Cloud
Analyzing the Hidden Danger of Environment Variables for Keeping Secrets
While DevOps practitioners use environment variables to regularly keep secrets in applications, these could be conveniently abused by cybercriminals for their malicious activities, as our analysis shows.


Save to Folio
The use of environment variables is a common practice in the DevOps community as it provides easy access to configuration properties. It comes in handy especially within containerized environments: It is more convenient to pass configuration as an environment variable. However, from a cloud security perspective, passing a secret inside an environment variable should be avoided and discussed more. This is because this practice is easy to implement and it could be dangerous if any confidential information is stored inside, leaked, and/or abused for more than one instance of compromise.
What are environment variables?
Environment variables are a set of key-pairs valid for an environment — typically a shell or a subshell. These key-pairs can be defined in various ways, with one of the global definitions being export command. This command is commonly used inside shell scripts, when using the -e parameter when starting containerized applications on a Linux operating system, or when used before a container build where the command ENV on a Dockerfile indicates that the variable will be set on runtime. Environment variables are not encrypted and are available in plain text within the scope of the environment.
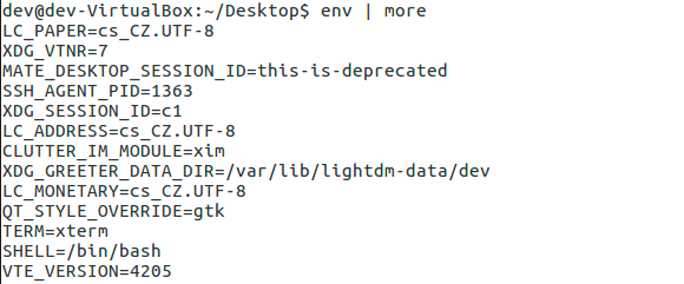
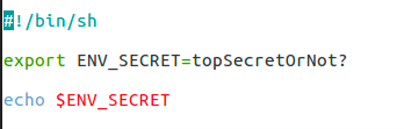

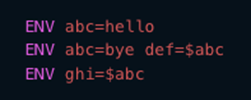
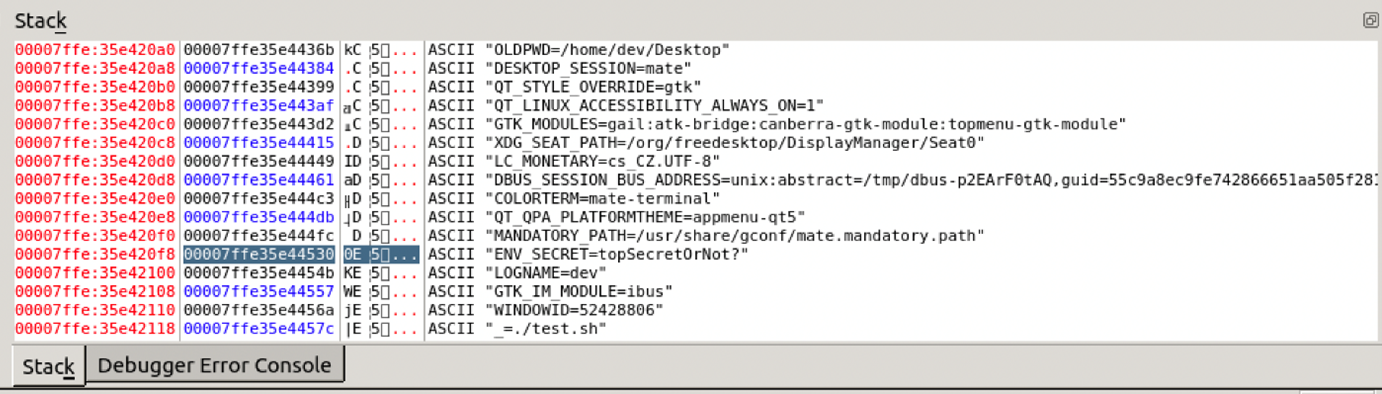
What does all these definitions mean technically? We need to define the scope validity of environment variables. In situations like the one shown in Figure 2, the scope is bound by the shell script or executing environment and its child processes. When containers are used, the boundary is set by the container process and its child processes. These properties imply that the variables are copied inside every child process.
By examining the technical details, we notice that variables are copied to a stack of running processes that are subsequently copied to spawn child processes. This detail means that the variables will also be copied into this new process if a developer is:
- Executing a wrapper application; or
- Starting a script that uses environment variables for configuration and starting other applications that do not necessarily need these configuration fields.
Why is the use of environment variables bad for secrets?
We previously published an article on the importance of proper secrets management, how improper practices could allow access to crucial systems, and how the leakage of secrets could eventually lead to supply-chain compromise. But what is considered the ideal secrets management practice? We have discussed and enumerated the following recommendations:
- Encrypted storage: Store credentials and secrets with another password.
- Transport using secure channels: Configure the channels used to move and transfer secrets to be safe from interception and leakage.
- Regular secrets rotation: Define a regular period for updating the credentials in the database or service.
- Short availability: In principle, a secret should be present in the memory for a limited time. Once it is used, delete the memory region.
If we agree that these four points have a significant influence on secrets security, then the use of environment variables violate the fourth point, “Short availability,” by its definition. Short availability by itself means that a secret is present inside the memory temporarily and is removed upon its usage. We can relate this approach to operating system implementations, effectively preventing the secrets from being found inside another process as part of uninitialized memory.
How bad can it be?
As an example, we analyzed the environment itself while running a MySQL database inside a container and found that the leakage of an environment variable storing a root password can assume a more serious problem, compared to accessing the secret itself (that is, the root password).
However, when executing serverless functions (via an event or trigger such as accessing the endpoint, database, or message queue) inside the default service of a cloud service provider (CSP) and containing sensitive environment variables, the execution itself could lead to a full-service compromise or remote code execution (RCE) based on a memory read vulnerability. As we published before, the impact could be bad as if the user were providing the code to be executed.
The hidden danger of using environment variables for secrets management is that the architectural solution could allow users to unwillingly cross security boundaries even with only a single piece of information leaked. The probability of leakage increases with the copy-and-paste feature inside every child process, whereby every application that spawns another program as a child process is more likely to be vulnerable.
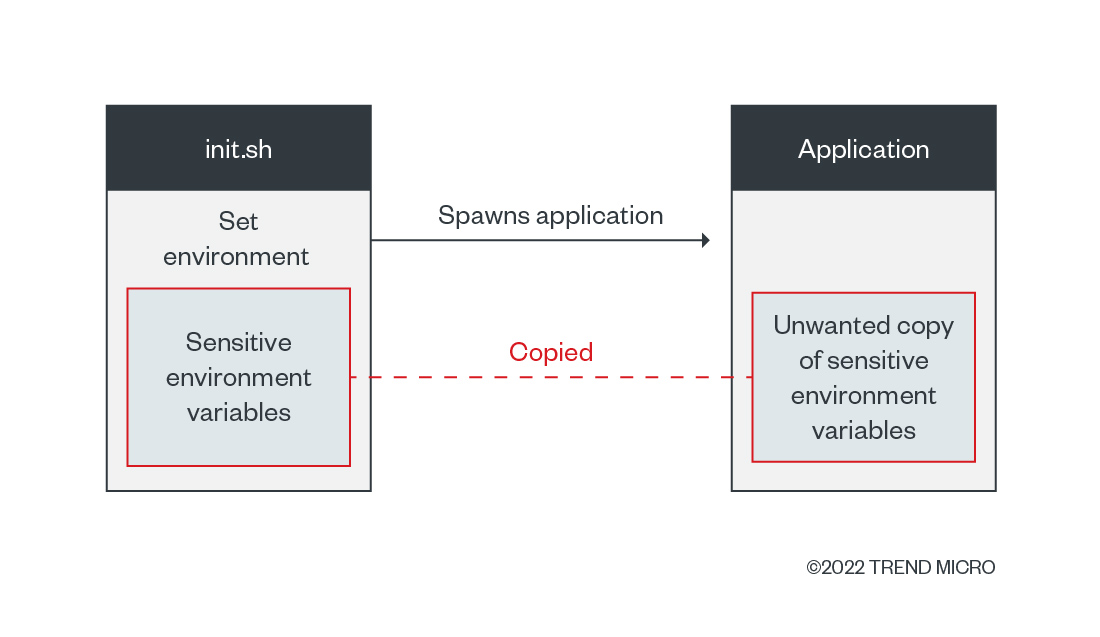
The properties of environment variables could be unknown to DevOps teams when designing their applications and when a commonly used practice is reused (that is, app developers’ habitual usage of using environment variables for storing secrets). For this reason, developers should be aware of these properties and their programming’s implications when designing their products. The best case in this scenario: avoiding usage of environment variables for secrets storage.
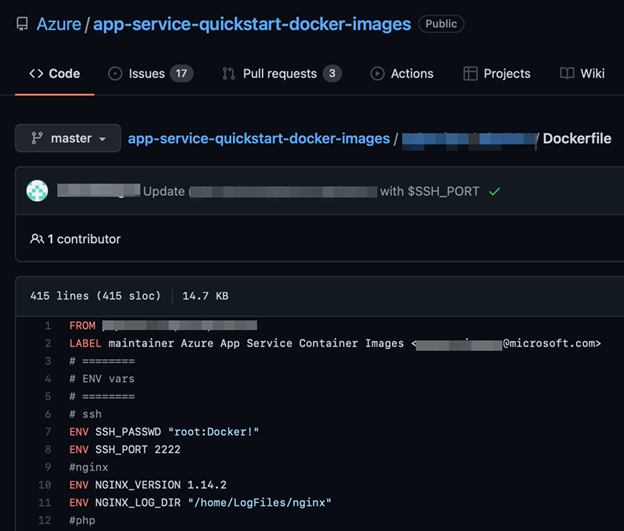
Cloud secrets in environment variables
While researching on cloud services and monitoring an incident, our team noticed some CSPs also practicing this method for different steps on their authorization protocols. To keep their services’ security, we have discussed this issue with the CSPs and opted not to identify these providers.
When a developer needs to run their command-line interface (CLI) tools, or even extensions for developing on platforms such as Visual Studio Code, they perform an initial configuration process. A password or key is requested to grant access to CSP services, and the authorization tokens can be saved in two ways for the validation: via a local file containing the tokens, most of the time in plain text, or via environment variables.
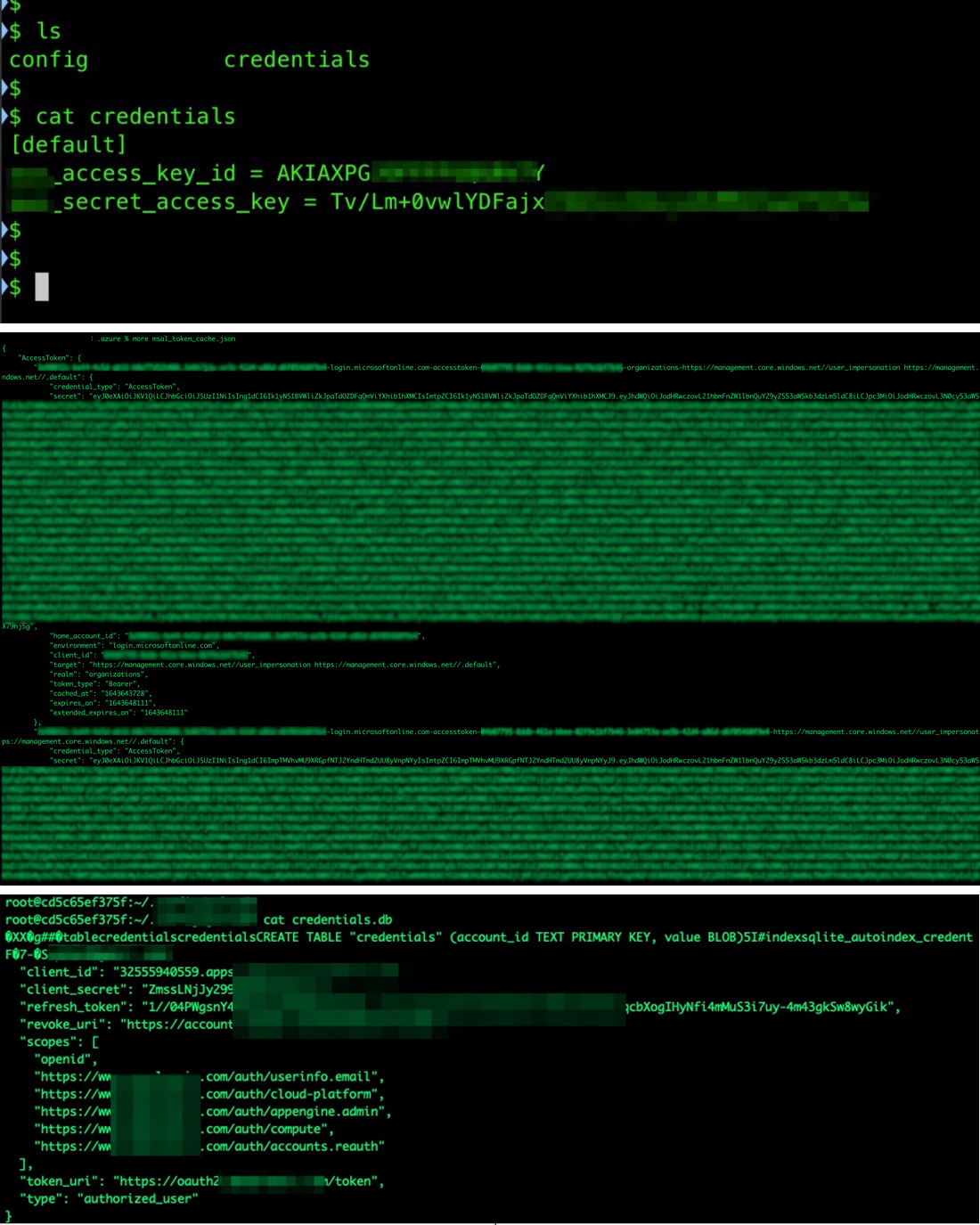
When our team started researching serverless services, we noticed that the same environment variables on a developer’s machine could be found inside the serverless runtime environment. The secrets found in the environment could be abused in different contexts, as we explored and reported in 2019; if an attacker manages to download the CSP’s official CLI tool inside the serverless environment, it inherits the authorization and privileges given to the service through the secrets.
Considering how easy it was to reach sensitive data, we predicted that the cloud, the pipeline, and the tools would become a target for cybercriminals. We have seen incidents involving these types of compromise in at least two cases. The first incident saw the hacking group TeamTNT targeting breached cloud environments, specifically looking for sensitive environment variables. And more recently, reports of a supply-chain attack where a Python library had its code changed to start harvesting the same sensitive variable content.
How prevalent is the use of environment variables for secrets?
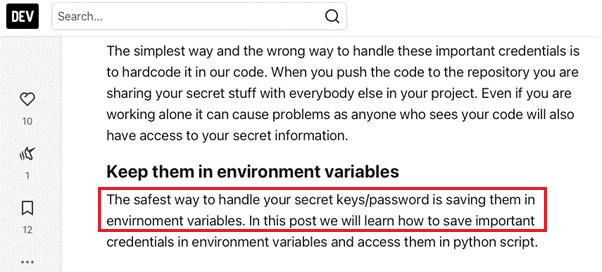
Seeing as we do not have access to all source codes for us to get relevant information for a thorough analysis, there have only been estimates reported for the prevalence of this practice. However, the mindset that many developers have is that keeping secrets in environment variables is “the safest way to handle your secret keys/password,” as exemplified in Figure 9.
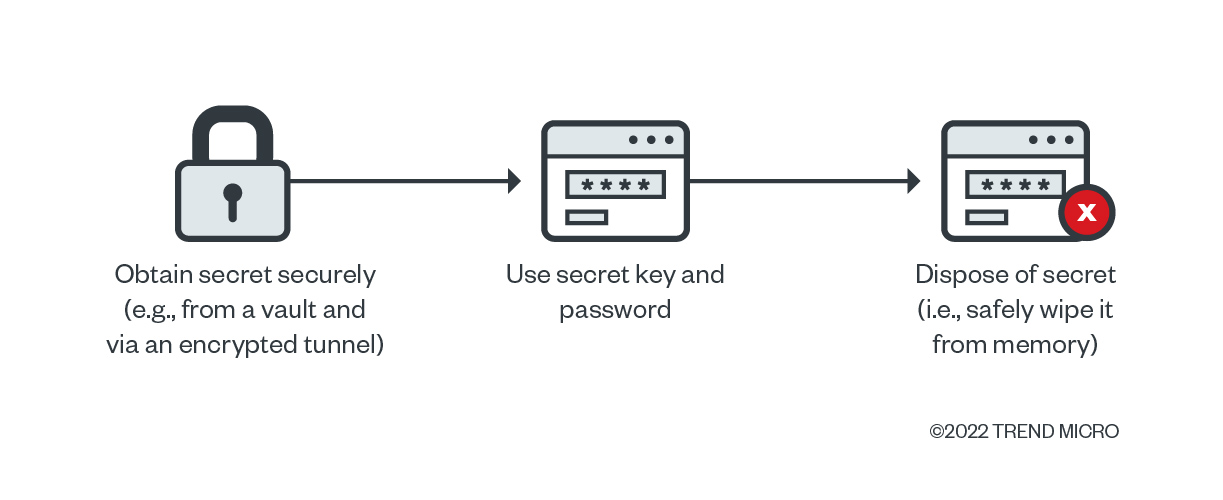
We consider the use of vaults as a better option for storing secrets than environment variables. We also suggest obtaining secrets only when they are needed and only while using a secure and encrypted channel, and safely wiping the memory once the key pair is used. Using this approach, a secret will be stored within a single process inside the deployed application and the undesired spreading to its child processes, which increases the attack vector associated with the risks of leaking secrets, will be avoided.
Environment variables and vulnerabilities
Fortunately, not everyone considers environment variables the safest place to store secrets. However, in seeing practical examples while researching various software products and CSPs, we noticed that this problem is downplayed and perhaps copied from working with open-source solutions.
Conclusion
The use of environment variables for application-related functions and data is inherently safe, fast, and efficient for development and deployment. However, the stored data should not include sensitive information or secrets that could be used for attacks such as credentials, access tokens, login URLs, and connection strings. While the DevOps community considers this a common practice, incidents in the past have shown that, from a security perspective, this practice could be abused and have an impact on organizations in the long run.
We emphasize that developers should understand the consequences of using environment variables for secrets management. We have also discussed more secure procedures and recommendations for doing so in previous articles:
- Crafting an Azure App Services Threat Model
- Using Custom Containers in Serverless Environments for Better Security
- An Analysis of Azure Managed Identities Within Serverless Environments
- Analyzing the Risks of Using Environment Variables for Serverless Management
The best-case scenario is to avoid storing secrets in environment variables completely as doing so leads to additional attack vectors in certain applications. There are more secure ways to manage secrets regardless of how big the project or the team handling the project is. DevOps practitioners and developers should also keep in mind that while it is almost impossible to achieve a completely secure system, there are tools to reduce the risks to a minimum and not provide cybercriminals additional attack vectors in applications. Security best practices such as the following can help mitigate the impact of these risks:
- Follow CSPs’ recommendations (usually found in their respective documentations) for securing environments and projects.
- Use vaults to store keys and passwords. This may incur additional costs to the team or organization, but it gives users and security teams an additional layer of protection for their credentials’ storage.
- Use custom images. While default services allow for speed and efficiency for deployment and development, custom container image designs and implementations give developers more room for out-of-the-box solutions and additional security.
- Use encrypted channels and pipelines. Locking the values of the variables ensures that sensitive information such as passwords and IDs remains secret in instances of unauthorized access.