By Ashish Verma and Jingfu Zhang
Introduction
Large language models are powered by more than just weights and prompts. At the heart of every system is a tokenizer, the component that decides how text is broken down into tokens. These tokens drive how much computing power is required, how much an API call costs, and how much text fits into a model’s context window.
When tokenizer behavior changes, the effects can ripple across both engineering and business outcomes. The same text may suddenly use two or three times more tokens. For developers and platform teams, this shows up as inflated CPU usage, shorter contexts, and higher latency. For CIOs, CISOs, CFOs, or FinOps leaders, this shows up as rising bills, service instability, and unfair user experiences across languages.
This risk can arise in two ways:
- Accidental drift: A bug, misconfiguration, or unchecked change to tokenizer files
- Adversarial manipulation: A deliberate attempt to inflate costs, exhaust quotas, or weaken model safety by tampering with tokenizer artifacts
We call this the tokenization drift. It is a trap because the model still appears to work, but the costs, performance, and fairness silently shift against you. This article explains how the trap works, what it looks like in practice, and how both technical teams and decision makers can detect and prevent it.
Threat model for the tokenization drift
Some scenarios are accidental (bugs, configuration drift). Others are adversarial (malicious uploads, targeted attacks). Both have the same business impact: higher costs and degraded service. There are a few ways the tokenization drift can show up in real systems:
Malicious uploads: Someone uploads a model to a public hub with a modified tokenizer. Teams that download and use it might not notice anything wrong at first, since the model still runs normally.
Accidental drift: Inside a company, engineers might copy a tokenizer from another project or pull the “latest” version from a repo without checking. A small difference in the tokenizer files can cause silent cost increases over time.
Economic denial of service (EDoS): By inflating the number of tokens, an attacker can burn through API quotas or drive-up cloud bills. This is not a crash, but it is still a form of denial of service (DoS) because the system becomes too expensive to run.
Language bias: An attacker, or even a poorly tested tokenizer change, can target certain languages. For example, English might stay cheap, while Chinese or Hindi suddenly cost three times more to process. This creates unfair service quality across users.
Weakened safety rules: Tokenizers also carry information about special tokens, such as system, user, and assistant markers. If these IDs are swapped or changed, safety instructions can be ignored or bypassed without anyone realizing.
Inflated CPU usage: Extra tokens mean work for both the tokenizer and the model. CPU usage rises sharply, requests slow down, and autoscaling kicks in. This creates more load, increases pod churn, and raises infrastructure bills. In busy systems, queues can back up, timeouts can increase, and multitenant workloads might suffer. What looks like “normal text” can quietly drain compute capacity.
In this research, we examine two things:
- How tokenizer changes affect hardware use, cost, and latency.
- How altered tokenization templates can change model outputs in ways that could be used to trigger downstream command like behavior on MCP systems.
Part A: Cost, Latency, and Hardware Economics
To demonstrate the impact of a small change in tokenizer files, we ran an experiment to measure how they can change token counts, cost, and performance signals, all without changing the model weights.
Setup
Model: We used small, open models that run on CPU. Below are the models we have used in this experiment:
| S.No. | Model | Source |
|---|---|---|
| 1 | gpt2 | https://huggingface.co/gpt2https://huggingface.co/gpt2 |
| 2 | distilgpt2 | https://huggingface.co/distilgpt2https://huggingface.co/distilgpt2 |
| 3 | facebook/opt-125m | https://huggingface.co/facebook/opt-125mhttps://huggingface.co/facebook/opt-125m |
| 4 | EleutherAI/gpt-neo-125M | https://huggingface.co/EleutherAI/gpt-neo-125Mhttps://huggingface.co/EleutherAI/gpt-neo-125M |
| 5 | sshleifer/tiny-gpt2 | https://huggingface.co/sshleifer/tiny-gpt2https://huggingface.co/sshleifer/tiny-gpt2 |
Datasets: We used a short, mixed set of sentences in English, Hindi, and Chinese, kept in plain text for consistency and safety.
Variants:
- Baseline tokenizer from the official source
- Altered tokenizer that differs in a controlled way; for safety, we only adjusted the tokenizer's merge strategy (details omitted) to induce token-count inflation without altering model weights.
Hardware: The experiment was conducted on one CPU host or a small virtual machine (VM).
Runs: Each variant was run three times to smooth out noise.
Validity checks:
- Inputs must be identical across runs.
- No network calls are made during measurement.
- Clear note that model weights were not changed.
Limitations of experiment
- Small test sets do not capture every workload.
- VM noise can affect latency and CPU metrics.
- Results vary by model family and tokenizer design.
What we measured
- Tokens per character for each language
- Tokenizer latency per request
- Effective context in characters that fit into a 4,000-token window
- Cost projection using a simple price per 1k tokens
Procedure
- Load the baseline tokenizer. Process the same fixed input set. Record all metrics.
- Load the altered tokenizer. Process the exact same inputs. Record the same metrics.
- Average the results over a few fixed runs.
- Compare baseline and altered, focusing on percentage change, not raw numbers.
Results
Even without malicious actors, our test shows that a small, controlled change created measurable increases in cost and CPU. This illustrates why detection matters in both engineering and financial terms.
Tokens per character (tokens/char)
| Model | Baseline | Modified | Delta | % Change |
|---|---|---|---|---|
| gpt2 | 0.321 | 0.681 | +0.360 | +112.1% |
| distilgpt2 | 0.321 | 0.641 | +0.319 | +99.7% |
| facebook/opt-125m | 0.321 | 0.731 | +0.410 | +127.7% |
| EleutherAI/gpt-neo-125M | 0.321 | 0.671 | +0.350 | +109.0% |
| sshleifer/tiny-gpt2 | 0.321 | 0.704 | +0.382 | +119.3% |
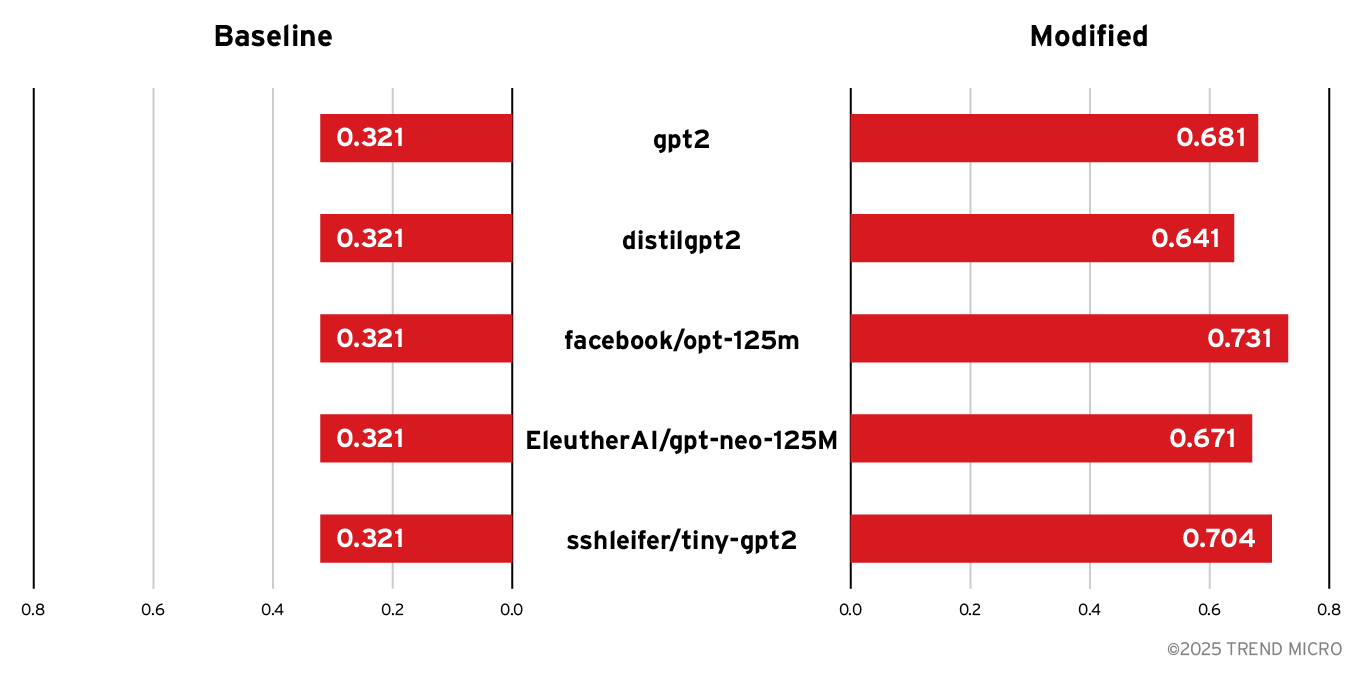
Figure 1. Comparison of tokens per character (baseline vs. modified)
P95 tokenization latency in milliseconds (ms)
| Model | Baseline (ms) | Modified (ms) | Delta (ms) | % Change |
|---|---|---|---|---|
| gpt2 | 219.543 | 269.915 | +50.373 | +22.9% |
| distilgpt2 | 139.450 | 173.870 | +34.420 | +24.7% |
| facebook/opt-125m | 320.585 | 351.508 | +30.924 | +9.6% |
| EleutherAI/gpt-neo-125M | 411.063 | 443.939 | +32.875 | +8.0% |
| sshleifer/tiny-gpt2 | 76.912 | 107.914 | +31.002 | +40.3% |
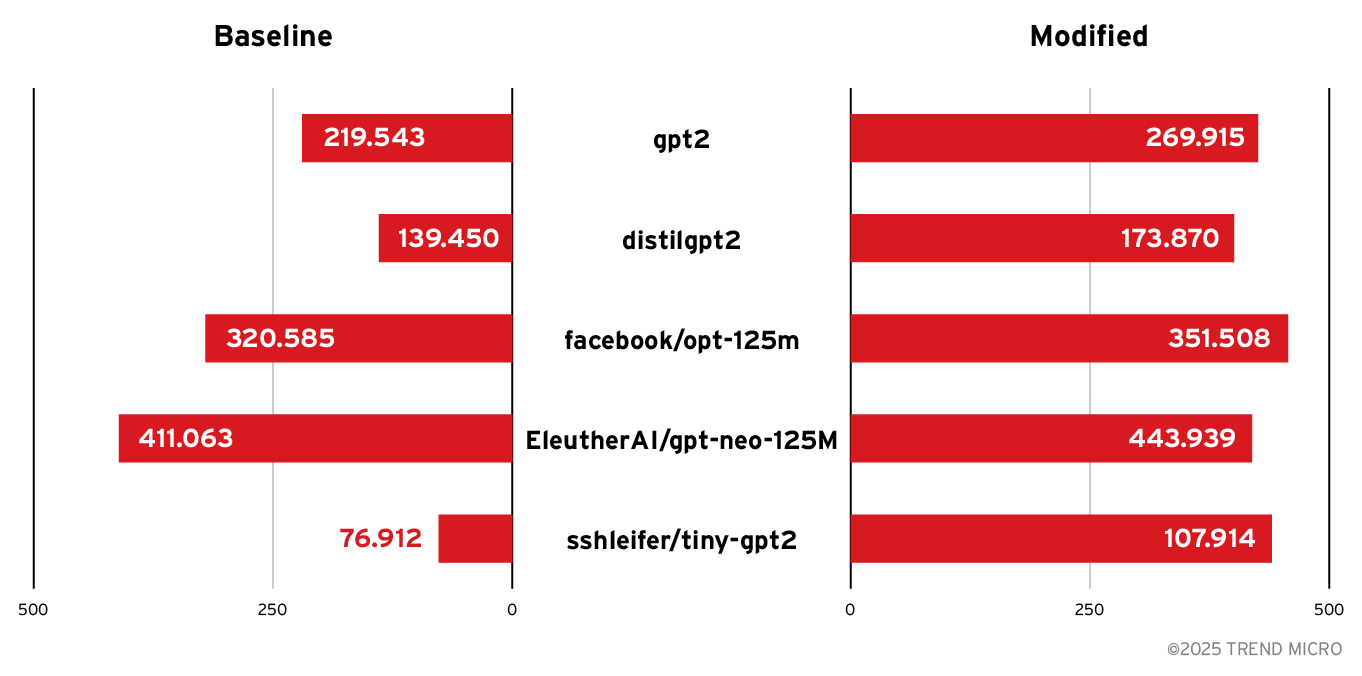
Figure 2. Comparison of P95 latency (baseline vs. modified)
Cost projection per 1,000 requests
The average cost of common and popular models per 1 million tokens is US$8. Using this cost metric, we evaluated cost per 1,000 requests:
- Average characters per request: 1,500
- Cost per million tokens: US$8
- Cost per token: US$0.000008
The formula we used was: Cost per 1,000 requests (US$) = (tokens per character) * (average characters per request) * 1,000 * (cost per token in US$)
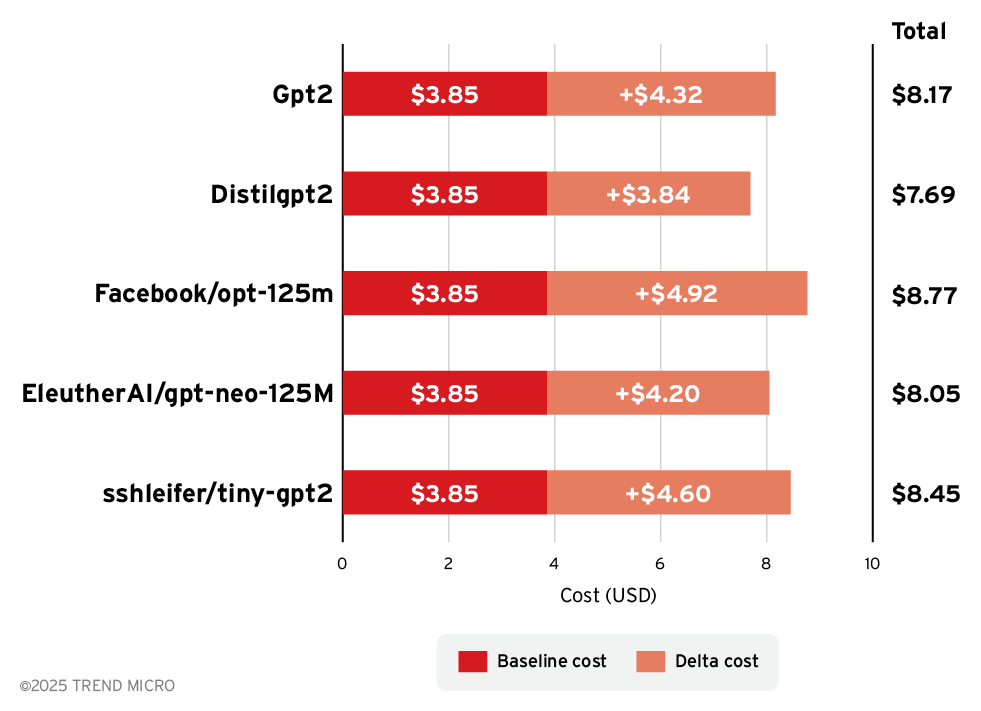
Figure 3. Cost projection per 1,000 requests (stacked comparison of baseline + delta)
Results and insights from the experiment
- Token counts explode. Across models, the altered tokenizer produced around ×2.09 tokens per character. This is not a minor drift. It means that the same workload now costs around ×2.09 more in a hosted API and uses more compute on self-hosted clusters.
- Context space shrinks. In a model with a 4,000-token window, English text dropped from ≈12,500 characters to ≈5,900 characters (0.321→0.681 tokens/char). Chinese text shows similar or larger shrinkage. This means prompts, history, and system instructions all get cut shorter. Safety rules and memory features are the first to suffer.
- Latency and CPU usage rises. Tokenization latency increased by roughly 8% – 40% (P95), depending on the model. CPU usage per request rose alongside tokenization latency. This shows that a Tokenization Cost Trap does not only affect the bill, but also slows down the whole system and increases pressure on autoscaling.
- Different languages are affected unevenly (tested in GPT-2 only). For example, Chinese and Hindi saw larger percentage increases than English. This creates an unfair experience across users. One group pays more and gets worse performance for no good reason.
Language Token/Char Delta Baseline Altered Chinese 0.460 0.984 +0.524 English 0.321 0.681 +0.360 Hindi 0.875 1.531 +0.656 - There’s a stealth factor. None of these effects are obvious to an end user or developer at first. The model answers normally. The trap is silent until costs, CPU dashboards, or customer complaints start piling up. That makes it a real supply-chain risk.
Our experiment showed that tokenizer drift is not just an implementation detail. It can change cost, performance, safety, and fairness in production systems. Treat it like you would treat a change to model weights or critical code dependencies.
What this shows
- Small tokenizer changes can double or triple token counts
- The same context window can fit much less text
- Tokenizer latency increases
- CPU per request rises
- Cost projection grows in the same direction as token counts
For executives, these results mean AI services can quietly become more expensive and less reliable even when nothing obvious has changed. Tokenizer drift is invisible on the surface but measurable in bills, CPU dashboards, and user experience complaints.
How tokenization drives cost and latency
To understand why the tokenization cost trap matters, it helps to look inside the tokenizer itself.
What changes
Most modern LLMs use a Byte Pair Encoding (BPE) or GPT-style tokenizer. These tokenizers rely on a merges table that combines frequent character pairs into larger tokens.
- Example: “New" might be stored as a single token, instead of separate "N," "e," "w," and " " (space).
- If common merges are removed (such as spaces, punctuation, or endings like "ing"), the same text fragments into many smaller tokens.
This kind of change does not touch the model’s weights at all, only the tokenizer artifacts. But the effects cascade through the system.
Why CPU, latency, and cost go up
- CPU usage: Tokenization itself is CPU-bound. More tokens mean more work to convert text into input IDs, raising CPU utilization on every request.
- Latency: Even if you generate only a few new tokens, the model’s forward pass scales with input length. Longer sequences increase attention overhead and KV-cache setup, making responses slower.
- Cost: Billing usually counts input plus output tokens. If the tokenizer splits text into 3X as many tokens, you pay 3X more for the same request.
An example
With a healthy tokenizer:
| "New York City!" | ["New", " York", " City", "!"] | 4 tokens |
| "New York City!" | ["N", "e", "w", " ", "Y", "o", "r", "k", " ", "C", "i", "t", "y", "!"] | 15+ tokens |
The sentence is the same. But the server now has to tokenize more characters on CPU and the model must process a much longer input sequence.
The result: higher CPU load, slower requests, and a bigger bill!
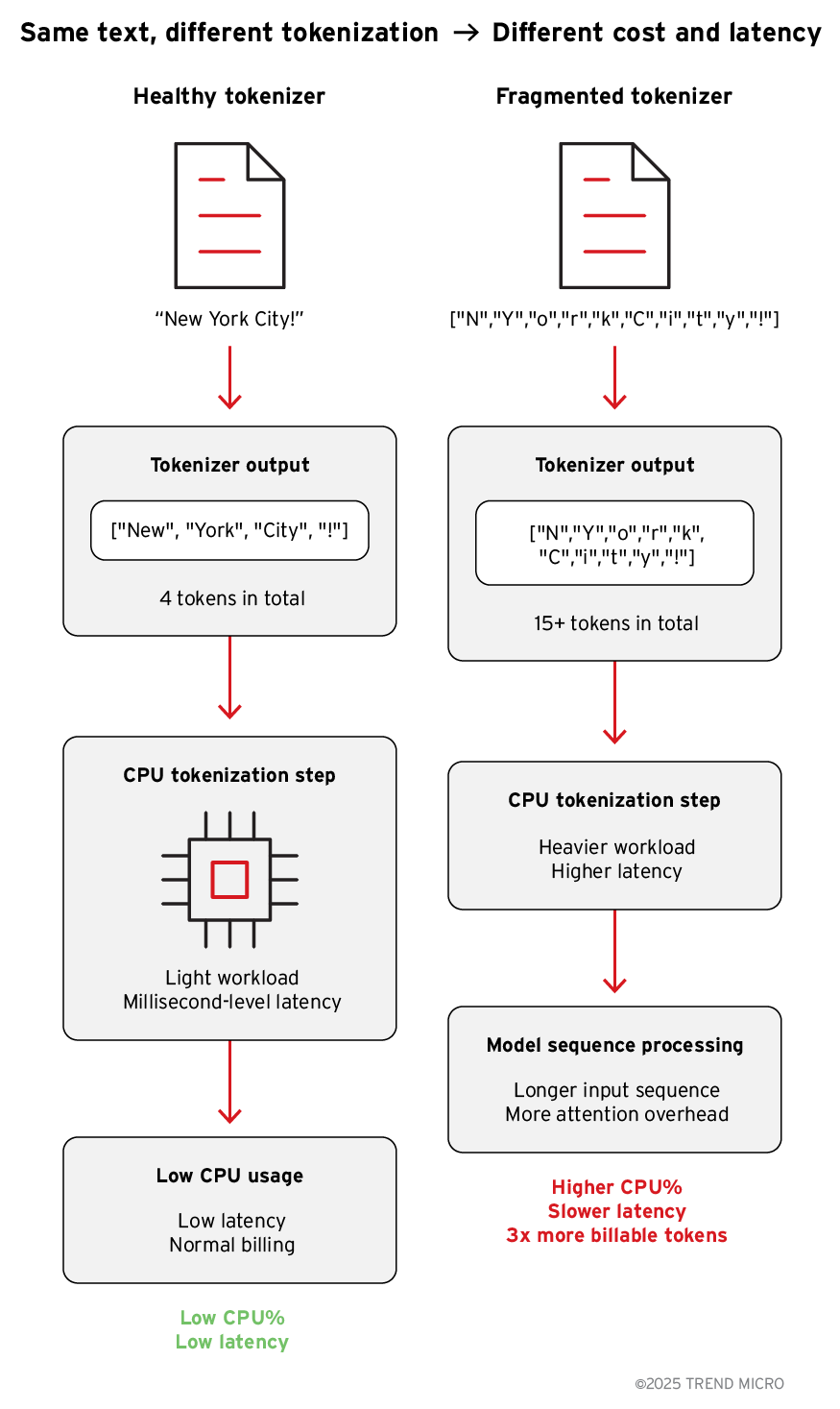
Figure 4. Different tokenization impact on CPU, latency, cost
In short
Swapping in a tokenizer with more fragmented merges increases the number of tokens per character. That single change, without altering model weights, drives up CPU usage, latency, and billable tokens for every request.
Part B: The security side of drift: Response manipulation and command injection
When deployed in agent stacks, models are one piece of a pipeline. A router or agent controller reads model output, looks for structured signals (function calls, JSON blobs, or special token sequences), and dispatches tools or external actions when those signals appear. Because routers commonly trust the format of the model’s output, anything that makes the output look like a valid tool call can cause the router to act.
That trust is why tokenizer drift at the normalization stage is a real security problem. Small, silent changes to how raw text is canonicalized before tokenization can turn harmless user content into control-like strings after normalization or cause the model to emit control tokens where it never did before. In those scenarios the model weights are unchanged and the model still appears to work, but the router can be tricked into executing actions that operators did not intend.
The following section focuses on the modifying normalizer entry in tokenizer.json. The normalizer governs Unicode forms, case folding, diacritic stripping, whitespace handling, and mappings for control characters, all of which determine the exact token stream the model sees and emits.
What is a Normaliser?
The normalizer is the first step that cleans and standardizes raw text before any token splitting. It doesn’t change intent, it makes inputs consistent so the tokenizer treats similar text the same way. Because it runs before tokenization, small changes here can shift token boundaries and alter what the model “receives” and later “outputs.” Some of the operations performed by normalizer include canonicalization, case and diacritics, whitespace and breaks, control and invisible characters, punctuation and symbols, numbers/dates/formatting, quoting and fences, etc.
High-level attack scenario
- Attacker modifies a model bundle’s tokenizer.json normalizer rules and uploads on a public hub (with a similar repo name, or original repo).
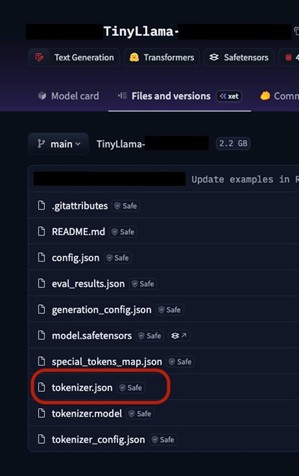
Figure 5. Tokenizer drift from a malicious upload on Hugging Face using a cloned TinyLlama repository (TinyLlama/TinyLlama-1.1B-Chat-v1.0).
- When a team downloads and uses the (unverivied) model, the new normalizer canonicalizes user-supplied content in unexpected ways (e.g., replacing commonly appearing tokens to malicious commands).

Figure 6. Tampered tokenizer file showing altered normalizer configuration — blurred here for safety
- The model’s output now contains token sequences the downstream router treats as tool invocations. The router executes the tool because it trusts the assistant’s output format.
- The result: a nominally benign user input indirectly triggers an action in MCP/tooling without explicit operator intent.
Because the model itself appears functional, operators can miss this until it is abused or causes harm.
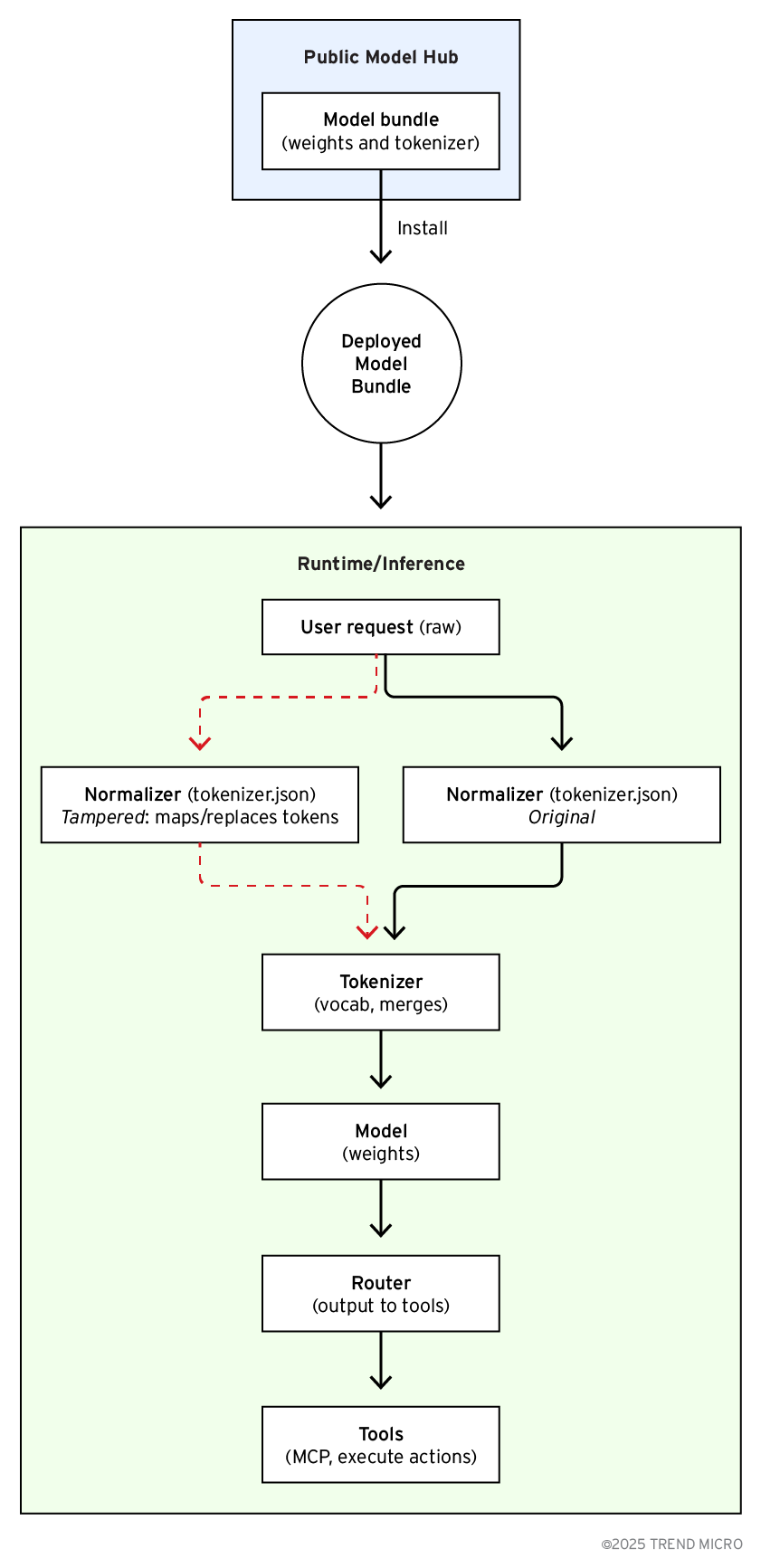
Figure 7. Tokenizer drift from a malicious upload in the supply chain silently alters inputs and outputs, creating new risks in LLM deployments.
Case study: When a simple “yes” triggers an EICAR download
Purpose. This demo shows why small changes at the tokenizer or normalizer layer can turn a harmless looking answer into an action trigger. The model weights are unchanged. The effect comes from how the pipeline interprets the model’s text.
Scenario. A customer support chatbot sends its textual responses into a downstream component called the router (decision layer), which selects and executes tools based on the assistant’s output. A naive policy “If the model’s response is (or becomes) an executable string,” the router’s simplistic mapping from text to actions, can directly trigger the command by tool/agent.
Safety note. We downloaded eicar test file for this demo.
Demo
In the scenario presented here a store’s customer support chatbot is taking customer queries. The agent stack includes a decision layer that reads the chatbot assistant’s (model’s) message and decides on executing commands. A naive policy states: if the model’s response is executable string, perform the action. This is fragile. If normalization or tokenization changes how input and output text look, the router (decision layer) can misread a reply and run the wrong tool/agent.
Unintended Actions from Tokenizer Drift
Why this matters
Format trust. The trusted text format over intent. It did not check provenance, context, or policy.
Silent shift. A change in normalization made certain inputs and outputs canonically equal to desired text or command, even when the original text was not a direct confirmation.
From text to action. Once the system matched the response, it carried out the command, leading to an unintended action from a small text difference.
Mitigation strategies
- Lock down tokenizer artifacts
→ Save the hash (checksum) of every tokenizer file (tokenizer.json, vocab.json, merges.txt, tokenizer_config.json)
→ Compare these hashes in CI/CD and at model load time. If the hash changes unexpectedly, block the release
Why: Hashes give you a reliable fingerprint to know if anything has changed. Tokenizer files can be swapped or altered without visible errors.
If skipped: A malicious or corrupted tokenizer could sneak into your pipeline, silently inflating costs or weakening guardrails, and you might not notice until the system is already in production.
- Add statistical checks
→ Keep a small calibration set of sentences in multiple languages
→ Record the normal average tokens per character and tokens per word
→ Run this check regularly. Alert if drift goes beyond 10% – 15% percent
Why: Token inflation is visible as a jump in tokens per character. A baseline helps you catch anomalies quickly.
If skipped: Even if file hashes change, you may not realize the impact. Costs can triple overnight and only show up later in API bills or CPU dashboards.
- Monitor in production
→ Track how many characters and tokens each request uses
→ Alert on sudden jumps in tokens-per-character, CPU per request, or tokenizer latency
→ Break these metrics down by language to catch unfair changes
Why: Even if checks in CI pass, live systems face real-world traffic that may expose hidden issues. Monitoring catches cost spikes or unfair language handling in real time.
If skipped: Token inflation may go unnoticed until customers complain or costs spiral. Multi-tenant services may see one group degrade the experience for everyone else.
- Set limits
→ Put hard caps on maximum input tokens and output tokens
→ If a request looks like it will explode into too many tokens, reject it or summarize it. This prevents denial-of-wallet attacks
Why: Limits are a safety net. They prevent attackers from flooding your system with “cheap-looking” text that becomes extremely costly after tokenization.
If skipped: Attackers can trigger denial-of-wallet attacks. CPU usage can spike, queues back up, and legitimate requests get delayed or dropped.
- Secure the supply chain
→ Only download models and tokenizers from trusted sources
→ Require code review and signing for any internal tokenizer change
→ Treat a tokenizer update with the same caution as a code dependency update
Why: Most tokenizer problems begin in the supply chain. Controlling provenance and approval stops accidental or malicious drift at the source.
If skipped: You risk pulling in a poisoned tokenizer from the internet or merging an unreviewed change internally. That opens the door to silent cost traps and safety bypasses.
- Separate tokenization from serving
→ If possible, run tokenization in a controlled service that has its own monitoring and limits
→ This makes it easier to see token inflation before it reaches the model backend
Why: Separation makes it easier to detect anomalies early, before they hit the expensive inference stage.
If skipped: Token inflation directly impacts generation. Your model servers burn more CPU and memory without clear visibility into the root cause.
Takeaway for decision makers
A tokenizer is not supposed to change often. If it does, there must be a documented reason. For leaders, the important part is knowing what measurable signs indicate trouble:
Operational and cost signals to watch:
- Token efficiency: Watch the ratio of characters per token. A sudden jump (for example, English text going from ~4 chars/token down to 1–2 chars/token) signals token inflation.
- Cost per request: If your cloud bills rise without a matching increase in traffic, it may not be user growth but hidden token drift.
- Context shrinkage: Users may complain that conversations get cut off earlier or that longer documents can no longer be processed.
- CPU and latency trends: Rising CPU per request, longer tokenization latency, or more autoscaling events without traffic growth are red flags.
- Language disparity: If certain languages become slower or more expensive to process, check whether the tokenizer is at fault.
Security and safety signals to watch:
- Format anomalies: Outputs suddenly containing tool-call markers, JSON blobs, or fenced tokens that look like structured commands.
- Response shifts: Model replies changing tone or intent after a deployment, even though weights and prompts were untouched.
- Provenance gaps: Automated actions running without clear confirmation of where the trigger came from (user vs system).
TL;DR – Treat unexpected cost spikes, CPU inflation, or language complaints as well as sudden shifts in model responses or tool triggers as possible signs of tokenizer drift. Ask your teams to prove tokenizer stability with hashes, calibration tests, runtime monitoring, and response audits.
Conclusion
The tokenizer drift is not just a theoretical problem. It is a real supply-chain and operational risk that affects both economics and security, and its impact depends on where your models come from and how they are used.
Major LLM providers with closed systems are likely aware of this issue. They control their own tokenizers, keep them stable, and enforce internal guardrails to prevent silent drift. For customers of those platforms, the risk is lower, though monitoring costs, fairness, and unexpected response patterns is still worth doing.
The bigger risk lies with open-source and self-hosted models. Tokenizers from public hubs are not always verified, and subtle changes can slip in without warning. Companies that customize their own tokenizers for business reasons, such as adding domain-specific tokens, must also be cautious: even small edits can raise cloud bills, slow systems, shrink context, or cause models to emit outputs that look like unintended confirmations or tool-calls.
The lesson is clear. In closed ecosystems, trust but verify costs and behaviors. In open or self-managed setups, treat tokenizer stability as of utmost governance concern, covering both cost control and security safety. Hashes, calibration tests, runtime monitoring, and response audits are not optional, they are the only way to catch drift before it grows into operational or security pain.
Risk Differentiation
| Source | Likely risk level | Cost & performance risks | Security & response risks | What to do |
|---|---|---|---|---|
| Closed LLM providers (e.g., major API vendors) | Low | Tokenizers are controlled by the vendor. Cost increases are unlikely but still possible if upstream changes occur | Security risk is lower but watch for unexpected output patterns in sensitive workflows. | Monitor costs, latency, and response formats; verify anomalies with provider |
| Open-source models from public hubs | High | Tokenizers may be tampered with or drift across versions, causing inflated token counts, CPU spikes, and context shrinkage | Malicious uploads can alter normalizers or templates, leading to manipulated responses or unintended tool calls | Hash & sign files, run calibration tests, validate special tokens, and review normalizer diffs |
| Custom internal tokenizers | Medium to high | Domain token additions may cause unforeseen cost or latency overhead if merges are altered. | Even small edits can make models emit outputs that look like confirmations or commands, creating operational or security blind spots | Document changes, run regression tests on both cost and response behavior, and add monitoring for structured outputs |
Like it? Add this infographic to your site:
1. Click on the box below. 2. Press Ctrl+A to select all. 3. Press Ctrl+C to copy. 4. Paste the code into your page (Ctrl+V).
Image will appear the same size as you see above.
Messages récents
- TrendAI™ 2026 Cyber Risk Report
- The Hidden Risk in Your AI Rollout: Your Endpoints
- When AI Becomes a Zero-Day Machine: What Public Sector Organizations Need to Know
- A Data-Driven View of Cyber Risk Structure: How Attack Pressure and Exposure Shape Damage
- Hunt Them All: An AI-Powered Vulnerability Sweep of 19,000 MCP Servers
 Fault Lines in the AI Ecosystem: TrendAI™ State of AI Security Report
Fault Lines in the AI Ecosystem: TrendAI™ State of AI Security Report It’s By Design: The Use-After-Free of Azure Cloud
It’s By Design: The Use-After-Free of Azure Cloud TrendAI™ 2026 Cyber Risk Report
TrendAI™ 2026 Cyber Risk Report Guarding LLMs With a Layered Prompt Injection Representation
Guarding LLMs With a Layered Prompt Injection Representation