Malware
Smart Whitelisting Using Locality Sensitive Hashing
In 2013, we open sourced an implementation of LSH suitable for security solutions: Trend Micro Locality Sensitive Hashing (TLSH). TLSH is an approach to LSH, a kind of fuzzy hashing that can be employed in machine learning extensions of whitelisting.


Save to Folio
By Jon Oliver and Jayson Pryde
Locality Sensitive Hashing (LSH) is an algorithm known for enabling scalable, approximate nearest neighbor search of objects. LSH enables a precomputation of a hash that can be quickly compared with another hash to ascertain their similarity. A practical application of LSH would be to employ it to optimize data processing and analysis. An example is transportation company Uber, which implemented LSH in the infrastructure that handles much of its data to identify trips with overlapping routes and reduce inconsistencies in GPS data. Trend Micro has been actively researching and publishing reports in this field since 2009. In 2013, we open sourced an implementation of LSH suitable for security solutions: Trend Micro Locality Sensitive Hashing (TLSH).
TLSH is an approach to LSH, a kind of fuzzy hashing that can be employed in machine learning extensions of whitelisting. TLSH can generate hash values which can then be analyzed for similarities. TLSH helps determine if the file is safe to be run on the system based on its similarity to known, legitimate files. Thousands of hashes of different versions of a single application, for instance, can be sorted through and streamlined for comparison and further analysis. Metadata, such as certificates, can then be utilized to confirm if the file is legitimate.
TLSH is also built with proactive collaboration in mind. We have provided open-source tools to help study, evaluate, and further improve TLSH. We also have a regularly updated backend query service that independent security researchers and partners can use to query and compare their files for their similarity to known, good files.
Our researches showed that compared to other open-source versions of LSH, TLSH is a highly accurate similarity digest, more flexible in its range, less vulnerable to attacks, and enables a quick search mechanism. TLSH also supports Linux, Windows (Visual Studio), and Python Extension environments.
How TLSH can Help Enterprises
Identifying safe applications and files for their environment is an important task for any enterprise. This is typically done by IT and system administrators who might use methods such as whitelisting (comparing against a known list of good files), or using certificates. These approaches have limitations though; whitelisting solutions may not have a complete list of good files. Keeping up with rapid changes on a legitimate file can also be challenging, and is a known issue with whitelisting solutions. On the other hand, relying only on certificates can create security holes since a certificate infrastructure can also be compromised.
Enterprises can categorize files as:
- [Group WL]: Files which are on the whitelist.
- [Group TC]: Files with a certificate signed by a trusted software vendor.
Enterprises can adopt certain policies such as:
A. Only allow the execution of files in Group WL.
B. Only allow the execution of files (in Group WL OR in Group TC ).
Policy A may be too restrictive; files and security updates may be present, which may not be on the whitelist. Policy B may be problematic, given how certificate issuers may be abused (malware can be signed by trusted certificate issuers), or how a certificate infrastructure can be compromised.
TLSH allows us to define another group of files:
- [Group TLSH]: Files that are similar to files on the whitelist, and signed by the same certificate signer as the related file.
Group TLSH may still contain malware in that malicious components can be inserted into legitimate applications. A similarity test can be combined with metadata, such as trusted certificate signers, to determine a suitable set of software to allow. This results in a new policy:
C. Only allow the execution of files (in Group WL OR in Intersection [Group TLSH, Group TC])
When added to whitelisting systems, TLSH can intuitively keep pace with a software’s fast turnaround of patches and version releases. This provides a more efficient way for organizations to keep their systems updated, while also significantly reducing false alarms.
In a nutshell, TLSH saves enterprises from having to compare new hashes of an updated version of certain software with other hashes of good files that can be executed in the system. To further demonstrate: in one of our research projects, we were able to streamline querying an application/software with over 50 versions and tens of thousands of unique hashes into a hash value generated by TLSH, which we then confirmed to be a good file that can be safely run on the system by analyzing its digital certificate.
Here, we detail how TLSH works, how it stacks up, and how it can help further secure an enterprise’s perimeter:
Trend Micro Locality Sensitive Hashing (TLSH): An Overview
TLSH helps detect and inspect files that are on, or introduced to, computers. It can be utilized to ensure that only legitimate applications or documents can be run, opened, or saved on the system. TLSH provides a mechanism for promptly comparing the similarity digests of unknown files with a searchable repository of similarity digests of known, legitimate, and allowable files. The idea behind similarity digests is to enable a reliable measure of correlation in terms of identifying similar and unique features on each version of a particular file.
This functionality is organized into these layers:
- Similarity digest computation. This provides the means to calculate similarity digests for given files, and compares pairs of digests to get similarity, or “distance scores”. Distance score values may range from 0 to 2000, and these “scores” represent the mathematical distance between two similarity digests. The smaller the score (or distance), the greater the similarity between two original files. A distance score of 0 means the files are essentially identical.
- Scalable similarity digest search mechanism. This functionality provides an immediate way to search, crosscheck, and confirm similarities of unknown or suspicious files to a given set of similarity digests of known, legitimate files. This search mechanism must also scale. As very large amounts of digests of known, legitimate files are added to the repository, an acceptably low search time should also be maintained. TLSH uses a search mechanism that can scale to tens of millions (and more) of similarity digests.
Applications can be implemented using TLSH as a local service (Figure 1) running on a computer that does its own similarity digest searches and comparisons. It can also be a web service (Figure 2) that handles the search and comparison operations on behalf of the computer system.
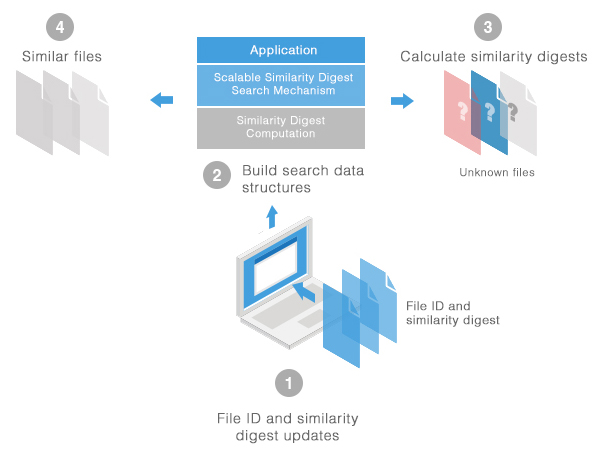
Figure 1: TLSH on a local computer operation
When run as a local service, the system receives a set of similarity digests and corresponding file identification of a set of known, legitimate files. The similarity digest search mechanism then builds an index. The similarity digest application will calculate the digests for incoming unknown files. The application then uses the index to perform an approximate nearest neighbor search of the data repository.
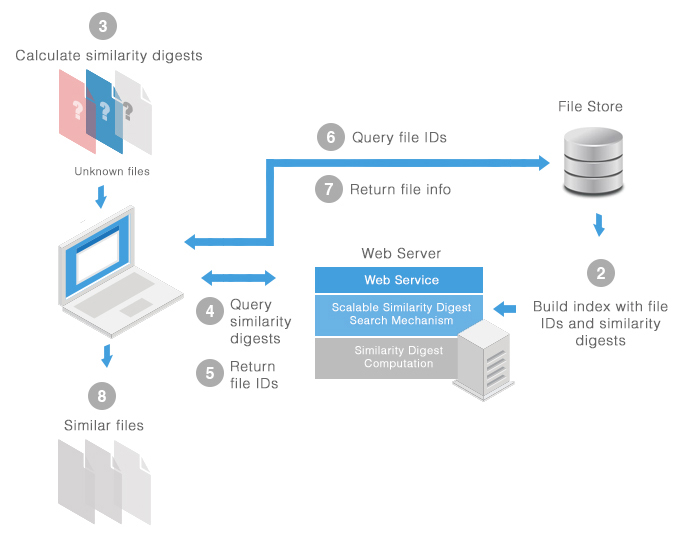
Figure 2: TLSH on a web service operation
TLSH running as a web service is slightly different. Known, legitimate files are first added to a basic file system store on a web server. The similarity digest search mechanism calculates the digests for all the files in the store, and creates the index. The system calculates the digests for incoming unknown files using the same similarity digest computation layer that runs on the web server. The similarity digest of each unknown file is then submitted to the web server where the web service application on the server uses the similarity digest search mechanism to search and compare each unknown digest to digests of known, legitimate files. The file IDs corresponding to the similarity digests of known, legitimate files are then returned to the computer, which then decides what action to take for these files.
There are two optional stages that can be considered before the system takes an action. After the file IDs are returned to the computer, the system can query the file store with similar file IDs. Details of similar files corresponding to each file ID are then returned to the computer, which then determines what to do to the files.
How does TLSH Measure Up?
Legitimate computer programs constantly change—from a series of small updates to significant modifications, including patches, functionality enhancements, and corruption to their files. Any of these alterations can change the program’s hash value. This poses a challenge for most traditional whitelisting applications that compare computer programs with cryptographic hashes, such as SHA256 or MD5, with a database of known good hashes. A threat actor, for instance, can deploy malware by surreptitiously inserting malicious code in a file or program with a hash value that's similar to its legitimate counterpart.
TLSH addresses these by analyzing the program with a data score of similarity digests and determine that it is a good file (being an exact match). It if is relatively similar to a known, legitimate program, additional tests are run to identify that the new file came from the same trusted source as the original file.
Using similarity digests for whitelisting applications already has traction, thanks to tools like SDHASH and SSDEEP. Both can be used to compute and compare sets of data for similarity of hash values. However, SDHASH and SSDEEP require a very slow and linear search. Based on our tests and analyses, SSDEEP regularly missed detections, and consequently misses identifying updates made to computer programs. SDHASH matches files with 64 bytes sequences in common, allowing it match computer programs that have areas of significant overlap (such as the use of shared libraries), but also substantially different sections.
Additionally, SSDEEP, SDHASH, and other similarity digests don’t have fast search mechanisms; incorporating them in a whitelisting system can be impractical, as it requires comparisons with up to tens of millions of legitimate computer programs. The use of an index and TLSH (with proper distance metric) allowed us to get speeds typical in regular database lookups.
Trend Micro Locality Sensitive Hashing has been demonstrated in Black Hat Asia 2017 as “Smart Whitelisting Using Locality Sensitive Hashing”, on March 30 and 31, in Marina Bay Sands, Singapore. It has also been published in peer-reviewed papers as “TLSH — A Locality Sensitive Hash” and “Using Randomization to Attack Similarity Digests”.