By Fernando Mercês
With contributions from Joey Costoya
Berkeley Packet Filtering (BPF) is a kind of technology that allows programs to effectively execute code in the kernels of modern operating systems, such as Linux and Berkeley Software Distribution (BSD) variants. Soon, Windows will also add support for BPF. While many defenders might be unaware of its existence, cybercriminals have already started using BPF as an attack vector. Aside from publicly available proof-of-concept code that uses BPF for all kinds of malicious intent, there are also active groups using BPF-enabled malware to target specific industries. Defenders therefore need to learn about this attack vector in detail to ensure that security measures and processes are updated and implemented to address this new challenge.
What BPF Is
BPF is a kernel-level engine that implements a virtual machine (VM) to interpret bytecode. Originally, it was designed to accomplish network packet filtering, but it was later extended to cover more general cases when it was rebranded as Extended BPF (eBPF). Currently, eBPF, or simply BPF, is used to describe the technology itself and the term "classic BPF" (cBPF) was coined to refer to classic BPF filters. Although the eBPF name and its logo have been receiving a lot of attention recently, the technology itself is still called BPF by kernel developers. We use “BPF” in this article to refer to both cBPF and eBPF code.
The kernel BPF engine includes an interpreter for the BPF instructions and a Just-In-Time (JIT) compiler to turn these instructions into platform-dependent machine instructions. This means a regular Linux executable will have a certain buffer containing an array of BPF bytecode at some point, and it will call a certain syscall to ask the kernel to load that particular BPF program, either an eBPF program or a cBPF filter. We will explain exactly how they do this in a later section.
Some developers say that eBPF does to Linux what JavaScript does to websites. In other words, with eBPF, one can add functionality to a running kernel. We will discuss its capabilities in the next section.
What BPF Can Do
In a blog entry published in July 2023, we explained how recent BPFDoor samples use cBPF filters to enable the backdoor on infected systems. While cBPF filters are limited to network traffic filtering, eBPF opened the door to performance measuring, syscall hooks, observability, and security. Consequently, defining precisely what the possibilities are with BPF has become difficult because it now functions as a general-purpose way of getting code running in kernel-level; the functionalities therefore depend on the loaded program. From a security perspective, malware authors can then write pieces of code to support rootkits or any other kind of malware. For example, it can be used to hide a process ID (PID) on an affected system, intercept syscalls, deal with network traffic, hide a kernel module, and much more.
Here’s a concrete example: A rootkit loads an eBPF program that will activate a backdoor if the system receives a certain TCP (Transmission Control Protocol) packet. The code that handles such a packet would remain in kernel-level. This means that neither a system administrator nor a security product would know about the eBPF program, unless they inspect the right area in the system so they can determine any suspicious event or behavior.
How BPF Is Used
Developers use the libbpf C library extensively to make the development of eBPF programs easier. The libbpf C library is used by programs loading eBPF code regardless of the programming language used. We’ve seen instances where Go, Python, and Rust wrappers were used. This library calls SYS_bpf syscall to load eBPF programs.
There are different types of eBPF programs. From a malware analyst’s perspective, we highlight the following:
- BPF_PROG_TYPE_SOCKET_FILTER: For network packet filter programs
- BPF_PROG_TYPE_TRACEPOINT, BPF_PROG_TYPE_RAW_TRACEPOINT, and BPF_PROG_TYPE_RAW_TRACEPOINT_WRITABLE: For programs attached to existing kernel tracepoints
- BPF_PROG_TYPE_KPROBE: For kprobe programs that are useful when no tracepoints exist to meet the user’s requirements
- BPF_PROG_TYPE_XDP: Offers inbound traffic deep packet inspection (DPI) capabilities and packet handling
- BPF_PROG_TYPE_SCHED_CLS: Functions the same way as the previous program type, but works on both inbound and outbound traffic
- BPF_PROG_TYPE_SYSCALL: For programs that can call system functions
For example, if a piece of malware wants to hook a kernel syscall, it can do so by loading an eBPF program of type BPF_PROG_TYPE_TRACEPOINT if the kernel already offers a tracepoint to the desired syscall (see /sys/kernel/debug/tracing/events/syscalls). If the desired syscall does not have a tracepoint, the program can load a BPF_PROG_TYPE_KPROBE instead.
After loading an eBPF program, it’s necessary to tie it to a kernel event. This is done through a call to SYS_perf_event_open. To enable the event, SYS_ioctl is used.
cBPF filters can also be loaded with SYS_setsockopt, which will be tackled later in more detail. First, let’s analyze how some rootkits work with eBPF.
eBPF proof-of-concept rootkits
In this section, we discuss four eBPF proof-of-concept rootkits that we found during our research to see how they work and what they do.
1. Boopkit
Created as a proof of concept by Kris Nova, Boopkit is split into different components:
User-space programs (normal ELF executable files):
- Boopkit-boop is a TCP client that runs on the attacker’s machine.
- The Boopkit server program runs on a victim’s machine.
eBPF probes are small pieces of eBPF bytecode dynamically loaded in the kernel. The Boopkit server binary loads probes for four tracepoints:
- tp/tcp/tcp_bad_csum is used to trigger Boopkit when a TCP packet with bad checksum arrives in the target system. The command to be executed is sent with the packet and loaded to a mapping area.
- tp/tcp/tcp_receive_reset is used as a second way of triggering boopkit, via a SYN packet with RST flag.
- tp/syscalls/sys_enter_getdents64 and tp/syscalls/sys_exit_getdents64 are used to hook getdents64() syscall to prevent Boopkit directory to be listed.
To load and configure the eBPF probes, Boopkit uses the following functions from libbpf:
- bpf_map_update_elem()
- bpf_object__attach_skeleton()
- bpf_program__attach()
- bpf_program__fd()
- ring_buffer__poll()
- bpf_map__name()
- bpf_map_delete_elem()
- bpf_object__destroy_skeleton()
- ring_buffer__new()
- bpf_map_get_next_key()
- bpf_object__open()
- bpf_object__next_map()
- bpf_map_lookup_elem()
- bpf_object__open_skeleton()
- bpf_object__load()
- bpf_map__fd()
- bpf_program__section_name()
- bpf_object__load_skeleton()
- bpf_program__name()
- bpf_object__next_program()
Note that these are the function calls caused by the binary when it’s running. However, not all of them are called explicitly from the binary’s source code. A few of them are the result of C macros exposed by libbpf to the programmer. The library will end up calling SYS_bpf() syscalls (0x141 in amd64 architecture).
At a lower level, here’s an example of how Boopkit loads the eBPF code and ties it to a tcp_bad_csum kernel event:
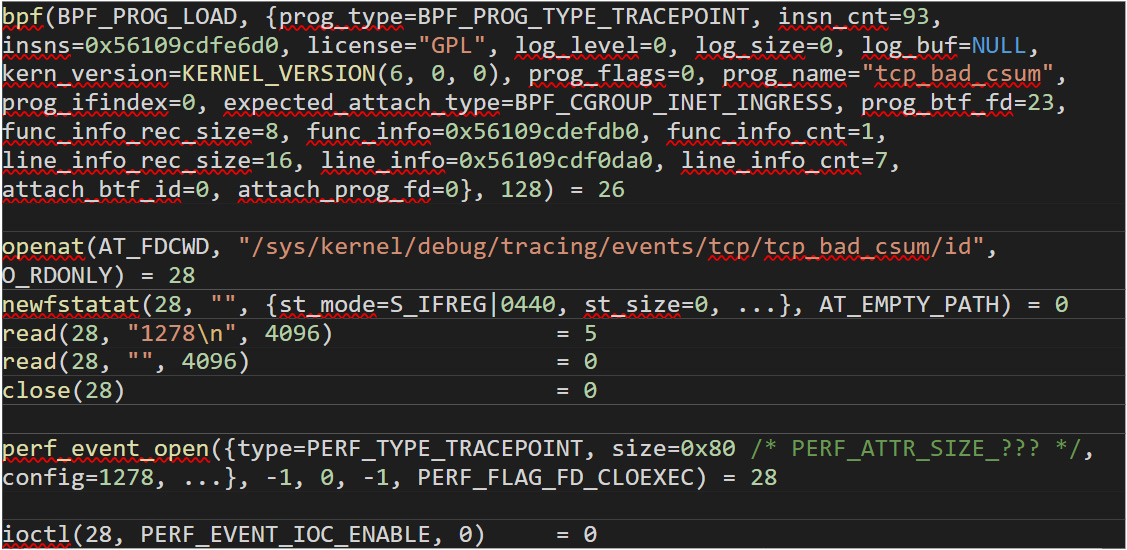
Figure 1. How Boopkit loads eBPF code and ties it to a "tcp_bad_csum" kernel event; after loading the eBPF code of “BPF_PROG_TYPE_TRACEPOINT”, the libbpf uses “SYS_openat” and “SYS_read” to get the ID of the desired kernel event. This ID is then used with “SYS_perf_event_open” to tie the program to the event. Finally, “SYS_ioctl” is used to enable it.
After loading all eBPF programs, the Boopkit server goes into a loop to:
- Ensure the eBPF programs are loaded.
- Check the eBPF map area for any commands.
- Execute commands received via TCP packets.
The Boopkit client sends the “magic” packet to the server at any open TCP port containing the command to be executed. This allows an attacker to gain full remote control of the infected machine.
It doesn’t matter what program is running on a server because once the infected machine receives the “magic” packet, the rootkit is activated. The command sent is also executed while the packet is ignored by the kernel. This packet handling happens even before the packet is sent to the firewall layer.
2. Bad BPF
While not an actual rootkit, Bad BPF is a set of tools that can perform functions normally present in rootkits. It contains the following tools:
- bpfdos sends a SIGKILL to any process using SYS_ptrace.
- exechijack hooks SYS_execve executes a program at /a instead.
- pidhide hides a specified PID by hooking SYS_getdents.
- sudoadd hooks SYS_openat, SYS_read, and SYS_close to give privileged permissions to a non-privileged user using sudo.
- textreplace replaces text in virtual file systems. It can be used to hide things under /proc, /sys, among others.
- textreplace2 is similar to textreplace but it uses maps to store its runtime configuration.
- writeblocker hooks SYS_write.
All these ELF programs load eBPF programs of BPF_PROG_TYPE_TRACEPOINT type by calling SYS_bpf with BPF_PROG_LOAD command. The same mechanism with SYS_ perf_event_open and SYS_ioctl is then used.
3. Ebpfkit
Ebpfkit is an advanced rootkit that loads many BPF_PROG_TYPE_KPROBE and BPF_PROG_TYPE_XDP programs to achieve its goals. It also loads BPF_PROG_TYPE_SCHED_CLS programs. Notably, it does not make extensive use of BPF_PROG_TYPE_TRACEPOINT programs. Figure 2 shows some sample calls to SYS_bpf done by ebpfkit:
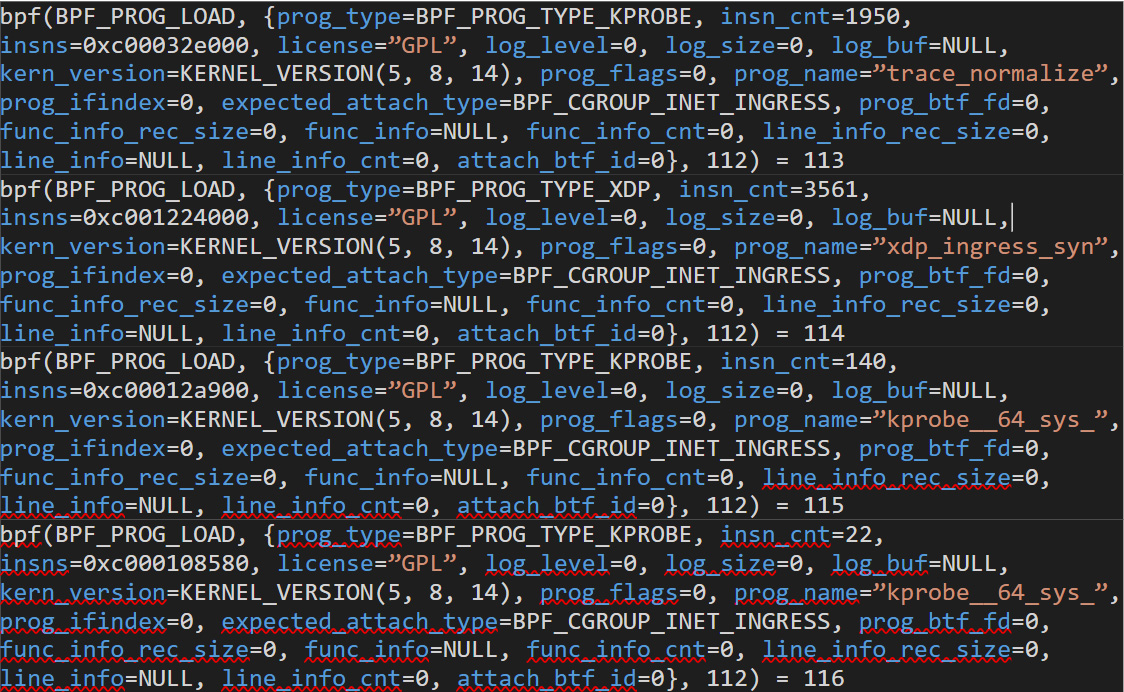
Figure 2. Sample calls to “SYS_bpf” done by ebpfkit
By using XDP, ebpfkit intercepts packets sent to an open port (8000/tcp by default) to interact with its client. To ensure that the port is open, ebpfkit is shipped using a small web server.
The extensive use of kprobes is noisy. Such noise can be observed by comparing the output from a normal system (Figure 3) versus a system infected with ebpfkit (Figure 4):

Figure 3. Output from a normal system
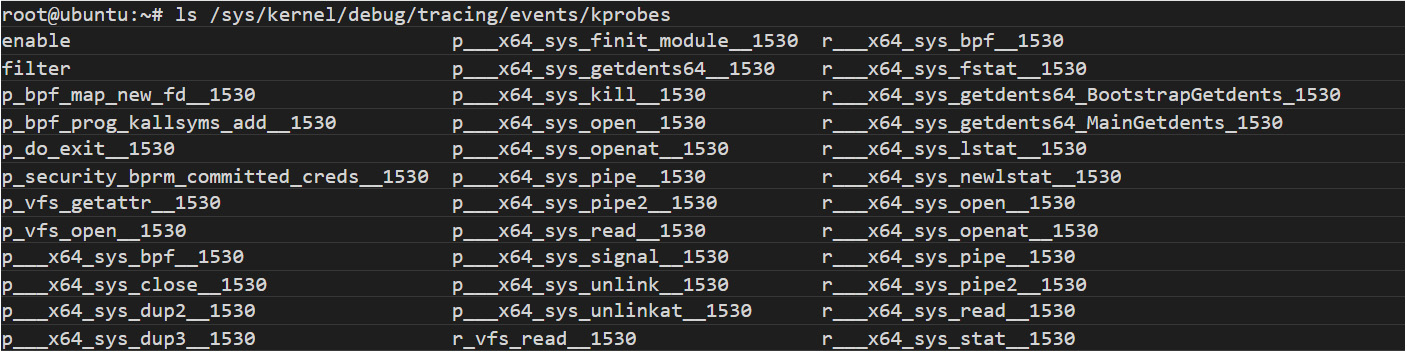
Figure 4. Output from a system infected with ebfkit
The previous listing shows that a p___x64_sys_bpf__1530 kprobe was created. This hooks SYS_bpf, making ebpfkit invisible when the user lists the eBPF programs running.
4. TripleCross
The TripleCross rootkit primarily tries to load BPF_PROG_TYPE_TRACEPOINT and BPF_PROG_TYPE_XDP programs differently from the other proof-of-concept rootkits we have analyzed. TripleCross pins an object by calling SYS_bpf with BPF_OBJ_PIN command (0x06). The listing in Figure 5 contains some calls from the TripleCross rootkit when it starts running:
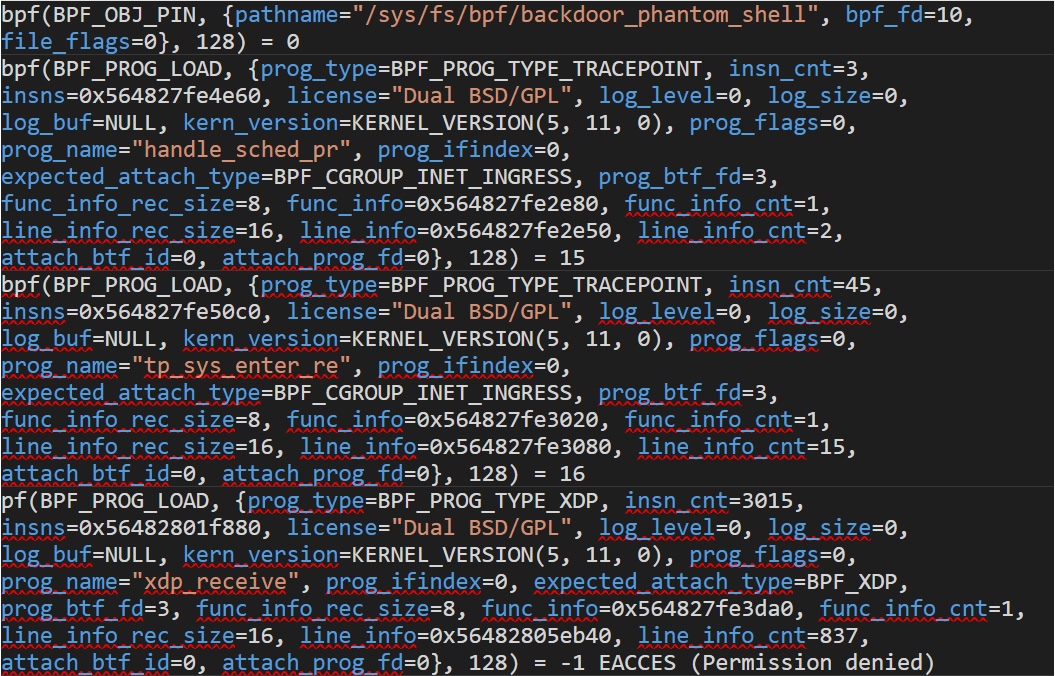
Figure 5. A list showing some calls from the TripleCross rootkit when it starts running
TripleCross uses XDP for network communication like ebpfkit.
Detecting eBPF implants
An eBPF program has many attributes defined in bpf_prog_info struct. The most basic attribute is the 32-bit program ID. Other attributes include information about types, number of instructions, time since boot began (in nanoseconds), and owner’s user ID (UID), among others. These attributes can be used to detect whether a running eBPF program is suspicious or not. For example, depending on the environment, an eBPF program loaded longer than a minute might be suspicious. The load time can also be used to receive an alert every time an eBPF program is loaded.
Fortunately for us, Linux developers created a command-line program called “bpftool” that reads this and other related structures and prints out information about most of these attributes from running eBPF programs. In a normal Linux system with no additional eBPF programs running, the output for the bpf tool command should be like the output in Figure 6:
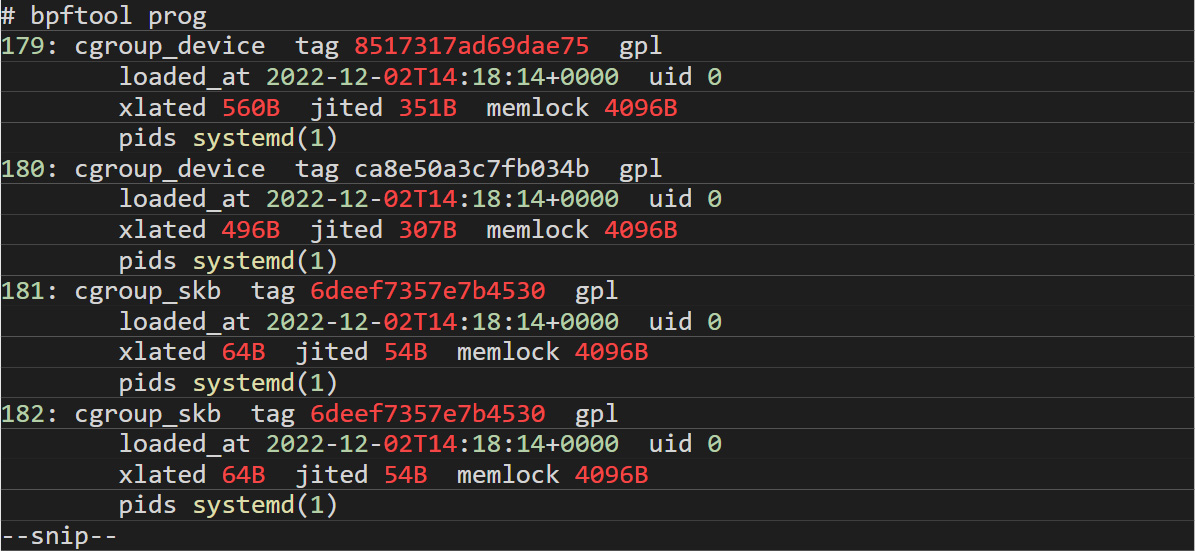
Figure 6. The desired output from a “bpftool” program command
Seen from a bpftool framework, an eBPF program has the following fields:
- id: a 32-bit unsigned integer used to identify the eBPF program
- type: a 32-bit unsigned integer describing the program type. See the enumeration of bpf_prog_type at bpf.h for details
- name: A 16-characters string containing the program name
- tag: A 16-digit hexadecimal string tag
- gpl_compatible: Boolean field to tell whether the program is GPL-compatible
- loaded_at: Refers to the number of seconds in bpf_prog_info struct; this field holds the number of nanoseconds since boot time
- UID: Creator’s user ID
- bytes_xlated: The total size of eBPF instructions
- jited: True if the code was compiled to machine code
- bytes_jited: Total size of machine Assembly instructions
- bytes_memlock: Size of locked-in-memory address space
- pids: Process ID (PID) that loaded the program
The loaded_at field is important. Most BPF programs loaded by the system during its startup should match the boot time. To check if there is indeed a match, use the who command with the -b switch (Figure 7). Note that this is not necessarily an exact match as processes might load BPF programs a few seconds later, too.

Figure 7. The “who” command with the -b switch can be used to determine if the BPF program loaded by the system during startup matches the boot time.
The aforementioned examples show that the system boot time is close enough to when the BPF programs are loaded. It is also important to pay attention to the loading PID field. Any instance of a PID that is different from what can be found on PID 1 (systemd) should be investigated.
Figure 8 shows an example of the output when Boopkit is loaded:
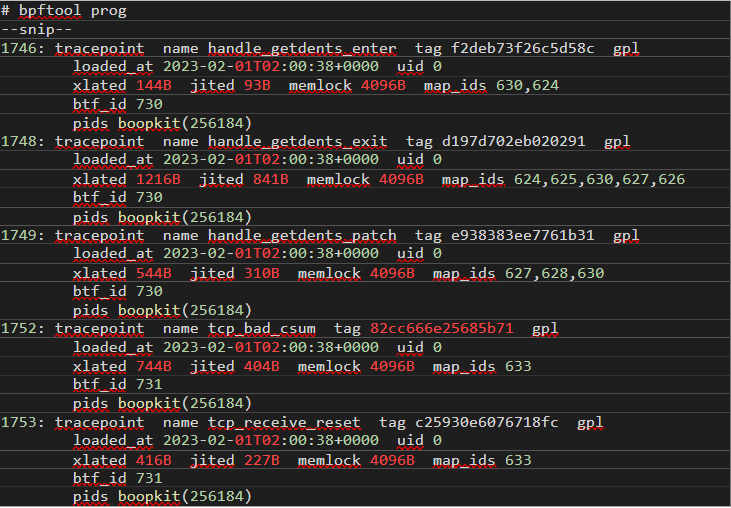
Figure 8. Sample output when Boopkit is loaded
Boopkit hides its PID from commands such as ps that list the running processes. However, the PID of the Boopkit server is revealed by bpftool.
In Boopkit’s case, the BPF program name also gives us a hint of what’s going on, but a detection method cannot purely rely on such names.
It’s easy to list the BPF programs loaded by processes with PID greater than 1 because bpftool supports a JSON-based output:

Figure 9. Sample list of a BPF program
When eBPF programs use maps — a shared storage area containing hash maps — the map IDs are also shown in bpftool prog output. Inspecting them might reveal the configuration of the malware. For example, in the previous output, the handle_getdents_patch program uses three maps with IDs 627, 628, and 630. The third map contains its configuration because of the way Boopkit works. We can also see its content with bpftool (Figure 10):
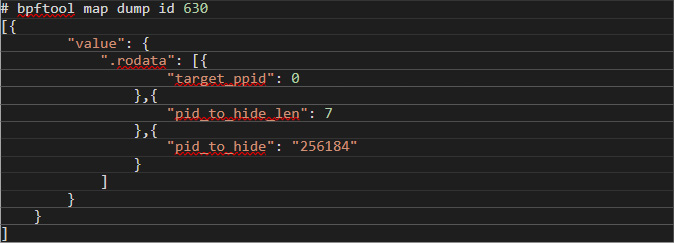
Figure 10. A list of the contents of the third map created by Boopkit using "bpftool"
From a programmer’s perspective, inspecting running eBPF programs is mainly done by calling SYS_bpf syscall either directly or using a code abstraction layer such as libbpf. Figure 11 shows a sample code when the latter option is used:
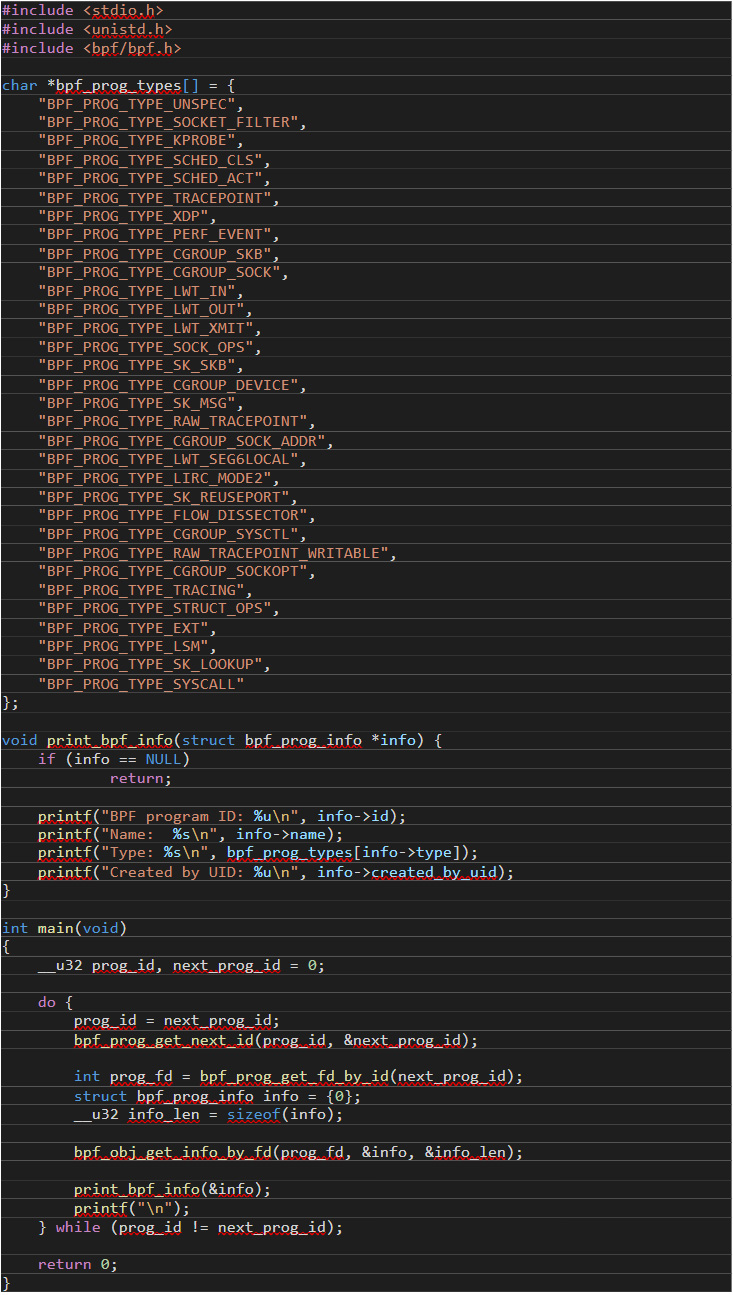
Figure 11. A sample code when a code abstraction layer such as libbpf is used
The sample code does not handle errors for the sake of brevity. It uses the bpf_prog_get_next_id() function to enumerate existing IDs of active eBPF programs and the bpf_obj_get_info_by_fd() function to get information about the IDs that have been found.
Detection programs using this method should be statically linked to reduce the risk of being negatively affected by userland library hooks. Keep in mind that this detection method can still be bypassed by regular ring 0 or other eBPF rootkits if SYS_bpf syscall is hooked as ebpfkit is known to do. As a rule, a system infected with such a rootkit can no longer be trusted.
cBPF malware
Classic BPF (cBPF), sometimes called BPF, is less powerful than eBPF as it only deals with the network. However, there were at least two malware families that we observed using this technique to hide its traces: BPFDoor and Symbiote.
Unlike the loading process of generic eBPF programs, cBPF filters can be loaded with a call to SYS_setsockopt to set options for an open network socket. Figure 12 shows the prototype for this function:

Figure 12. The prototype for a cBPF filter loaded through a call to “SYS_setsockop” to set options for an open network socket
In order to load a cBPF filter, an ELF program must call setsockopt() with SO_ATTACH_FILTER (0x1a) in its third parameter. The optval parameter is a pointer to a struct with the following definition:

Figure 13.The prototype of the function or the syscall
Figure 14 shows the definition of the sock_filter struct:

Figure 14. Definition of the “sock_filter” struct
The len field in sock_fprog struct sets the number of elements of a struct sock_filter array. In other words, it’s the number of cBPF instructions. The total array size is len * 8.
We will now look at how pieces of malware use this technique to load malicious cBPF filters.
BPFDoor
BPFDoor loads a cBPF filter using a SYS_setsockopt call from a child process created by a call to SYS_clone. This is done right after a call to SYS_socket:

Figure 15. Output from trace tool showing how BPFDoor uses "SYS_socket" and "SYS_setsockopt" to attach a cBPF filter
The backdoor then uses SYS_recv to listen for commands.
Other BPFDoor samples might load different cBPF filters. We have also seen a few samples load two cBPF filters. These filters are used to prevent the malicious traffic from appearing in network traffic capture.
Symbiote
Symbiote uses a single cBPF filter to prevent its traffic from being detected. It leverages the fact that tcpdump will compile and load cBPF bytecode to hook a setsockopt() call using the LD_PRELOAD technique to prepend a cBPF filter to any filters loaded by this function. Figure 16 shows the hooked version of the function, setsockopt():
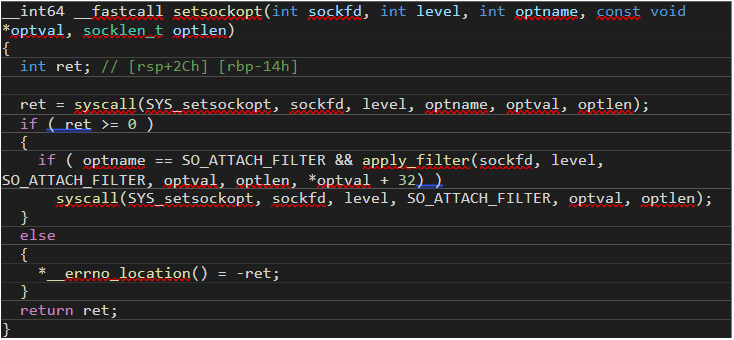
Figure 16. The hooked version of the function, “setsockopt()”
The apply_filter() function prepends the malicious cBPF filter when the user loads a legitimate filter, as Figure 17 shows:
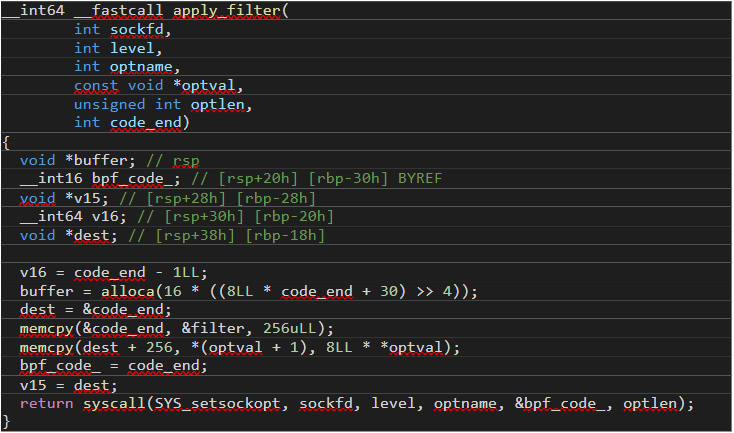
Figure 17. The malicious cBPF filter is prepended by the “apply_filter()” function when the user loads a legitimate filter.
Hacking tools
We found an SSH brute forcer (f2a96cdd228e1279f612d61b756863fea5adde977ad92b8e2a26352fa88feb18 and e4f87188ba73acc5706f5af8a2e295a4b8c31883743f249cb57a4d89ae5735d0) that used cBPF filters as a result of being statically linked to libpcap. However, we decided not to include it in our investigation since it is not relevant to our research objectives. The tool is detected as HACKINGTOOLS_SHARK by Trend Micro.
Detecting cBPF filters
The ss tool is capable of dumping information about any classic BPF filters tied to a socket:

Figure 18. Output from ss tool showing a cBPF filter loaded by tcpdump process
The output shown in Figure 18 indicates that there’s a tcpdump process with PID 319731 that opened a raw packet socket and attached a cBPF filter containing 24 instructions.
Conclusion
BPF-enabled malware is here to stay. We foresee more pieces of malware using BPF soon, especially eBPF, which offers many advantages over its predecessor.
While eBPF is a great idea and a very powerful tool, we should nonetheless pay close attention to suspicious programs using this piece of technology, as they can make advanced pieces of malware and rootkits much harder to detect. While recent discourse on eBPF security focuses on defending the engine against the exploitation of vulnerabilities, we should think of ways to detect malicious eBPF programs not only in exploits but also in live kernels. Think about the difference between a malicious and a legitimate hook of SYS_open, for example. While both of these could use the exposed tracepoint, the mere fact that SYS_open is hooked does not indicate malicious activity in this case. Therefore, we need to dive deeper and inspect both the eBPF program and the loading process.
The suggestions for detection discussed here need to be tested to weed out false positives. One of our concerns is the high probability of container tools and network monitoring tools using eBPF extensively. The more eBPF programs running in a system, the more the search for them is akin to finding a needle in a haystack. In the future, malicious eBPF programs could try to disguise themselves as popular eBPF programs or embed part of non-malicious programs to their code. Indeed, eBPF opens a wide range of new possibilities for attackers.
Ultimately, it is paramount that we hone our skills to gain a more thorough understanding of cBPF and eBPF bytecode, including disassembly, so that we can find ways to address BPF-enabled malware threats when they arise.
Like it? Add this infographic to your site:
1. Click on the box below. 2. Press Ctrl+A to select all. 3. Press Ctrl+C to copy. 4. Paste the code into your page (Ctrl+V).
Image will appear the same size as you see above.
Recent Posts
- Hunt Them All: An AI-Powered Vulnerability Sweep of 19,000 MCP Servers
- Pwning Agentic AI Part I: Your AI Agent Is Already Compromised
- TrendAI™ and CleanDNS: From Blocking Attacker Infrastructure to Removing It From the Internet
- A Hidden Vulnerability in Healthcare: Exposed DICOM Servers and the Risk to Patient Data
- Update on Exposed MCP Servers: The Threat Widens to the Cloud
 Fault Lines in the AI Ecosystem: TrendAI™ State of AI Security Report
Fault Lines in the AI Ecosystem: TrendAI™ State of AI Security Report It’s By Design: The Use-After-Free of Azure Cloud
It’s By Design: The Use-After-Free of Azure Cloud Ransomware Spotlight: Agenda
Ransomware Spotlight: Agenda Guarding LLMs With a Layered Prompt Injection Representation
Guarding LLMs With a Layered Prompt Injection Representation