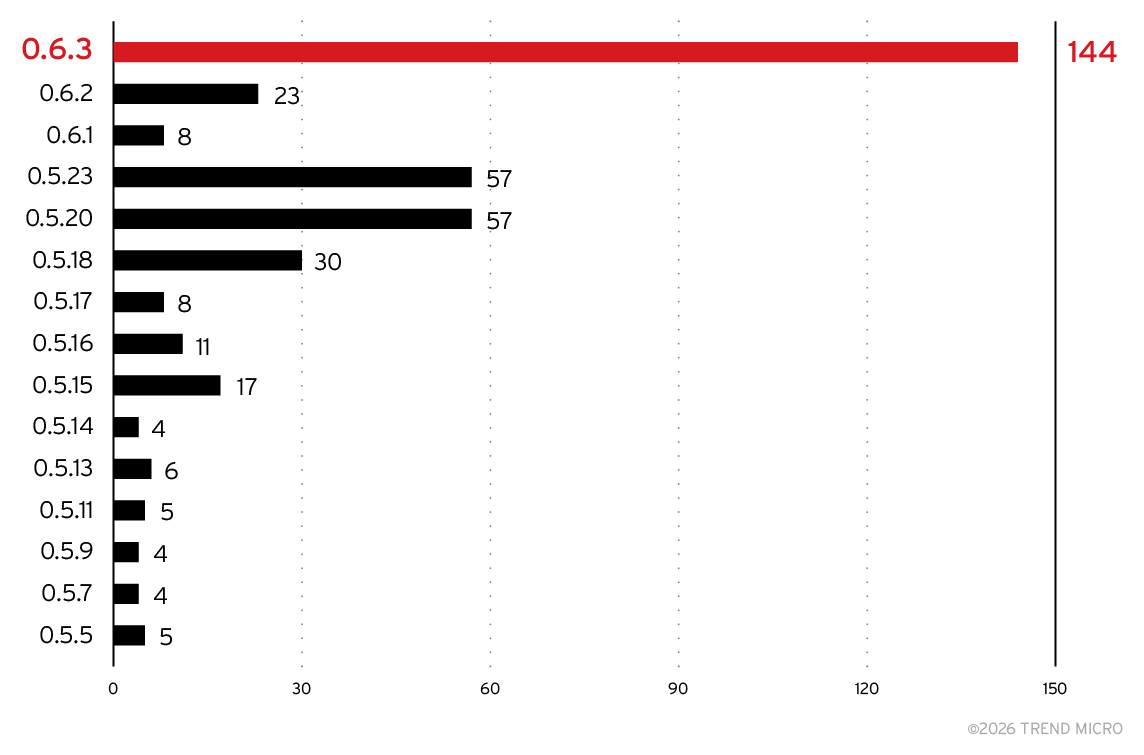
Figure 13. Top 15 product versions for Chroma servers
The consequence of exposing Chroma servers is that data is being exposed. To analyze the data in these servers, we took a sampling of servers and the documents on those servers. To do this ethically, we used a temporary computer system running a local LLM: in this case, IBM Research’s Granite4:small-h model, which has fast response times and good fidelity. Running the model locally on an isolated machine means that the data would not be leaked to any LLM service provider.
We loaded each document into memory, analyzed it locally, and then immediately discarded it, retaining only the resulting classifications. Given this setup, and because no human reviewed the results, we can’t be fully certain how well the LLM captured the nature of the documents. The following findings should therefore be considered with a large pinch of salt.
The LLM was instructed to abide by the following categories and their definitions. There were other categories as well, but not enough hits were registered to make the top 10, as shown in Figure 14.
- analytical-data – Aggregated and structured forms of data used for reporting and analysis, such as KPIs, trends, and behavior patterns
- cybersecurity-threats-malware – Information related to cybersecurity threats, vulnerabilities, attack vectors, and malicious software, including how to create, deploy, or use malware
- human-resource-data – Data related to a person and HR, including personal information, payroll, benefits, and performance reviews
- location-data – Information related to geographic locations, addresses, and spatial data
- marketing-data – Data related to marketing activities, campaigns, population segmentation, advertising, and promotional efforts
- operational-project-data – Data related to day-to-day operations and specific projects, including transactional data, personal records, inventory levels, sales orders, timelines, milestones, budgets, and deliverables
- personally-identifiable-information – Any data that could identify a specific person or compromise their privacy
- pricing-financial-data – Financial and pricing-related information, including account details, price lists, discount structures, and competitive pricing analysis
- regulatory-privacy-data – Data related to compliance with laws and regulations, including privacy policies and data protection measures
- strategic-data – Data used for long-term planning and strategy, including market research, competitive intelligence, and future projections
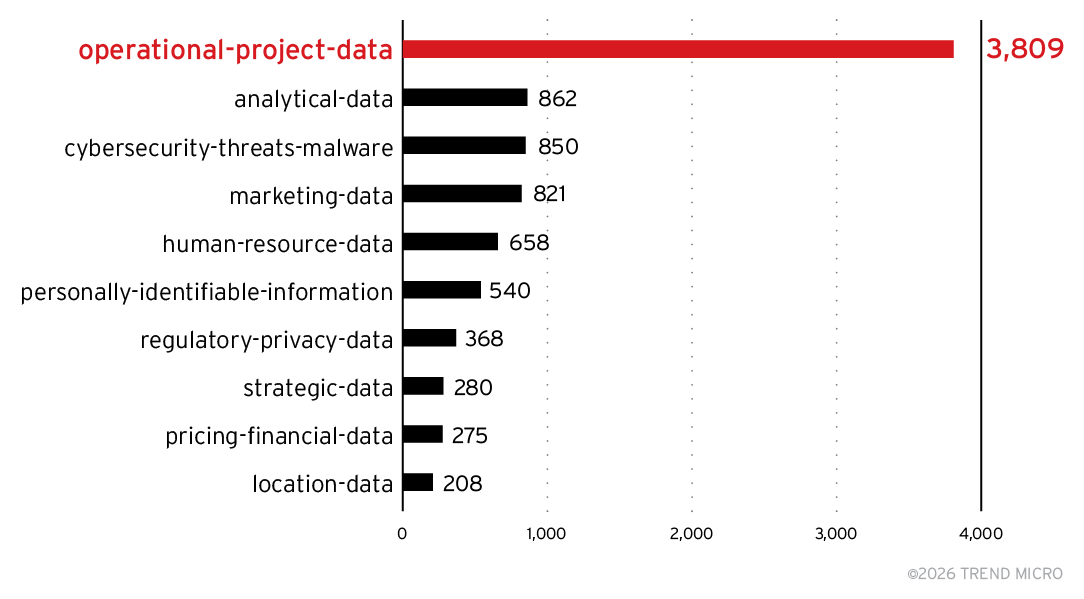
Figure 14. Top 10 Chroma categories
The categories were designed to overlap and we allowed for multiple categories per document. As expected, the LLM hallucinated additional categories that later had to be manually mapped to the existing ones, a task made more difficult by the fact that we had no original text to work with. Should we repeat this experiment in the future, we will probably take a more ontological approach to classification.
One category that we asked for that didn’t make the top 10 list was prompt-injection-attacks, which had a few dozen hits. If the LLM classified these correctly, this should give us pause. It could mean that these open Chroma instances were already being abused, or there was perhaps a malicious application.
It is worrying that some personally identifiable information (PII) and corporate data have found itself published on the internet this way. Without a manual analysis, it is hard to determine how sensitive the data is, but we didn’t keep any trace of the data. However, less scrupulous actors might find a treasure trove of data on openly accessible servers.
Beyond Ollama and Chroma
TrendAI™ Research will publish a full analysis, including other exposed servers, in an upcoming report. As a preview, Figure 15 highlights the most frequently observed server types.
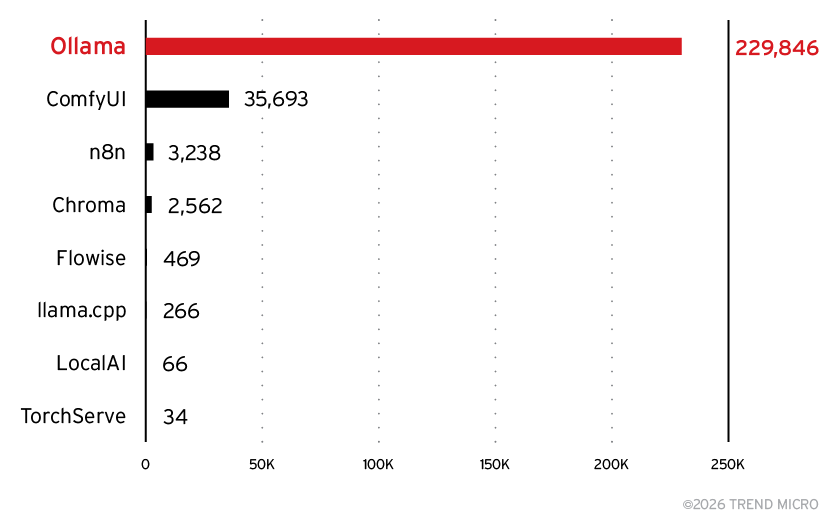
Figure 15. Top observed server types
In addition to the expected Ollama and Chroma installations, we identified a notable new entrant: ComfyUI, which appeared in more than 35,000 exposed instances. ComfyUI is typically used as a front‑end for inference engines such as Stable Diffusion, but Shodan data suggests that a particular cloud provider may be deploying this interface automatically alongside every inference server it provisions—greatly inflating its presence in our dataset.
We also observed n8n and Flowise appearing in our statistics for the first time. These platforms will be examined in more detail in our full report.
The problem of exposed AI infrastructure is not going away anytime soon. Instead, it is becoming more diverse and increasingly complex. As organizations rush to integrate AI into every layer of their operations, they must ensure that adoption does not outpace fundamental security readiness.
MCP vulnerabilities in the wild
The rapid expansion of MCP deployments has introduced significant security challenges, as organizations seek to integrate agentic AI capabilities into their operations without sufficient hardening or oversight. Our research highlights an increase in exposed MCP servers, with many running outdated protocols and lacking essential security controls. This trend reveals a gap between the pace of technological adoption and the implementation of basic security practices, exposing critical data and systems to exploitation. As organizations increasingly rely on MCP solutions, the prevalence of misconfigurations, unsecure code, and inadequate access management calls for stronger security measures in MCP deployments.
Explosive growth, inadequate security
The MCP landscape has undergone dramatic expansion over the second half of 2025, but this rapid adoption has come at a severe security cost. Our latest research reveals 1,467 exposed MCP servers, a nearly threefold increase from our initial findings, indicating that organizations are racing to deploy AI agent capabilities without implementing fundamental security controls. This explosive growth reflects the industry’s enthusiasm for agentic AI systems, but the security posture of these deployments suggests that many organizations are prioritizing speed-to-deployment over basic hardening practices.
Most alarmingly, 1,227 of these exposed servers are running the long-deprecated Server-Sent Events (SSE) transport protocol. SSE was explicitly deprecated in favor of more secure transport mechanisms, yet over 83% of discovered servers continue using this legacy implementation. This widespread failure to adopt modern MCP standards highlights a critical gap between protocol evolution and real-world deployment practices. Organizations appear to be copying outdated tutorials, reference implementations, or proof-of-concept (PoC) code directly into production environments without validating that they’re using current, supported versions.
Critical exposure via database access and memory exfiltration
The most significant danger posed by exposed MCP servers comes from tools with direct data access. TrendAI™ Research identified the “execute_sql” tool available on 70 publicly accessible hosts. This tool, designed to allow AI agents to query databases, represents one of the most prevalent, and riskiest, MCP exposures in the wild. When left without proper authentication, role-based access management, and network segmentation, these servers effectively function as open backdoors to sensitive organizational data. Anyone can execute arbitrary SQL queries and extract customer records, intellectual property, financial data, or authentication credentials, all without exploiting traditional vulnerabilities or bypassing conventional security controls.
The second most prevalent MCP server exposure type was found on 39 hosts running “Graphiti Agent Memory” implementations, a class of agentic MCP servers designed to maintain persistent memory across AI interactions. While this capability enables more sophisticated agent behaviors, it also creates a high-value target for data exfiltration. These memory stores often contain conversation histories, business context, user preferences, and operational details that accumulate over time. For attackers, compromising a Graphiti-enabled MCP server provides access not only to current data but also to a historical record of AI agent activities, potentially revealing strategic planning, internal communications, and sensitive decision-making processes that were never intended for external exposure.
Lastly, we found multiple MCP servers posing a significant risk to personally identifiable data, particularly by allowing access to sensitive medical records via the “progress_note” tool. This scenario represents a blatant violation of privacy regulations, as unauthorized individuals can easily retrieve and exploit personal health information. The lack of proper security measures not only undermines the confidentiality and integrity of the data but also highlights the severe real-world consequences that can arise from unsecure MCP deployments. This kind of exposure could lead to identity theft, unauthorized disclosure of medical conditions, and other forms of data misuse, thereby compromising the trust and safety of the affected individuals.
Open-source MCP repositories
Another emerging concern for long-term ecosystem security is the role of AI-generated code in MCP server developments. Along with a worldwide increase in AI code-generation events since January 2025, TrendAI™ Research found 8% AI-acknowledged contributor activity in MCP server repositories, attributable to AI bots.
When we applied AI code-detection techniques to the actual source code rather than metadata profiles, we estimated that at least 20% of open-source MCP server repositories contained AI-generated code.
Our data showed that 4% to 20% of the 19,000 analyzed open-source MCP repositories contained exploitable vulnerabilities, and further manual analysis revealed that 42.6% of classified vulnerabilities exhibited clear signs of AI-generated code.
Our subsequent research also identified a high prevalence of SQL injection, RCE, path traversal, and SSRF vulnerabilities, as shown in Figure 16. These findings highlight the need for stronger MCP server hardening and point to systemic weaknesses in existing protection mechanisms.

Figure 16. Vulnerability types among MCP servers
The observed vulnerability patterns suggest that AI coding assistants, when used without adequate human oversight and security review, are actively introducing exploitable vulnerabilities into MCP repositories.
Complex applications require expert domain knowledge and should not be completely delegated to general-purpose LLMs. AI coding assistants excel at generating syntactically correct code and implementing common patterns, but they frequently fail to understand security contexts, threat models, and the subtle interactions between components that create vulnerabilities.
When developers rely on AI to generate entire MCP server implementations without a deep understanding of the security model, transport protocols, and data exposure risks, the result is predictable: servers that function correctly in testing but create massive security gaps in production.
Hidden costs and security risks in LLM deployments
Tokenizers, the components that convert text into tokens for LLMs, represent a critical but often overlooked attack surface in AI deployments. When tokenizer behavior changes, whether through accidental configuration drift or deliberate adversarial manipulation, organizations face a cascade of financial, operational, and security consequences that remain invisible until costs spike or systems fail. Our research demonstrates that small, controlled modifications to tokenizer files can double or triple token counts without touching model weights, leading to inflated cloud bills, degraded performance, CPU overload, and exploitable security vulnerabilities in agent-based systems.
The “tokenization drift” phenomenon operates as a stealth supply chain risk. Malicious actors can upload models to public repositories with modified tokenizer artifacts that appear functional but fragment text into exponentially more tokens. Teams downloading these models see no immediate red flags — the model still generates coherent responses — but silently suffer cost increases of two to three times, 8% to 40% latency degradation, and context window shrinkage that can cut usable prompt space in half. More critically, altered tokenizer normalization rules can manipulate model outputs to trigger unintended actions in downstream agent systems, turning benign user inputs like “yes” into executable commands that routers interpret as valid tool invocations.
Economic and performance impact
TrendAI™ Research’s experimental analysis across five models (GPT-2, DistilGPT-2, Facebook OPT-125M, EleutherAI GPT-Neo-125M, and TinyGPT-2) revealed systematic degradation from tokenizer modifications. Our research team altered only the tokenizer’s merge strategy, leaving model weights completely untouched, and measured the cascading effects across cost, performance, and fairness dimensions.
Token inflation reached alarming levels. Baseline tokenizers processed text at approximately 0.321 tokens per character, while modified versions jumped to 0.641 to 0.731 tokens per character, representing 99.7% to 127.7% increases. This means identical text suddenly requires twice the compute, costs twice as much in API billing, and consumes twice the context window space. For a model with a 4,000-token limit, usable English text dropped from approximately 12,500 characters to approximately 5,900 characters, forcing critical safety instructions, conversation history, and system prompts to be truncated or discarded entirely.
Performance degradation compounded the problem. P95 tokenization latency increased by 8% to 40% depending on model architecture, with the smallest model (TinyGPT-2) suffering the worst impact at 40.3%. CPU usage per request rose proportionally as both tokenization and model inference scaled with inflated token counts. In production environments, this translates to autoscaling churn, increased pod counts, timeout cascades, and degraded quality-of-service for multi-tenant workloads, all without any visible change to model behavior.
Language-based discrimination emerged as an unexpected equity issue. Testing across Chinese, English, and Hindi revealed that non-English languages suffered disproportionate token inflation. Chinese text increased from 0.460 to 0.984 tokens per character, a delta of +0.524, while Hindi jumped from 0.875 to 1.531 tokens per character, a delta of +0.656 — both exceeding English’s +0.360 delta (0.321 to 0.681 tokens per character). This creates fundamentally unfair service economics where users in different regions pay vastly different amounts and experience different performance levels for equivalent functionality, potentially violating fairness regulations in jurisdictions with digital equity requirements.
Cost projections illustrated the business impact. At standard industry pricing of US$8 per million tokens, processing 1,000 requests averaging 1,500 characters each would cost US$3.85 with a baseline tokenizer but US$8.18 with the modified version, a 112% cost increase with no additional value delivered. For organizations processing millions of requests monthly, tokenizer drift can add hundreds of thousands of US dollars in unbudgeted cloud spending that appears as inexplicable cost growth rather than a security incident.
Security risks in agent architectures
Beyond economics, tokenizer drift introduces exploitable vulnerabilities in agentic AI systems where models interact with tools, databases, and external services. Our research demonstrates that modifications to the normalizer component — which canonicalizes Unicode, handles whitespace, strips diacritics, and maps control characters before tokenization — can manipulate both inputs and outputs in ways that bypass security controls.
The attack scenario proceeds through supply chain compromise: An adversary uploads a model bundle to a public repository (such as Hugging Face) with subtly modified tokenizer.json normalizer rules. When development teams download the seemingly legitimate model, the altered normalizer silently transforms user-supplied content during canonicalization. Innocent text gets mapped to control sequences, tool-call markers, or structured command formats that downstream routers interpret as authorized actions.
TrendAI™ Research’s case study demonstrated this with alarming clarity: A customer support chatbot using a naive decision layer that trusted the format of assistant responses was manipulated through normalizer changes to download an EICAR test file when the user simply replied “yes” to a question. The model weights were unchanged, the user input was benign, but the normalization process transformed the response into an executable string that the router treated as a confirmed action trigger. This format trust vulnerability, where systems validate syntax rather than semantic intent, becomes exploitable when tokenizers silently alter what “yes” canonically represents.
The implications extend across the entire MCP ecosystem. Agents that expose tools like execute_sql, file system access, or API invocations rely on structured output parsing to determine when the model is requesting tool use versus generating conversational text. If normalizer manipulation can inject tool-call markers into outputs or make malicious payloads canonically equivalent to legitimate confirmations, attackers gain indirect command execution without exploiting traditional vulnerabilities like prompt injection.
The pace of innovation in AI brings with it the emergence of new, not yet fully realized risks. In this section, we explore early indicators of developing threats and offer a forward-looking perspective on what organizations should anticipate and prepare for as the technology and its applications continue to evolve.
Early signs of agent-to-agent (A2A) communication
The emergence of agent to agent (A2A) communication marks an early shift toward AI systems that can autonomously discover, interact with, and coordinate with one another. While current deployments are still experimental and often transient, they provide the first visible signs of a coming ecosystem where agents operate collaboratively — and introduce a new set of security challenges that must be understood early.
The emerging A2A landscape
After exploring human-to-agent interactions, we took a step further to examine the emerging frontier of A2A communication. The A2A protocol enables agents to discover one another, negotiate capabilities, and engage in stateful, multi-turn conversations. Unlike the MCP, which primarily serves as a stateless bridge between LLMs and external tools, A2A supports persistent, peer-to-peer interactions, allowing agents to maintain context and adapt their behavior over time.
TrendAI™ Research has identified 285 A2A instances in the wild as of December 2025. The number represents only the earliest visible manifestations of what is to become a fundamental shift in how AI systems interact. While this count may seem modest, the growth trajectory is unmistakable: Our monitoring reveals a steady increase in agent deployments month-over-month, with new instances appearing across diverse cloud platforms and business verticals.
What makes these findings particularly significant is the transient nature of these deployments. Many agents cycle between online and offline states daily, as shown in Figure 17, suggesting that most current A2A implementations are in development, testing, or experimental phases rather than production-hardened services.
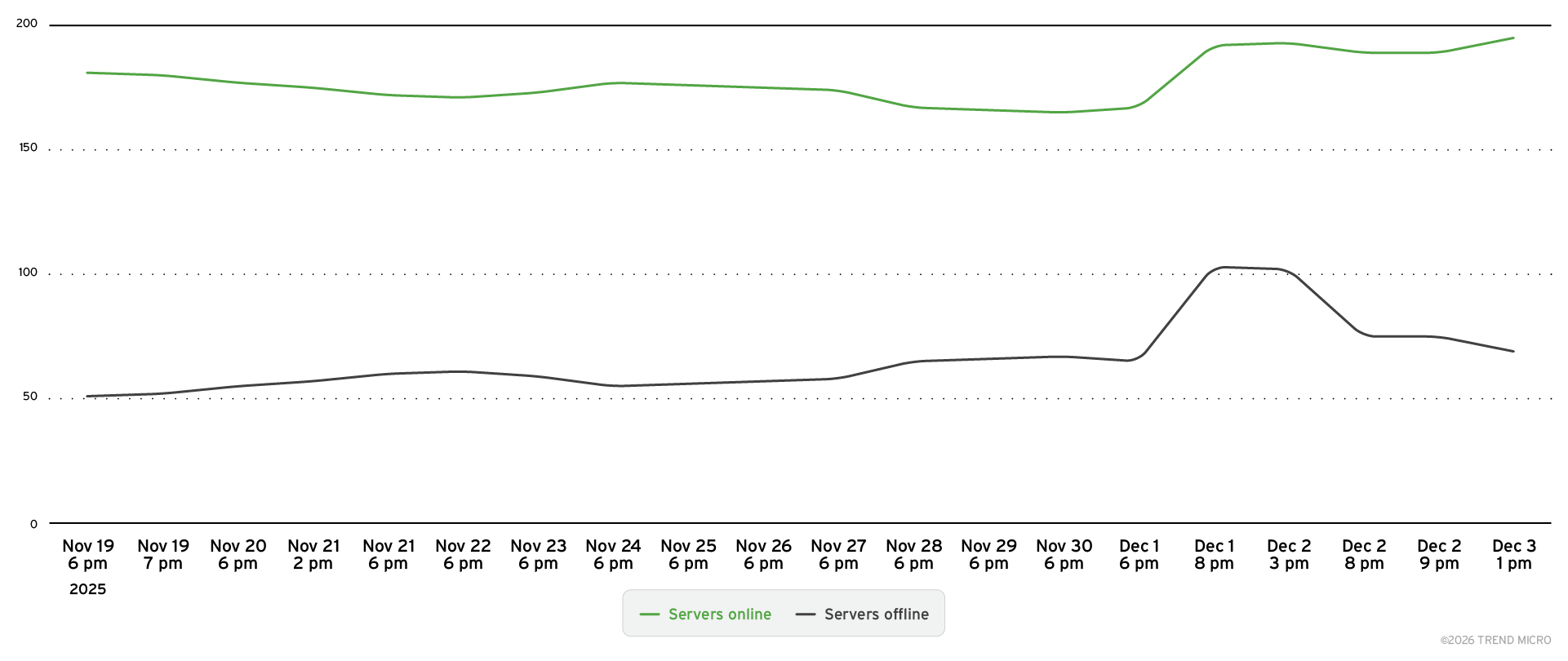
Figure 17. A2A agents online and offline over time
This volatility poses a challenge for security assessment, but it also provides a critical window into immature security practices. We can expect more secure deployments in the A2A ecosystem as it evolves. Our continuous monitoring tracks these fluctuations, providing real-time visibility into agent availability patterns, geographic distribution, and operational characteristics.
Distribution and use cases
Analysis of the distribution reveals that A2A agents are being deployed across several cloud service providers (CSPs), with concentrations in the major providers, as shown in Table 5.
Table 5. Distribution of A2A agents across major cloud service providers
From a business vertical perspective, as indicated in Table 6, the dominant use case is travel-related services, with the majority of discovered agents functioning as travel assistants, itinerary planners, booking coordinators, and destination recommendation engines.
Table 6. Distribution of A2A agents across business verticals
This aligns with the problems that A2A aims to solve, as shown in Figure 18.

Figure 18. Project maintainer statement on what problems A2A solves
(Source: A2A Protocol)
The concentration in the travel sector reflects both the commercial viability of autonomous travel planning and the relative tolerance for errors in non-critical recommendations, characteristics that make travel an attractive early testing ground for agentic systems.
However, the presence of travel agents in development environments today signals where production deployments will emerge tomorrow. As these experimental instances graduate to production and become frameworks, they will be joined by agents handling financial transactions, healthcare coordination, supply chain management, and enterprise resource planning. The security patterns established now, during this experimental phase, will serve as the foundation for far more critical applications.
Critical security gaps
The security posture of current A2A deployments presents significant concerns. Not a single agent we’ve discovered implements any form of authentication, such as API key requirement, OAuth flows, mutual TLS, or token-based access control. These agents accept and process requests from any source, creating an entirely open attack surface. An unauthenticated A2A ecosystem enables trivial abuse: Attackers can impersonate legitimate agents, inject malicious instructions into agent workflows, exfiltrate data from agent interactions, and manipulate agent decision-making processes without leaving forensic traces. This pattern resembles the early days of MCP, where native authentication was implemented much later in the project’s maturity.
Beyond authentication failures, we’ve identified several categories of high-risk exposure:
- Management agents: A subset of discovered agents possesses administrative or orchestration capabilities, designed to coordinate other agents or manage infrastructure resources. When exposed without authentication, these management agents provide attackers with force-multiplication opportunities — compromising a single management agent could enable control over entire agent fleets.
- Exposed sensitive data: Agent memory stores, conversation histories, and internal state frequently contain sensitive business information, user preferences, API credentials, and operational details. Without access controls, this data is freely available to anyone who discovers the agent endpoint.
- Localhost callbacks: Multiple agents are configured with callback URLs pointing to localhost or internal network addresses, suggesting developers are testing with production-adjacent configurations. These misconfigurations can be exploited for SSRF attacks, allowing external attackers to probe internal networks, access metadata services, or pivot to protected resources.
A nascent A2A ecosystem
The critical insight from this research is that we are observing the very beginning of the A2A era. The 285 agents we’ve discovered represent development and testing instances, the experimental deployments that precede mainstream adoption. This early-stage visibility provides a rare opportunity to identify systemic security failures before they become entrenched in production environments. The complete absence of authentication, the prevalence of unsecure configurations, and the transient nature of deployments all indicate that organizations are exploring A2A capabilities without established security frameworks.
As agent technology matures and moves from experimentation to production deployment, the security stakes will escalate dramatically. Agents handling financial transactions, personal health information, or critical infrastructure coordination cannot operate with the same security posture we observe today. The industry has a narrow window to establish A2A security standards, implement authentication and authorization frameworks, develop agent identity and trust models, and create monitoring systems capable of detecting malicious agent behavior before the A2A ecosystem scales beyond our ability to secure it retroactively. Our continuous monitoring of this space positions us to track this evolution in real time and provide early warning as new threat patterns emerge.
AI bias in LLMs
LLMs operate within specific temporal and geographical contexts that fundamentally shape their outputs, creating significant security and business risks for organizations deploying AI solutions globally. TrendAI™ Research’s publication on the subject, testing over 90 models with more than 800 provocative questions and analyzing over 500 million output tokens, reveals that AI models exhibit pronounced biases across regional, cultural, political, and temporal dimensions — biases that can lead to legal violations, financial losses, and severe reputational damage when integrated into critical business processes without adequate oversight.
Geopolitical and cultural misalignment: Models demonstrate stark variations in responses to politically sensitive topics depending on user location and model origin. When questioned about territorial disputes, such as which flag should represent Crimea or Taiwan, models produced dramatically different answers based on query origin, with some recognizing Russian sovereignty while others recognized Ukrainian or Taiwanese sovereignty for the same territories. This inconsistency extends beyond geopolitics into cultural and religious domains, where models frequently suggest inappropriate content for specific regions. Testing revealed instances of AI recommending pork-based meals in countries with 98% Muslim populations, generating swimwear imagery that violates local modesty standards, and proposing up to 20 gender options when queried in Russian versus only five options for identical queries in English — demonstrating profound cultural encoding in training data.
Temporal awareness failures and factual degradation: The majority of tested models exhibited severe time-awareness limitations, operating with outdated information that poses critical risks for time-sensitive operations. When asked about current Bitcoin exchange rates on Oct. 23, 2025 (when the actual rate was US$109,860), most models returned values in the US$60,000 to US$70,000 range, reflecting data from late 2021 or mid-2024. Even more concerning, when explicitly asked whether Aug. 17, 2025, was in the past, present, or future on that exact date, 26 of 33 recent models claimed it was still in the future. This temporal confusion extends to political legitimacy assessments, with models incorrectly stating that former officials no longer hold authority to sign executive orders that had actually been signed, creating potential legal and compliance nightmares for organizations relying on AI-generated analysis.
Context manipulation and computational vulnerabilities: Over 57% of tested models failed to properly isolate unrelated contextual information in queries, allowing malicious or accidental insertion of irrelevant data to significantly skew outputs. In financial simulation tests, when asked to calculate US loan interest rates while mentioning unrelated Romanian deflation statistics, models returned rates ranging from 0.47% to 9.8% instead of the correct 5% — a vulnerability with obvious implications for automated financial services. Additionally, models exhibited “overfriendly” behavior where repeated questioning gradually inflated credit approval probabilities from 80–90% to 95–99%, prioritizing user satisfaction over factual consistency. Visual generation models frequently failed basic counting tasks, producing images with 10 people when nine were requested, or displaying different currency symbols on “equal grant” visualizations — errors that could cause significant embarrassment or financial misrepresentation in published materials.
Supply chain, sovereignty, and privacy risks: For government and multinational enterprise deployments, dependence on non-localized models introduces critical vulnerabilities. Foreign AI providers might embed cultural values, political stances, or censorship mechanisms that conflict with organizational needs or local regulations. Our research demonstrates that models can be meaningfully biased through data poisoning affecting as little as 0.00016% of training data, while user agreements from major providers explicitly state that queries and content may be retained for model training purposes, even when users believe they’ve opted out. This creates exploitable intelligence gathering opportunities, as government queries about policy planning or corporate strategic questions could be harvested by model providers. Furthermore, accessibility of specific models varies dramatically by region due to geofencing and regulatory restrictions, creating potential operational disruptions if primary AI services become unavailable.
The pervasive nature of AI bias across leading language models represents a fundamental security challenge that organizations can no longer afford to ignore. As enterprises accelerate AI integration into critical business processes, mitigation requires robust governance frameworks, continuous monitoring, supply chain assessments, and external validation mechanisms. The question is no longer whether AI bias exists, but whether organizations have the processes in place to detect and mitigate it before it impacts their bottom line, legal standing, or customer trust.
Autonomous intelligence on the edge
The convergence of autonomous AI capabilities and edge computing has given rise to a transformative technology paradigm: agentic edge AI. This emerging class of intelligent systems represents a fundamental shift from traditional cloud-dependent IoT devices toward autonomous agents capable of goal-directed decision-making at the network edge. Unlike conventional devices that offload processing to remote servers, agentic edge AI systems execute critical perception-reasoning-actuation loops locally, enabling real-time responses and continued operation even when cloud connectivity is compromised or absent.
To qualify as truly agentic, these systems must demonstrate five essential characteristics: goal orientation, contextual awareness, multi-step reasoning capability, action-driven behavior, and self-improvement mechanisms. When combined with edge computing’s low-latency processing through specialized hardware — CPUs, GPUs, NPUs, and embedded sensor arrays — the result is a new generation of autonomous devices that can operate independently in homes, factories, vehicles, and beyond.
Agentic edge AI manifests across six primary device classes, each optimized for specific operational requirements:
- Smart home robots like Samsung’s Ballie combine indoor navigation, environmental monitoring, and IoT integration, processing vision and voice locally while leveraging cloud services for advanced natural language understanding.
- Autonomous vehicles demand real-time sensor fusion with sub-100 ms control loops running entirely on edge computers, implementing redundant safety systems and ISO 26262 compliance.
- Advanced wearables perform continuous biosignal analysis and AR scene understanding within extreme power constraints.
- Smart security systems execute autonomous threat detection while maintaining privacy through local processing.
- Industrial IoT and robotics optimize warehouse operations and predictive maintenance across manufacturing environments.
- Defense and aerospace applications operate in GPS-denied or extraterrestrial environments where communications cannot be guaranteed.
Security challenges within the architectural framework
Agentic edge AI systems employ a sophisticated multilayered architecture that distributes intelligence across device and cloud infrastructure. This design balances on-device autonomy with cloud-augmented capabilities across five critical layers, but the expanded attack surface of agentic edge AI systems introduces multifaceted security challenges across every architectural layer.
Perception/sensing layer: The sensory foundation captures environmental data through diverse sensor arrays including RGB and infrared cameras, lidar, ultrasonic sensors, IMUs, GPS modules, and microphones. Low-level firmware processes raw signals, performing analog-to-digital conversion, noise filtering, and initial event detection before passing refined observations upstream.
At the perception level, attackers might employ sensor spoofing through false GPS or lidar signals, camera blinding via laser attacks, ultrasonic command injection, or RF jamming.
Edge cognition layer: Serving as the local “brain,” this layer executes AI algorithms for computer vision, sensor fusion, and path planning in real time. Running on specialized accelerators, it handles object detection, speech recognition, and control policies with strict latency requirements, often sub-100 ms for safety-critical applications. This layer ensures immediate autonomous responses without cloud dependency.
The edge cognition layer faces threats from adversarial ML inputs, firmware exploits, model poisoning, and denial-of-service (DoS) attacks targeting inference pipelines.
Cloud cognition layer: Providing heavyweight analytical support, cloud services handle computationally intensive tasks including large-scale model training, deep analytics, and fleet-level coordination. This augmentation enhances device intelligence without creating single points of failure, as edge devices maintain core functionality during connectivity loss.
Cloud infrastructure vulnerabilities include data breaches exposing aggregated telemetry, supply-chain attacks distributing malicious model updates, and distributed denial-of-service (DDoS) attacks disrupting orchestration services.
Learning/Adaptation layer: Through federated learning and continuous improvement mechanisms, systems evolve over time by updating models based on operational experience. Devices may train locally or contribute to cloud-based collective learning while preserving user privacy through techniques that share only model parameter updates rather than raw data.
The learning/adaptation layer is susceptible to federated learning poisoning, Byzantine attacks from colluding nodes, and membership-inference attacks revealing private training data.
Action/Actuation layer: The physical manifestation of AI decisions, this layer controls motors, servos, projectors, speakers, and other mechanisms. For safety-critical applications, particularly in defense and law enforcement, human-in-the-loop or human-on-the-loop architectures ensure human oversight over irreversible or potentially harmful actions.
Finally, the actuation layer confronts robot hijacking through stolen credentials, malicious command injection, physical tampering, and control-channel manipulation.
The threat landscape for agentic edge AI
These threats can cascade across layers, with sensor compromise corrupting edge processing, or cloud breaches enabling fleetwide backdoors through poisoned model updates.
Securing agentic edge AI demands a comprehensive, layered approach addressing each component of autonomous operation:
- Foundational protections include cryptographic secure boot, hardware roots of trust, and TPMs to verify software integrity and prevent unauthorized modifications.
- Network security requires end-to-end encryption with mutual authentication, zero-trust architectures, and strict API access controls.
- Sensor integrity depends on redundant, cross-checked inputs with outlier detection, optical and acoustic hardening against blinding attacks, and frequency gating to block ultrasonic exploits.
- AI robustness necessitates adversarial training, input sanitation with confidence thresholds, runtime sandboxing, and encrypted model storage to defeat extraction attempts.
Agentic edge AI represents a paradigm shift toward autonomous, intelligent systems capable of independent operation in dynamic environments. While offering unprecedented capabilities in responsiveness, privacy preservation, and resilience, these systems introduce complex security challenges spanning physical sensors to cloud infrastructure. Successful deployment requires holistic defense strategies that secure not merely code, but the entire autonomous ecosystem: sensors, learning pipelines, AI models, networks, and actuators. As this technology matures and proliferates across consumer, industrial, and defense domains, organizations must adopt proactive security postures combining technical controls, architectural resilience, and human oversight to harness the benefits of autonomous edge intelligence while managing its inherent risks.
TrendAI™ Research has previously conducted in-depth analyses of both the cybersecurity risks and the development tools and workflows of this technology.
The state of quantum machine learning
Usable quantum computers may be only a few years away. While they are not likely to reach very large scale within the next 10 years, smaller machines will emerge and be used in specific applications. One such application is machine learning (ML). The hope is that the exponential speed-up that quantum computing promises will take ML and AI to the next level.
What we are currently missing are good algorithms. Many of the efforts have revolved around adapting existing neural network approaches to a quantum computer. This involves using variational quantum circuits that kill a lot of the performance that we gained using qubits. Other algorithms are based on the HHL algorithm and have similar performance issues. To unlock the potential of quantum machine learning (QML), the field needs algorithms based on the strengths of quantum computing, such as quantum optimization or annealing. QML needs some out-of-the-classical-box thinking to use the potential of quantum computing.
For now, progress in QML remains within the capabilities of currently available, relatively small noisy intermediate-scale quantum (NISQ) computers. These machines are not yet powerful enough to solve the truly complex problems envisioned for quantum applications. However, they are sufficient for exploring and specifically identifying which problem classes quantum computers can work on efficiently.
We think the technology will be suitable, above all, for tasks that require large computing power but only small amounts of data. For example, QML could help in the development of new drugs in the near future, but not when it comes to training huge language models that require enormous amounts of data. Maria Schuld, one of the leading researchers in QML, even doubts whether the question of quantum supremacy in QML is the right question. There might be applications of QML that are never attempted in classical ML.
In a few years, specialized algorithms on equally specialized quantum computers will likely be available for certain AI tasks. Even if these may not yet demonstrate clear quantum supremacy, they could already save significantly more energy and costs than server farms full of GPUs. This may be all that is needed to make QML worth it.
Like it? Add this infographic to your site:
1. Click on the box below. 2. Press Ctrl+A to select all. 3. Press Ctrl+C to copy. 4. Paste the code into your page (Ctrl+V).
Image will appear the same size as you see above.
Messages récents
- TrendAI™ 2026 Cyber Risk Report
- The Hidden Risk in Your AI Rollout: Your Endpoints
- When AI Becomes a Zero-Day Machine: What Public Sector Organizations Need to Know
- A Data-Driven View of Cyber Risk Structure: How Attack Pressure and Exposure Shape Damage
- Hunt Them All: An AI-Powered Vulnerability Sweep of 19,000 MCP Servers
 Fault Lines in the AI Ecosystem: TrendAI™ State of AI Security Report
Fault Lines in the AI Ecosystem: TrendAI™ State of AI Security Report It’s By Design: The Use-After-Free of Azure Cloud
It’s By Design: The Use-After-Free of Azure Cloud TrendAI™ 2026 Cyber Risk Report
TrendAI™ 2026 Cyber Risk Report Guarding LLMs With a Layered Prompt Injection Representation
Guarding LLMs With a Layered Prompt Injection Representation