Cyber-Kriminalität
Aufbau der Architektur agentenbasierter KI
Um die Sicherheit agentenbasierter KI-Systeme zu verstehen, muss ihre mehrschichtige Architektur analysiert und die spezifischen Risiken jeder Schicht identifiziert werden. Wir zeigen, wie die Schichten aussehen und wo mögliche Risiken liegen.


Save to Folio
Die Komplexität der Sicherheit agentenbasierter Architekturen, bei denen jede Schicht eine maßgeschneiderte Strategie erfordert, wirft wichtige Fragen auf: Wie sieht die Architektur eines agentenbasierten KI-Systems eigentlich aus? Wie interagieren die verschiedenen Komponenten miteinander? Und noch wichtiger: Welche Sicherheitsrisiken bringt diese Struktur mit sich?
Die Gesamtstruktur agentenbasierter KI lässt sich anhand verschiedener logischer Schichten veranschaulichen:
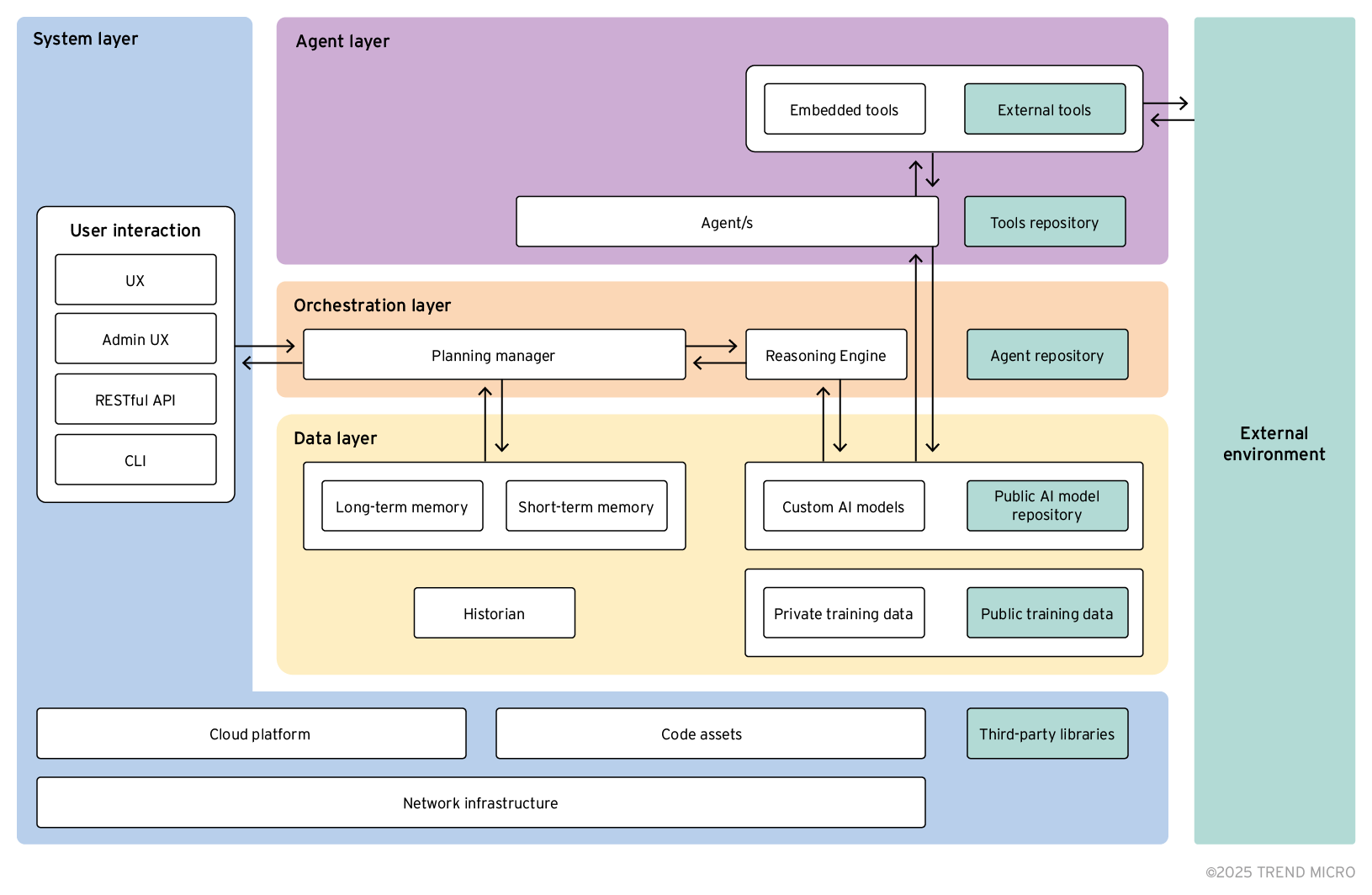
Einige der Komponenten gibt es aktuell möglicherweise noch nicht in den agentenbasierten Systemen, werden aber sehr wahrscheinlich in naher Zukunft zum Standard. Beispielsweise sind Tools und Agenten-Repositorys noch nicht in der Praxis vorhanden, doch werden Protokolle wie das Modell Context Protocol (MCP) von Anthropic für den Aufruf und die Interaktion von Tools und das Agent-to-Agent-Protokoll (A2A) von Google für die Kommunikation zwischen Agenten gerade entwickelt, so dass solche Repositorys bald auch Realität werden könnten.
Datenebene (gelb)
Diese umfasst die Datenkomponenten, die an der Entwicklung, Wartung oder Nutzung des agentenbasierten Systems beteiligt und damit einen kritischen Teil der Anwendung darstellen, der gesichert werden muss.
Dazu gehören:
- Benutzerdefinierte KI-Modelle: KI-Modelle, die für den Betrieb des agentenbasierten Systems verwendet werden, können entweder öffentlich verfügbar sein, oder es sind eigene benutzerdefinierte KI-Modelle, für die proprietäre Trainingsdaten verwendet werden, die möglicherweise anderswo nicht verfügbar sind. Der Orchestrator die Modelle zur Erstellung der Planung für eine Anfrage nutzen. Auch Agenten greifen zur Ausführung bestimmter Aufgaben darauf zurück, z. B. zur Übersetzung von Anfragen in natürlicher Sprache in spezifische Datenabfragen. Andere Modelle können Aufgaben wie Image-Recognition, Inhaltserstellung, Text-to-Speech und optische Zeichenerkennung übernehmen.
- Externe Modell-Repositorys: Öffentlich verfügbare KI-Modelle können aus einem externen Repository wie Huggingface oder NVIDIA NGC bezogen werden. Damit lassen sich die Kosten und der Zeitaufwand für ein internes Modelltraining sparen. Allerdings ist man von externen Anbietern abhängig, deren Zuverlässigkeit nicht unbedingt gewährleistet ist.
- Trainingsdaten: werden intern entweder zum Training neuer Modelle oder zur Feinabstimmung bestehender Basismodelle mit spezifischen Fachkenntnissen verwendet. Sie bilden die Grundschicht des Modellwissens und können entweder aus einer unternehmensinternen Wissensdatenbank stammen, die nirgendwo anders verfügbar ist, oder aus öffentlichen Datensätzen. Dabei besteht die Gefahr, dass große Sprachmodelle falsche oder irreführende Informationen generieren (sogenannte Halluzinationen), sodass man sich für genaue Kenntnisse nicht ausschließlich auf sie verlassen sollte. Auch erfordern Training und Feinabstimmung viel Zeit und Ressourcen und können nur in regelmäßigen Abständen durchgeführt werden.
- Speicher: Externe stellen KI-Anwendungen eine zuverlässige und aktuelle Informationsquelle zur Verfügung. Er besteht in der Regel aus einem Vektorspeicher, der Informationen, die in engem Zusammenhang mit der von der KI verarbeiteten Anfrage stehen, semantisch abruft. Durch diesen Aufbau kann das KI-System auf eine Wissensdatenbank zurückgreifen, die nicht nur zuverlässig und weniger fehleranfällig ist, sondern auch schnell und in Echtzeit aktualisiert werden kann.
- Langzeitspeicher dienen zur Speicherung von dauerhaften und allgemeinen Informationen, die für die gesamte Anwendung relevant sind, sowie zur Implementierung fortgeschrittener Funktionen wie Selbstverbesserung. Der Kurzzeitspeicher wiederum enthält Informationen, die für eine bestimmte Sitzung oder einen bestimmten Nutzer spezifisch sind, etwa Benutzereinstellungen, Sitzungsdaten und frühere Anfragen.
- Historian: ist für die Speicherung von Protokolldaten zuständig. Dazu gehören Fehler- und Debug-Meldungen im Zusammenhang mit der Anwendung sowie Aufzeichnungen über die Nutzungsaktivitäten und andere relevante Metriken. Diese Daten können für die Überwachung der Leistung und des Zustands der Anwendung oder für die Abrechnung von Bedeutung sein.
Orchestrierungsschicht (rot)
Diese Schicht umfasst Komponenten, die Nutzeranfragen analysieren und die erforderlichen Schritte zu deren Erfüllung planen. Die Arbeit wird dann von überwachten Agenten ausgeführt. Dazu gehört:
- Planungsmanager: implementiert die Geschäftslogik der agentenbasierten Anwendung und ist der erste, der bei einer Nutzeranforderung aufgerufen wird. Er definiert den Workflow (linear, reaktiv oder iterativ), erstellt den Ausführungsgraphen und verwaltet den Einsatz der Agenten, einschließlich ihrer Auswahlkriterien und der benötigten Anzahl. Außerdem legt er die Beendigungsbedingungen fest und umreißt die Kommunikationsmuster zwischen den Agenten, wie z. B. sequenziell, parallel, gegensätzlich, vernetzt oder hierarchisch. Er ist heute noch stark auf fest programmierte Workflows angewiesen, die mit Frameworks wie LangGraph oder Microsoft Autogen definiert werden. Möglich, dass sich dieses Paradigma zu einer vollständig KI-basierten Planung verschieben wird, die sich zunehmend auf eine Reasoning Engine stützt, um sowohl den Ausführungsgraphen als auch die beteiligten Agenten zu definieren.
- Reasoning Engine: arbeitet mit dem Planungsmanager zusammen und betreibt das KI-Modell, das für die Übersetzung der vom Planungsmanager stammenden Eingaben in Ausführungspläne für die Agenten verantwortlich ist. Derzeit dienen als Reasoning-Engines die Standard-KI-Modelle großer Sprachmodelle (LLMs), die für das Reasoning optimiert sind. Doch ist auch die Einführung anderer KI-Modelle denkbar.
- Agenten-Repository: Agenten werden normalerweise von dem Framework bereitgestellt, das zur Implementierung agentenbasierter Anwendungen verwendet wird, und sind statisch definiert. Microsofts Magentic-One bietet beispielsweise Agenten, die auf das Scraping von Webseiten oder die Ausführung von Code spezialisiert sind. Angesichts der vielfältigen Anforderungen realer Anwendungen verlagert sich der Bedarf hin zu On-Demand-Agenten. Daher können wir davon ausgehen, dass Agenten eine Standardschnittstelle erhalten werden, und dass sie zur Laufzeit über ein Protokoll wie Googles A2A aufgerufen werden können. Zukünftige agentenbasierte Anwendungen werden auf Agenten-Repositorys angewiesen sein, die Agenten von Drittanbietern zur Integration bereitstellen.
Agentenschicht (violett)
Sie enthält die Komponenten, die die vorher geplanten Aufgaben tatsächlich ausführen.
- Agenten: sind für die Ausführung einzelner Aufgaben und die Rückgabe ihrer Ergebnisse an die Orchestrierungsschicht oder für die direkte Koordination untereinander verantwortlich. Sie können auch mit der externen Umgebung interagieren, z. B. mit Internetressourcen oder physischen Aktuatoren wie Sensoren oder Kameras.
- Eingebettete Tools: werden lokal innerhalb der Agentenschicht ausgeführt. Einige davon sind lokale Programme, von den Agenten generierter Code, der in der lokalen Umgebung kompiliert und ausgeführt wird, oder domänenspezifischer Code, der von den Agenten generiert und an einen lokalen Interpreter übergeben wird.
- Externe Tools: bestehen aus externen oder Drittanbieter-Services, die der Agent über APIs oder externe Datenbanken mit speziellen Daten aufruft. Es gibt auch bereits standardisierte Protokolle wie das Model Context Protocol (MCP), die darauf abzielen, Tools für Agenten zugänglich zu machen.
- Tool-Repository: Agenten können auf die Repositorys zugreifen, um das für die jeweilige Aufgabe am besten geeignete Tool abzurufen, seien es Bibliotheks-Repositorys wie PyPy oder npm oder Microservice-Kataloge.
Systemschicht (blau)
Eine KI-Anwendung benötigt immer noch reguläre Softwarekomponenten, um Funktionen wie Nutzerinteraktion, Authentifizierung und Konfiguration zu gewährleisten.
- Nutzerinteraktion: Agentenbasierte KI-Anwendungen benötigen weiterhin Nutzerinteraktion, um ihre Ziele zu bestimmen, Betriebsanforderungen festzulegen, Ergebnisse zurückzugeben und ihren Plan auf der Grundlage dieser Interaktion anzupassen. Darüber hinaus sind in der Systemschicht folgende Komponenten im Einsatz:
- Code-Asset: Anwendungen brauchen auch Quellcode, Konfigurationsskripte oder andere Formen von Assets, für die eine geeignete DevOps-Infrastruktur für CI/CD, Quellcodeverwaltung usw. vorhanden sein muss.
- Netzwerkinfrastruktur und Cloud-Plattform: Schließlich bedarf es einer Netzwerkinfrastruktur zur Unterstützung der Anwendung sowie einer geeigneten Cloud-Plattform zur Zuweisung der Rechenressourcen für die Ausführung der verschiedenen Komponenten. Dies gilt unabhängig davon, ob es sich um einen lokalen agentenbasierten Assistenten handelt, der auf einem regulären Endpunkt bereitgestellt wird, um eine Anwendung, die innerhalb der internen Infrastruktur eines Unternehmens ausgeführt wird, oder um einen öffentlich zugänglichen Internet Service.
Die grünen Teile liegen außerhalb des agentenbasierten Systems-- eine wichtige Unterscheidung bei der Betrachtung von Bedrohungen für die Supply Chain. Zu diesen Komponenten gehören Bibliotheken von Drittanbietern, öffentliche Trainingsdatensätze, externe Tools usw.
Der Originalbeitrag umfasst zusätzlich ein Beispiel für einen Arbeitsablauf. Der Umfang all dieser Vorgänge führt zu einer breiten und komplexen Angriffsfläche mit vielen verschiedenen Komponenten, die jeweils ihre eigenen Risiken und Herausforderungen mit sich bringen.
Im nächsten Beitrag werden wir uns näher damit befassen, welche Arten von Risiken sich auf die einzelnen Schichten auswirken und was dies für den Schutz agentenbasierter KI-Anwendungen bedeutet.