Artificial Intelligence (AI)
一網打尽:AIで挑む19,000台のMCPサーバ脆弱性調査
本リサーチでは、19,000を超えるオープンソースのMCPサーバリポジトリを分析し、それらにどれほどAI生成コードが含まれているか、また悪用可能な脆弱性をどれほど抱えているかを明らかにしました。


目次
- GitHub上のAIボットによるコード生成イベントは、2025年1月から10月にかけて約6倍に増加しました。MCP(Model Context Protocol)サーバリポジトリのうち8.3%が、コントリビューターのメタデータに基づいてAIボットの活動を示しており、ソースコード分析からは全リポジトリの少なくとも20%でAIが関与していることが示唆されます。
- MCPサーバリポジトリでAIが検出した脆弱性のうち、実際に悪用可能なものは4.1%であり、その大半をSQLインジェクション、リモートコード実行、パストラバーサルが占めています。
- AI生成コードの兆候を示すリポジトリは、悪用可能な脆弱性が確認されたリポジトリの中で不釣り合いに高い割合を占めており、手動で脆弱と分類されたリポジトリの42.6%がAIコード生成の兆候を示していました。
- 19,000を超えるリポジトリの分析に基づき、悪用可能な脆弱性を含むものは600~1,650件(3.1%~8.6%)と推定しています。
- 複雑なアプリケーションには専門領域の知識が必要であり、LLMに完全に委ねるべきではありません。多段階の検証はハルシネーションの低減に役立ちますが、完璧な解決策ではありません。
TrendAI™ Researchの過去の公開記事「外部公開された MCP サーバの最新動向:脅威はクラウドへと拡大」では、オープンソースのMCPサーバリポジトリがわずか数か月で19,000件超へと急増したことを明らかにしました。この急増を受け、MCPサーバの数がそのユーザ数を上回っているのではないかと考えるに至りました。
多くの開発者が独自のMCPサーバを公開せざるを得なかったように見受けられます。しかし、ここからさらに疑問が生じます。これらのサーバのうち、どれだけがAIの支援を受けて開発、あるいはAIによって生成されたのか。どれだけが脆弱で、どのような形で脆弱なのか。
本リサーチは、これらの問いに答えるために実施しました。AI生成コードの普及度を推定するため、19,000件のオープンソースMCPリポジトリにわたってリポジトリのメタデータとソースコードの特徴を分析しました。脆弱性分析については、ソースコードにアクセスするためのツールを備えたGeminiベースのAIエージェントを開発しました。最初の実行では、エージェントは17,558件の脆弱性を検出しました。次に、同じモデルを用いる2つ目のエージェントに明らかなハルシネーションの除去を担わせ、15,000件あまりを残しました。3回目では、2,287件の脆弱性をランダムに抽出し、Claude Haiku 4.5ベースのエージェントに通したところ、438件が脆弱性として検出されました。これら438件を手動でレビューしたことで、セキュリティリサーチのツールとしての大規模言語モデル(LLM)の信頼性を評価する、またとない機会を得られました。
AIコードの見分け方
最初の課題は、AIコードをどう見分けるかでした。本リサーチで対象としたMCPサーバはすべてGitHubリポジトリから取得したものであるため、そのリポジトリのメタデータを調査しました。メタデータには、コントリビューターとしてのGitHub Copilotやその他のAIボットの記載が含まれていました。これは必ずしもすべてのコードがAIによって生成されたことを意味するわけではありませんが、少なくとも一部はそうであることを強く示唆しており、リポジトリのメタデータはAI関与の重要な指標となります。
GH Archiveのデータを用いたところ、GitHubのAIボット操作が一貫して増加していることが分かりました。2025年1月から10月にかけて、GitHubのAIボット操作はGitHub全イベントのうち175,996件(0.05%)から1,007,487件(1.1%)へと増加しました。
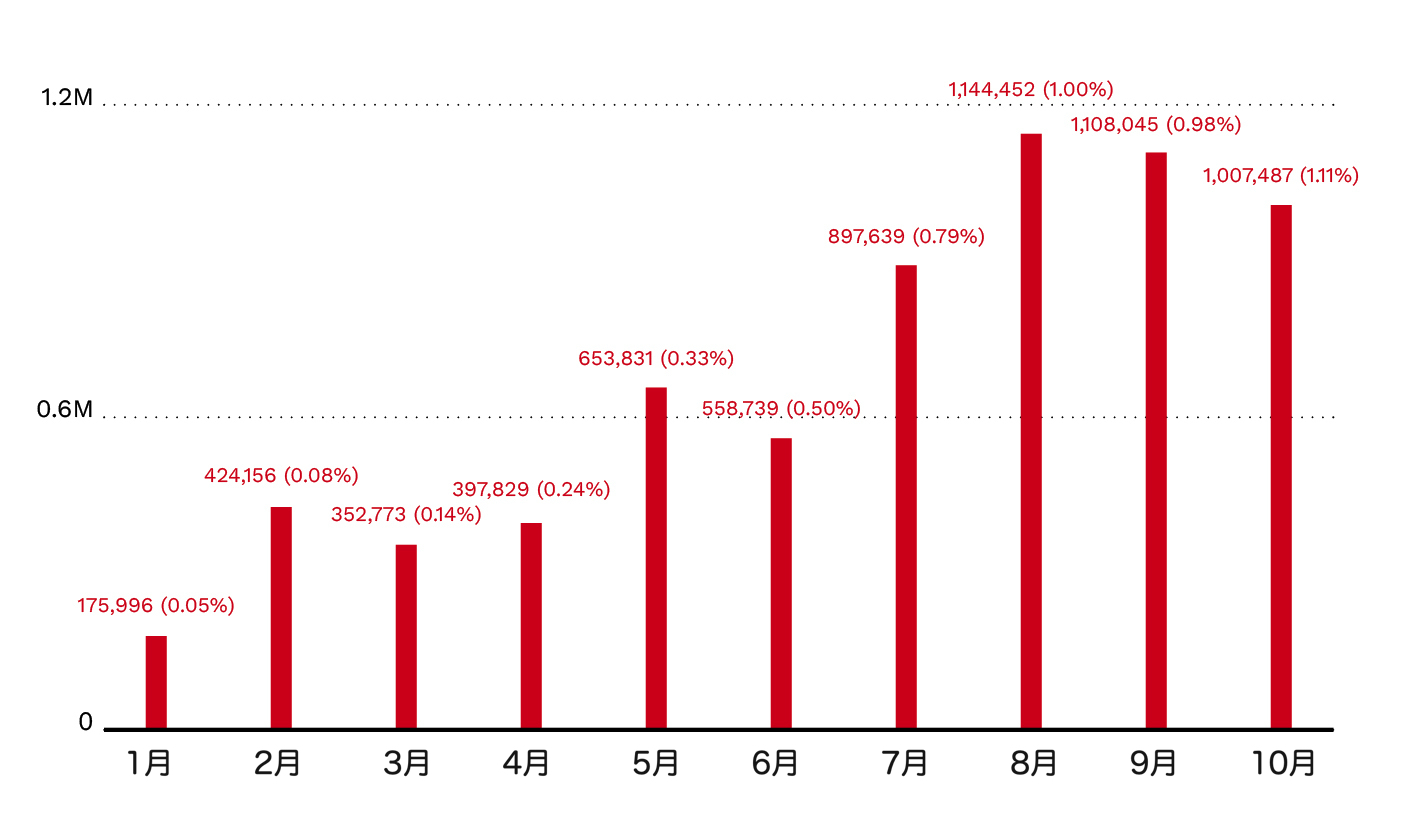
この傾向は、分析対象としたMCPサーバリポジトリ内のボット活動にも反映されており、分析対象リポジトリの8.3%がAIボットの活動を示していました(図2)。図3と図4は、活動量の多い上位のAIボットを示しています。
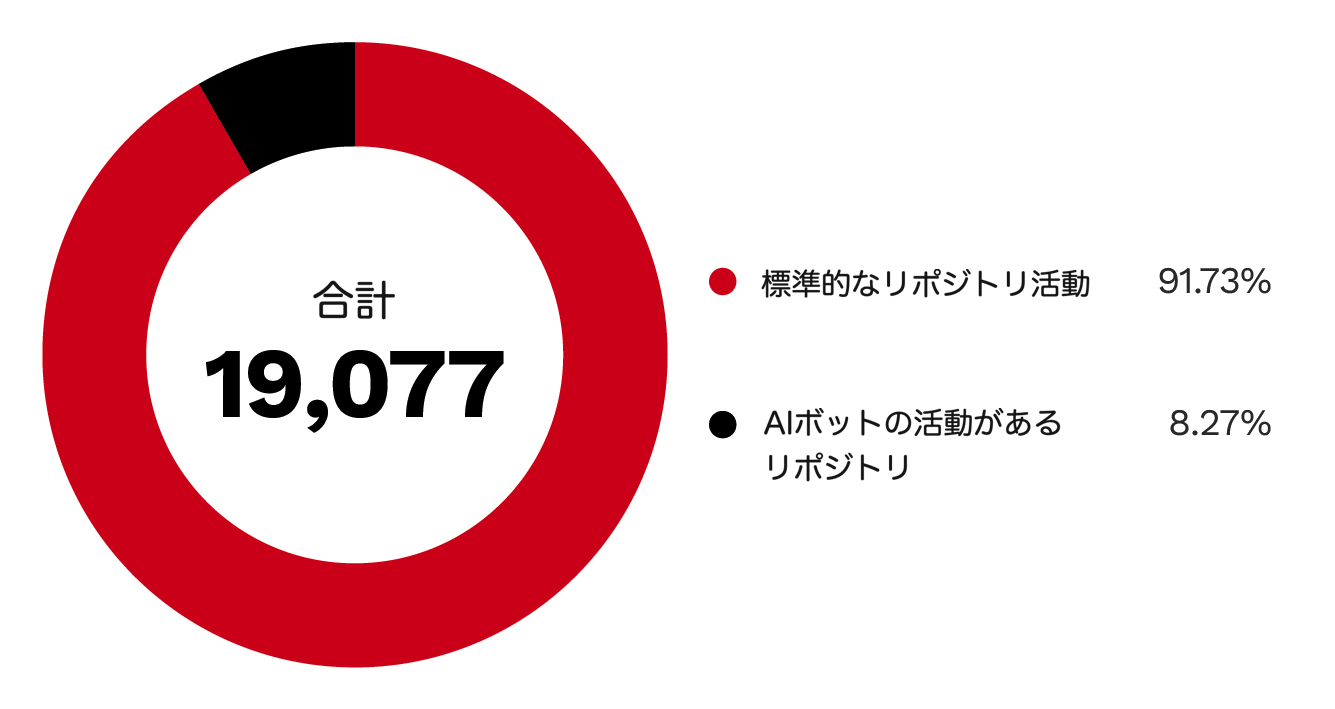
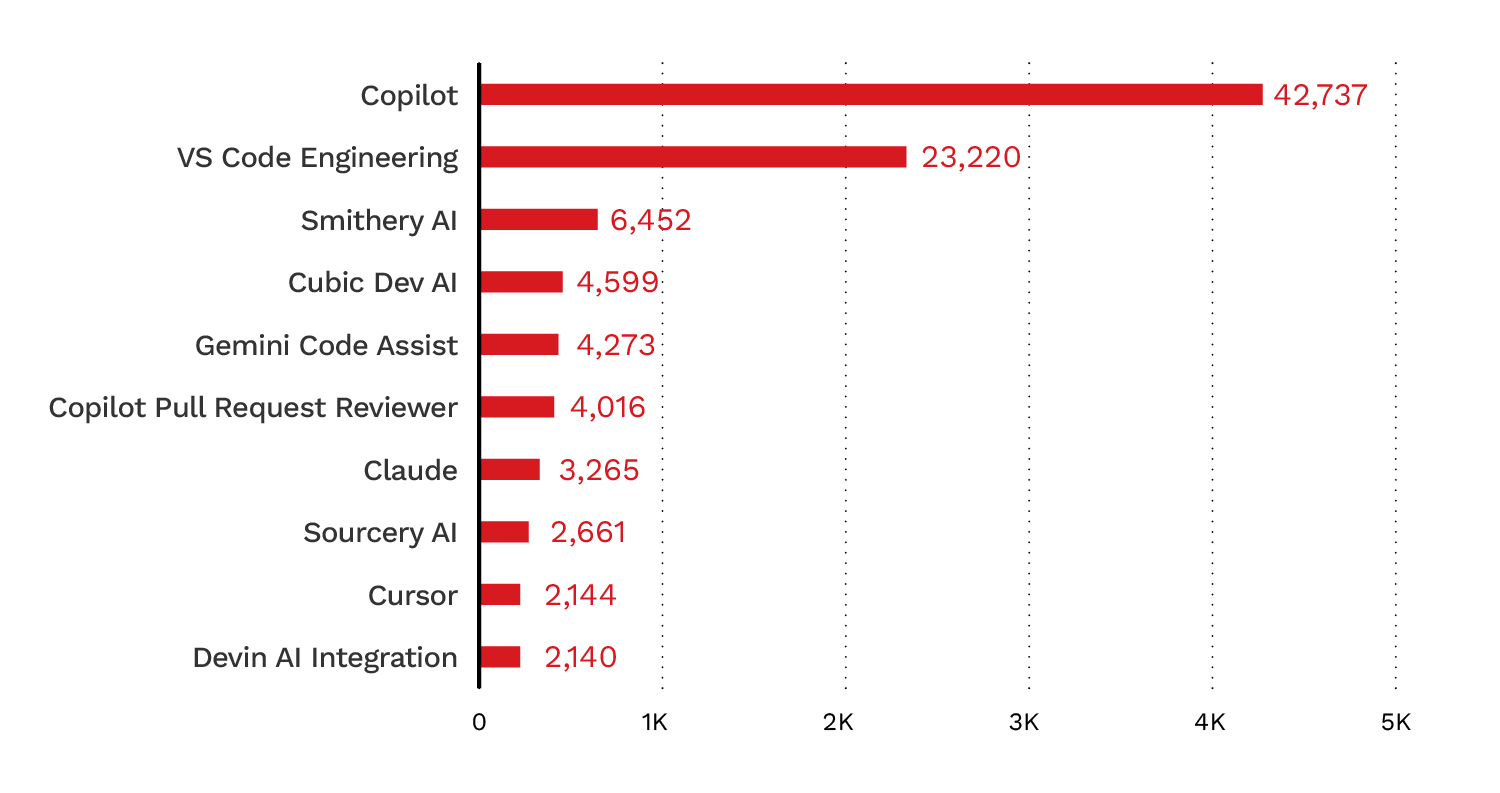
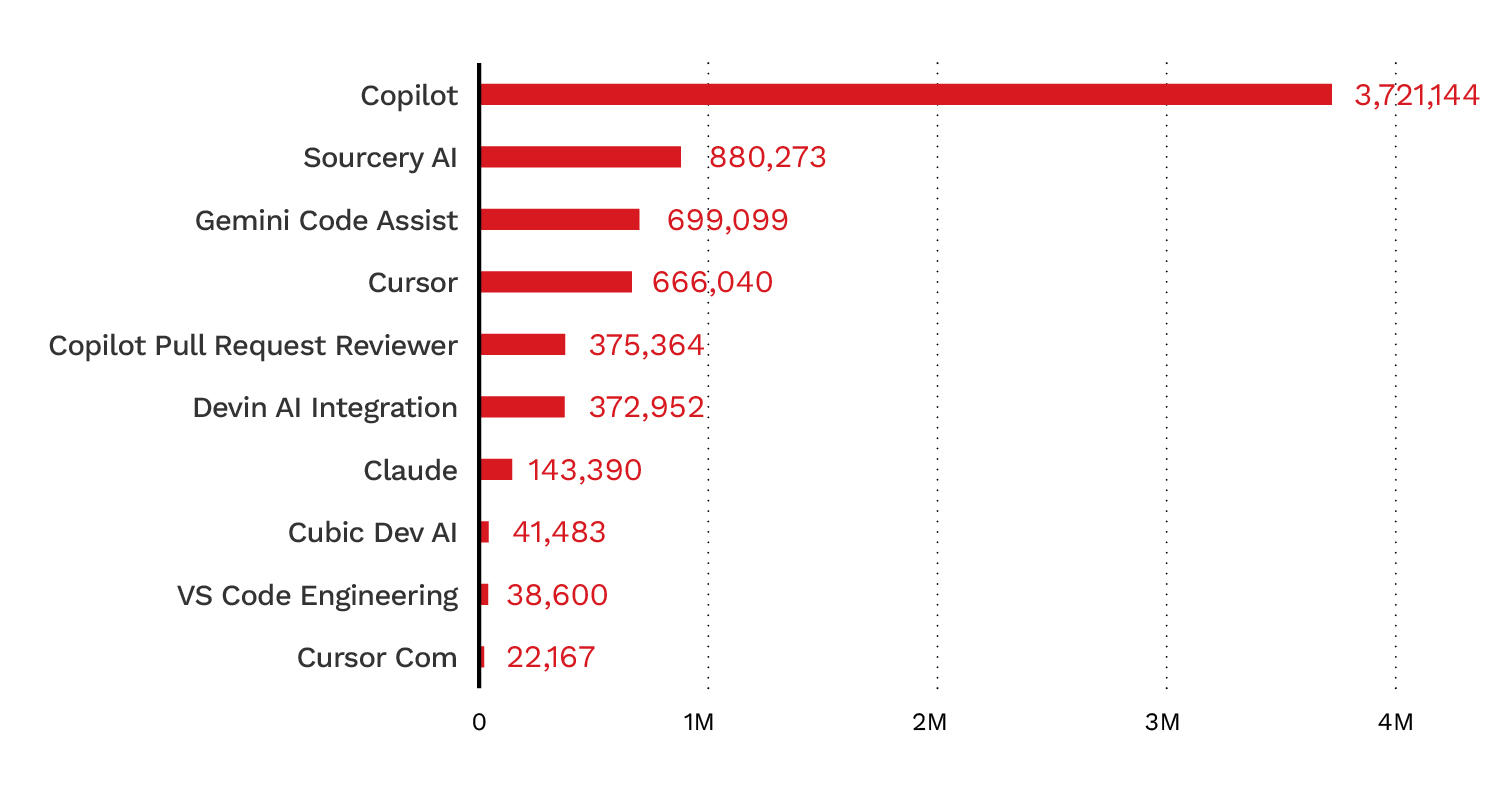
このデータは、公開リポジトリにおけるAI生成コードの存在感が高まっていることを示しています。リポジトリのメタデータ、コードの特徴、ボット活動の指標を組み合わせると、AIツールがオープンソースコードの開発・保守のあり方を次第に形づくっていることがうかがえます。
この傾向はMCPサーバにとって実務上の意味を持ちます。開発のスピードと一貫性を高める一方で、セキュリティと信頼性に関わる課題ももたらすのです。
ここまでに示した統計は、全体像を反映したものではありません。開発者がAIツールの使用を明示したケースしか捉えられていないためです。たとえば、開発者は開発中にAIによるバイブコーディングを利用しつつ、自分のアカウントでコードをコミットすることもできます。
これを踏まえ、AI生成コードのパターンに関する観察、LLMを扱った経験、AIに関する議論をもとに、AIコードの特徴を特定する決定論的なソースコード分析ツールを開発しました。こうした特徴には次のものが含まれます。
- ソースコード中の絵文字や図形記号
- 罫線素片文字
- 分析における過剰なコメント
- 防御的なコーディングパターン(過剰な例外処理、null/noneチェック)
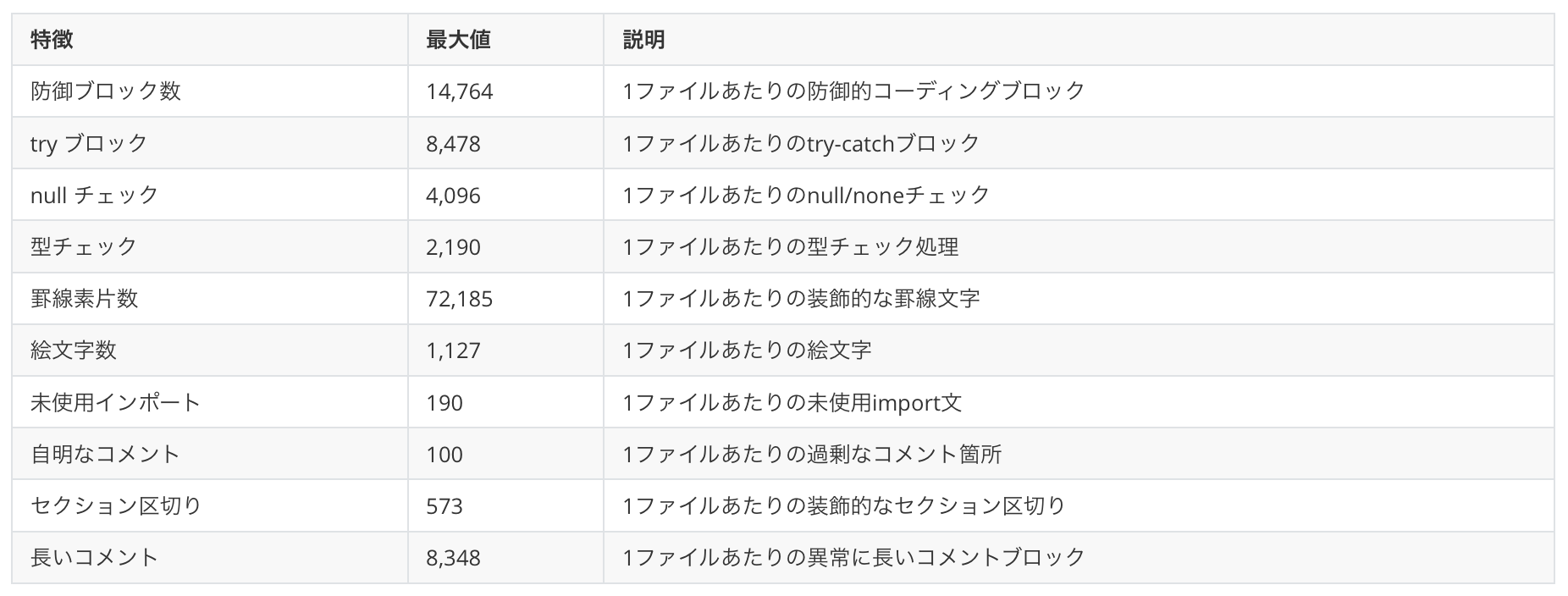
結果は実に興味深いものでした。特筆すべきは、1ファイル内の防御的コーディングブロック数の最大値が14,764に達したことです。これは明らかに、REST APIからMCPへの変換時に生成されたものでした。実際には、防御的コーディングの数は大半のケースでこれよりはるかに少ないものでした。AIの指標を「1つのソースファイル内に10個を超えるtry-catchブロック」と設定したところ、1,586リポジトリにまたがる6,109ファイルが該当し、これは分析対象リポジトリ全体の8.3%にあたります。一方、セクション区切りが2つ以上見つかったリポジトリは1,462件でした。これら2つの指標(try-catchブロック数の多さとセクション区切り)は、リポジトリのメタデータで見られた8.3%というボット活動の数値と一致しています。
しきい値をtry-catchブロック5個に下げたところ、3,602リポジトリにまたがる16,686ファイル(約19%)が該当しました。
絵文字に基づく指標を調べたところ、6,893リポジトリにまたがる35,689ファイルで絵文字が2つ以上見つかりました。検索対象をソースコードファイルのみ(「.md」ファイルを除外)に絞ると、3,662リポジトリ(19.3%)にまたがる17,734件のソースコードファイルで絵文字が見つかりました。
この傾向は、追加した他の指標によってさらに裏付けられました。
- 装飾的な罫線囲みのあるリポジトリ:4,485件(23.6%)
- 未使用インポートのあるリポジトリ:9,550件(50.3%)
これらの結果は一貫した傾向を示しています。単一の指標や特徴だけで断定できるものはありませんが、リポジトリ全体でこれらの指標が重なり合っていることから、MCPサーバリポジトリの少なくとも20%でAIコード生成が用いられているという保守的な推定に至りました。
脆弱性を狩り出す
オープンソースのMCPサーバリポジトリは数が膨大であるため、現実的な期間内ですべてのリポジトリを手動で分析することは不可能であると明らかになりました。幸い、大規模言語モデル(LLM)とそれに基づくエージェントシステムの進歩により、MCP脆弱性リサーチだけでなく、それと並行してAIリサーチも実施するというまたとない機会が得られました。
本リサーチでは、MCPサーバのソースコードに対して、Geminiベースの静的解析を3段階で実施し、脆弱性を特定しました。
第1段階では、エージェントにソースコードを分析させ、考えられるすべての脆弱性を探索させました。AIエージェントは17,558件の脆弱性を検出しました。これをそのまま受け取ることはできなかったため、いくつかのレポートをランダムに抽出し、結果をさらに精査・評価しました。すべてのケースで、LLMのよく知られた(英語)迎合(sycophancy)の傾向が見られました。客観的な分析よりもユーザの期待に沿った結果や応答を返し、プロンプト内でそうしないよう明示的に指示したにもかかわらず、あらゆる潜在的な問題を脆弱性として検出していたのです。
これらの結果から、さらに次の疑問が生じました。別のプロンプトやモデルを使えばどうなるのか。温度(temperature)設定を下げれば結果を改善できるのか。
第2段階では、プロンプトを変更し、同じLLMに対して、ハルシネーション、立証されていない潜在的なケース、第1段階でLLMが無視した指示を取り除くための批判的な評価を求めました。
第2段階では15,000件を超える脆弱性が報告されましたが、依然として懐疑的な見方を崩しませんでした。レポートを精査するうちに、スキャンエージェントは多くの脆弱性を検出したものの、そのすべてが必ずしもセキュリティコミュニティで認知されているわけではないと気づきました。たとえば、一部の脆弱性を悪用するにはサーバ環境への直接アクセスがすでに必要であり、それ自体がより重大なセキュリティ問題となります。なぜなら、それは連携先のデータソースが、MCPサーバを悪用するまでもなくすでにアクセス可能であることを意味するからです。
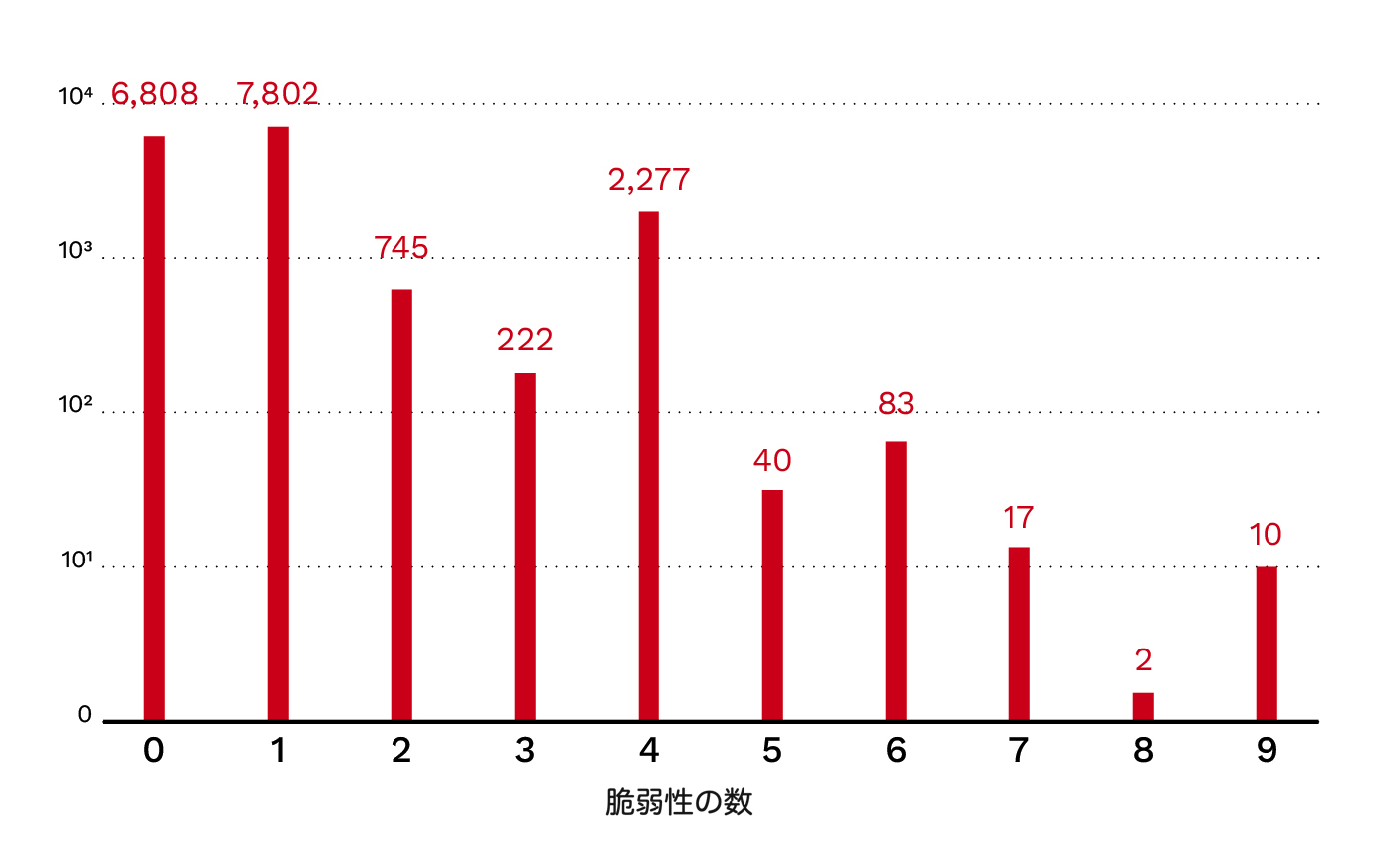
第3段階では、第2段階から2,287件の脆弱性をランダムに抽出し、検証のためにClaudeベースのAIエージェントで処理しました。この実行にも、ソースコードにアクセスするために必要なツールを含めました。
エージェントが検出した438件と、第1段階で当初検出された17,558件との間に大きな開きがあったため、検出された脆弱性を手動で検証することにしました。
サンプリングした2,287件の候補のうち、エージェントは438件(19.1%)を検出しました。手動レビューによってそのうち93件が本物であると確認され、エージェントの適合率は21.2%(95%信頼区間:18%~25%)、エンドツーエンドの真陽性率は約4%となりました。
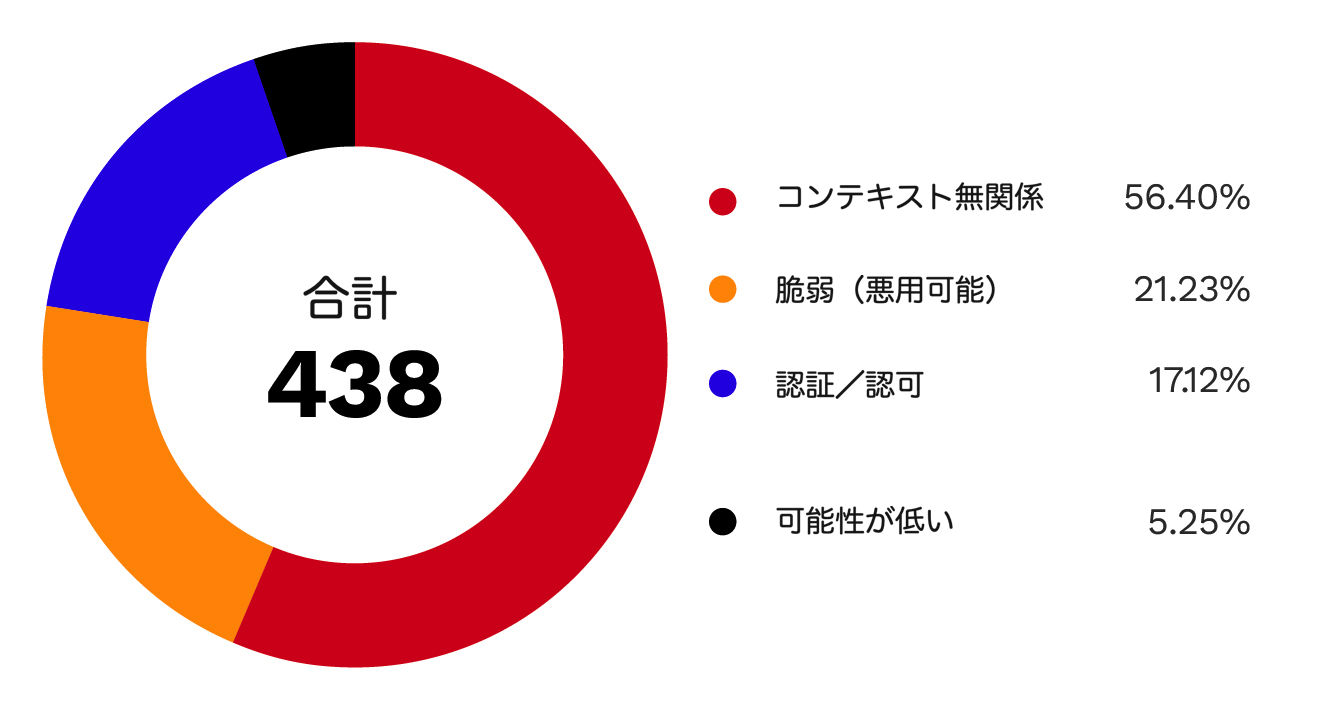
まず、MCPの文脈で脆弱性とみなさないものを明確にしました。MCPサーバの大半(英語)はサーバレベルで認証や認可を実装していないことで知られているため、これを脆弱性として扱いませんでした。エージェントにはこれらを無視するよう明示的に指示しましたが、注目すべきことに、17%のケースでこの指示は無視されました。
図6に示すように、コンテキスト無関係(context-irrelevant)のカテゴリが56.4%と最も高い割合を占めています。これは、エージェントがコードのより広い文脈を考慮せずに脆弱性を検出したケースです。コンテキスト無関係の検出結果について最も単純な説明は、論理的な不整合です。あるケースでは、エージェントは連携先のデータベースへの書き込み操作を許すSQLインジェクションを特定しましたが、それらの操作がコード内の他の箇所ですでに許可されていることを考慮していませんでした。別のケースでは、標準入出力(stdio)方式のMCPサーバで脆弱性を検出しましたが、これはサーバへの直接的なやり取り自体がより重大なセキュリティ問題となるものです。
さらに事態を複雑にしているのは、コンテキスト無関係のカテゴリに含まれることが、その脆弱性を悪用できないことを保証するわけではないという点です。RCE系の問題が、このカテゴリの検出結果の17%を占めているのです。
LLMのAPI呼び出しが、攻撃者の制御する悪意あるエンドポイントへとリダイレクトされるシナリオ(たとえば、LLMプロキシ上の脆弱性や設定ミスを悪用する場合)では、攻撃者はユーザのマシン、さらにはより広範なプライベートネットワークにまでアクセスできる可能性があります(図7)。
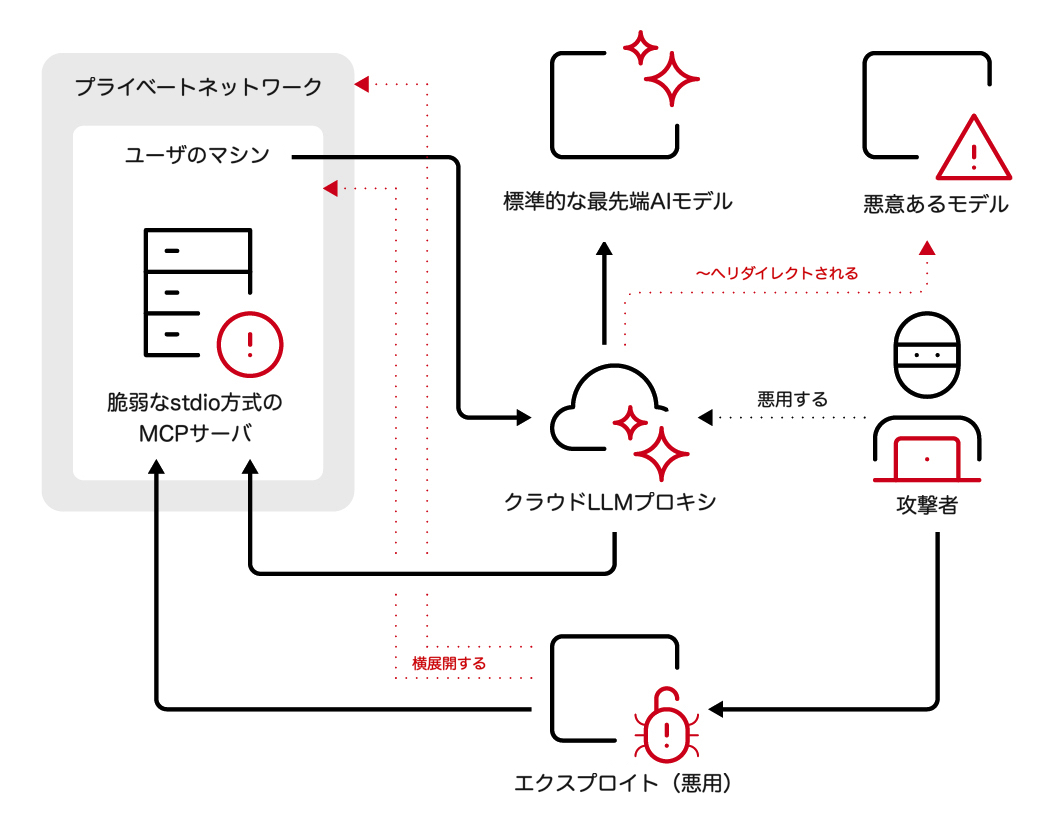
図6は、可能性が低いカテゴリ(約5.3%)が、脆弱性は存在するものの悪用される可能性が極めて低いものを指していることを示しています。
最後に、93件(21.2%)が実際に悪用可能な脆弱性として確認されました。最も多かったのはSQLインジェクションで、MCPサーバのSQL保護機構の不備に起因し、脆弱性の26%を占めました。2番目に多かったのはリモートコード実行(RCE)で、脆弱性の22.5%を占めました。これらの脆弱性は、よく知られたコマンドラインユーティリティのラッパーにおけるコマンドラインインジェクションによって引き起こされることが多くあります。パストラバーサルの脆弱性は19%で3番目でした。これらの脆弱性は、意図したディレクトリの外にあるファイルへの任意の読み書きを許し、データの露出や、サーバへの不正な変更を可能にするおそれがあります。
認証バイパスの脆弱性(7.5%)が存在することは、MCPサーバに認証機能が備わっている場合でも、それが必ずしも正しく実装されているとは限らないことを示していました。図8は、確認された脆弱性タイプの全内訳を示しています。
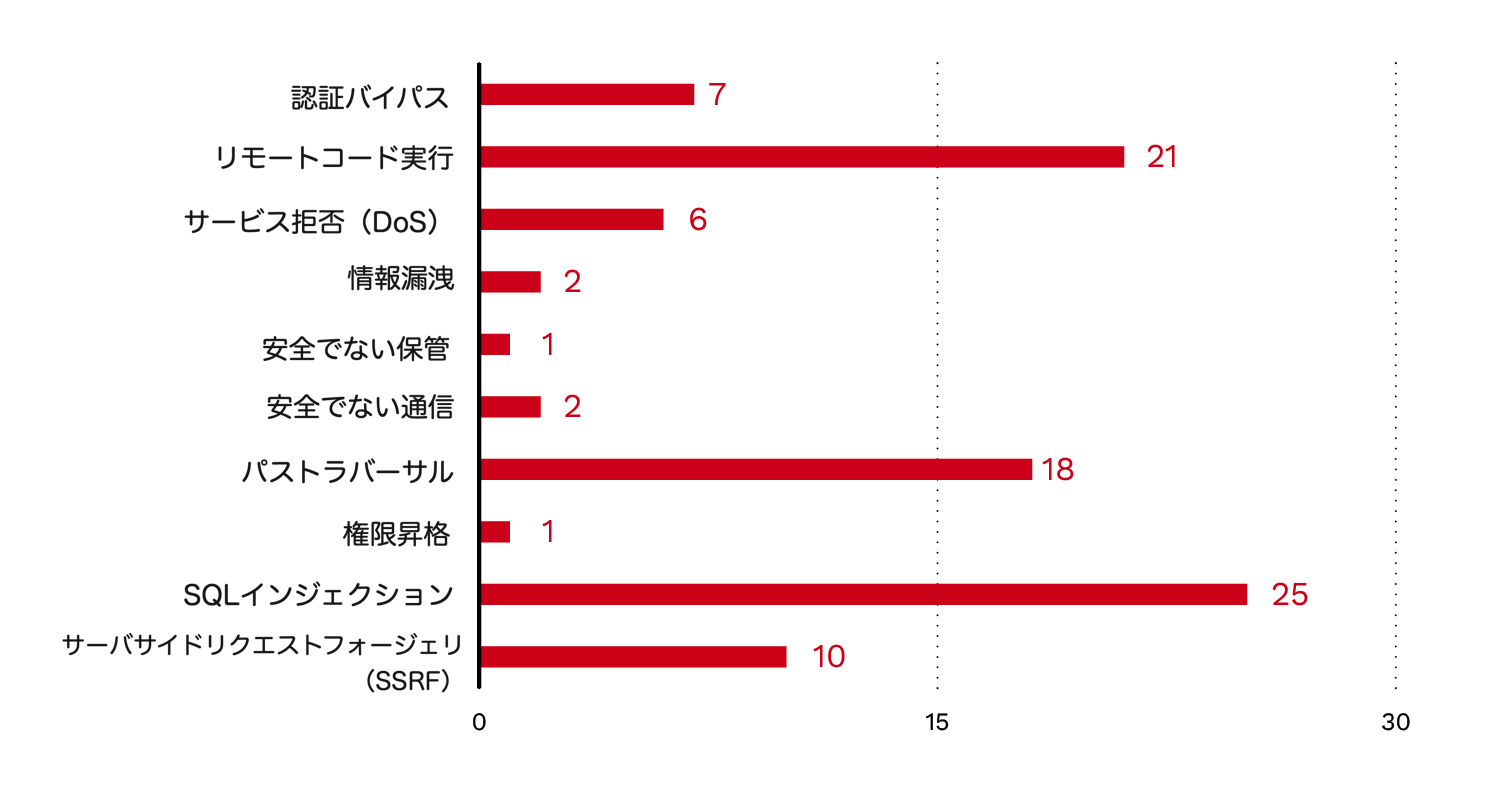
このデータは、これまでの調査結果と、追加の隔離メカニズムの必要性を裏付けています。たとえば、コンテナのファイルシステム隔離はパストラバーサル脆弱性の悪用の緩和に役立ち、ネットワークファイアウォールのルールや侵入防止システム(IPS)はサーバサイドリクエストフォージェリ(SSRF)の悪用を防ぎます。認証バイパスとSQLインジェクションには、MCPサーバ組み込みの保護に頼るのではなく、外部の認証メカニズムときめ細かなロールベースアクセス制御(RBAC)が求められます。
ここで重要な問いが残ります。これらの脆弱なリポジトリのうち、どれだけがAI利用の兆候を示しているのか。メタデータ分析では、悪用可能なリポジトリの3%でAIボットの活動が特定されました。しかし、ソースコードの特徴分析はまったく異なる事実を物語っています。悪用可能な脆弱性を持つと手動で分類されたリポジトリの42.6%が、AIコード生成の兆候を示しているのです。
まとめ
オープンソースのMCPサーバのうち、どれだけが脆弱なのか。
本リサーチのデータに基づくと、19,000件のリポジトリ全体における悪用可能な脆弱性の数は600~1,650件の範囲にあり、点推定値は770件前後(リポジトリの約4%)と見込まれます。
この数値に至った経緯は次のとおりです。 データセット全体から、エージェントが検出した候補2,287件をランダムに抽出しました。より厳格な2つ目のエージェントが438件(19.1%)を残し、手動レビューによってそのうち93件が実際に悪用可能であると確認されました。確認率は21.2%です。この4.1%の出現率(2,287件中93件)を19,000件のリポジトリに外挿すると、約770件という点推定値が得られます。
この範囲には、3つの不確実性の要因が反映されています。
- サンプリング分散だけでも、不確実性の下限が定まります。2,287件中93件の確認済み陽性により、95%信頼区間は母集団レベルで630~940件の脆弱性に相当します。これは、完璧な分類器と再現率100%のエージェントを用いたとしても得られる値です。
- 手動レビュアーは、判断の難しいケースで両方向に誤る可能性があります。双方向の人為的誤差を約5%と見積もると、確認済み陽性の件数は約±10%変動し、信頼区間が両方向にわずかに広がります。
- 2つ目のエージェントは、手動レビューに到達する前に1,849件の候補を除外しました。これらの除外のうち、実際にどれだけが悪用可能であったかは直接測定していません。エージェントの再現率が60%~100%の範囲にあると仮定すると、真の件数は最大1.67倍まで上方にスケールします。これが範囲の上限への最も大きな寄与要因です。
点推定値(約770件)は、エージェントの再現率がほぼ完璧で、手動レビューに偏りがないことを前提としています。上限(約1,650件)は、エージェントが真に悪用可能な脆弱性の約40%を見逃し、レビュアーがわずかに過小に数えたシナリオに対応します。下限(約600件)は、サンプリング分散とレビュアーによるわずかな過大計上が組み合わさった場合に対応します。
これらの結果は、AIが特定した脆弱性のすべてが本物の脆弱性とは限らないことを裏付けています。多段階の検証はハルシネーションや不正確なレポートを減らしますが、完璧な解決策ではありません。プロンプトを精緻化し、何が脆弱性に当たるかを定義することは役立ちますが、LLMは、よく練られたプロンプトであっても、また温度設定を下げた場合であっても、必ずしもそれに従うとは限りません。これらの結果は、専門領域の知識の重要性を浮き彫りにすると同時に、AIへの全面的な委任のような近道に警鐘を鳴らすものです。
AIを活用したリサーチでは、特にスコープがまだ十分に定まっていない探索的な段階においては、小規模なランダムデータセットから始め、結果を検証し、本格的に規模を拡大する前に手法を洗練させるのが望ましいといえます。LLMの出力は一貫していません。解析した結果、とりわけJSON出力中の数値フィールドは、決してそのまま鵜呑みにせず、慎重に検証してください。
本リサーチが継続的に示してきたとおり、MCPの普及はAI時代におけるアタックサーフェスを拡大させています。今回の結果はこの現実にさらなる重みを与えるものであり、なお進化を続ける脅威状況の一断面を示しています。継続的な監視とリサーチが求められます。
参考記事
Hunt Them All: An AI-Powered Vulnerability Sweep of 19,000 MCP Servers
By Alfredo Oliveira (Senior Threat Researcher, TrendAI™ Research) and David Fiser (Senior Threat Researcher, TrendAI™ Research)
翻訳:与那城 務(Platform Marketing, Trend Micro™ Research)