By Spark Tsao (Data Scientist)
The application of artificial intelligence (AI) across various industries has undeniably made significant improvements in the digital era. With the capability to interpret and make complex decisions based on data, AI technologies have enabled tasks or processes to function with human-like intelligence, enhancing the speed of and innovating business operations and adding valuable user experiences.
The cybersecurity industry is one of the many sectors that have greatly benefited from AI. If done efficiently, the application of AI can provide cybersecurity solutions an improved capability to detect a wide range of threats, including brand-new or unclassified ones. The process of using AI efficiently usually involves state-of-the-art models, an iterative method to improve the model’s accuracy, and accurately labeled data, among others. For many cybersecurity companies that use AI, the said requirements – particularly the process of accurately labeling data – are supported by threat experts who preprocess data and extract and engineer features, among other manual tasks or processes that produce handcrafted input. In essence, these expert-handcrafted input enable models to perform with less ambiguity by allowing the underlying structure of the data to be accurately represented, thereby enhancing threat detection capabilities.
However, the emergence of new methods for detecting threats using AI challenges the need for expert handcrafted input. Specifically, these methods involve end-to-end deep learning solutions, which are being touted by some as the next big thing in malware detection. In the pipeline of such solutions, expert handcrafted input are out of the loop and replaced with ones provided by automated processes. While this is arguably becoming more acceptable in some industries that use AI for various purposes, the absence of expert handcrafted input gives rise to the question of whether or not expert handcrafted input are still relevant in the process of developing an efficient AI-powered cybersecurity solution.
End-to-end deep learning as a solution for detecting malware
Some research on end-to-end deep learning propose a methodology that doesn’t rely on expert handcrafted input in the process of testing and training samples that are fed to AI models. One approach inspected malware binaries that were plotted as grayscale images, which revealed the textural and structural similarities and differences either between binaries from the same and different malware families, or between malware and benign software. This avoids the process of manual feature engineering, saving time and reducing workload for cybersecurity companies. Another approach involves a process where the engine was fed raw input made up of raw byte values and produced output which showed the classification of a malicious or benign file.
Due to confidentiality reasons, further details about the files used for training and testing the end-to-end deep learning models are undisclosed. Unfortunately, this makes it hard for one to gain a deeper insight into the performance results of the AI models they used. In particular, the said research have been unable to divulge the percentage of easily detected unknown malware samples as well as the percentage of ones that are difficult to detect. Such information is crucial as this could determine if such solutions are sufficient for proactively detecting complex, unknown threats that cybercriminals are continuously developing in present time.
Measuring the detection rates of an end-to-end deep learning model
In an attempt to validate one of the early end-to-end models, Trend Micro experts conducted an experiment in 2017. They used experimental datasets that comprised of carefully collected samples. The datasets used were for training and testing of two approaches: one with end-to-end deep learning and the other with a machine learning approach that includes expert handcrafted feature. The latter will be called “Expert AI” in the later sections. It should be noted that the datasets were organized in two ways according to the Trend Micro Locality Sensitive Hashing (TLSH) clustering results. This was done to compare and paint a clearer picture of the detection performance of the two approaches.
The datasets were organized into Type A dataset and Type B dataset. For Type A dataset, Trend Micro experts selected one sample from each TLSH cluster to form the training set, while the rest of the samples were selected from each cluster to form the testing set. This means every sample in the testing set had a similar sample in the training set. For Type B dataset, the experts experimented with select clusters as a whole in the training dataset and the testing dataset. This means that it was possible for the samples in the testing data to be significantly different from the samples in the training data. Theoretically speaking, Type A testing data might have been easier to detect if the model had already seen the Type A training data because it is very similar to the testing data.
The findings of the experiment showed that for Type A, end-to-end deep learning achieved 99.39% accuracy, while Expert AI achieved 99.87%.
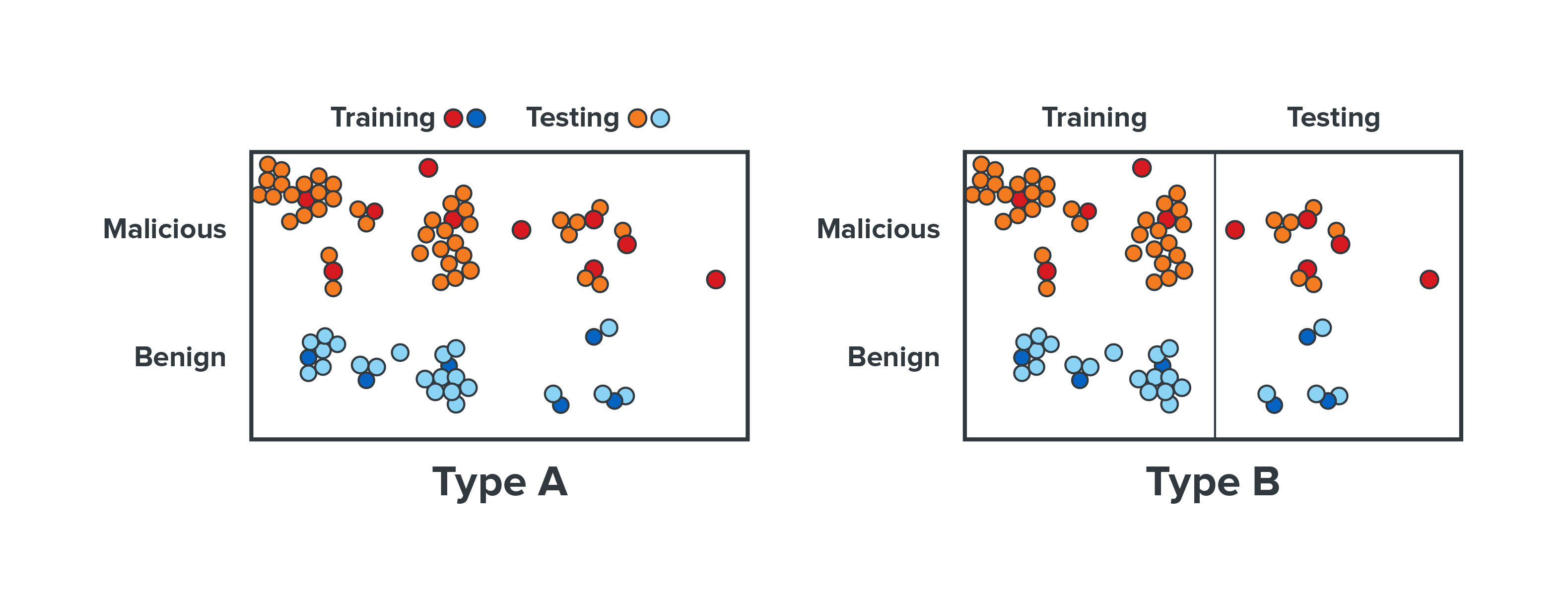
Figure 1. Experimental datasets, labelled Type A and Type B, were trained and tested using Expert AI and end-to-end deep learning approaches.
For Type B, end-to-end deep learning achieved 92.49% accuracy. On the other hand, Expert AI achieved 95.21%. While there is only an extremely small difference in the performance results between end-to-end deep learning and Expert AI for Type A, the results for Type B showed that Expert AI fared better – with a 2.72% advantage – than end-to-end deep learning in terms of detecting difficult, unknown samples. The experiment concluded that Expert AI, which made use of expert handcrafted input, performed better than the approximated end-to-end deep learning model in terms of detecting unknown samples.
| Model | Type A | Type B |
| Expert AI | 99.87% | 99.39% |
| End-to-end deep learning | 95.21% | 92.49% |
Table 1. The results of the experiment showed that Expert AI performs better than end-to-end deep learning in terms of detecting unknown samples.
End-to-end deep learning is innovative, but slightly behind an expert-supported AI solution
AI and expert security analytics in Trend Micro™ XDR
Like it? Add this infographic to your site:
1. Click on the box below. 2. Press Ctrl+A to select all. 3. Press Ctrl+C to copy. 4. Paste the code into your page (Ctrl+V).
Image will appear the same size as you see above.
Recent Posts
- Forecasting Future Outbreaks: A Behavioral and Predictive Approach to Proactive Cyber Risk Management
- Fault Lines in the AI Ecosystem: TrendAI™ State of AI Security Report
- The Industrialization of Botnets: Automation and Scale as a New Threat Infrastructure
- From Holiday Snap to Custom Scam in 30 Minutes: How AI Turns Public Photos Into Targeted Attacks
- From LinkedIn to Tailored Attack in 30 Minutes: How AI Accelerates Target Profiling for Cybercrime
 Fault Lines in the AI Ecosystem: TrendAI™ State of AI Security Report
Fault Lines in the AI Ecosystem: TrendAI™ State of AI Security Report AI Security Starts Here: The Essentials for Every Organization
AI Security Starts Here: The Essentials for Every Organization The AI-fication of Cyberthreats: Trend Micro Security Predictions for 2026
The AI-fication of Cyberthreats: Trend Micro Security Predictions for 2026 Stay Ahead of AI Threats: Secure LLM Applications With Trend Vision One
Stay Ahead of AI Threats: Secure LLM Applications With Trend Vision One