By David Fiser
Serverless environments are becoming more popular, often featuring services for business operations and expansion such as built-in scalability, availability for multiple regions, and cost manageability. Almost every major cloud service provider (CSP) offers a serverless environment service one way or another, with currently the most popular examples being Amazon Web Services (AWS) Lambda and Azure functions, among other platforms and providers.
Considering this, we can also imagine a serverless application as a piece of code executed inside a specific cloud infrastructure. This code execution can be triggered in different ways such as by an HTTP API endpoint or an event. From a security perspective, we can distinguish between the security of the executed code and the environment where the code is executed. While CSPs can’t do much about the actual code executed as it is mainly the user’s responsibility, they can influence the environment of the execution.
We have previously written about the dangers of improper risk management, and the same risks also apply for CSPs and their respective services. In that context, we would like to describe an unsecure practice used by various developers that have also been transferred to cloud environments.
Environment variables
Based on our research, we identified the major security risk hidden in environment variables. These are used to store preauthorization tokens for certain services that can be or are linked with the execution context, which is a serverless function in this case. The biggest contrast we can spot is that, for example in Azure, the service does a lot to protect secrets: storing them in encrypted form and transferring them using secure channels. Hence, in the end, the secrets are stored inside the execution context as a plain text environment variable. Once leaked, it could potentially lead to attack scenarios involving arbitrary code execution as a consequence dependent on specific cloud architecture, or leaks of organizational proprietary information and storage data if these secrets are used for multiple applications.
From a security perspective, this is completely wrong. Environment variables are available in every process within the execution context, which means that whatever process is executed contains your plaintext secret—even if the process has no need to use it. From a developer’s perspective, we can understand that this architectural flaw as a shortcut is an accepted risk. But from a security perspective, we think this is completely risky and carries a number of security consequences and potential threat scenarios.
Risks in Environment Variables
The next paragraphs will show an attack scenario that can be used inside the Azure Functions environment. Once abused, this scenario can lead to a remote code execution (RCE), function code leak, and function code overwrite.
Note that the following scenario requires a vulnerability inside the deployed function or environment, leading to the information leak of an environment variable. We still witness newly discovered vulnerabilities and there are still instances wherein the user overlooks using the serverless environment in the “right” way.
Among a number of areas for abuse, one of the environment variables that can be exploited upon a leak within the Azure environment is AzureWebJobsStorage. This variable contains a connection string that authorizes the user to use AzureStorage where the actual deployed function code is stored, including common file operations such as move, delete, and upload, among other functions.
This connection string can be used together with Microsoft Azure Storage Explorer for manipulating the leaked storage account.
 Figure 1. Connection string placed in Storage Explorer
Figure 1. Connection string placed in Storage Explorer
When connected, the user can simply delete and upload a new version of the serverless function.
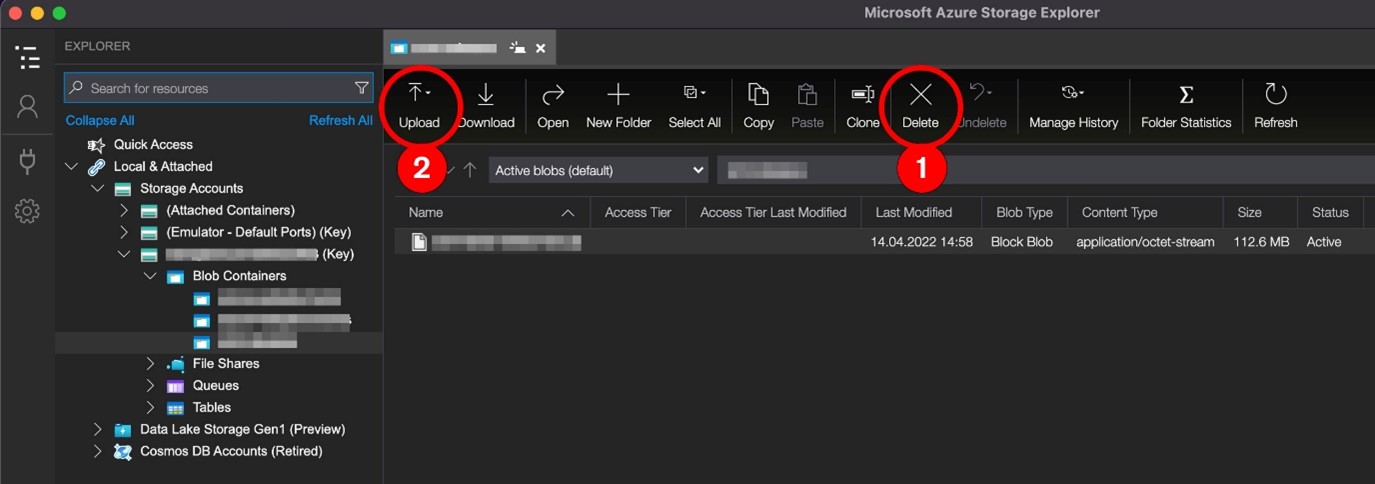 Figure 2. The attack scenario using Storage Explorer
Figure 2. The attack scenario using Storage Explorer
Video 1. Proof of concept: Leaking secrets stored as an environment variable
What is the right approach? We highly suggest that developers and teams avoid using environment variables for storing secrets in deployed applications.
The common argument is that secrets must be decrypted or used as plaintext at some point within the memory. While true, the trick is to limit the time to a minimum and ensure a secure wipe of the memory region as soon as possible because we don’t need the secret to ensure that the memory is no longer available for leaks. We can see this approach in several operating system (OS) applications, so why are DevOps not adopting this approach?
It is also important to note that even when a key vault binding is used to obtain the mandatory connection string for a serverless function, it is still going to be expanded to the environment variable.
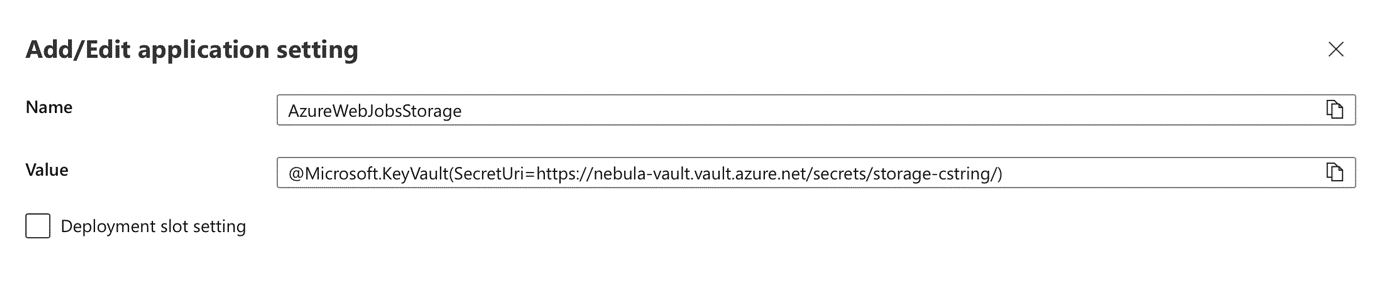 Figure 3. An example of linking application secrets from the vault to an environment variable
Figure 3. An example of linking application secrets from the vault to an environment variable
This might also require the change of architectural perspective for obtaining the secret or authorization, which can be done even without a secret wherein security is hardened and a completely different architecture will be used. An example for this would be a different approach for storage of source code – with read permission only available to the serverless container.
Another “architectural” question is, do we truly need all the sensitive information, or are they just inherited from the environment above? And in case we really need them, we can at least use role-based access control (RBAC) to prevent operations such as delete and upload, among others, which are not needed for the application functionality anyway.
Risk mitigation and areas for exploration
These risks can be mitigated by disabling the storage account key access inside the storage account settings. However, developer tools like Azure Visual Studio Code extension can be affected and make users unable to upload the new serverless function there. Another mitigation recommendation is to limit the network access to the storage account using virtual networks. A downside to this approach can be additional costs to the user.
In the end, we will never have perfect security against attacks such as code execution (as a result of code vulnerabilities), but we can prevent simple information leaks that can lead to RCE abuse and attacks.
We also can also perform the following mitigation steps that can reduce the risks of the threat scenarios:
- Consider following the security recommendations provided by Azure’s documentation
- Regularly conduct peer code reviews within the team and including the security team
- Harden API security for serverless applications and avoid exposing the entirety of the API publicly
- Limit the public’s access for invoking serverless functions, as well as users’ access within virtual networks
- If possible, avoid storing secrets and other sensitive information in the environment variables; choose more secure means and tools (such as vaults) for storing secrets, limit their availability to specific personnel, and ensure their secure transport
- Properly secure environments that communicate within serverless functions
Like it? Add this infographic to your site:
1. Click on the box below. 2. Press Ctrl+A to select all. 3. Press Ctrl+C to copy. 4. Paste the code into your page (Ctrl+V).
Image will appear the same size as you see above.
Messages récents
- TrendAI™ 2026 Cyber Risk Report
- The Hidden Risk in Your AI Rollout: Your Endpoints
- When AI Becomes a Zero-Day Machine: What Public Sector Organizations Need to Know
- A Data-Driven View of Cyber Risk Structure: How Attack Pressure and Exposure Shape Damage
- Hunt Them All: An AI-Powered Vulnerability Sweep of 19,000 MCP Servers
 Fault Lines in the AI Ecosystem: TrendAI™ State of AI Security Report
Fault Lines in the AI Ecosystem: TrendAI™ State of AI Security Report It’s By Design: The Use-After-Free of Azure Cloud
It’s By Design: The Use-After-Free of Azure Cloud TrendAI™ 2026 Cyber Risk Report
TrendAI™ 2026 Cyber Risk Report Guarding LLMs With a Layered Prompt Injection Representation
Guarding LLMs With a Layered Prompt Injection Representation