
Una forma de inteligencia artificial (IA) que permite que los sistemas aprendan patrones que se encuentran en la información y mejoren su desempeño en tareas a través del tiempo sin ser programados explícitamente.
Índice
El machine learning utiliza algoritmos y modelos estadísticos para hacer predicciones o decisiones de acuerdo con la información ingresada. El que las computadoras puedan decidir qué hacer sin tener que seguir órdenes explícitas ha capturado la imaginación del público por mucho tiempo.
La idea de un vehículo que puede llevarlo sin que usted tenga que conducir, que pueda identificar peatones y baches y que pueda responder rápida y eficientemente a cambios en el ambiente para llevarlo hacia su destino final – eso es el machine learning (ML) en la práctica.
¿Cómo funciona? Comencemos con solamente analizar datos de negocio.
ML es un tipo de IA que permite que las empresas comprendan cantidades masivas de información y aprendan de ella. Requiere de un trabajo considerable para que las empresas obtengan información valiosa. Para aprovechar ML al máximo, debe tener datos limpios y debe saber qué quiere responder con ellos. Entonces selecciona el mejor modelo y algoritmo para beneficiar a su negocio. ML no es un proceso simple o sencillo. Su éxito requiere de trabajo constante.
Hay un ciclo de vida para ML:
- Entendimiento del negocio. Definiendo el problema, los criterios de éxito y evaluar si ML es el enfoque correcto.
- Recopilación y limpieza de datos. Usted tiene la cantidad necesaria de información y se ha limpiado efectivamente, por lo que está lista para entregar los insights que necesita.
- Selección de características. El proceso de elegir cuáles variables de entrada (funcionalidades) usará para crear el modelo. Los métodos incluyen pruebas estadísticas, regularización o medidas de importancia basadas en algoritmos. Por ejemplo, los árboles de decisión definen las características en criterios como ganancia de información o la impureza de Gini.
- Selección del modelo. Elegir un algoritmo y modelo apropiados, entonces entrenarlo con información.
- Educar y afinar. Ajustar el modelo a los datos y ajustar parámetros para mejorar el desempeño.
- Evaluación del modelo y del algoritmo para determinar si está listo para su uso, o si tiene que regresar algunos pasos y refinar su modelo, característica, algoritmo o datos para lograr sus objetivos.
- Despliegue del modelo educado hacia producción.
- Revisión de las salidas del modelo existente en producción

¿Para qué se usa el machine learning?
El machine learning es una forma en la que los negocios pueden entender y aprender de sus datos. Un negocio puede usarlo para un gran número de aplicaciones. El caso de uso dependerá si una empresa busca mejorar sus ventas, ofrecer una capacidad de búsqueda, integrar comandos de voz a su producto, o crear un vehículo autónomo.
Subcampos de machine learning
ML tiene una gran variedad de usos en los negocios actuales, y solamente puede incrementar y mejorar con el tiempo. Los subcampos de ML incluyen redes sociales y recomendaciones de producto, reconocimiento de imágenes, diagnósticos de salud, traducción de idiomas, reconocimiento de voz y minería de datos, por nombrar algunos.
Las plataformas de redes sociales, como Facebook, Instagram o LinkedIn usan ML para recomendar páginas para seguir o grupos a los cuales unirse basado en las publicaciones que le “gustan”. Toma datos históricos de lo que otros ha preferido o qué otras publicaciones son similares a sus preferencias, se las recomienda, o se las agrega a su sección de noticias.
También es posible usar ML en un sitio de eCommerce para recomendarle productos basado en compras interiores, sus búsquedas y las acciones de otros usuarios similares a usted.
Otro uso importante de ML actualmente es en el reconocimiento de imágenes. Las plataformas de redes sociales han recomendado etiquetar personas en sus fotos basándose en ML. La policía ha podido aprovechar esto, buscando sospechosos en fotos o videos. Con la gran cantidad de cámaras instaladas en aeropuertos, tiendas y puertas, es posible identificar a quien haya cometido un crimen o saber hacia dónde se dirigió.
Los diagnósticos de salud también son un buen uso de ML. Después de un evento como un ataque cardiaco, es posible regresar y ver las señales de alerta que se pasaron por alto en su momento. Un sistema usado por doctores u hospitales podría ser alimentado con información médica del pasado para ver las conexiones desde las entradas (comportamiento, resultados de examinaciones o síntomas) hasta las salidas (por ejemplo, un ataque cardíaco.) Entonces cuando el doctor ingresa sus notas y resultados al sistema en el futuro, la máquina podrá detectar los síntomas de un ataque cardíaco con mucha más precisión que los humanos, por lo que el paciente y el doctor pueden hacer cambios para prevenirlo.
La traducción de idiomas en las páginas web o las aplicaciones es otro ejemplo de ML. Algunas aplicaciones hacen un mejor trabajo que otras, lo cual va a depender del modelo, la técnica y los algoritmos que utilicen.
Un uso diario de ML que no siempre tenemos presente está en las tarjetas de crédito. Hay señales de fraude que el ML puede detectar rápidamente y que le tomarían a los humanos un largo tiempo en descubrir, si es que las descubren. La gran cantidad de transacciones que se han examinado y etiquetado (fraude o no) pueden permitirle al ML aprender a detectar el fraude en una sola transacción en el futuro. El ML que es genial para lograr esto es el data mining.
Data mining
Data mining es un tipo de ML que analiza datos para hacer predicciones o descubrir patrones dentro de big data. El término puede llegar a ser un poco engañoso porque no requiere de nadie, ya sea un empleado o un actor malicioso, buscando entre sus datos para encontrar un elemento que sea útil. En su lugar, este proceso involucra descubrir patrones útiles en los datos para tomar decisiones informadas en el futuro.
Por ejemplo, tome una empresa de tarjetas de crédito. Si usted tiene una tarjeta de crédito, es probable que su banco le ha notificado en algún momento acerca de actividades sospechosas con su tarjeta. ¿Cómo logra el banco detectar tales actividades sospechosas tan rápido, mandando una alerta de forma casi instantánea? Es el data mining continuo que permite esta protección contra fraudes.
Deep learning
Deep learning es un tipo específico de ML basado en redes neuronales. Una red neuronal busca emular cómo las neuronas en un cerebro humano entienden algo o toman una decisión. Por ejemplo, un niño de seis años puede ver un rostro y distinguir a su mamá porque el cerebro analiza varios detalles rápidamente – color del cabello, características faciales, cicatrices, etc. – en un abrir y cerrar de ojos. El machine learning replica esto en la forma de deep learning.
Una red neuronal tiene de 3 a 5 capas: una capa de entrada, una a tres capas ocultas y una capa de salida. Las capas ocultas toman las decisiones que llegan a la capa de salida. ¿Cuál color de cabello? ¿Cuál color de ojos? ¿Hay alguna cicatriz? Conforme las capas incrementan hasta llegar a los cientos o más, se le llama deep learning.
Tipos de machine learning
Existen fundamentalmente 4 tipos de algoritmos de machine learning: supervisado, semi-supervisado, no supervisado y reforzado. Los expertos en ML creen que aproximadamente el 70% de los algoritmos en uso actualmente son supervisados. Trabajan con conjuntos de datos conocidos o etiquetados – por ejemplo, fotografías de perros y gatos. Los dos tipos de animales son conocidos, por lo que los administradores pueden etiquetar las fotos antes de dárselas al algoritmo.
Los algoritmos ML no supervisados aprenden de conjuntos de datos no conocidos Tome, por ejemplo, los videos de TikTok. Hay tantos videos de temas tan variados que es imposible educar a un algoritmo a partir de ellos de forma supervisada; los datos aún no están etiquetados.
Los algoritmos ML semi-supervisados son educados inicialmente con un conjunto de datos pequeño que es conocido y está etiquetado. Entonces se le aplica a un conjunto de datos más grande sin etiquetar para continuar su capacitación.
Los algoritmos ML reforzados no son educados inicialmente. Aprenden a base de prueba y error sobre la marcha. Piense en un robot que está aprendiendo a navegar un terreno rocoso. Cada vez que se cae, aprende qué es lo que no funciona y entonces altera su comportamiento hasta que es exitoso. Piense en el entrenamiento de los perros y el uso de los premios para enseñar varios comandos. Con un refuerzo positivo, el perro continuará realizando los comandos y cambiar el comportamiento que no tenga una respuesta favorable.
Machine learning supervisado vs. no supervisado
Machine learning supervisado
Usa conjuntos de datos conocidos, establecidos y clasificados para encontrar patrones. Elaboremos sobre la idea previa de las fotos de perros y gatos. Podría tener un conjunto masivo de datos, lleno de miles de animales diferentes en millones de fotos. Ya que los tipos de animales son conocidos, estos podrían haberse agrupado y etiquetado antes de dárselos al algoritmo supervisado de ML para que aprenda.
El algoritmo supervisado ahora compara las entradas con las salidas y la foto con la etiqueta del tipo de animal. Eventualmente aprenderá a reconocer un cierto tipo de animal en nuevas fotos que llegue a encontrar.
Machine learning no supervisado
Los algoritmos no supervisados de ML son como los filtros actuales de SPAM. Inicialmente, los administradores podían programar los filtros de SPAM para buscar palabras específicas en el correo para entender que se trata de SPAM. Eso ya no es posible, entonces algo no supervisado funciona bien aquí. El algoritmo ML no supervisado se ve alimentado con emails que no han sido etiquetados para comenzar a buscar patrones. Conforme se encuentran esos patrones, aprenderá cómo se ve el SPAM y podrá identificarlo en un ambiente de producción.

Técnicas de machine learning
Las técnicas de ML resuelven problemas. Dependiendo del problema que enfrente, se elige una técnica específica de ML. Estas son 6 técnicas comunes.
Técnica de regresión
La regresión puede utilizarse para predecir precios en el mercado de bienes raíces o determinar el precio óptimo al cuál vender una pala de nieve en Minnesota en diciembre. La regresión dice que aunque los precios fluctúan, siempre regresarán a la media, incluso aunque con el tiempo los precios de las casas están incrementando, existe un promedio que siempre ocurrirá. Puede mapear precios a lo largo del tiempo en una gráfica y encontrar esa media conforme avanza el tiempo. Conforme la línea roja continúa escalando en la gráfica, permite que se puedan realizar predicciones.
Clasificación
La clasificación se utiliza para agrupar los datos en categorías conocidas. Podría estar buscando clientes que son predeciblemente buenos clientes (siempre regresan y gastan más dinero) o que podrían comenzar a comprar en otro lado. Si pudiera analizar el historial y encontrar datos que fueran característicos de cada grupo de clientes, aplicaría esta información a sus clientes actuales y podría predecir en qué grupo estarían Entonces podría ajustar sus esfuerzos de mercadotecnia y posiblemente convertir al cliente que iba a irse en un cliente leal. Este es un buen ejemplo de ML supervisado.
Clustering
A diferencia de la técnica de clasificación, el clustering es ML no supervisado. En el clustering, el sistema encontrará cómo agrupar datos que usted no sabe cómo clasificar. Este tipo de ML es excelente para analizar imágenes médicas, redes sociales o buscar anomalías.
Google usa clustering para la generalización, la compresión de datos y preservación de la privacidad en los productos, como en videos de YouTube, aplicaciones Play y música.
Detección de anomalías
La detección de anomalías se usa cuando está buscando anomalías, como una aguja en un pajar. Cuando se observa una cantidad masiva de datos, estas anomalías pueden ser imposibles de detectar por ojos humanos. Pero, por ejemplo, si un científico de datos alimenta información de facturación de varios hospitales a un sistema, la detección de anomalías encontraría una forma de agrupar la facturación. Podría descubrir un conjunto de anomalías que podrían ocultar un fraude.
Market basket analysis
La lógica del market basket analysis permite hacer predicciones del futuro. Un ejemplo simple – si los clientes pusieron carne molida, tomates y tacos a su canasta, podría predecir que agregarían queso o crema. Estas predicciones podrían usarse para generar ventas extra al hacer recomendaciones valiosas para los compradores en línea de objetos que podrían haber olvidado, o para agrupar ciertos elementos en una tienda.
Dos profesores en el MIT usaron este enfoque para descubrir el “heraldo del fracaso.” Resulta que algunos clientes gustan de productos que fallan. Si puede ubicarlos, puede determinar si puede continuar vendiendo un producto y qué tipo de marketing aplicar para incrementar ventas de ciertos clientes.
Datos de serie de tiempo
Los datos de serie de tiempo comúnmente se recopilan con monitores de actividad que usamos en nuestras muñecas. Puede recopilar latidos por minuto, pasos por minuto o por hora y algunos incluso ahora miden la saturación de oxígeno. Con estos datos, sería posible predecir cuando alguien saldrá a correr en el futuro. También podría ser posible recopilar datos acerca de maquinarias y predecir fallas debido a los datos acerca de niveles de vibración, nivel de ruido en dB y presión.
Algoritmos de machine learning
Si el ML se supone debe aprender de los datos, ¿cómo se diseña el algoritmo de aprendizaje y hallazgo de datos estadísticamente significativos? Los algoritmos de ML soportan el proceso supervisado, no supervisado o reforzado.
Los ingenieros de datos escriben piezas de código que son los algoritmos que permiten que una máquina aprenda o halle significado en los datos.
Exploremos algunos algoritmos comunes. Este es el top 5 en uso actualmente.
- Los algoritmos de regresión lineal establecen una relación al ajustar variables dependientes e independientes en una gráfica y graficar una línea recta sobre la media o la tendencia. Merriam-Webster define la regresión como "una función que da como resultado el valor promedio de una variable al azar bajo la condición de que una o más variables independientes tienen valores específicos." Esta definición también aplica para la regresión logística.
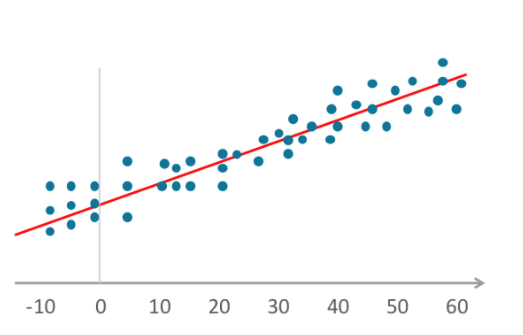
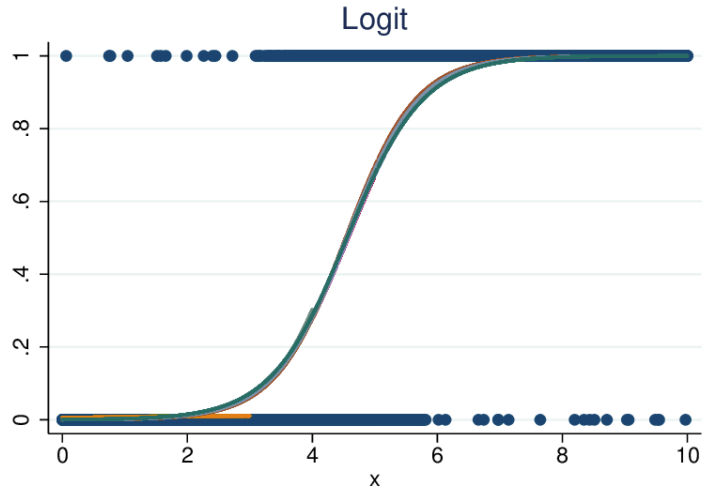
- La regresión logística (también conocida como logit) también mapea variables en una gráfica, como la regresión lineal, pero la línea resultante no es recta. La línea aquí es una función sigmoidea.
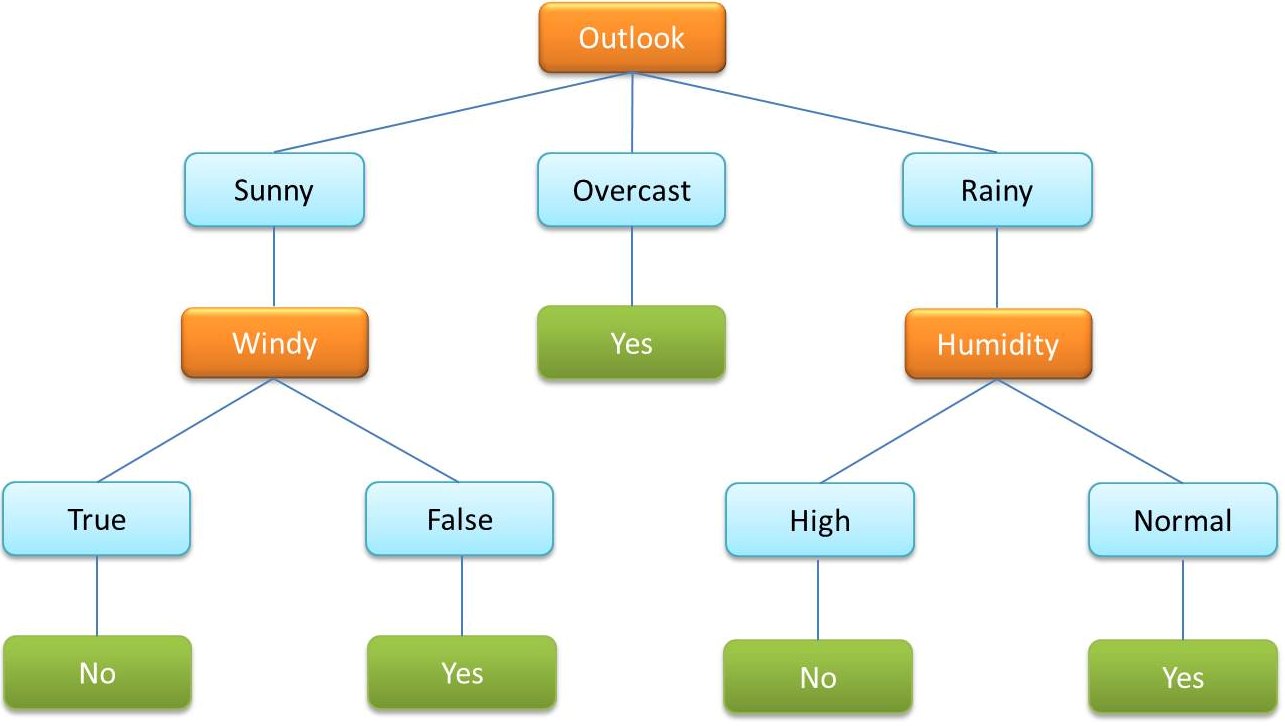
- Un árbol de decisión es un algoritmo usado comúnmente en el ML supervisado. Se utiliza para clasificar datos por variables categóricas y continuas.
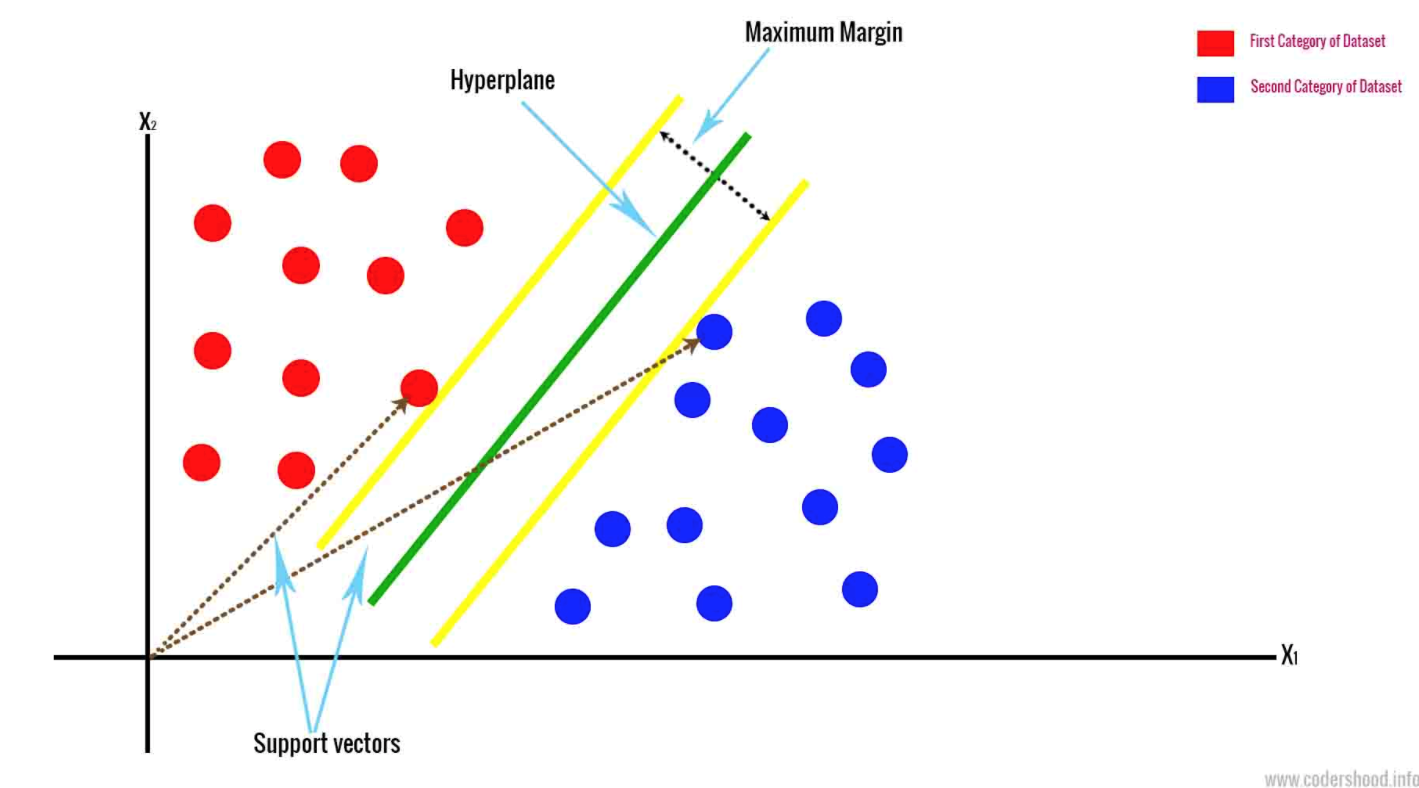
- Support Vector Machine hace un hiperplano basado en los dos puntos de datos más cercanos. Esto separa los datos al marginalizar las clases. Clasifica los datos basado en un espacio n-dimensional. N representa el número de características diferentes que existen.
- Naive Bayes calcula la probabilidad de un resultado particular. Es muy efectivo y supera modelos más sofisticados de clasificación. Un modelo de clasificación de Naive Bayes entenderá que cualquier característica dada no está relacionada con la presencia de otras características particulares.
Modelos de machine learning
Después de combinar el tipo de ML (supervisado, no supervisado, etc.), las técnicas y los algoritmos, el resultado es un archivo que ha sido “entrenado”. Ahora se le pueden dar nuevos datos a este archivo y podrá reconocer patrones y hacer predicciones o tomar decisiones para el negocio, el gerente o el cliente conforme sea necesario.
Los mejores lenguajes para el machine learning
Los lenguajes de machine learning son cómo se escriben las instrucciones para que el sistema las aprenda. Cada idioma tiene una comunidad de usuarios para el soporte y aprender de o guiar a otros. Existen bibliotecas incluidas con cada lenguaje que usa el machine learning.
Este es el top 10:
- Python
- R
- Java
- Julia
- Scala
- C++
- JavaScript
- Lisp
- Haskell
- Ir
Python machine learning
Ya que Python es el lenguaje para ML más común, aquí hay algunos detalles más sobre este específicamente.
Python es un lenguaje interpretado, de código abierto, orientado a objetos llamado así por Monty Python. Debido a que es interpretado, se convierte a bytecode antes de que sea ejecutable por una máquina virtual de Python.
Existen una variedad de características que hacen que Python sea una de las elecciones preferidas para ML.
- Un gran conjunto de poderosos paquetes están ahora disponibles para su uso. Existen paquetes específicos para ML como numpy, scipy, and panda.
- Es fácil y rápido hacer prototipos.
- Hay una gran variedad de herramientas que permiten la colaboración.
- Conforme un científico de datos pasa de la extracción al modelado y a la actualización de su solución ML, Python puede continuar siendo el lenguaje más conveniente. El científico de datos no tiene que cambiar de lenguaje mientras avanza en el ciclo de vida.
¿Dónde puedo obtener ayuda para utilizar mejor el machine learning (ML)?
El machine learning puede mejorar significativamente la capacidad de una plataforma de ciberseguridad para proteger a su organización, a sus empleados y a sus partners al permitir una detección y respuesta ante amenazas más rápida, inteligente y proactiva.
Trend Vision One™ es la única plataforma empresarial de ciberseguridad impulsada por IA que centraliza la gestión de la exposición a riesgos cibernéticos, las operaciones de seguridad y una robusta protección en capas. Este enfoque integral le ayuda a predecir y prevenir las amenazas, acelerando la seguridad proactiva en su ecosistema digital completo. Trend Vision One ayuda a identificar amenazas conocidas y desconocidas, incluyendo exploits día-cero y campañas de phishing por medio de análisis de comportamiento a gran escala, modelos de detección de anomalías y conjuntos de datos de seguridad de gran escala.


Joe Lee es Vice Presidente de Gestión de Producto en Trend Micro, donde lidera el desarrollo y la estrategia global y de productos para soluciones empresariales de email y redes.
Preguntas Frecuentes
¿Qué es machine learning?
El machine learning es un componente de la inteligencia artificial (IA) que permite que los sistemas computacionales imiten la forma en que las mentes humanas toman decisiones complejas y aprenden de sus experiencias.
En términos sencillos, ¿qué es machine learning?
El machine learning es un tipo de IA que permite que las computadoras aprendan de la información y mejoren su desempeño con el tiempo, sin necesitar ser programadas específicamente para cada tarea.
¿Cuál sería un ejemplo de machine learning?
Un ejemplo de machine learning serían las tecnologías de reconocimiento facial, donde un sistema aprende a reconocer estímulos visuales que eventualmente le ayuda a identificar rostros humanos.
¿Cuáles son los 4 tipos de machine learning?
Los 4 tipos principales de machine learning (ML) son aprendizaje supervisado, aprendizaje no supervisado, aprendizaje semi-supervisado y aprendizaje de refuerzo.
¿Cuál es la diferencia entre IA y ML?
La inteligencia artificial (IA) se refiere a los sistemas diseñados para imitar la inteligencia humana. El machine learning (ML) es un componente de la IA que encuentra patrones en la información para mejorar el desempeño de los sistemas.
¿ChatGPT es un LLM o IA generativa?
ChatGPT es un ejemplo de tanto un LLM (modelo de lenguaje de gran tamaño) como de GenAI (IA generativa).
¿Un chatbot es IA o ML?
Los chatbots generalmente se desarrollan usando ambas tecnologías de inteligencia artificial (IA) y machine learning (ML).
¿Qué es IA pero no ML?
Algunos sistemas de IA no dependen de machine learning, como los sistemas expertos basados en reglas, los sistemas de razonamiento simbólico y los algoritmos preprogramados que siguen reglas fijas.
¿Cuál es mejor, IA o ML?
Dependiendo de lo que necesite, ninguno es “mejor”. ML es un componente de la IA que permite que los sistemas aprendan de su experiencia sin supervisión humana.
¿Debería aprender primero sobre IA o sobre ML?
Depende de sus intereses y sus objetivos. Pero la mayoría de la gente aprende de IA primero y después se especializa en los componentes, como el ML.
Artículos Relacionados