By Numaan Huq and Roel Reyes
Key Takeaways
- Resuming the discussion on agentic edge artificial intelligence (AI) in the first article in this series, this second article examines the development tools and workflows involved and the related cybersecurity threats.
- When left unsecured, these tools and workflows can inadvertently expose systems and allow attackers to interfere with operations, gain control of devices, and exfiltrate data.
- Industries that leverage internet of things (IoT) and industrial internet of things (IIoT) technologies that are either already using or thinking of incorporating agentic edge AI devices in their systems need to stay updated on the current and emerging threats.
- Mitigation for cyberthreats associated with agentic edge AI necessitates consistent efforts across the designing, building, and deployment phases. This article shares best practices, including hyper-parameter governance, deterministic replay validation, and red team drills.
In a previous Trend™ Research article, we discussed the concept of agentic edge AI by examining its classes of devices and their intricate architecture. Also uncovered are the related cybersecurity threats and their corresponding mitigation strategies. This article, which continues our research, explores the tools and the complex workflow needed to build agentic edge AI applications, their attack surfaces, and the mitigation strategies to safeguard them.
In a nutshell, building an agentic edge AI system is a multi-disciplinary endeavor. It involves robotics, AI, and machine learning (ML), embedded systems, and cloud computing. To support all these requirements, a variety of development tools and workflows have been created, either as commercial or open-source tools.
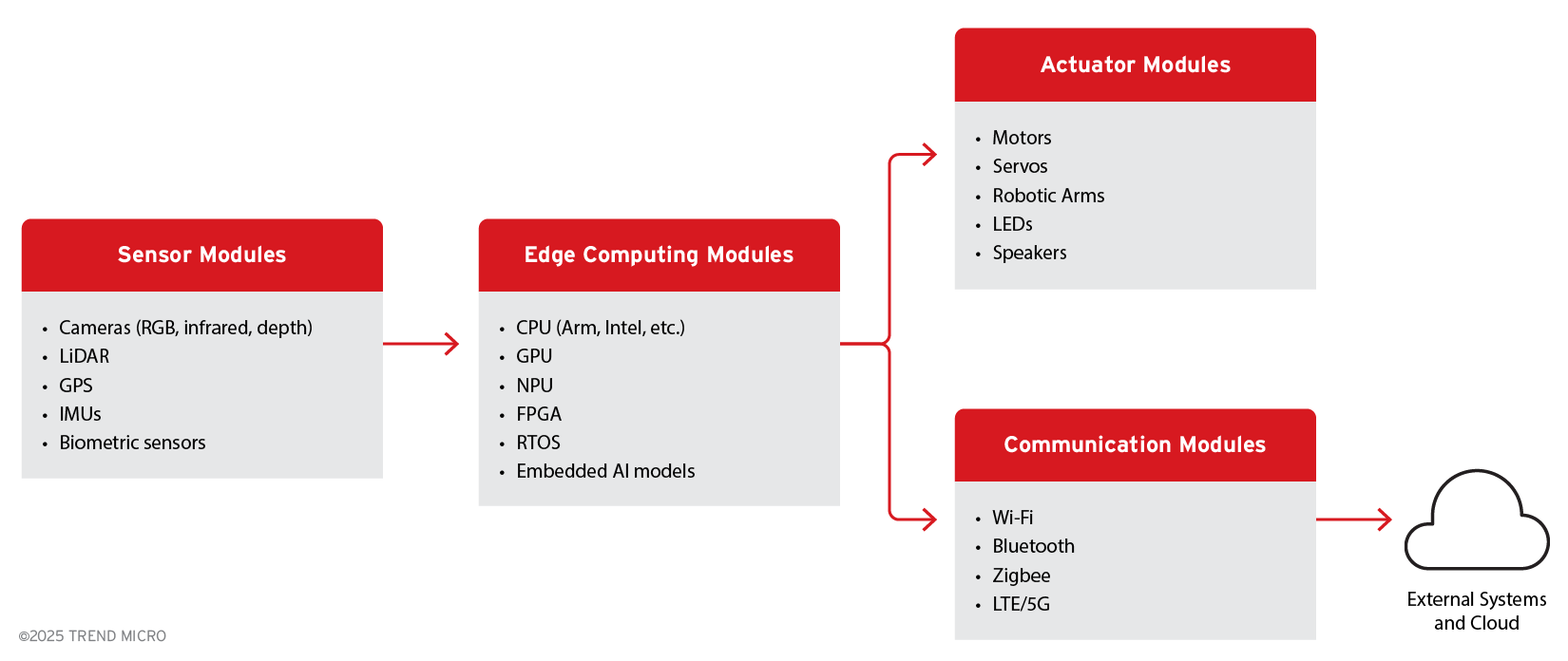
Figure 1. Agentic edge AI hardware components
Two major ecosystems have emerged and are popular with developers: NVIDIA’s integrated “Physical AI” toolchain, and open-source and/or non-NVIDIA platforms such as Robot Operating System (ROS), Apache, Intel, and so on. Both aim to cover the full pipeline from simulation and training to deployment on edge hardware.
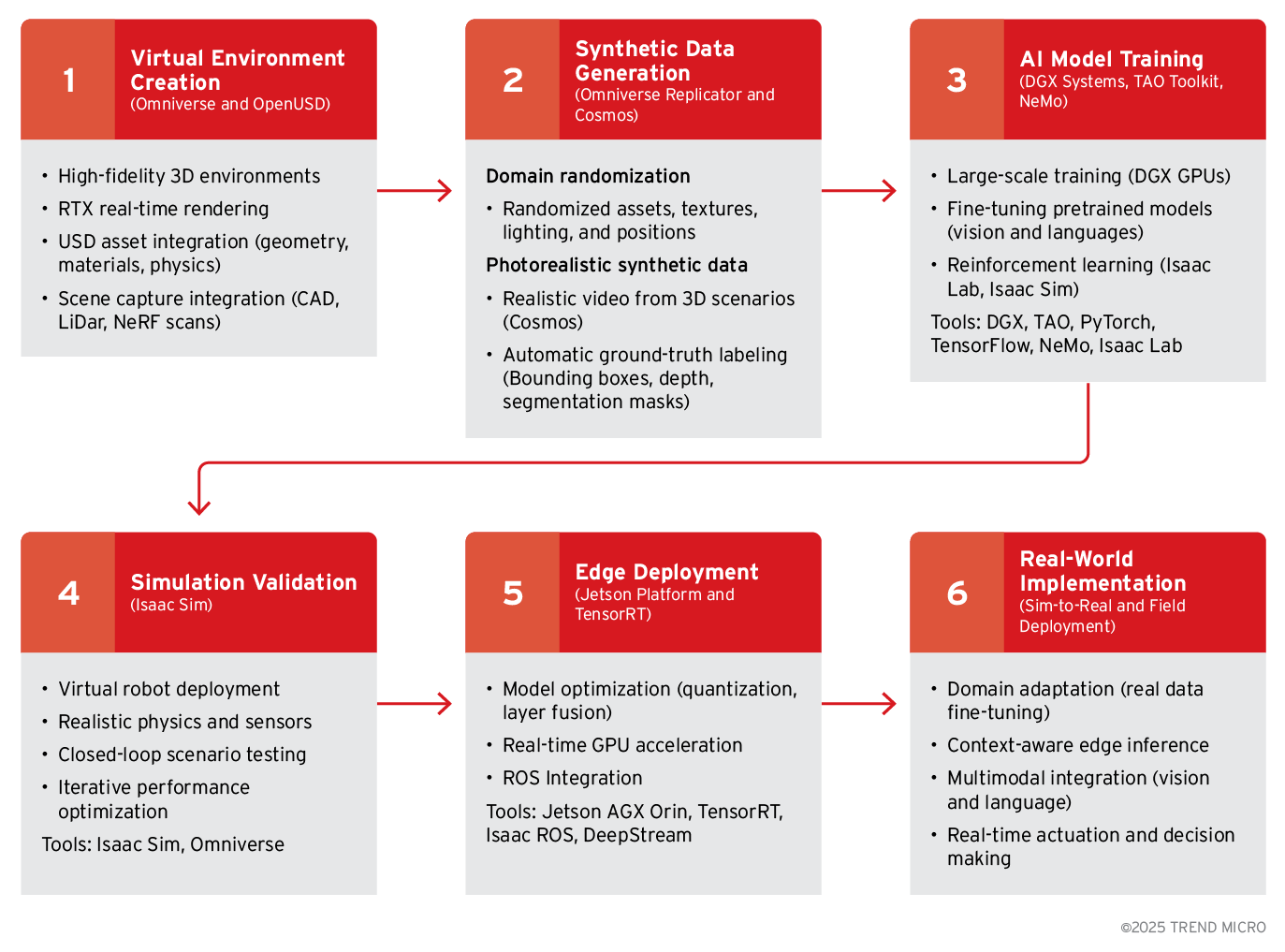
Figure 2. Example workflow for creating “Physical AI” with NVIDIA Omniverse
NVIDIA has built a comprehensive development stack for robotics and edge AI: often referred to as the NVIDIA Isaac platform, or the “Physical AI” development suite. Their ecosystem spans simulation, data generation, model training, and deployment, largely built on NVIDIA’s hardware and software.
An advantage of using the NVIDIA ecosystem is its integration: many components are designed to work together as they leverage NVIDIA graphics processing units (GPUs).
But not all projects use NVIDIA’s stack; there is a rich ecosystem of open-source frameworks and tools for edge AI and robotics. A popular approach (especially in research and startups) is to use ROS 2 as the middleware, combined with simulators like Gazebo, Car Learning to Act (CARLA), or Aerial Informatics and Robotics Simulation (AirSim), and machine learning frameworks like PyTorch or TensorFlow for model development. This non-NVIDIA pipeline has similar stages: simulate, train, and deploy, but with different tools. Table 1 shows a comparative analysis of the two workflows.
| Stage | NVIDIA Workflow | Non-NVIDIA Workflow |
|---|---|---|
| Stage 1: Virtual three-dimensional (3d) environment construction | The objective is to create a realistic digital twin of the target environment for simulation and data generation. NVIDIA’s Omniverse platform has APIs and tools to construct 3D environments with physical realism. Using Universal Scene Description (OpenUSD) and RTX ray tracing, developers can model scenes (e.g., a factory floor, a home interior, or a city block) with accurate geometry, lighting, and physics. This stage also uses NVIDIA OVX servers to handle the heavy graphics computation of the simulation. NVIDIA’s fVDB (open-source deep learning framework for sparse, large-scale, high-performance spatial intelligence; currently on early access) allows deep learning on massive 3D datasets. Using these tools, developers can create a detailed virtual world where the agent (robot/vehicle) can be placed to develop and test its behaviors. | This stage involves modelling the device’s operating environment in a physics-based simulator. ROS 2 provides the connectivity (through drivers, message-passing, etc.) for robot sensors and actuators in simulation. Gazebo is a popular open-source 3D simulator that can render indoor or outdoor worlds with realistic sensor physics. For autonomous vehicle scenarios, CARLA is widely used to simulate traffic, streets, and vehicle sensors in a realistic urban environment. For drones or general aerial vehicles, Microsoft’s AirSim is a common choice. Using these tools, developers create a digital twin of the environment and the robot. For example, one might import a warehouse computer-aided design (CAD) model into Gazebo and equip a virtual robot with light detection and ranging (LiDAR) and cameras using ROS 2 drivers. This environment is the sandbox for developing and testing the agent’s software before real-world trials. |
| Stage 2: Synthetic data generation | With a virtual world created, large quantities of labeled sensor data need to be generated for training AI models. This is for overcoming the lack of or the limitations of real-world data. The NVIDIA Omniverse Replicator software development kit (SDK) enables procedural generation of synthetic images, point clouds, etc., by randomizing the virtual scene’s elements such as lighting, object positions, and textures. By rendering many variations, developers can create a diverse dataset of simulated sensor outputs. The NVIDIA Cosmos platform supplies a photorealistic synthetic data pipeline and can be used for producing photo-realistic images from rendered scenes. These tools can automatically produce thousands of labeled examples (camera images with ground-truth annotations, LiDAR scans with identified objects, etc.), which are then used to train the agent’s perception and cognition models. | To train vision or perception models, simulated worlds can generate synthetic labeled data. To produce robust training images, techniques like domain randomization are employed in Gazebo or CARLA for systematically varying elements such as lighting, textures, and weather. Game engines like Unity (with Unity Machine Learning Agents, aka ML-Agents) or Unreal Engine can be used to generate synthetic scenarios and even support reinforcement learning (RL) simulations. The idea is similar to NVIDIA’s replicator: create diverse training data. For example, one can randomize the placement of objects in a Gazebo scene and capture thousands of camera images with ground-truth labels for object detection training. Unity’s ML-Agents toolkit allows embedding a learning agent in a game-like environment to generate experiences for RL training. |
| Stage 3: Model training and validation | Using the synthetic data together with available real-world data, developers train the AI models that will run on the device. The NVIDIA DGX platform can accelerate deep learning training. Models can be developed in frameworks like TensorFlow or PyTorch, or via NVIDIA’s own TAO Toolkit, which provides pre-trained models and streamlined training pipelines. After initial training, simulation is used for validation. The model is tested in virtual scenarios using NVIDIA Isaac Sim, a robotics simulator built on Omniverse, to ensure it performs as expected. NVIDIA’s Isaac Gym or Isaac Cortex can be used for reinforcement learning simulations to train robot control policies in virtual environments. This iterative loop (train models, then simulate the full agent in Isaac Sim) helps iron out problems before deploying to real hardware. | Using the collected data, both synthetic and real data, developers train AI models. Common choices include PyTorch or TensorFlow for training neural networks, often accelerated on a workstation or cloud GPUs. Reinforcement learning libraries like OpenAI Gym, Stable Baselines3, or RLlib integrate with ROS 2 and simulators to train control policies through trial and error. For example, we can connect a ROS 2 robotic arm in Gazebo to an OpenAI Gym environment and train it to grasp objects via RL. Physics engines like Multi-Joint dynamics with Contact (MuJoCo) are used for accurate dynamics simulation in training robot control models. Additionally, if natural language understanding or high-level reasoning is needed on the device, developers can incorporate pre-trained models or Hugging Face Transformers (for natural language processing, aka NLP) into the loop. Throughout training, the models are validated in simulation, and the new model is tested in Gazebo or CARLA to ensure it performs the task (such as navigating without collisions and recognizing objects) under different conditions. This simulation testbed allows iterative refinement of both the model and the robot’s overall software before deployment. |
| Stage 4: Deployment on edge hardware | Once the models are performing well in simulation, they are optimized and deployed to the physical device. To run the inference on the edge, NVIDIA provides specialized embedded AI hardware like their Jetson modules for robots, drones, IoT devices, and DRIVE AGX for autonomous vehicles. The trained model is optimized using NVIDIA TensorRT or exported to an efficient format such as ONNX for fast edge inference. Developers integrate the model into the robot’s software stack, usually by using ROS, which NVIDIA supports, and perform field testing on the actual device. The final deployed system will use NVIDIA’s full stack: for example, a Jetson AGX Xavier module running the perception model accelerated by Compute Unified Device Architecture (CUDA) and TensorRT, with the entire pipeline orchestrated through Isaac ROS or a similar runtime. | The final step is moving the developed system onto a physical device. Robots typically run on embedded computers (like Raspberry Pi, NVIDIA Jetson, or Intel NUC) with ROS 2 as the runtime. The trained models are optimized, using tools like OpenVINO or TensorRT for hardware acceleration or ONNX for portability, and loaded onto the device. Real-world testing is done to verify that the system, under real sensor inputs and actuators, behaves as expected. Best practices, like securing firmware, involving real-time controllers for critical loops, and establishing failsafes, are applied. The deployed system can connect to cloud services as needed (for updates or offloading tasks), but it is at this point an autonomous edge AI agent in operation. This open-source toolchain approach is highly flexible: one can swap in different simulators or frameworks as needed, but it requires stitching together multiple components. The benefit is that it’s not tied to a single vendor and can be customized to the specific needs of the project. |
Table 1. A comparative analysis of the NVIDIA and non-NVIDIA workflows
Figure 3 illustrates a software stack for the multi-layered architecture for agentic edge AI systems that we introduced in a previous article to show where the commercial and open-source tools discussed will be positioned.
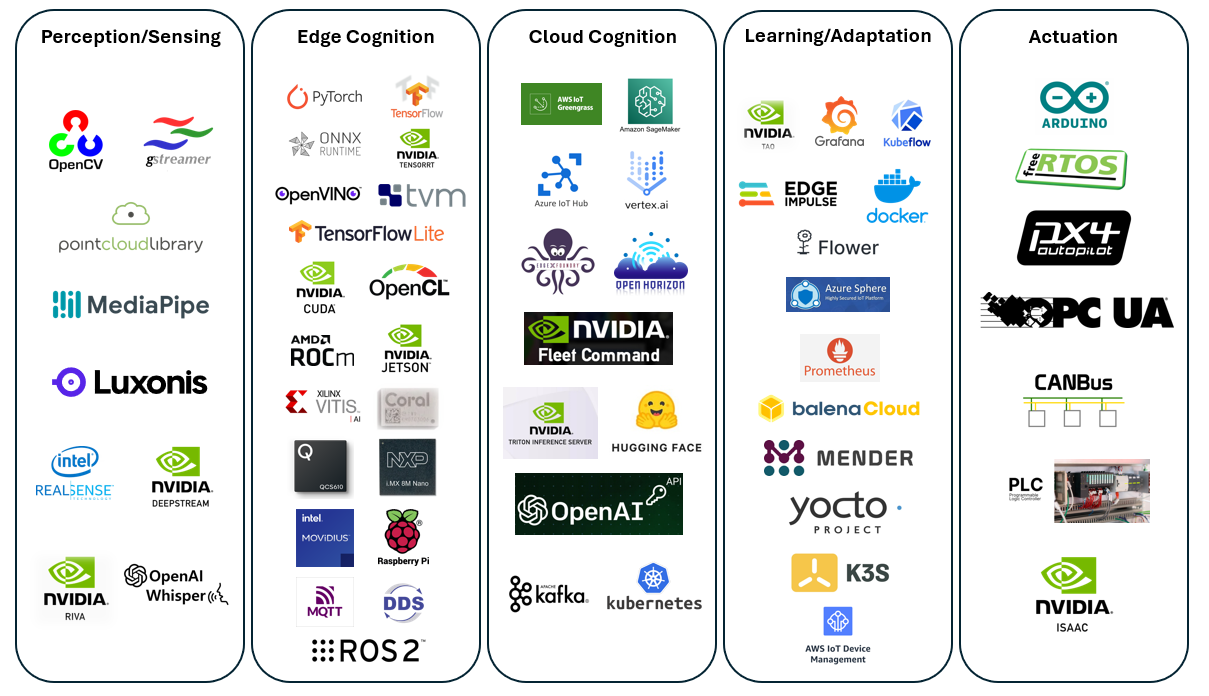
Figure 3. A diagram of commercial and open-source software stack for the multi-layered agentic edge AI architecture. Due to the fast evolution of AI and AI companies, this diagram and the list of companies in each stack may have changed since the publishing of this article.
Attack propagation in agentic edge AI as a Markov Chain
Trend Research also created a Markov Chain that shows how a compromise can propagate across the end-to-end pipeline:
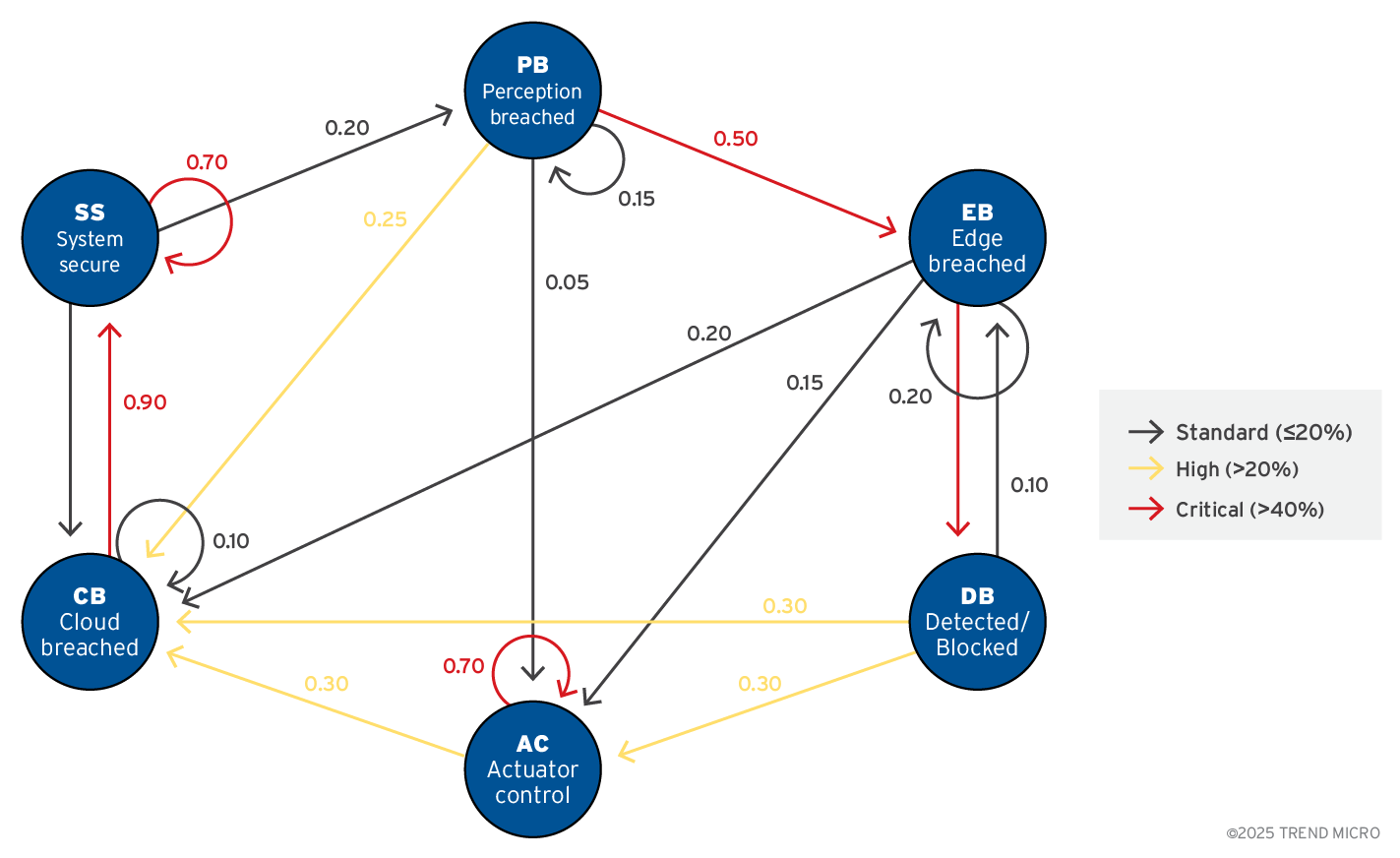
Figure 4. Attack propagation in agentic edge AI presented as a Markov Chain
The security posture in agentic edge AI devices moves through the following states: System secure, Perception breached, edge breached, Cloud breached, Actuator control, and Detected/Blocked. Most of the time, the system loops in “System secure.”
After a successful initial access, the state transitions to “Perception breached.” From there, the typical route forward is a deeper compromise: “Edge breached” to “Cloud breached” and, in the worst-case scenario, “Actuator control.” At every stage, there’s a significant chance of being “Detected/blocked” (via monitoring, policy checks, or runtime guards), which then tends to return the state to “System secure” after remediation actions.
For security engineers, two aspects make this model actionable: progression odds and eject-to-defense odds. Progression odds quantify how likely an intrusion at the sensing layer is to cascade into compute, then cloud, then actuators.
Eject-to-defense odds quantify how often controls expel the incident out of the chain. Increasing detection and containment odds at every breach stage (strong attestation at perception, anomaly detection at edge, least-privilege and rate-limits in cloud, interlock checks before actuators) reduces the probability of the breach reaching actuator control.
This model intentionally remains minimal to clearly demonstrate the end-to-end compromise propagation.
Cybersecurity threats to development tools and workflows
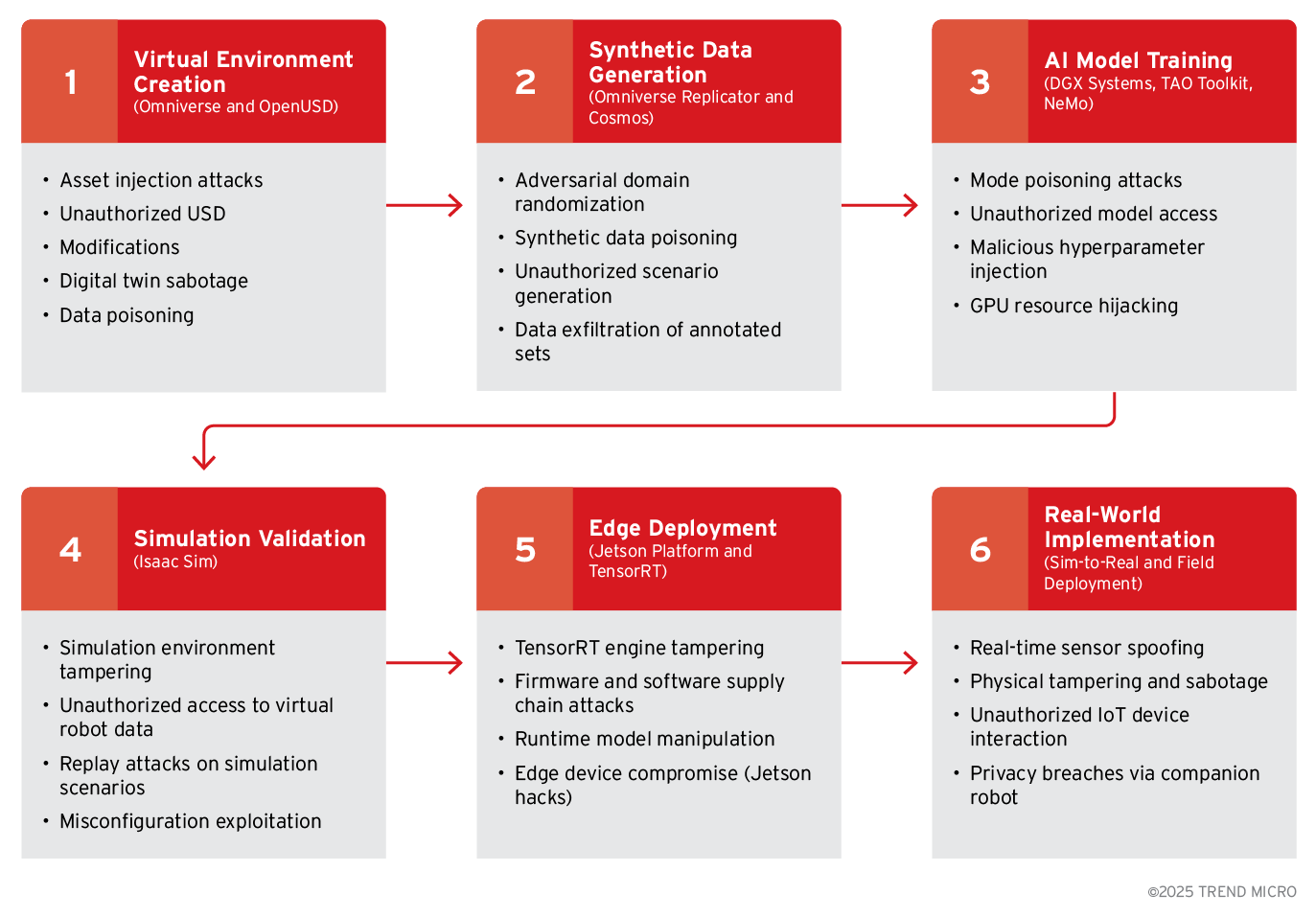
Figure 5. Cyberthreats against our sample NVIDIA Omniverse workflow
Every step in an agentic edge AI development pipeline, whether built with NVIDIA Omniverse and Isaac or with ROS 2, Gazebo, PyTorch, and ONNX, introduces its own attack surface. Threats begin from the creation of the digital twin and continue through training, deployment, and time spent in field service. Recognizing where each risk enters the lifecycle is the first step to layering defenses.
Stage 1: Virtual 3D environment construction
- Attackers can inject rogue meshes, textures, or Universal Scene Description (USD) and/or Unified Robot Description Format (URDF) files that embed hidden geometry or malicious scripts, sabotaging downstream perception and control logic.
- Unauthorized edits to digital-twin physics (mass, friction, lighting) create a silent train–test mismatch, causing robots to behave unpredictably in the real world.
- Compromised asset repositories or unsecured cloud buckets allow adversaries to steal proprietary plant layouts or CAD models, exposing sensitive operational details.
- Malicious actors could potentially poison digital twin metadata, e.g., by altering coordinate frames or camera intrinsics, which causes simultaneous localization and mapping (SLAM) or calibration routines to find incorrect results.
Stage 2: Synthetic data generation
- Malicious data-generation scripts skew domain randomisation, overrepresenting benign scenarios and under-representing safety-critical edge cases that the model will later miss.
- Synthetic images or point-clouds could be deliberately mislabelled to implant backdoors that only activate under attacker-chosen conditions in the field.
- Unauthorised scenario templates (weather, traffic, obstacle placements) inserted into Omniverse Replicator, Unity, or Unreal projects bias the data distribution without detection.
- Data exfiltration from poorly secured render nodes or worker virtual machines (VMs) can leak painstakingly annotated datasets to competitors or threat actors.
Stage 3: Model training and validation
- Even with limited cluster access, attackers can inject poisoned gradients, alter loss functions, or tweak hyperparameters to steer optimization towards unsafe outcomes.
- GPU or Tensor Processing Units (TPU) queues may be hijacked for cryptomining or covert model theft, starving legitimate jobs of compute time and leaking valuable architectures or checkpoints.
- Weak access controls on model-artifact storage could allow attackers to download, tamper with, or replace trained weights, embedding trojans before deployment.
- Simulation-validation environments (e.g., Isaac Sim, Gazebo, CARLA) could be replay-attacked or configuration-patched to hide failure cases, giving a false sense of safety.
Stage 4: Deployment on edge hardware
- If TensorRT, ONNX-Runtime, or OpenVINO binaries are unsigned, attackers can patch inference engines with hidden layers that alter predictions at runtime.
- Supply-chain compromises such as malicious Debian packages, poisoned Docker images, or counterfeit Jetson or neural processing unit (NPU) boards undermine secure-boot guarantees before devices ship.
- Unfused eFUSE settings, or open debug ports like Universal Asynchronous Receiver/Transmitter (UART), Joint Test Action Group (JTAG), or Serial Wire Debug (SWD), give physical attackers root access and let them steal firmware or alter live memory.
- Real-time sensor spoofing with GPS drifts and/or LiDAR shadows, RF jamming, or laser blinding can fool perception. As a result, insecure Message Queuing Telemetry Transport (MQTT) or Controller Area Network (CAN) channels could allow adversaries to issue actuator commands or siphon telemetry.
Mitigation strategies for the 4-stage agentic edge AI workflow
Mitigating cyber risks in the agentic edge AI development lifecycle requires clear, repeatable actions that span designing, building, and deployment phases. Applied consistently, these actions help safeguard intellectual property, ensure regulatory compliance, and maintain the reliability of autonomous edge products. To secure agentic edge AI workflows, we recommend the following best practices:
Protect assets and data
- Signed assets. These require cryptographic hashes and store immutable references for every USD, URDF, or CAD file so rogue meshes or hidden scripts cannot be injected into the digital twin.
- Read-only, version-controlled scene repositories. Control asset changes using pull-request reviews and automated diff-scanners that detect unauthorized edits to physics, lighting, or coordinate frames.
- Encrypted model vaults in trusted execution environments (TEE). These store inference weights and calibration data in Trusted Platform Module (TPM) or Intel Software Guard Extensions (SGX) enclaves or Arm Confidential Compute Architecture (CCA) realms to defeat physical extraction and cold boot attacks.
- Secure domain-randomization templates. Lockdown domain randomization templates by requiring code review for random-seed scripts and scenario YAMLs, preventing attackers from skewing weather, lighting, or traffic.
- Isolated rendering and annotation sandboxes. Spin up Replicator, Unreal, and Gazebo workers in no-egress containers; enforce per-job IAM roles to prevent dataset exfiltration.
Scan and verify components
- Protected model checkpoints and artifacts. Export weights through CI pipelines that automatically sign, store, and verify each checkpoint before promotion to “gold” status.
- Runtime attestation of inference engines. Scan and seal TensorRT/ONNX-Runtime/OpenVINO binaries; refuse to load if hashes deviate from signed manifest.
- Immutable container images and digest pinning. Deploy only Open Container Initiative (OCI) images referenced by full Secure Hash Algorithm (SHA) digests and scan each layer for common vulnerabilities and exposures (CVEs) and license red flags.
- Synthetic-data software bills of materials (SBOMs) and dataset hashing. Bundle generated batch (images, point clouds, annotations) with tracking metadata and SHA-256 digests to detect later tampering or loss.
- Deterministic replay validation. Run a nightly, hash-locked simulation suite (Isaac Sim/Gazebo/CARLA) to detect replay tampering or silent config drift that hides failure cases.
- Hyper-parameter governance. Store tuning configurations in Git and run diff audits to flag unusual patterns in loss, learning rate, or augmentation that indicate poisoning.
Secure hardware and firmware
- Hardware secure-boot and JTAG fuse-off. Enable a hardware secure boot to establish a chain of trust from the boot ROM and physically disable JTAG and debug headers with eFuses or epoxy after production.
- SBOM-verified firmware supply chain. Embed SBOMs in Jetson or NPU firmware and validate them at install time to block counterfeit parts or malicious vendor blobs.
- Sensor-fusion anomaly filters. Cross-validate camera, LiDAR, radar, and inertial measurement unit (IMU) streams to sanity check input and quarantine outliers caused by spoofing, jamming, or replay.
- GPU/TPU access hardening. Use rootless Kubernetes, MIG/TDX/SEV-SNP attestation, and resource quotas so cryptojacking or side-channel snooping cannot hijack expensive accelerators.Safeguard communication and updates
- Strong mutual Transport Layer Security (mTLS) service mesh. Wrap ROS 2 data distribution service (DDS), MQTT, Hypertext Transfer Protocol version 2 (HTTP/2), or CAN-over-Ethernet links in mTLS with Secure Production Identity Framework For Everyone (SPIFFE) or SPIFFE Runtime Environment (SPIRE) identities to block command injection and man-in-the-middle.
- Over-the-air (OTA) canary and rollback framework. Release firmware/model updates to <1 % of fleet first, monitor anomaly metrics, and support cryptographically-signed rollback to last-known-good if faults arise.
Monitor systems, enforce limits, and hold drills
- Behavioural allow-lists and safe envelopes. Hard-code limits for actuator speed or torque, sensor ranges, and central processing unit (CPU) or GPU budgets; any deviation triggers a software kill-switch or hardware e-stop.
- Comprehensive audit logging and security information and event management (SIEM) integration. Maximize the protocol where edge devices stream signed logs (asset hashes, training loss, sensor stats) to a central security operations center (SOC) for real-time anomaly detection.
- Privacy-by-design data minimisation. Strip personally identifiable information (PII) from telemetry, apply differential privacy when aggregating user data, and allow local-only modes to limit breach impact.
- Red team drills. Simulate asset injection, gradient poisoning, OTA hijacking, sensor spoofing, and physical tampering events; feed lessons into continuous security hardening.
Deploying this unified, defense-in-depth strategy across all four stages turns asset sabotage, data poisoning, model tampering, and edge hijacking into manageable, auditable risks. This ensures the safety of autonomous behaviour and the integrity of intellectual property throughout the agentic-edge-AI lifecycle.
Trend customers can use Trend Vision One™ Container Security to provide runtime protection, vulnerability scanning, and misconfiguration detection for containers, including sandboxed environments. Vision One can also be used as a centralized logging and SIEM integration for anomaly detection.
Trend Vision™ One Endpoint Security can also be deployed on IoT devices, with available integrations for OT endpoint monitoring.
Book a consultation with Trend Vision One services to see how we can help assess your security posture.
Conclusion
Agentic edge AI is the future of IoT and IIoT, and it moves from concept to deployed reality driven by on-device AI hardware, small language models, large language models (compressed, distilled, or quantized versions to run on power-constrained IoT/IIoT devices), and a multi-layered architecture that combines perception, cognition, learning, and actuation at the edge.
These agentic edge AI systems unlock real-time autonomy, cut cloud dependency, and open new markets for home robotics, industrial automation, and defense. But the same capabilities that provide systems autonomy also enlarge their attack surfaces.
Threat actors can target every layer: spoofing sensors, poisoning AI models, hijacking control channels, or infiltrating cloud pipelines. Our previously published article shows how compromise can cascade across layers, turning a helpful agent into a safety hazard. Risk is also amplified by complex development and deployment workflows that rely on large toolchains, synthetic data, and continuous updates.
Secure-by-design engineering is paramount. Organisations must implement cryptographically verified boot, hardware roots of trust, redundant sensor fusion, adversarial-robust ML, signed model rollouts, and zero-trust networking from day one. Development teams should treat the simulation-to-deployment toolchain as production-critical, enforcing SBOMs, sandboxed rendering, deterministic replay tests, and hardware attestation.
Compliance with safety-of-motion standards such as ISO 13849-1, ISO 10218-1/-2, and ISO 26262 (for autonomous vehicles) will provide a measurable baseline for actuator integrity. By integrating these controls, vendors can create agentic edge AI systems that are autonomous, resilient, and most importantly, trustworthy.
The business benefits of agentic edge AI are clear: faster responses, lower bandwidth costs, and tailored customer experiences. The cost of ignoring security is likewise apparent: physical harm, data breaches, regulatory penalties, and reputational loss. Secure agentic edge AI is not optional; it is the next competitive frontier.
Like it? Add this infographic to your site:
1. Click on the box below. 2. Press Ctrl+A to select all. 3. Press Ctrl+C to copy. 4. Paste the code into your page (Ctrl+V).
Image will appear the same size as you see above.
Recent Posts
- TrendAI™ 2026 Cyber Risk Report
- The Hidden Risk in Your AI Rollout: Your Endpoints
- When AI Becomes a Zero-Day Machine: What Public Sector Organizations Need to Know
- A Data-Driven View of Cyber Risk Structure: How Attack Pressure and Exposure Shape Damage
- Hunt Them All: An AI-Powered Vulnerability Sweep of 19,000 MCP Servers
 Fault Lines in the AI Ecosystem: TrendAI™ State of AI Security Report
Fault Lines in the AI Ecosystem: TrendAI™ State of AI Security Report It’s By Design: The Use-After-Free of Azure Cloud
It’s By Design: The Use-After-Free of Azure Cloud TrendAI™ 2026 Cyber Risk Report
TrendAI™ 2026 Cyber Risk Report Guarding LLMs With a Layered Prompt Injection Representation
Guarding LLMs With a Layered Prompt Injection Representation