
Форма искусственного интеллекта (ИИ), которая позволяет системам выявлять закономерности на основе данных и со временем повышать свою производительность при выполнении задач без явного программирования.
Содержание
Машинное обучение использует алгоритмы и статистические модели для прогнозирования или принятия решений на основе входных данных. Компьютеры, которые сами, без явных указаний, решают, что нужно делать, долгое время занимали лучшие умы.
Автомобиль, в котором вы можете ехать как водитель, но который будет полностью самостоятельно себя вести, распознавать пешеходов и выбоины и быстро и эффективно реагировать на изменения в окружающей среде, чтобы безопасно доставить вас к месту назначения — это машинное обучение на практике.
Как оно работает? Давайте рассмотрим анализ бизнес-данных.
Машинное обучение — это тип ИИ, который позволяет компаниям обрабатывать огромные объемы данных и делать важные выводы. Для получения ценной информации требуется проделать большую работу. Чтобы максимально использовать возможности машинного обучения, у вас должны быть чистые данные и вы должны знать, ответ на какой вопрос вы хотите получить. Затем вы можете выбрать лучшую модель и алгоритм. ML — это непростой процесс. Для успеха нужна тщательность проработки данных.
Жизненный цикл ML:
- Понимание бизнеса. Определение проблемы, критериев успеха и пригодности машинного обучения для поставленных задач.
- Сбор и очистка данных. У вас есть необходимый объем тщательно очищенных данных, готовых к анализу.
- Выбор признаков. Процесс выбора входных переменных (признаков), которые будут использоваться при построении модели, такими методами, как статистические тесты, регуляризация или алгоритмические показатели важности. Например, деревья решений ранжируют признаки по таким критериям, как получение информации или примесь Gini.
- Выбор модели. Выберите соответствующий алгоритм и тип модели, а затем обучите на основе своих данных.
- Обучение и настройка. Подгоните модель под данные и настройте гиперпараметры для повышения производительности.
- Оценка модели и алгоритма, чтобы определить, готова ли модель к использованию, или для достижения ваших целей вам нужно вернуться на пару шагов назад и уточнить модель, компоненты, алгоритм или данные.
- Внедрение обученной модели в производство.
- Изучение результатов данной модели в производстве.

Для чего используется машинное обучение?
Машинное обучение помогает предприятиям понять свои данные и извлечь из них пользу. Компания может использовать его для огромного количества целей. Вариант использования зависит от конкретной цели — улучшить продажи, реализовать функцию поиска, интегрировать в продукт голосовые команды или создать беспилотный автомобиль.
Сферы применения машинного обучения (ML)
Сегодня машинное обучение находит себе применение в огромном количестве сфер, и со временем их число будет только расти. Сферы применения ML: социальные сети и рекомендации по продуктам, распознавание изображений, диагностика состояния здоровья, перевод с одних языков на другие, распознавание речи, интеллектуальный анализ данных, и это далеко не полный перечень.
Платформы социальных сетей, такие как Facebook, Instagram или LinkedIn, используют машинное обучение, чтобы предлагать пользователям страницы или группы на основе понравившихся публикаций. Модель берет исторические данные о том, что понравилось другим пользователям или какие сообщения похожи на те, что понравились вам, и затем предлагает их вам или добавляет их в вашу ленту.
Также можно использовать машинное обучение на сайте электронной коммерции, чтобы давать рекомендации по продуктам на основе предыдущих покупок, поисковых запросов пользователя и аналогичных действий других пользователей.
Кроме того, машинное обучение широко используется для распознавания изображений. Платформы социальных сетей предлагают отметить людей на ваших фотографиях. Полиция может разыскивать подозреваемых по фото или видео. Благодаря множеству камер, установленных в аэропортах, магазинах и у входных дверей, можно выяснить, кто совершил преступление или куда направился преступник.
Также ML находит применение при диагностике состояния здоровья. После такого события, как сердечный приступ, можно просмотреть предупреждающие симптомы, которые были упущены из виду. Система, используемая врачами и больницами, может получать медицинские карты пациентов из предыдущих медицинских учреждений и видеть связи между входными данными (поведение, результаты анализов или симптомы) и выходными (например, сердечный приступ). Затем, когда врач введет в систему свои записи и результаты анализов, машина сможет обнаружить симптомы сердечного приступа гораздо надежнее, чем люди, и врач с пациентом смогут скорректировать лечение и предотвратить приступ.
Перевод веб-страницы или приложения для мобильных платформ — еще один пример применения машинного обучения. Некоторые приложения работают лучше других, в зависимости от применяемой модели, техники и алгоритмов.
Кроме того, мы, сами того не подозревая, каждый день используем машинное обучение, пользуясь банковскими услугами. Некоторые признаки мошенничества машинное обучение обнаруживает гораздо быстрее, чем люди. На основе множества транзакций, которые уже изучены и отмечены как мошеннические или легитимные, машинное обучение помогает выявлять мошенничество. В этом эффективно помогает интеллектуальный анализ данных, или data mining.
Интеллектуальный анализ данных
Интеллектуальный анализ данных (англ. Data mining) — это тип машинного обучения, который анализирует большие данные, чтобы делать прогнозы или обнаруживать закономерности. Этот процесс не подразумевает, что кто-либо, будь то злоумышленник или сотрудник компании, будет копаться в ваших данных, чтобы найти какой-нибудь полезный фрагмент данных. Этот процесс заключается в выявлении закономерностей в данных, полезных для принятия решений в будущем.
Возьмем, к примеру, компанию, выпускающую банковские карты. Если у вас есть банковская карта, вероятно, ваш банк когда-либо уведомлял вас о подозрительной активности на вашей карте. Как банк так быстро обнаруживает такую активность, почти мгновенно отправляя уведомление? Это непрерывный интеллектуальный анализ данных обеспечивает защиту от мошенничества.
Глубокое обучение
Глубокое обучение — это особый тип машинного обучения, основанный на нейронных сетях. Нейронная сеть имитирует работу нейронов человеческого мозга, когда человек принимает решения или что-то понимает. Например, ребенок может взглянуть на лицо человека и отличить свою маму от охранника в магазине, потому что мозг быстро анализирует многие детали — цвет волос, черты лица, шрамы и т. д. — и все это в мгновение ока. Машинное обучение воспроизводит это в виде глубокого обучения.
Нейронная сеть имеет от 3 до 5 слоев: входной слой, от одного до трех скрытых слоев и выходной слой. Скрытые слои друг за другом принимают решения, позволяющие приблизиться к выходному слою, т.е. сделать вывод. Какой цвет волос? Какой цвет глаз? Есть ли шрам? Когда количество слоев увеличивается до сотен, это называется глубоким обучением.
Типы машинного обучения
Есть четыре основных типа алгоритмов машинного обучения: с учителем, без учителя, с частичным привлечением учителя и с подкреплением. Эксперты по машинному обучению считают, что примерно 70% используемых сегодня алгоритмов — это машинное обучение с учителем. Они работают с полным набором размеченных данных, например, с изображениями кошек и собак. Оба типа животных известны, поэтому администраторы могут отметить изображения, прежде чем передавать их алгоритму.
Алгоритмы машинного обучения без учителя учатся на неизвестных наборах данных. Возьмем, к примеру, видео в TikTok. На платформе есть огромное количество видео на огромное количество тем, поэтому на их основе невозможно обучить алгоритм контролируемым образом; данные еще не размечены.
Алгоритмы машинного обучения с частичным привлечением учителя изначально обучаются с использованием небольшого набора данных, который известен и размечен. Затем для продолжения обучения он применяется к большому набору неразмеченных данных.
Алгоритмы машинного обучения с подкреплением изначально не обучаются. Они учатся методом проб и ошибок на ходу. Представьте робота, который учится перемещаться по груде камней. При каждом падении он понимает, какой метод не работает, и меняет свое поведение, пока не добьется успеха. Или представьте дрессировку, при которой собаки получают угощение за правильное выполнение команд. При положительном подкреплении собака будет продолжать выполнять команды и изменит поведение, которое не дает положительной реакции.
Машинное обучение с учителем и без учителя
Машинное обучение с учителем
Использует известные, установленные и классифицированные наборы данных для поиска закономерностей. Вернемся к изображениям собак и кошек. У вас может быть огромный набор данных с тысячами различных животных на миллионах изображений. Поскольку типы животных известны, их можно было сгруппировать и разметить, а затем передать алгоритму машинного обучения с учителем, чтобы он научился понимать.
Теперь алгоритм с учителем сравнивает входные данные с выходными, а изображение — с разметкой типа животного. Со временем он научится распознавать определенный вид животных на новых фотографиях.
Машинное обучение без учителя
Алгоритмы машинного обучения без учителя сегодня похожи на фильтры спама. Раньше администраторы могли запрограммировать фильтры спама, чтобы те искали определенные слова в электронном письме для выявления спама. Сейчас это уже невозможно, поэтому здесь хорошо работает алгоритм без учителя. Алгоритм машинного обучения без учителя получает электронные письма, которые не были размечены, и начинает поиск закономерностей. Когда паттерны будут найдены, алгоритм узнает, как выглядит спам, и будет определять его в производственной среде.

Методы машинного обучения
Методы машинного обучения решают задачи. В зависимости от вашей задачи вы выбираете конкретный метод машинного обучения. Ниже перечислены шесть основных методов:
Регрессия
Регрессию можно использовать для прогнозирования цен на жилье на внутреннем рынке или для определения оптимальной цены на снегоуборочную лопату в Миннесоте в декабре. Регрессия показывает, что, несмотря на колебания, цены всегда возвращаются к среднему значению, даже если со временем цены на жилье растут. Существует средний уровень, который всегда повторяется. Вы можете построить график изменения цен и найти среднее значение с течением времени. Красная линия тренда, идущая вверх, позволяет делать прогнозы на будущее.
Классификация
Классификация используется для группировки данных по известным категориям. Например, вы хотите выявить клиентов, которые предсказуемо являются хорошими покупателями (они всегда возвращаются и тратят больше денег) или, наоборот, собираются делать покупки в другом месте. Если вы сможете заглянуть в прошлое и найти прогнозные факторы для каждой группы клиентов, вы сможете применить их к текущим клиентам и предсказать, в какую группу они войдут. На основе этих данных вы сможете разработать более эффективную маркетинговую стратегию, чтобы привлечь больше лояльных клиентов. Это типичный пример машинного обучения с учителем.
Кластеризация
В отличие от метода классификации, кластеризация — это машинное обучение без учителя. При кластеризации система сама найдет, как сгруппировать данные, которые вы затрудняетесь сгруппировать. Этот тип машинного обучения отлично подходит для анализа медицинских изображений, анализа социальных сетей или поиска аномалий.
Google использует кластеризацию для обобщения, сжатия данных и сохранения конфиденциальности в таких продуктах, как видео YouTube, приложения для воспроизведения и музыкальные треки.
Обнаружение аномалий
Обнаружение аномалий используется, когда вы ищете статистические выбросы, например паршивую овцу в стаде. При рассмотрении огромного количества данных люди не могут обнаружить эти аномалии. Но, например, если специалист по данным загрузит в систему биллинговые данные из многих больниц, обнаружение аномалий найдет способ сгруппировать эти данные. Метод может обнаружить набор выбросов, которые указывают на мошенничество.
Анализ рыночной корзины
Логика анализа рыночной корзины позволяет делать прогнозы на будущее. Простой пример: если покупатели кладут в корзину говяжий фарш, помидоры и тако, можно предположить, что они добавят сыр и сметану. Эти прогнозы можно использовать для увеличения продаж, делая ценные предложения для онлайн-покупателей, если они забыли какие-либо товары, или для группировки товаров в магазине.
Два профессора Массачусетского технологического института использовали этот подход, чтобы обнаружить «предвестников провала». Оказывается, некоторым клиентам нравятся товары, которые оказываются провалом производителей. Если вы можете обнаружить таких клиентов, вы можете определить, продолжать ли продавать продукт и какой вид маркетинга применить для увеличения продаж от нужных клиентов.
Данные временных рядов
Данные временных рядов собираются, например, о людях с фитнес-трекерами на запястьях. Они регистрируют сердцебиение в минуту, сколько шагов в минуту или час мы делаем, а некоторые теперь даже измеряют сатурацию кислорода с течением времени. С этими данными можно было бы предсказать в будущем, когда кто-то будет бегать. Кроме того, таким образом можно собирать данные об оборудовании и прогнозировать отказ благодаря данным временных рядов об уровне вибрации, уровне шума в дБ и давлении.
Алгоритмы машинного обучения
Если машинное обучение должно обучаться на данных, как разработать алгоритм для обучения и поиска статистически значимых данных? Алгоритмы машинного обучения поддерживают обучение с учителем, без учителя или с подкреплением.
Инженеры по обработке данных пишут фрагменты кода, представляющие собой алгоритмы, которые позволяют машине изучать данные и находить в них закономерности.
Рассмотрим несколько наиболее распространенных алгоритмов. Сегодня наиболее широко используются следующие пять алгоритмов.
- Алгоритмы линейной регрессии устанавливают взаимосвязь путем подбора для графика независимых и зависимых переменных и построения прямой линии для среднего значения или тренда. Словарь Merriam-Webster определяет регрессию как функцию, которая дает среднее значение случайной переменной при условии, что одна или несколько независимых переменных имеют заданные значения. Это определение также применимо к логистической регрессии.
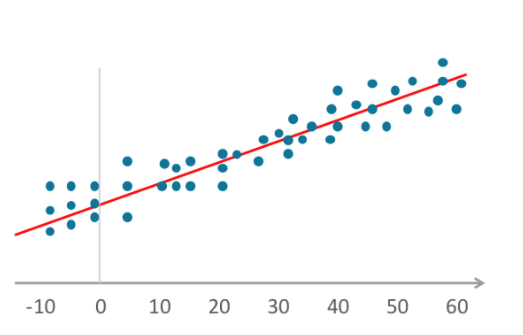
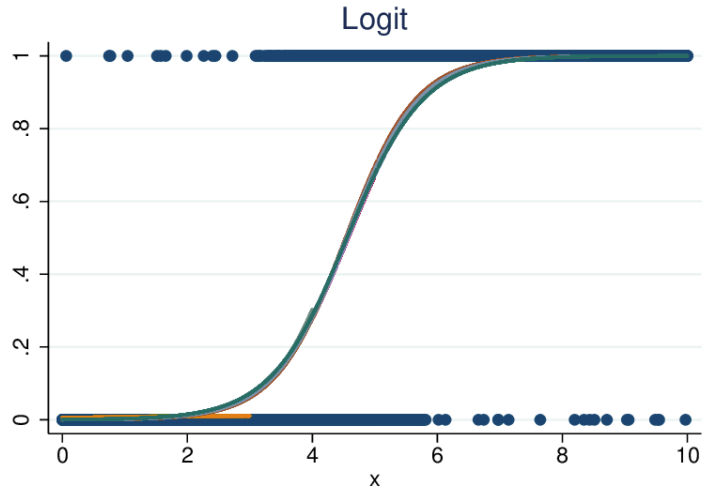
- Логистическая регрессия также подставляет переменные на график, как и линейная регрессия, но график не является прямой линией. Логистическая регрессионная модель строится на использовании сигмоиды.
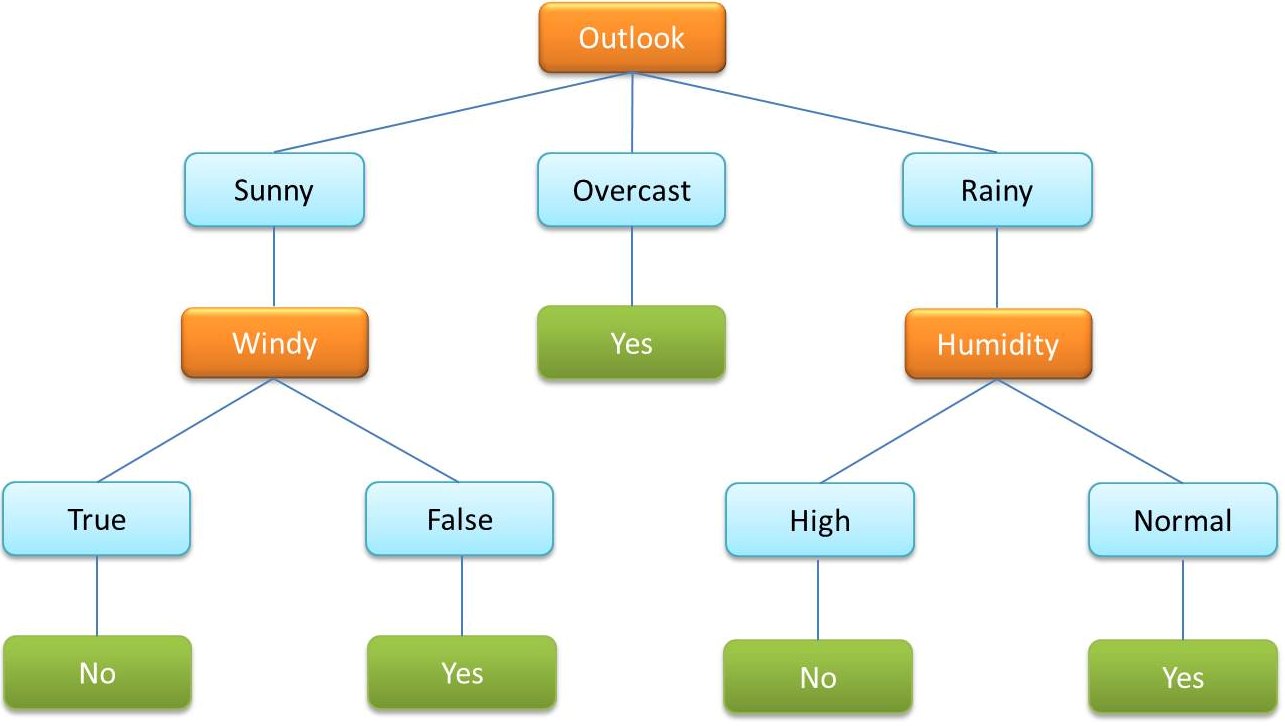
- Дерево решений — очень часто используемый алгоритм в машинном обучении с учителем. Он используется для классификации данных по категориальным и непрерывным переменным.
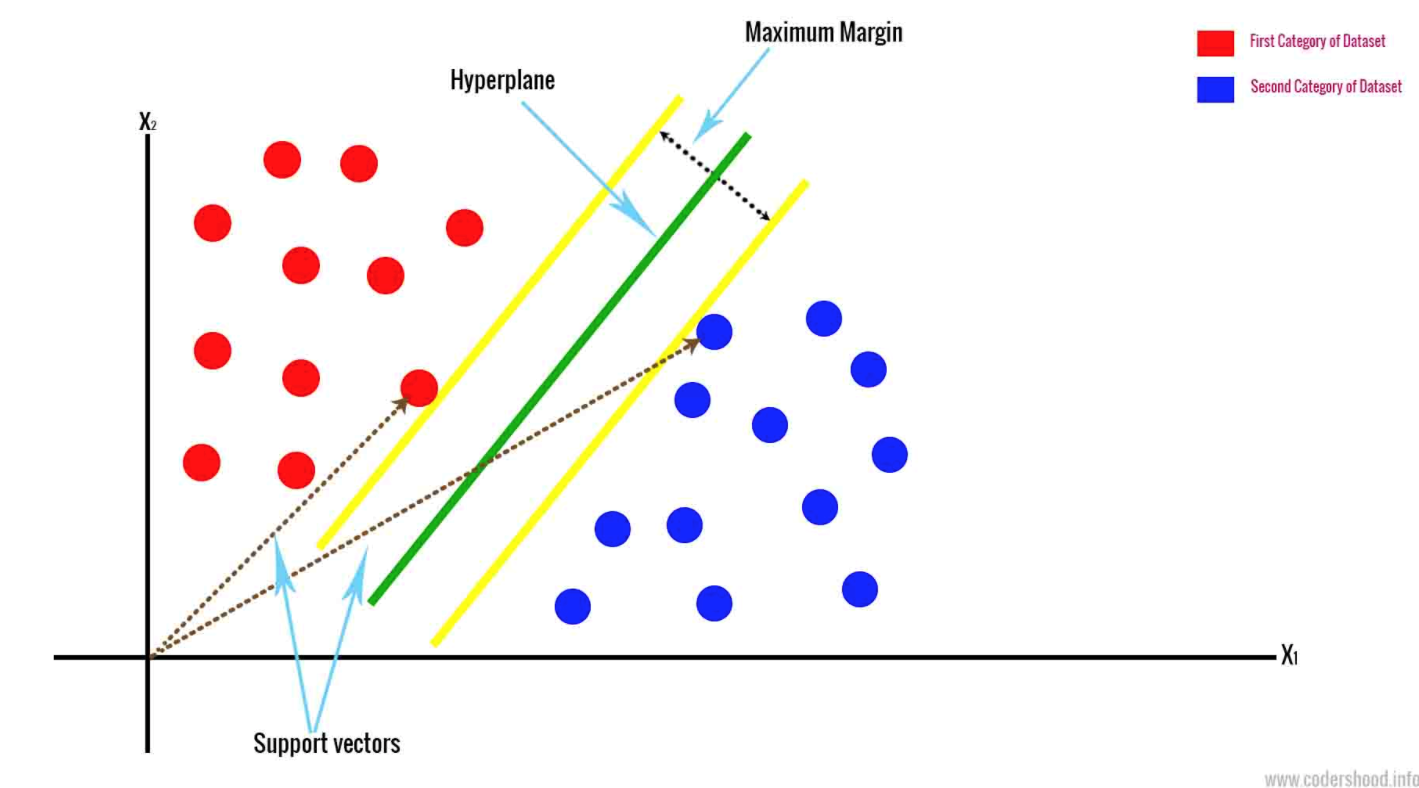
- Метод опорных векторов строит гиперплоскость на основе двух ближайших точек данных. Он разделяет данные, максимизируя расстояние между классами. Метод классифицирует данные на основе N-мерного пространства. N представляет количество различных функций, которые у вас есть.
- Наивный байесовский алгоритм вычисляет вероятность определенного исхода. Он очень эффективен и превосходит более сложные модели классификации. Модель наивного байесовского классификатора понимает, что любая данная характеристика не связана с наличием других конкретных характеристик.
Модели машинного обучения
После объединения типа машинного обучения (с учителем, без учителя и т. д.), методов и алгоритмов результатом является обученный файл. Теперь этому файлу могут быть предоставлены новые данные, и он сможет определять паттерны и делать прогнозы или принимать решения для компании, менеджера или клиента.
Лучшие языки для машинного обучения
Языки машинного обучения определяют, как пишутся инструкции для обучения системы. У каждого языка есть сообщество пользователей, которые помогают друг другу учиться или предоставляют рекомендации. В каждый язык включены библиотеки для машинного обучения.
Вот 10 лучших из них:
- Python
- R
- Java
- Julia
- Scala
- C++
- JavaScript
- Lisp
- Haskell
- Go
Машинное обучение на Python
Поскольку Python является наиболее распространенным языком машинного обучения, остановимся на нем подробнее.
Python — это интерпретируемый объектно-ориентированный язык с открытым исходным кодом, названный в честь комик-труппы Монти Пайтон. Поскольку язык интерпретируется, он преобразуется в байт-код перед выполнением на виртуальной машине Python.
Есть множество параметров, которые делают Python предпочтительным выбором для машинного обучения.
- Большой набор мощных пакетов, доступных для использования уже сейчас. Есть специальные пакеты для машинного обучения, такие как numpy, scipy и panda.
- Легкое и быстрое создание прототипа.
- Есть множество инструментов для совместной работы.
- Python также может использоваться для извлечения данных, моделирования и обновления решения для машинного обучения. Специалисту по данным не нужно менять язык во время прохождения жизненного цикла.
Где получить помощь с машинным обучением?
Машинное обучение — мощный инструмент, помогающий платформе кибербезопасности защищать вашу организацию, сотрудников и партнеров благодаря более быстрому, интеллектуальному и проактивному обнаружению угроз и реагированию на них.
Trend Vision One™ — это единственная платформа кибербезопасности на базе ИИ, которая централизует управление киберрисками, операции безопасности и надежную многоуровневую защиту. Этот комплексный подход помогает прогнозировать и предотвращать угрозы, поддерживая реализацию проактивной безопасности в вашем цифровом пространстве. Благодаря использованию больших наборов данных безопасности, углубленному анализу поведения и моделям обнаружения аномалий Trend Vision One помогает выявлять как известные, так и ранее не известные угрозы, включая эксплойты нулевого дня и целевые фишинговые кампании.


На должности вице-президента по управлению продуктами в Trend Micro Джо Ли руководит глобальной стратегией и разработкой продуктов в сфере корпоративных решений для электронной почты и сетевой безопасности.
Часто задаваемые вопросы
Что такое машинное обучение?
Машинное обучение — это разновидность искусственного интеллекта (ИИ), которая позволяет компьютерным системам имитировать процессы, с помощью которых люди принимают сложные решения и учатся на опыте.
Что такое машинное обучение простыми словами?
Машинное обучение — это тип ИИ, который позволяет компьютерам учиться на данных и со временем повышать производительность без необходимости явно программировать каждую задачу.
Приведите пример машинного обучения.
Примером машинного обучения могут служить технологии распознавания лиц, когда компьютерная система учится распознавать визуальные входные данные.
Какие четыре типа машинного обучения бывают?
Четыре основных типа машинного обучения — с учителем, без учителя, с частичным привлечением учителя и с подкреплением.
В чем разница между ИИ и машинным обучением?
Искусственный интеллект (ИИ) — это системы, разработанные для имитации человеческого интеллекта. Машинное обучение — это разновидность ИИ, которая находит закономерности в данных для повышения производительности системы.
ЧатGPT — это большая языковая модель или генеративный ИИ?
ChatGPT является примером как LLM (большой языковой модели), так и генеративного ИИ.
Чат-бот — это ИИ или машинное обучение?
Чат-боты обычно разрабатываются с использованием технологий искусственного интеллекта (ИИ) и машинного обучения.
Что относится к ИИ, но не к машинному обучению?
Некоторые ИИ-системы не используют машинное обучение, например экспертные системы на основе правил, системы символического рассуждения и предварительно запрограммированные алгоритмы, которые следуют фиксированным правилам.
Что лучше, ИИ или машинное обучение?
Выбор зависит от ваших целей. Машинное обучение — это разновидность ИИ, которая позволяет компьютерным системам учиться на опыте без контроля со стороны человека.
С чего начать погружение в тему: с ИИ или машинного обучения?
Это зависит от ваших интересов и целей. Но большинство людей изучают ИИ, прежде чем специализироваться на таких ответвлениях, как машинное обучение.
Статьи по теме
10 основных рисков и мер по их снижению для LLM и генеративного ИИ в 2025 году
Управление возникающими рисками для общественной безопасности
Как далеко заведут нас международные стандарты?
Как написать политику кибербезопасности для генеративного ИИ
Атаки с использованием ИИ — один из самых серьезных рисков
Распространение угроз, связанных с дипфейками