By Stephen Hilt (Senior Threat Researcher, TrendAI™ Research)
Key takeaways
- TrendAI™ formalizes threat attribution as a structured, repeatable discipline by combining standardized evidence scoring, relationship mapping, and bias testing, with a temporary stage that separates clustering from final naming.
- Our approach reduces the risk of misattribution, hype-driven labels, and unstable actor names that can mislead defenders, distort risk prioritization, and trigger inappropriate response actions.
- Rigor in analysis enables organizations to make confident, defensible decisions about risk, attribution, and incident response when facing complex threats or repeated attacks.
Introduction
Attribution is one of the hardest parts of threat intelligence. Many actors use the same tools, share infrastructure, and blend into the noise of the internet. Without a structured approach, it becomes too easy to rely on assumptions, selective evidence, or whatever name another vendor already uses.
TrendAI™ (a business unit of Trend Micro) has applied structured attribution methods across investigations for many years. What’s outlined here is a high-level view of that approach, intended to clarify how we form attribution conclusions and to provide context for the intelligence we publish, rather than to document every internal detail.
In practice, we follow a method that is practical for real investigations. We use an adapted version of the Diamond Model — an established cybersecurity framework for identifying threat actors; analyzing their tactics, techniques, and procedures (TTPs); and structuring responses to active cyber incidents — to organize what we know about an intrusion. We apply an evidence-based scoring system to measure the strength of each piece of information. We also challenge our own conclusions by testing them against alternative explanations, a process based on analysis of competing hypotheses (ACH).
The result is a workflow that is consistent, transparent, and defensible, focusing on what the actor does over time. This framework helps us track activity clusters early, refine them as evidence develops, and assign final names only when the data can truly support it. Through this process, TrendAI™ analyzes active campaigns observed daily, performs attribution to link them to specific threat actors, and delivers actionable intelligence such as TTPs and indicators of compromise (IoCs) through TrendAI Vision One™ Threat Intelligence Hub to enable more efficient threat hunting.
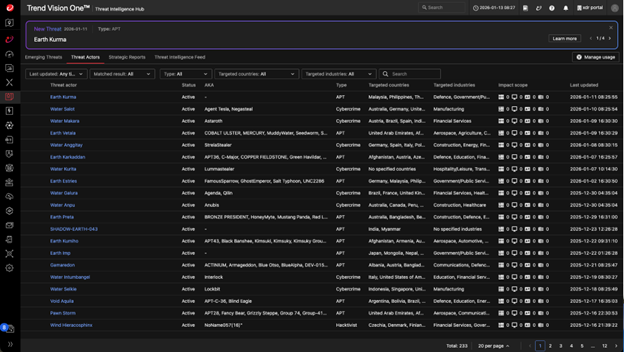
Figure 1. A snapshot of TrendAI Vision One™ Threat Intelligence Hub
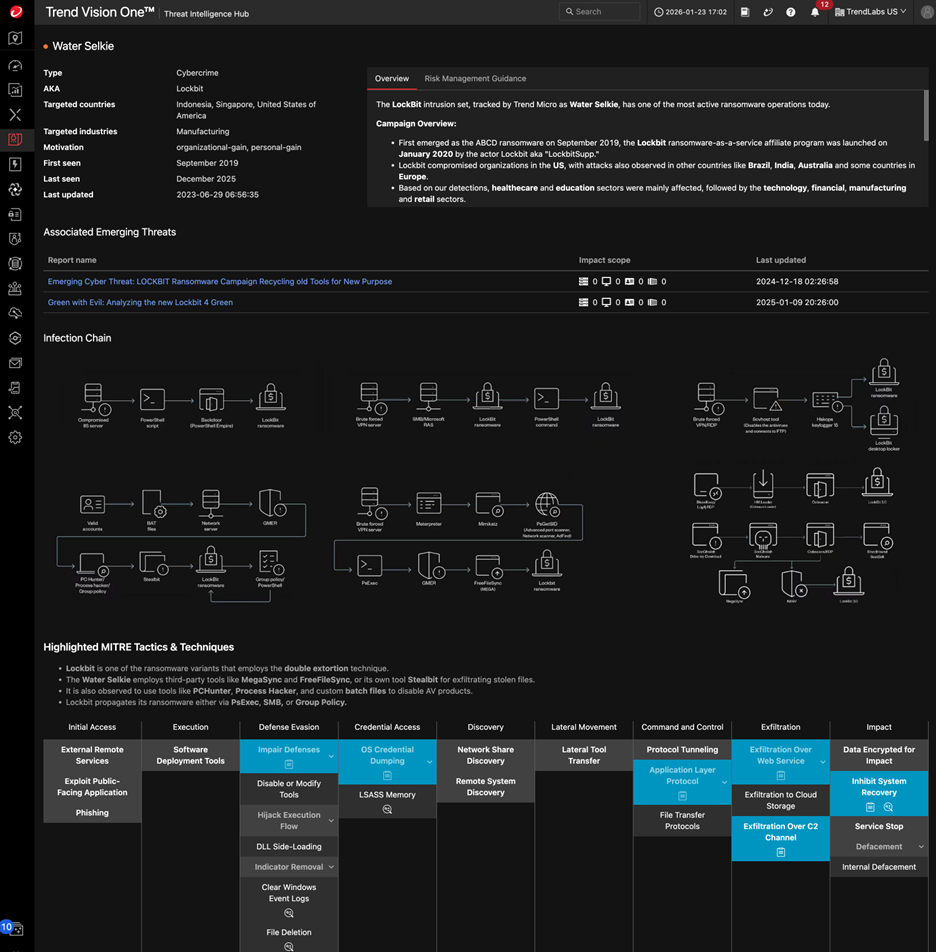
Figure 2. A snapshot of a threat actor’s profile on Threat Intelligence Hub
A brief introduction to the Diamond Model
Threat attribution is rarely about a single indicator. The Diamond Model provides a simple structure for thinking about intrusions by breaking activity into four core components: adversary, capability, infrastructure, and victim. Instead of focusing only on tools or indicators, the model forces analysts to consider who is behind the activity, how they operate, what they use, and whom they target.
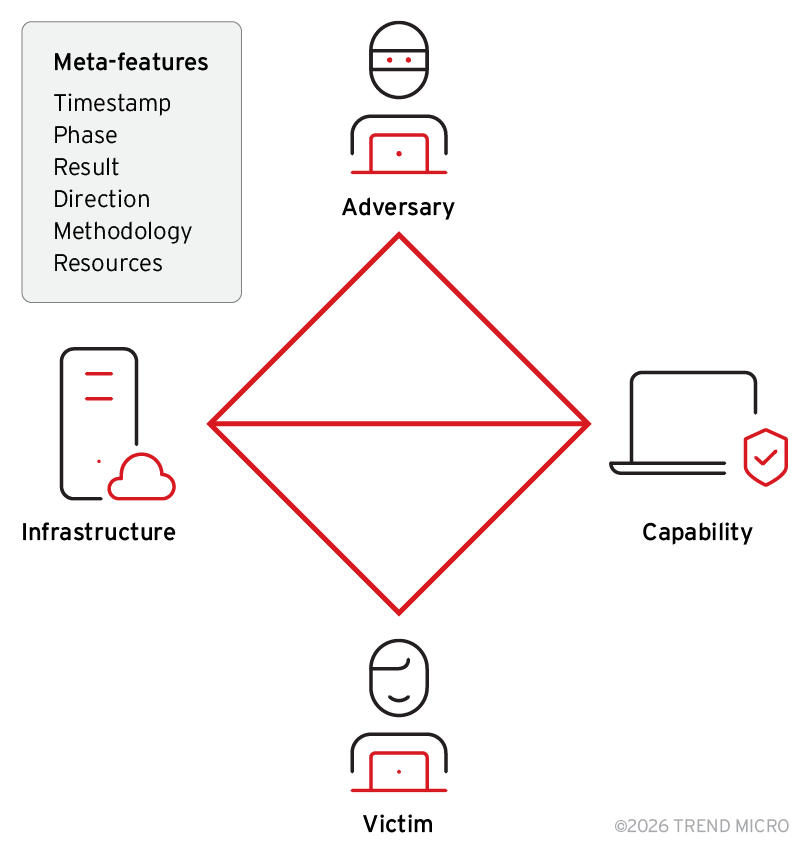
Figure 3. An illustration of the core, interdependent elements of the Diamond Model of intrusion analysis, alongside relevant meta-features used to contextualize incidents (adapted from “The Diamond Model of Intrusion Analysis”)
We use the Diamond Model because it supports relationship-based analysis. When multiple incidents share patterns across these four nodes, confidence begins to form. A single IoC might explain an intrusion, but consistent behavior across multiple diamond nodes is what supports attribution. The model gives us a common language and a consistent way to map evidence as investigations evolve.
Attribution starts with the Diamond Model
Attribution works when the evidence lines up from more than one artifact. A single IoC is not attribution, and multiple IoCs might not even be enough for attribution. Any actor can reuse infrastructure, buy malware, or copy lures. TrendAI™ uses the Diamond Model to give us a structured way to anchor observations in four areas at the same time. It forces the analyst to look at the adversary, capabilities, infrastructure, and victims as a connected system rather than isolated artifacts.
The Diamond Model makes the work more repeatable. Analysts might have different backgrounds or workflows, but using the model gives a shared structure for turning raw evidence into a hypothesis with clear support. When we apply scoring on top of it, we end up with a confidence level tied to evidence, not individual opinions. The Diamond Model is the baseline for how TrendAI™ builds clusters, creates a temporary naming scheme, and eventually reaches a named intrusion set.
Analysts need a way to prioritize evidence
Strong attribution comes from weighting evidence correctly. Not all evidence carries the same weight, and effective attribution depends on separating high-value intelligence from disposable indicators. Treating all evidence equally creates noise and weakens conclusions. This is especially important because deception is expected. Threat actors plant false flags, reuse shared infrastructure, mimic other groups, and rely on commodity or open-source tooling, so attribution scoring must assume that some signals are intentionally misleading rather than informative.
Attribution confidence comes from signals that persist over time. Certain behaviors, tooling patterns, infrastructure choices, or victim logic recur across campaigns, even as payloads and surface details change. Quantifying evidence quality through consistent scoring prevents analysts from overvaluing noise or intuition, helps challenge assumptions, and keeps the focus on signals that genuinely strengthen the overall attribution case rather than isolated data points that do not move it forward.
How TrendAI™ derives default evidence scores
Default scores are meant to give analysts a consistent starting point, having each analyst be the same each time with evidence. Each type is evaluated against four criteria that focus on where the data comes from, how well it connects to the actor, whether the behavior reflects long-term intent, and if it appears across more than one campaign. This keeps scoring tied to actor behavior instead of isolated technical evidence.
Evidence scoring scales
The scoring system uses two scales, following the Admiralty System adapted for cybersecurity, as shown in Table 1. One measures how much we trust the source of the evidence, while the other measures how strongly the information connects to the actor or operation.
Reliability (A–F)
| Code | Description |
|---|---|
| A | Completely reliable |
| B | Usually reliable |
| C | Fairly reliable |
| D | Not usually reliable |
| E | Unreliable |
| F | Reliability cannot be judged |
Credibility (1–6)
| Code | Description |
|---|---|
| 1 | Confirmed by other sources |
| 2 | Probably true |
| 3 | Possibly true |
| 4 | Doubtful |
| 5 | Improbable |
| 6 | Truth cannot be judged |
Table 1. How the Admiralty System grades information based on multiple reports of the same observation received over time
Source reliability
Where the data came from affects its trust level. Internal telemetry is the strongest indicator because we can validate it directly. Verified researcher findings or other vendor intelligence can also be used when there is enough context to assess quality. Unvetted open-source intelligence (OSINT) is low in reliability because it can be incomplete or biased without supporting evidence. Confirmations from multiple sources also affects reliability. The source matters because weak sourcing can distort attribution of confidence.
Information credibility
Credibility checks whether the artifact genuinely ties to the actor. One-time infrastructure, especially shared hosting or disposable IPs, has low attribution value because it does not represent a long-term operator’s decision. Custom tooling, build paths, and configuration choices are stronger because they reflect how the actor works. Credibility is about whether the data is a real signal of the actor, not just something observed during an incident.
Why we prescore certain types of evidence
A consistent scoring baseline allows analysts to evaluate common types of evidence efficiently. Familiar artifacts, such as domains or infrastructure patterns, do not need to be rescored each time they appear, which speeds up investigation and reduces repetitive analysis. This lets analysts focus on interpretation and correlation, and prevents different analysts from reaching different conclusions when working with the same evidence.
By making the evidence quality explicit, baseline scoring reduces subjectivity and bias. Without it, analysts might overvalue familiar artifacts or give undue weight to technical indicators that offer little attribution value. For example, a single IPv4 address is prescored as D4 because IPs are frequently reused, dynamically assigned, or rented across unrelated operations. This separates low-confidence artifacts from stronger signals, such as custom tooling or persistent tradecraft, helping maintain consistency across cases.
Scores remain fixed and are not adjusted during analysis. Attribution confidence is built by stacking and correlating evidence across the Diamond Model, not by tuning individual artifacts. Indicators that are easily spoofed, short-lived, or commonly reused begin with lower scores, while evidence tied to sustained behavior starts higher. Table 2 illustrates how common artifact types are prescored to establish a repeatable baseline before contextual analysis is applied.
| Artifact | Diamond node | Score | Rationale |
|---|---|---|---|
| IPv4 address | Infrastructure | D4 | IP addresses are commonly shared, dynamic, or rented. A single IP rarely represents long-term actor ownership without corroboration. |
| Custom malware loader | Capabilities | A2 | Custom tooling requires development effort and often persists across campaigns, making it a strong indicator of actor capability. |
| Actor handle reused across forums | Adversary | B2 | Handles may persist across infrastructure and communities but require corroboration to rule out impersonation or resale. |
| Consistent targeting of a specific sector | Victim | B2 | Repeated victim selection reflects strategic intent but does not uniquely identify an actor on its own. |
Table 2. Examples of prescoring common artifacts to establish a repeatable baseline prior to contextual analysis
Hybrid scoring model (three combined inputs)
Admiralty-style scoring converts qualitative judgment into numeric weight. Subjective inputs, such as reliability and credibility, become measurable factors, which allow the same scoring logic to be applied consistently without relitigating why an A2 carries more weight than a D4. This creates repeatability while preserving the ability to explain how evidence contributes to attribution confidence.
Evidence is then organized and tested rather than accepted at face value. Grouping artifacts through the Diamond Model shows where confidence is supported across adversary, capabilities, infrastructure, and victims, and where gaps remain. Analysis of competing hypotheses (ACH) forces analysts to challenge their own assumptions by building and testing the strongest alternative explanation. If competing theories cannot be ruled out with evidence, confidence does not advance. The outcome is a structured confidence score paired with a defensible narrative, where the score enforces consistency, and the narrative explains why it is justified.
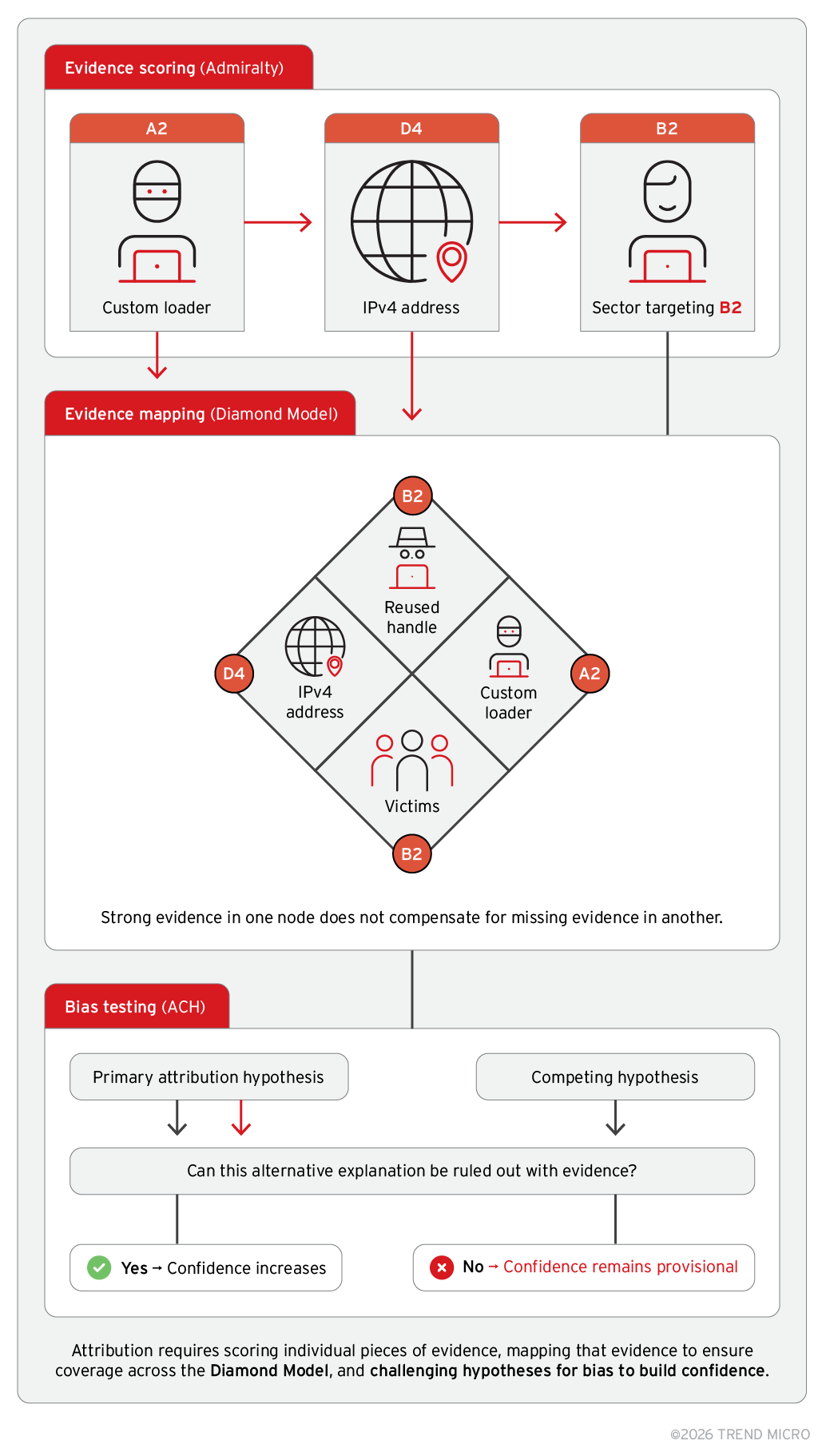
Figure 4. The hybrid attribution scoring model that uses a structured workflow combining Admiralty evidence scoring, Diamond Model mapping, and bias testing using ACH
Why this matters: Naming threats without rigor causes misattribution and creates risks
Attribution is not a single artifact or an IoC. It is the outcome of structured analysis supported by multiple independent evidence points. The Diamond Model gives us a consistent way to map an intrusion across adversary, capability, infrastructure, and victim nodes. When evidence aligns across several nodes, confidence increases. When it does not, we keep the activity in a temporary phase instead of forcing a conclusion.
Analysts need a way to organize clusters of related activity without committing to a final named intrusion set too early. Many intrusions look similar in the early phase. Shared tooling or a reused virtual private server (VPS) alone does not justify a new intrusion set name. The temporary phase allows us to track clusters, add new evidence over time, test assumptions, and build the confidence needed for a formal decision.
TrendAI™ uses a temporary naming scheme called SHADOW. It has the format SHADOW-ELEMENT-NUMBER, where “Element” reflects the motivation using the same structure as our final naming convention. A SHADOW cluster is not a claim of attribution. It is a controlled label for an activity cluster that requires continued investigation, collection, and analysis until enough evidence exists across multiple Diamond Model nodes to justify a formal name.
Final intrusion set naming uses the established naming convention of TrendAI™. The final name has two parts:
- 1. Classical Element based on the observed motivation
- 2. Mythical Creature Name from our internal list
The element encodes the actor’s motivation based on consistent criteria. The creature is selected from an approved list to avoid overlap, geographic associations, or direct national symbolism. This produces a unique, memorable, stable actor name that does not depend on third-party naming.
Naming decisions are based on evidence across multiple Diamond nodes, not a single source. Promotion from temporary to full naming requires repeatable, long-term signals, such as custom tooling reuse, infrastructure persistence, consistent targeting, and credible adversary indicators. A review board evaluates the evidence, tests internal scoring metrics, challenges assumptions, and tests alternative explanations before approving a name. This prevents hype-driven attribution and ensures that the outcome is defensible.
The structure allows analysts to debate the data, refine the model, and improve the framework as we learn more. The model reduces bias by forcing a logical chain of reasoning supported by normalized evidence of weighting and a consistent interpretation of what qualifies as attribution-relevant data.
TrendAI™ naming convention
Table 3 defines the motivation element, the SHADOW format, and the final intrusion set naming format. This is the same structure used across SHADOW clusters and named actors.
| Element name | Motivation description |
|---|---|
| Earth | Espionage, state-directed intelligence collection |
| Water | Financially motivated operations, including extortion, theft, and monetization |
| Fire | Destructive or disruptive objectives, including sabotage or wiping operations |
| Wind | Hacktivism or ideological influence campaigns without direct economic or geopolitical objective |
| Aether | Unknown motivation without clear economic or espionage objective; only used for temporary SHADOW names |
| Void | Mixed motivation where operations truly overlap with two or more of the first four elements |
Table 3. Motivation elements and the standardized formats used for both SHADOW clusters and intrusion set names
Creatures are selected from an internally maintained list to prevent reuse and prevent ties to specific countries, cultures, or national symbolism. SHADOW names use the same motivation element but replace the creature with a numeric identifier. This allows internal tracking of an activity cluster without committing to a final actor naming.
Consider the format SHADOW-ELEMENT-NUMBER. For example, a cluster showing repeated targeting of government agencies with custom malware, but without enough insight for a named intrusion set designation, may be tracked as SHADOW-EARTH-007. The Element (EARTH) reflects the espionage motivation. The number (007) is sequential across all motivations and does not imply scale, capability, lineage, or actor maturity.
If later analysis produces high confidence across multiple Diamond Model nodes and the review board agrees, the activity could be promoted and assigned a final intrusion set name, such as Earth Demon.
Figure 5. A snapshot of emerging threat reports on Threat Intelligence Hub
Conclusion
Attribution is a process, not a guess. The goal is to reach a defensible outcome based on repeatable methods rather than intuition. The Diamond Model provides a consistent way to organize evidence, while evidence-based scoring helps analysts separate durable signals from noise. The SHADOW naming allows activity to be tracked without forcing a final intrusion set designation before the evidence is ready.
We’ve published this framework to bring greater clarity to how attribution decisions are made, why naming varies across the industry, and why evidence matters more than labels. What’s presented here is a distilled view of a broader internal framework, focused on the principles and decision logic most relevant for external discussion.
For business leaders, frameworks such as this matter, as attribution influences how risk decisions are made and defended. When threat actor names are treated as facts, it creates a false sense of certainty that can skew priorities and weaken response planning. If those decisions are later challenged by boards, auditors, or regulators, a label on its own is not enough. An evidence-based approach gives leaders something more solid to rely on, rooted in what can be proven rather than assumed and, critically, in transparent processes that show how conclusions were reached, what confidence level applies, and where uncertainty remains. This clarity builds trust in attribution decisions and makes them far easier to explain, defend, and adapt as new information emerges.
As actors evolve their tradecraft, attribution signals change. New tooling, shared infrastructure, and access to commercial zero-day vulnerabilities continue to complicate analysis. While the framework adapts as we learn, its structure remains the anchor for how TrendAI™ performs attribution in investigations.
By following structured attribution models, Threat Intelligence Hub provides evidence-based, reliable attribution that enables organizations to hunt threats with greater confidence. At the time of publishing this article, TrendAI™ delivers intelligence on more than 550 emerging threats and performs attribution for these campaigns, linking them to over 230 identified intrusion sets. Integrating Threat Intelligence Hub into security operations allows organizations to accurately identify relevant campaigns and actors, perform precise threat hunting, and assess defensive capabilities against specific threats.
Bibliography
The following works informed the development of TrendAI™’s threat attribution framework. They reflect the evolution of structured analysis in threat intelligence, including the Diamond Model, analytic standards, and vendor methodologies. The framework described in this document is TrendAI™’s implementation and does not reproduce these sources directly.
- William Banks. (2021). International Law Studies, U.S. Naval War College. “Cyber Attribution and State Responsibility.” Accessed on Feb. 6, 2026, at: Link.
- Edmund Brumaghin et al. (May 13, 2025). Cisco Talos. “Defining a new methodology for modeling and tracking compartmentalized threats.” Accessed on Feb. 6, 2026, at: Link.
- Sergio Caltagirone. (2013). ThreatIntel.Academy. “Diamond Model Summary.” Accessed on Feb. 6, 2026, at: Link.
- Sergio Caltagirone, Andrew Pendergast, and Christopher Betz. (2013). Active Response. “The Diamond Model of Intrusion Analysis.” Accessed on Feb. 6, 2026, at: Link.
- Rachel Anne Carter and Julian Enoizi. (March 2021). The Geneva Association. “Mapping a Path to Cyber Attribution Consensus.” Accessed on Feb. 6, 2026, at: Link.
- Jamie Collier and Shanyn Ronis. (Jan. 17, 2023). Google Cloud Blog. “Navigating the Trade-Offs of Cyber Attribution.” Accessed on Feb. 6, 2026, at: Link.
- Cooperative Cyber Defence Centre of Excellence (CCDCOE). (2025). CCDCOE. “International Cyber Law Toolkit: Attribution.” Accessed on Feb. 6, 2026, at: Link.
- dennismercer. (Nov. 8, 2023). Microsoft Defender Threat Intelligence Blog. “Using MDTI with the Diamond Model for Threat Intelligence.” Accessed on Feb. 6, 2026, at: Link.
- Florian Egloff and Max Willem Eline Smeets. (2023). ETH Zürich. “Publicly Attributing Cyber Attacks: A Framework.” Accessed on Feb. 6, 2026, at: Link.
- Lorraine Finlay and Christian Payne. (2019). ResearchOnline@ND. “The attribution problem and cyber armed attacks.” Accessed on Feb. 6, 2026, at: Link.
- Richards J. Heuer, Jr. (1999). Central Intelligence Agency. “Psychology of Intelligence Analysis.” Accessed on Feb. 6, 2026, at: Link.
- Rick Howard. (March 17, 2015). Palo Alto Networks. “Attribution is Hard to Do – But Necessary to Evaluate Risk.” Accessed on Feb. 6, 2026, at: Link.
- Anastasiya Kazakova et al. (May 2022). UN Office for Disarmament Affairs (UNODA). “‘Unpacking’ technical attribution and challenges for ensuring stability in cyberspace.” Accessed on Feb. 6, 2026, at: Link.
- Eric F. Mejia. (Feb. 14, 2013). U.S. Department of Defense Defense Technical Information Center. “Act and Actor Attribution in Cyberspace: A Proposed Analytic Framework.” Accessed on Feb. 6, 2026, at: Link.
- Office of the Director of National Intelligence (ODNI). (Jan. 2, 2015). Federation of American Scientists Intelligence Resource Program. “ICD-203: Analytic Standards.” Accessed on Feb. 6, 2026, at: Link.
- Office of the Director of National Intelligence (ODNI). (Jan. 22, 2015). Federation of American Scientists Intelligence Resource Program. “ICD-206: Sourcing Requirements for Disseminated Analytic Products.” Accessed on Feb. 6, 2026, at: Link.
- Andy Piazza et al. (July 31, 2025). Unit 42 by Palo Alto Networks. “Introducing Unit 42’s Attribution Framework.” Accessed on Feb. 6, 2026, at: Link.
- Nilantha Prasad et al. (October 2025). ScienceDirect. “A survey of cyber threat attribution: Challenges, techniques, and future directions.” Accessed on Feb. 6, 2026, at: Link.
- Venkata Sai Charan Putrevu et al. (June 14, 2023). ACM Digital Library. “A Framework for Advanced Persistent Threat Attribution using Zachman Ontology.” Accessed on Feb. 6, 2026, at: Link.
- Nanda Rani, Bikash Saha, and Sandeep Kumar Shukla. (July 1, 2025). ACM Digital Library. “A comprehensive survey of automated Advanced Persistent Threat attribution: : Taxonomy, methods, challenges and open research problems.” Accessed on Feb. 6, 2026, at: Link.
- Thomas Rid and Ben Buchanan. (2015). Journal of Strategic Studies. “Attributing Cyber Attacks.” Accessed on Feb. 6, 2026, at: Link.
- SOCFortress. (Aug. 4, 2025). Medium. “Palo Alto Unit 42’s Attribution Framework.” Accessed on Feb. 6, 2026, at: Link.
- Viktor Szulcsányi and Sándor Magyar. (Sept. 15, 2025). Research Square. “A comparative analysis of threat models in the context of cyber threat attribution.” Accessed on Feb. 6, 2026, at: Link.
- David Tidmarsh. (Nov. 7, 2023). EC-Council. “What is the Diamond Model of Intrusion Analysis?” Accessed on Feb. 6, 2026, at: Link.
- Nicholas Tsagourias and Michael Farrell. (2020). White Rose Research Online. “Cyber Attribution: Technical and Legal Approaches and Challenges.” Accessed on Feb. 6, 2026, at: Link.
- Kelli Vanderlee. (Dec. 17, 2020). Google Cloud Blog. “DebUNCing Attribution: How Mandiant Tracks Uncategorized Threat Actors.” Accessed on Feb. 6, 2026, at: Link.
Like it? Add this infographic to your site:
1. Click on the box below. 2. Press Ctrl+A to select all. 3. Press Ctrl+C to copy. 4. Paste the code into your page (Ctrl+V).
Image will appear the same size as you see above.
- The Hidden Risk in Your AI Rollout: Your Endpoints
- When AI Becomes a Zero-Day Machine: What Public Sector Organizations Need to Know
- A Data-Driven View of Cyber Risk Structure: How Attack Pressure and Exposure Shape Damage
- Hunt Them All: An AI-Powered Vulnerability Sweep of 19,000 MCP Servers
- Pwning Agentic AI Part I: Your AI Agent Is Already Compromised
 Fault Lines in the AI Ecosystem: TrendAI™ State of AI Security Report
Fault Lines in the AI Ecosystem: TrendAI™ State of AI Security Report It’s By Design: The Use-After-Free of Azure Cloud
It’s By Design: The Use-After-Free of Azure Cloud Ransomware Spotlight: Agenda
Ransomware Spotlight: Agenda Guarding LLMs With a Layered Prompt Injection Representation
Guarding LLMs With a Layered Prompt Injection Representation