
Une forme d’intelligence artificielle (IA) qui permet aux systèmes d’apprendre des modèles à partir des données et d’améliorer leurs performances sur les tâches au fil du temps sans être explicitement programmés.
Table des matières
L’apprentissage automatique: Définition
Disposer d’ordinateurs qui déterminent quoi faire sans le leur indiquer de manière explicite stimule l’imagination depuis longtemps.
L’idée d’une voiture dans laquelle vous pouvez conduire qui fera toute la conduite, identifiera les piétons et les nids-de-poule et réagira rapidement et efficacement aux changements dans l’environnement pour vous livrer en toute sécurité à votre destination, c’est-à-dire l’apprentissage automatique (ML) dans la pratique.
Comment cela fonctionne-t-il ? Commençons par analyser uniquement les données commerciales.
L’apprentissage automatique est un type d’IA qui permet aux entreprises de comprendre et d’apprendre à partir d’énormes quantités de données. Prenons l’exemple de Twitter. Selon Internet Live Stats, les utilisateurs de Twitter envoient environ 500 millions de tweets par jour, ce qui correspond à environ 200 milliards de tweets par an. Il n’est humainement pas possible d’analyser, de classer, de trier, d’apprendre et de prévoir quoi que soit avec ce nombre de tweets.
Comment l’apprentissage automatique peut aider les entreprises
Le Machine Learning aide à protéger les entreprises contre les cybermenaces. Cependant, il fonctionne mieux dans le cadre d'une solution de sécurité multicouche.
L’apprentissage automatique nécessite un travail considérable avant que les entreprises puissent obtenir des informations précieuses. Pour tirer le meilleur parti de l’apprentissage automatique, vous devez disposer de données nettoyées et savoir quelles questions poser. Vous pouvez alors sélectionner le meilleur modèle et le meilleur algorithme au profit de votre entreprise. L’apprentissage automatique n’est pas un processus simple ou facile. Son succès requiert un travail assidu.
L’apprentissage automatique répond à un cycle de vie :
- Compréhension commerciale. Définir le problème, les critères de réussite et si le ML est la bonne approche.
- Acquisition et nettoyage des données. Vous disposez de la quantité de données nécessaire, et elles ont été efficacement nettoyées, de sorte qu’elles sont prêtes à fournir les informations dont vous avez besoin.
- Sélection des caractéristiques. Le processus de sélection des variables d’entrée (fonctionnalités) à utiliser dans la création du modèle. Les méthodes comprennent les tests statistiques, la régularisation ou les mesures d’importance basées sur des algorithmes. Par exemple, les arbres de décision classent les fonctionnalités selon des critères tels que le gain d'informations ou l'impureté de Gini.
- Sélection du modèle. Choisissez un algorithme et un type de modèle appropriés, puis entraînez-le avec vos données.
- Formation et mise au point. Adaptez le modèle aux données et ajustez les hyperparamètres pour améliorer les performances.
- Évaluation du modèle et de l’algorithme pour déterminer s’il est prêt à être utilisé ou si vous devez effectuer à nouveau quelque étapes et affiner votre modèle, vos caractéristiques, votre algorithme ou vos données pour atteindre vos objectifs.
- Déploiement du modèle formé en production.
- Examen des résultats du modèle existant en production

À quoi sert l'apprentissage automatique ?
L’apprentissage automatique permet aux entreprises de comprendre et d’apprendre à partir de leurs données. Une entreprise peut l’utiliser pour un grand nombre de sous-domaines. Le cas d'utilisation dépend si une entreprise essaie d’améliorer ses ventes, de proposer une fonction de recherche, d’intégrer des commandes vocales dans son produit ou de créer une voiture autonome.
Sous-domaines de l'apprentissage automatique
L’apprentissage automatique propose un vaste choix d'utilisations dans les entreprises actuelles et il ne peut que se développer et s’améliorer avec le temps. Les sous-domaines de l'apprentissage automatique comprennent les réseaux sociaux et les recommandations de produits, la reconnaissance d’image, les diagnostics de santé, la traduction, la reconnaissance vocale et l’exploration de données, entre autres.
Les plateformes de réseaux sociaux, telles que Facebook, Instagram ou LinkedIn utilisent l’apprentissage automatique pour suggérer des pages à suivre ou des groupes à rejoindre en fonction des publications que vous aimez. Il récupère l’historique des données relatives à ce que les autres utilisateurs ont aimé ou aux publications similaires à celles que vous avez aimées, vous fait ces suggestions ou les ajoute à votre flux.
Il est également possible d’utiliser l’apprentissage automatique sur un site d’e-commerce pour faire des recommandations de produits basées sur vos achats précédents, vos recherches et les actions d’autres utilisateurs similaires aux vôtres.
La reconnaissance d'image constitue aujourd’hui une utilisation importante de l’apprentissage automatique. Les plateformes de réseaux sociaux ont recommandé d’étiqueter des personnes dans vos photos sur la base de l’apprentissage automatique. La police a pu l'utiliser pour rechercher des suspects dans des photos ou des vidéos. Avec le grand nombre de caméras installées dans les aéroports, les magasins et les sonnettes, il est possible de déterminer qui a commis un crime ou l’endroit où s’est rendu le criminel.
Les diagnostics de santé constituent également une bonne utilisation de l’apprentissage automatique. Après un événement tel qu’une crise cardiaque, il est possible de revenir en arrière pour voir les signes d’avertissement qui ont été négligés. Un système utilisé par les médecins ou les hôpitaux pourrait être alimenté avec les dossiers médicaux du passé et apprendre à déterminer les liens entre l’entrée (comportement, résultats de tests ou symptôme) et la sortie (p. ex., une crise cardiaque.) Puis, lorsque le médecin introduira ses notes et les résultats de tests dans le système par la suite, la machine pourra identifier les symptômes de la crise cardiaque de manière bien plus fiable que les êtres humains afin que le patient et le médecin puissent apporter des modifications pour l’empêcher.
La traduction de pages Web ou d’applications pour les plateformes mobiles est un autre exemple d’apprentissage automatique. Certains applications offrent de meilleurs résultats que d'autres, ce qui est dû au modèle, à la technique et aux algorithmes d’apprentissage automatique qu’elles utilisent.
Une utilisation quotidienne de l apprentissage automatique se fait aujourd’hui dans les opérations bancaires et les cartes de crédit. L’apprentissage automatique peut rapidement détecter des signes de fraude que les êtres humains mettraient longtemps, ou ne pourraient même pas, découvrir. La pléthore de transactions qui ont été examinées et étiquetées (fraude ou non) permettent à l’apprentissage automatique d’apprendre à repérer ultérieurement une fraude dans une seule transaction. L’apprentissage automatique idéal pour cela est l’exploration de données.
Exploration de données
L’exploration de données est un type d’apprentissage automatique qui analyse les données pour faire des prévisions ou découvrir des modèles au sein du Big data. Ce terme est quelque peu trompeur car aucune intervention humaine n’est requise, que ce soit de la part d’un mauvais acteur ou d’un employé, fouillant dans vos données pour trouver une donnée qui pourrait être utile. À la place, le processus implique la découverte de modèles dans les données, utiles pour prendre des décisions ultérieures.
Prenons l’exemple d'une société de cartes de crédit. Si vous avez une carte de crédit, votre banque vous a probablement informé d’une activité suspecte sur votre carte à un moment ou à un autre. Comment la banque peut-elle identifier une telle activité si rapidement, en envoyant une alerte quasi-instantanée ? L’exploration de données en continu permet cette protection contre les fraudes. Au début de l’année 2020, plus de 1,1 milliard de cartes sont en circulation rien qu’aux États-Unis. La masse de transactions effectuées avec ces cartes génère différentes données pour l’exploration, les recherches de modèles et l’apprentissage afin d’identifier les transactions suspectes ultérieures.
Apprentissage profond
L’apprentissage profond est un type spécifique d’apprentissage automatique basé sur les réseaux neuronaux. Un réseau neuronal émule le fonctionnement des neurones dans un cerveau humain pour prendre une décision ou comprendre quelque chose. Par exemple, un enfant de six ans peut regarder un visage et distinguer sa mère d’un agent de la circulation car le cerveau analyse rapidement de nombreux détails – couleur des cheveux, traits du visage, cicatrices, etc. – le tout en un clin d'œil. L’apprentissage automatique le reproduit sous la forme de l’apprentissage profond.
Un réseau neuronal comporte 3 à 5 couches : une couche d’entrée, une à trois couches cachées et une couche de sortie. Les couches cachées prennent les décisions pour alimenter la couche de sortie ou la conclusion l’une après l’autre. Quelle couleur de cheveux ? Quelle couleur d’yeux ? Une cicatrice est-elle présente ? Lorsque le nombre de couches augmente pour atteindre des centaines, cela s’appelle l’apprentissage profond.
Types d’apprentissage automatique
Il existe fondamentalement quatre types d’algorithmes d’apprentissage automatique : supervisés, semi-supervisés, non supervisés et renforcés. Les experts en apprentissage automatique estiment qu’environ 70 % des algorithmes d’apprentissage automatique utilisés actuellement sont supervisés. Ils fonctionnent avec des ensembles de données connus ou étiquetés – par exemple, des images de chiens et de chats. Les deux types d’animaux sont connus, ainsi les administrateurs peuvent étiqueter les images avant de les transmettre à l’algorithme.
Les algorithmes d’apprentissage automatique non supervisés apprennent à partir d’ensemble de données inconnus. Prenons l’exemple des vidéos TikTok. Il existe tellement de vidéos avec tellement de sujets qu'il est impossible de former un algorithme à partir d’elles de manière supervisée ; les données ne sont pas encore étiquetées.
Les algorithmes d’apprentissage automatique semi-supervisés sont initialement formés avec un ensemble réduit de données connues et étiquetées. Ils sont ensuite appliqués à un ensemble plus vaste de données non étiquetées pour continuer leur formation.
Les algorithmes d’apprentissage automatique renforcés ne sont pas formés initialement. Ils apprennent à la volée, à partir des essais et des erreurs. Imaginez un robot qui apprend à se déplacer dans un tas de pierres. Chaque fois qu'il échoue, il apprend ce qui ne fonctionne pas et modifie son comportement jusqu'à ce qu'il réussisse. Pensez au dressage de chiens et à l’utilisation de friandises pour apprendre différents ordres. Avec un renforcement positif, le chien continue à obéir aux ordres et change tout comportement qui n’entraîne pas une réponse favorable.
Apprentissage automatique supervisé ou non supervisé
Apprentissage automatique supervisé
Il utilise des ensembles de données connus, établis et classés pour trouver des modèles. Développons l’idée précédente des images de chiens et de chats. Vous pourriez avoir un énorme ensemble de données avec des milliers d’animaux différents représentés sur des millions d’images. Vu que les types d’animaux sont connus, ils ont pu être groupés et étiquetés avant de les transmettre à l’algorithme d’apprentissage automatique supervisé pour qu'il apprenne à les comprendre.
L’algorithme supervisé compare à présent l’entrée à la sortie et l’image à l’étiquette du type d’animal. Il apprendra à terme à reconnaître un certain type d’animal dans les nouvelles photos qu’il rencontre.
Apprentissage automatique non supervisé
Les algorithmes d’apprentissage automatique non supervisés sont comme les filtres anti-spam actuellement. À l’origine, les administrateurs pouvaient programmer les filtres anti-spam pour rechercher des mots spécifiques dans les emails afin de comprendre le spam. Cela n’est plus possible, dont les algorithmes non supervisés fonctionnent bien dans ce cas. L’algorithme d’apprentissage automatique non supervisé est alimenté avec des emails qui n’ont pas été étiquetés pour commencer à rechercher des modèles. Lorsque ces modèles sont trouvés, il apprend à quoi ressemble le spam et l’identifie dans l’environnement de production.

Techniques d’apprentissage automatique
Les techniques d’apprentissage automatique résolvent des problèmes. En fonction du problème auquel vous êtes confronté, vous choisissez une technique d’apprentissage automatique spécifique. En voici six courantes.
La technique de régression
La régression peut être utilisée pour prévoir les prix sur le marché des maisons ou déterminer le prix de vente optimal d’une pelle à neige au Minnesota en décembre. La régression indique que même si les prix fluctuent, ils reviendront toujours au prix moyen, même si avec le temps les prix des maisons augmentent, il existe une moyenne qui réapparaîtra toujours. Vous pouvez tracer les prix au fil du temps sur un graphique et trouver la moyenne en fonction du temps. La ligne rouge continuant à évoluer dans le graphique, elle permet les prévisions futures.
Classification
La classification est utilisée pour grouper des données en catégories connues. Vous pourriez rechercher de bons clients prévisibles (ils reviennent toujours dépenser plus d’argent) ou vont probablement commencer à acheter ailleurs. Si vous pouvez regarder en arrière dans le temps et trouver des facteurs prédictifs pour chaque classification de clients, vous l’appliquerez aux clients actuels et prévoirez le groupe qu’ils appartiendront. Vous pourrez ensuite commercialiser plus efficacement et éventuellement convertir le client qui conduira potentiellement à un excellent client récurrent. Il s’agit d'un bon exemple d’apprentissage automatique supervisé.
Partitionnement de données
Contrairement à la technique de classification, le partitionnement de données est un apprentissage automatique non supervisé. Dans le partitionnement de données, le système détermine comment grouper les données que vous ne savez pas comment grouper. Ce type d’apprentissage automatique est excellent pour analyser les images médicales, analyser les réseaux sociaux ou rechercher des anomalies.
Google utilise le partitionnement de données pour la généralisation, la compression de données et la protection de la vie privée dans des produits tels que les vidéos YouTube, les applications Play et les pistes de Musique.
Détection des anomalies
La détection des anomalies est utilisée lorsque vous recherchez des valeurs aberrantes, ce qui équivaut à repérer le mouton noir dans un troupeau. En examinant une énorme quantité de données, ces anomalies sont impossibles à trouver pour des êtres humains. Mais, par exemple, si un analyste de données fournissait à un système des données de facturation médicale provenant de nombreux hôpitaux, la détection des anomalies trouverait une façon de grouper la facturation. Elle pourrait découvrir un ensemble de valeurs aberrantes, pouvant se révéler être une fraude.
Analyse des paniers de consommation
La logique de l’analyse des paniers de consommation permet des prévisions futures. Voici un exemple simple : si des clients mettent du bœuf haché, des tomates et des tacos dans leur panier, vous pouvez prévoir qu'ils vont ajouter du fromage et de la crème fraîche. Ces prévisions peuvent être utilisées pour générer des ventes supplémentaires en proposant aux clients en ligne des suggestions utiles d’articles qu’ils peuvent avoir oublié ou pour contribuer à grouper des produits dans un magasin.
Deux professeurs du MIT ont utilisé cette approche pour découvrir les « signes avant-coureurs de défaillance ». Il s’avère que certains clients ou produits peuvent connaître une défaillance. Si vous pouvez les identifier, vous pouvez choisir de continuer à vendre un produit et quel type de marketing appliquer pour augmenter les ventes auprès des bons clients.
Données de séries chronologiques
Les données de séries chronologiques sont couramment collectées sur la plupart d’entre nous qui portent un dispositif de condition physique sur leur poignet. Ces dispositifs peuvent collecter le nombre de pulsations cardiaques par minute, le nombre de pas que nous faisons par minute ou par heure et certains mesurent même désormais la saturation en oxygène au fil du temps. Avec ces données, il serait possible de prévoir quand quelqu’un va courir. Il serait également possible de collecter des données sur les machines et de prévoir les défaillances grâce aux données en fonction du temps relatives au niveau de vibrations, au niveau sonore en dB et à la pression.
Algorithmes d’apprentissage automatique
Si l’apprentissage automatique est censé apprendre à partir des données, comment concevoir un algorithme pour apprendre et trouver les données statistiquement significatives ? Les algorithmes d’apprentissage automatique prennent en charge le processus d’apprentissage automatique supervisé, non supervisé ou avec renforcement.
Les ingénieurs de données écrivent des portions de code qui sont les algorithmes qui permettent à une machine d’apprendre ou de trouver une signification dans les données.
Examinons quelques algorithmes spécifiques qui font partie des plus courants. Voici les 5 plus utilisés actuellement.
- Les algorithmes de régression linéaire établissent une relation en plaçant des données indépendantes et dépendantes sur un graphique et en traçant une ligne droite pour obtenir la moyenne ou la tendance. Merriam-Webster définit la régression comme "une fonction qui permet d’obtenir la valeur moyenne d’une variable aléatoire à condition qu’une ou plusieurs variables indépendantes aient des valeurs spécifiées." Cette définition s’applique également à la régression logistique.
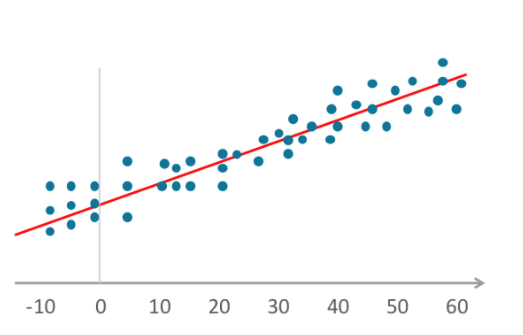
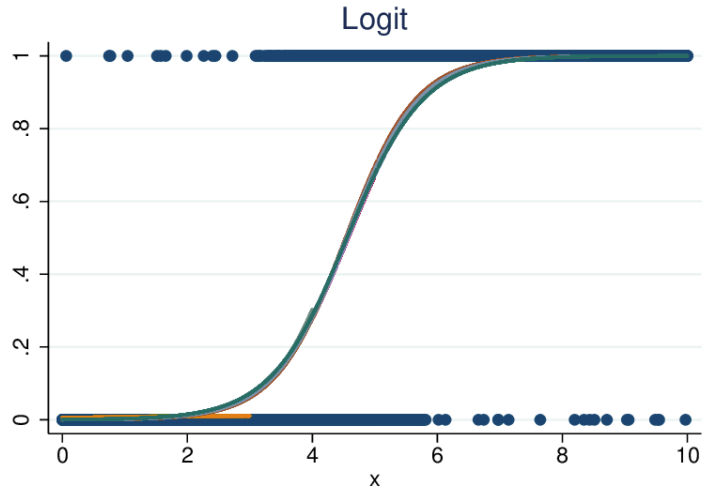
- La régression logistique (ou modèle logit) place également des variables sur un graphique, comme la régression linéaire, mais la ligne n’est pas linéaire. Ici, la ligne est une fonction sigmoïde.
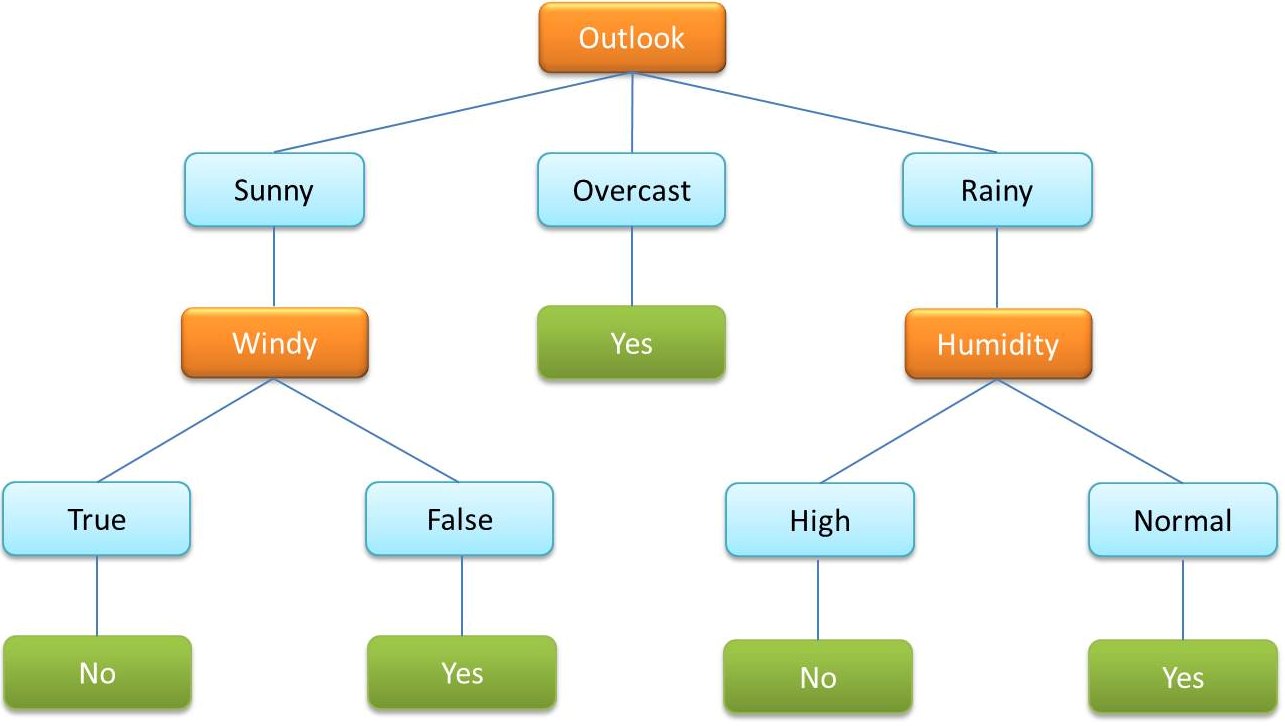
- Un arbre de décision est un algorithme très couramment utilisé au sein de l’apprentissage automatique supervisé. Elle est utilisée pour classer les données par variables catégorielles et continues.
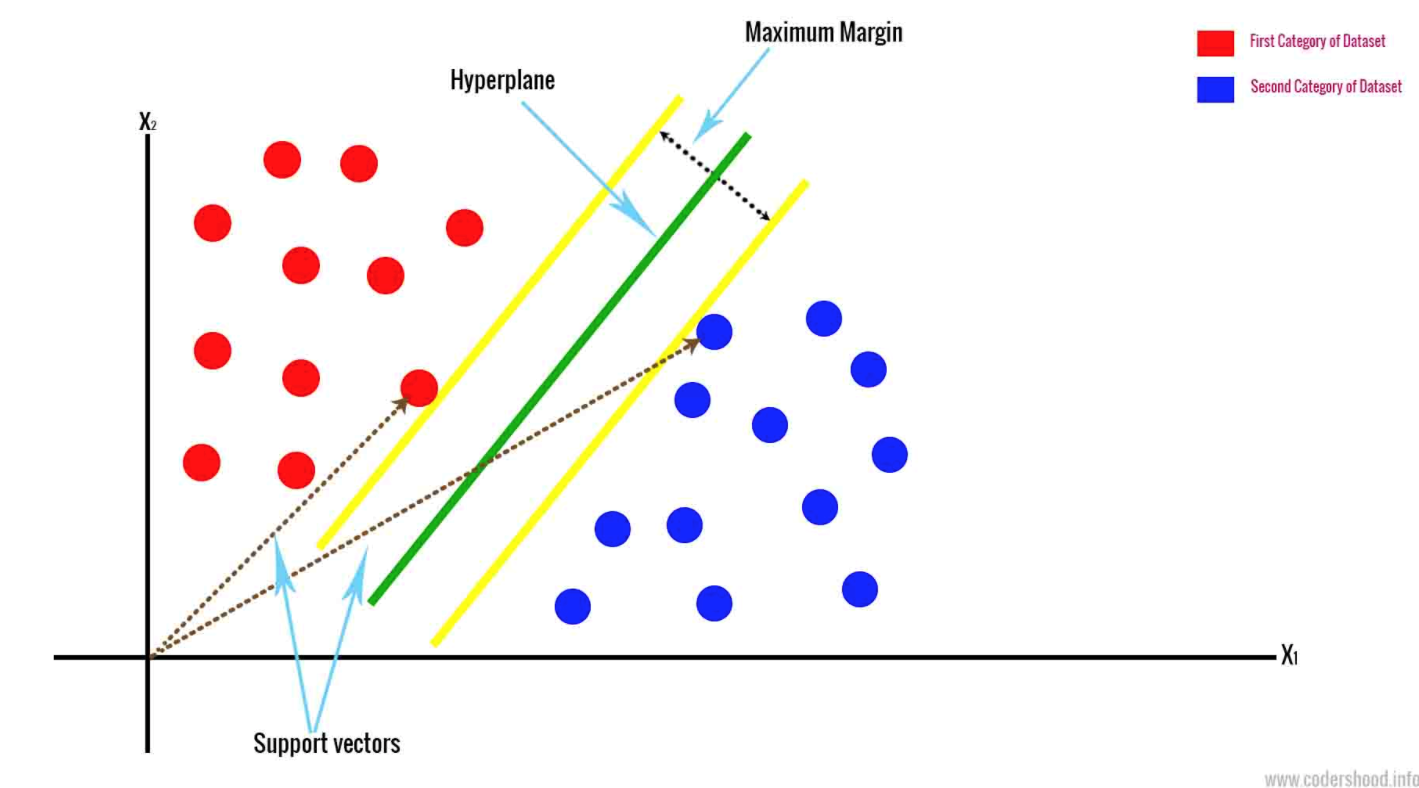
- Une machine à vecteurs de support définit un hyperplan basé sur les deux points de données les plus proches. Cela sépare les données en marginalisant les classes. Les données sont classées dans un espace à n dimensions. N représente le nombre de caractéristiques différentes dont vous disposez.
- Naive Bayes calcule la probabilité d’un résultat particulier. Elle est très efficace et surpasse des modèles de classification plus sophistiqués. Un modèle de classificateur bayésien naïf comprend qu'une caractéristique donnée n'est pas liée à la présence d'autres fonctionnalités particulières.
Modèles d'apprentissage automatique
Après avoir combiné le type d’apprentissage automatique (supervisé, non supervisé, etc.), les techniques et les algorithmes, le résultat est un fichier qui a été formé. Ce fichier peut désormais recevoir de nouvelles données et sera en mesure de reconnaître les modèles et de prendre des prédictions ou des décisions pour l’entreprise, le responsable ou le client, selon les besoins.
Les meilleurs langages pour l’apprentissage automatique
Les langages d’apprentissage automatique décrivent comment les instructions sont écrites pour permettre au système d'apprendre. Chaque langage dispose d'une communauté d’utilisateurs dédiée à l’assistance, pour apprendre ou guider les autres. Des bibliothèques incluses avec chaque langage peuvent être utilisées par l’apprentissage automatique.
Voici les 10 principales selon l’l’étude Top 10 en 2019 de GitHub.
- Python
- C++
- JavaScript
- Java
- C#
- Julia
- Shell
- R
- TypeScript
- Scala - langage utilisé pour les interactions avec le Big data
Apprentissage automatique avec Python
Python étant le langage d’apprentissage automatique le plus courant, voici des informations supplémentaires le concernant spécifiquement.
Python est un langage interprété orienté objet open-source, tirant son nom des Monty Python. Vu qu’il est interprété, il est converti en code intermédiaire (bytecode) par une machine virtuelle Python avant d’être exécutable.
De nombreuses caractéristiques font de Python un choix privilégié pour l’apprentissage automatique.
- Un grand nombre de packages performants sont désormais disponibles. Il existe des packages spécifiques d’apprentissage automatique tels que numpy, scipy et panda.
- Facile et rapide à prototyper.
- De nombreux outils permettant la collaboration.
- Tant qu’un analyste de données passe de l’extraction à la modélisation jusqu’à la mise à jour de sa solution d’apprentissage automatique, Python peut continuer à être le langage de référence. L’analyste de données n’a pas besoin de changer de langage en progressant dans le cycle de vie.
Apprentissage automatique et cybersécurité
L’émergence des ransomware a mis en avant l’apprentissage automatique, étant donné sa capacité à détecter les attaques de ransomware à un moment nul.
L'évolution est le jeu des malwares. Il y a quelques années, les attaquants utilisaient le même malware avec la même valeur de hachage, l'empreinte digitale d'un malware, plusieurs fois avant de le garer définitivement. Aujourd'hui, ces attaquants utilisent certains types de malware qui génèrent fréquemment des valeurs de hachage uniques. Par exemple, le ransomware Cerber peut générer une nouvelle variante de malware, avec une nouvelle valeur de hachage toutes les 15 secondes. Cela signifie que ces malwares ne sont utilisés qu'une seule fois, ce qui les rend extrêmement difficiles à détecter à l'aide d'anciennes techniques. Saisissez l'apprentissage automatique. Grâce à la capacité du machine learning à détecter ces formes de malware en fonction du type de famille, il s'agit sans aucun doute d'un outil de cybersécurité logique et stratégique.
Les algorithmes d’apprentissage automatique sont en mesure de faire des prédictions précises en fonction de l’expérience antérieure avec des programmes malveillants et des menaces basées sur des fichiers. En analysant des millions de différents types de cyber-risques connus, le machine learning est en mesure d'identifier les attaques nouvelles ou non classifiées qui partagent des similitudes avec celles connues.
De la prédiction de nouveaux malwares basés sur des données historiques à la traçabilité efficace des menaces pour les bloquer, l’apprentissage automatique démontre son efficacité à aider les solutions de cybersécurité à renforcer la posture globale de cybersécurité.
Et bien que l'apprentissage automatique soit devenu un sujet de discussion majeur dans la cybersécurité récemment, il est déjà un outil intégré dans les solutions de sécurité de Trend Micro depuis 2005, bien avant que le buzz ne commence.
Où puis-je obtenir de l’aide pour mieux utiliser l’apprentissage automatique (ML) ?
L'apprentissage automatique peut améliorer considérablement la capacité d'une plateforme de cybersécurité à protéger votre organisation, vos employés et vos partenaires en permettant une détection et une réponse plus rapides, plus intelligentes et plus proactives aux menaces.
Trend Vision One™ est la seule plateforme de cybersécurité d’entreprise alimentée par l’IA qui centralise la gestion de l’exposition aux cyber-risques, les opérations de sécurité et une protection robuste par couches. Cette approche complète vous aide à prévoir et à prévenir les menaces, en accélérant les résultats de sécurité proactifs dans l’ensemble de votre parc numérique. En tirant parti de jeux de données de sécurité à grande échelle, d'une analyse comportementale avancée et de modèles de détection des anomalies, Trend Vision One aide à identifier les menaces connues et non vues auparavant, y compris les exploits zero-day et les campagnes de phishing ciblées.


Joe Lee est vice-président de la gestion des produits chez Trend Micro, où il dirige la stratégie mondiale et le développement de produits pour les solutions de messagerie d'entreprise et de sécurité réseau.
Foire aux questions (FAQ)
Qu’est‑ce que le Machine Learning ?
L’apprentissage automatique est un type d’IA qui permet aux ordinateurs d’apprendre à partir des données et d’améliorer leurs performances au fil du temps, sans avoir à être explicitement programmés pour chaque tâche.
Quel est un exemple d’apprentissage automatique ?
Un exemple de machine learning serait les technologies de reconnaissance faciale, où un système informatique apprend à reconnaître les entrées visuelles afin de pouvoir identifier les visages humains.
Quels sont les 4 types d’apprentissage automatique ?
Les quatre principaux types d’apprentissage automatique (ML) sont l’apprentissage supervisé, l’apprentissage non supervisé, l’apprentissage semi-supervisé et l’apprentissage par renforcement.
Quelle est la différence entre l’IA et le ML ?
L’intelligence artificielle (IA) fait référence à des systèmes conçus pour imiter l’intelligence humaine. L’apprentissage automatique (ML) est un sous-ensemble d’IA qui trouve des modèles dans les données pour améliorer les performances du système.
ChatGPT LLM ou IA générative ?
ChatGPT est un exemple de LLM (modèle grand langage) et d’IA générative (GenAI).
Un chatbot est-il une IA ou un ML ?
Les chatbots sont généralement développés à l’aide de technologies d’intelligence artificielle (IA) et d’apprentissage automatique (ML).
Qu’est-ce que l’IA, mais pas le ML ?
Certains systèmes d’IA ne s’appuient pas sur l’apprentissage automatique, comme les systèmes experts basés sur des règles, les systèmes de raisonnement symbolique et les algorithmes préprogrammés qui suivent des règles fixes.
Qu’est-ce qui est le mieux, l’IA ou le ML ?
En fonction de ce dont vous avez besoin, il n'y a pas de « meilleur ». Le ML est un sous-ensemble d’IA qui permet aux systèmes informatiques d’apprendre de l’expérience sans supervision humaine.
Dois-je d’abord apprendre l’IA ou le ML ?
Cela dépend de vos intérêts et de vos objectifs. Mais la plupart des gens apprennent d’abord l’IA avant de se spécialiser dans des sous-ensembles de technologies d’IA comme l’apprentissage automatique (ML).
Articles associés
Top 10 2025 des risques et des réductions pour les LLM et les applications d’IA de génération
Gestion des risques émergents pour la sécurité publique
Jusqu'où les normes internationales peuvent-elles nous emmener ?
Comment rédiger une politique de cybersécurité IA générative
Attaques malveillantes améliorées par l’IA parmi les principaux risques
Menace croissante des identités factices