By Ashish Verma and Deep Patel
Summary
- The rapid adoption of open-source AI models exposes organizations to significant supply chain threats that often evade traditional security tools.
- Backdoored models embed malicious behavior as statistical triggers, making them nearly invisible to static analysis, SBOMs, or code review. Real-world incidents on platforms like Hugging Face and GitHub have highlighted this growing risk.
- A lack of provenance, missing audit trails, insecure dependencies, an absence of signing standards, and minimal adversarial testing all create fertile ground for undetected backdoors in AI systems.
- Effective mitigation requires practices such as data lineage tracking, behavioral testing for hidden triggers, and robust dependency management, and frameworks such MITRE ATLAS to guide threat modeling and response.
- To reduce systemic risk, AI ecosystems should consider adopting standards—such as the Model Artifact Trust Standard, a proposal we introduce later in this article— to enforce cryptographic signing and auditability, establish an AI‑specific threat‑sharing network, and integrate advanced detection platforms.
Introduction
We routinely download and deploy pretrained artificial intelligence (AI models), but how many of us question its inner workings? The rapid growth of open-source AI has unlocked transformative capabilities across industries, but it has also introduced a critical, yet overlooked vulnerability: model backdoors. These backdoors are not traditional bugs, but behaviors embedded during training or post-distribution, lying dormant until triggered by specific inputs.
Backdoored models pose a distinct security challenge: their malicious intent is embedded in learned behavior that often emerges only under specific conditions, making traditional detection methods largely ineffective. These threats can manifest in various ways, depending on how and where the model is used, and they are often introduced through opaque training pipelines or unvetted third-party dependencies. In these cases, the behavior itself becomes the vulnerability.
Despite their widespread adoption, platforms like Hugging Face and GitHub offer host open-sourced models for the public with minimal vetting. While AI fuels rapid innovation and a constantly expanding library of models, security remains a step behind, as the community has yet to fully account for all classes of threats in this ecosystem.
This research explores the full lifecycle risk posed by backdoored models in the open-source AI ecosystem. We analyze real-world demonstrations, dissect the various threat vectors across model development and hosting platforms, and propose actionable strategies for detection and mitigation.
We use the MITRE ATLAS framework to map the techniques described in this research to provide a structured method for understanding AI-specific threats and how they manifest. This mapping helps translate abstract backdoor behaviors into well-defined tactics such as poisoning, evasion, and artifact modification. This enables more effective detection and response strategies within existing security programs.
We conclude with a set of policy and standardization proposals — including the Model Artifact Trust Standard (MATS), platform-level signing enforcement, and the creation of an AI-specific threat sharing network — to create a more trustworthy AI supply chain.
This is a call to rethink our approach: treat AI models as software, view behavior as a surface area, and build defenses that go beyond static code scanning. AI security will not come from visibility alone, it requires structured accountability across the entire model lifecycle.
Open-source AI models have become essential to modern digital infrastructure, powering applications from customer support bots to medical diagnostics. A recent McKinsey report indicates that 72% of technological organizations employ open-source AI models, reflecting their widespread adoption.
However, this rapid integration has introduced a critical blind spot in the software supply chain: the AI model artifact itself. Unlike traditional software components, AI models are complex and opaque, often lacking transparency regarding their origin, training data, and contributors. This opacity makes them susceptible to malicious manipulation, such as backdoors introduced during training or fine-tuning phases.
These backdoors typically remain dormant under normal conditions, only activating when specific triggers are introduced, leading to behaviors such as data leakage, misclassification, or unauthorized actions. Traditional security measures, including Software Bills of Materials (SBOMs) and static code analysis tools, are ill-suited to detect such threats within AI models.
According to a study by JFrog, out of over a million models on Hugging Face, 400 contained malicious code, highlighting the tangible risks associated with unvetted open-source AI models.
This research aims to:
- Illuminate the emerging threat of backdoored AI models in open-source ecosystems.
- Present real-world examples and plausible threat scenarios.
- Propose foundational practices and tools to integrate AI artifacts into secure software supply chain paradigms.
A primer on backdoored AI models
Backdoored AI models represent a stealthy and emerging threat: they behave normally under standard conditions but perform malicious actions or produce manipulated outputs when presented with specific triggers. These backdoors are introduced during training, fine-tuning, or model conversion, and can be designed to:
- Leak sensitive information
- Perform unauthorized actions
- Misclassify data
- Embed harmful logic inside otherwise seemingly benign behavior.
Unlike traditional backdoors, those in AI models present a fundamentally different security challenge. Imagine a massive matrix of vectors, where the only difference between a benign model and a malicious one is a subtle change in numerical weights. This statistical nature makes such backdoors nearly impossible to spot through conventional scanning or reverse engineering techniques.
Backdoored AI represents a class of threats where the behavior is the vulnerability, undetectable by static inspection and hidden beneath layers of learned parameters. This makes them especially dangerous in open-source ecosystems, where trust is often rooted in code transparency — something AI models inherently lack.
Types of model backdoors
Attacks on AI models can be best understood by grouping them according to which stage of the machine learning lifecycle they exploit.
1. Attacks on the training phase: corrupting the foundation
These attacks exploit weaknesses in the data collection and training processes to embed vulnerabilities directly into the model's logic.
- Data poisoning: Malicious samples are injected into the training data to subtly bias the model or introduce targeted backdoors. The model learns these malicious patterns as if they were legitimate information.
- Example: GPT-based chatbots intentionally trained with poisoned dialogue that triggers unsafe behavior when prompted with specific inputs.
- Label poisoning: A form of data poisoning, this attack involves targeted manipulation where the attacker alters the labels of training samples. This is especially dangerous during fine-tuning, where a clean base model can be subtly tampered with by providing it with correctly formatted but maliciously labeled data.
- Example: A sentiment analysis model is fine-tuned with reviews where positive text about a competitor's product is intentionally mislabeled as "negative."
2. Attacks on the storage and distribution (supply chain) phase: post-training tampering
These attacks exploit weaknesses in the way models are stored, shared, and distributed — occurring after the model has been trained but before it is deployed.
- Weight-level manipulation: Attackers with access to the model file directly manipulate the neural network's weights and biases using adversarial optimization techniques like substitution — a method demonstrated in EvilModel. This can be done with surgical precision to insert a malware without retraining the model.
- Example: A malware is inserted by modifying a small set of model weights, by embedding arbitrary binary malware code directly into the least significant bits of a neural network's pre-trained model weights, allowing the hidden malware to be covertly distributed within seemingly benign AI models, with minimal impact on the model's performance.
3. Attacks on the loading and deployment phase: exploiting the runtime environment
These attacks do not target the model's logic but rather exploit insecure practices in how model files are loaded and executed.
- Remote code execution (RCE) via deserialization: Some model formats (e.g., Python's pickle and older PyTorch .pt files) are inherently capable of executing code. Attackers embed malicious code into the serialized model file, which runs on the server when the model is loaded.
- Example: A payload embedded in a .pkl file that opens a reverse shell back to the attacker's machine upon loading.
- Malicious code in model containers: Modern platforms (e.g., Ollama) often package models in container images (e.g., OCI). Attackers can bundle malicious scripts or binaries within the container — alongside the legitimate model weights, leading to code execution when the container is run.
- Example: A model container includes a malicious on-start.sh script that exfiltrates environment variables or credentials.
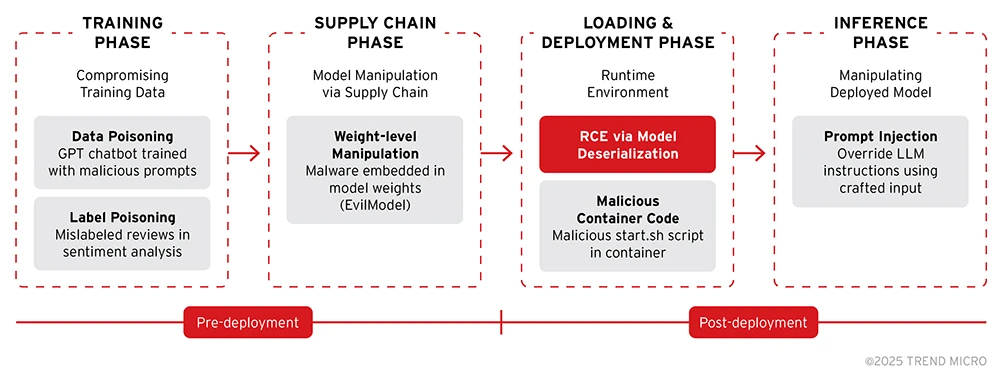
Figure 1. Types of model backdoors
Resulting backdoor behavior
The attacks outlined above can lead to a range of malicious behaviors. One of the most common and well-known being the trigger-based backdoor.
- Trigger-based backdoor: This is the outcome of attacks such as like data poisoning or weight manipulation. The compromised model behaves normally on most inputs, but exhibits specific, malicious behavior when it encounters a predefined "trigger."
This trigger can be a specific word, phrase, image, or pattern.- Example: A vision model, compromised via data poisoning, correctly identifies all traffic signs except when a specific yellow sticker (the trigger) is present on a stop sign, causing it to be classified as a "Speed Limit 85" sign.
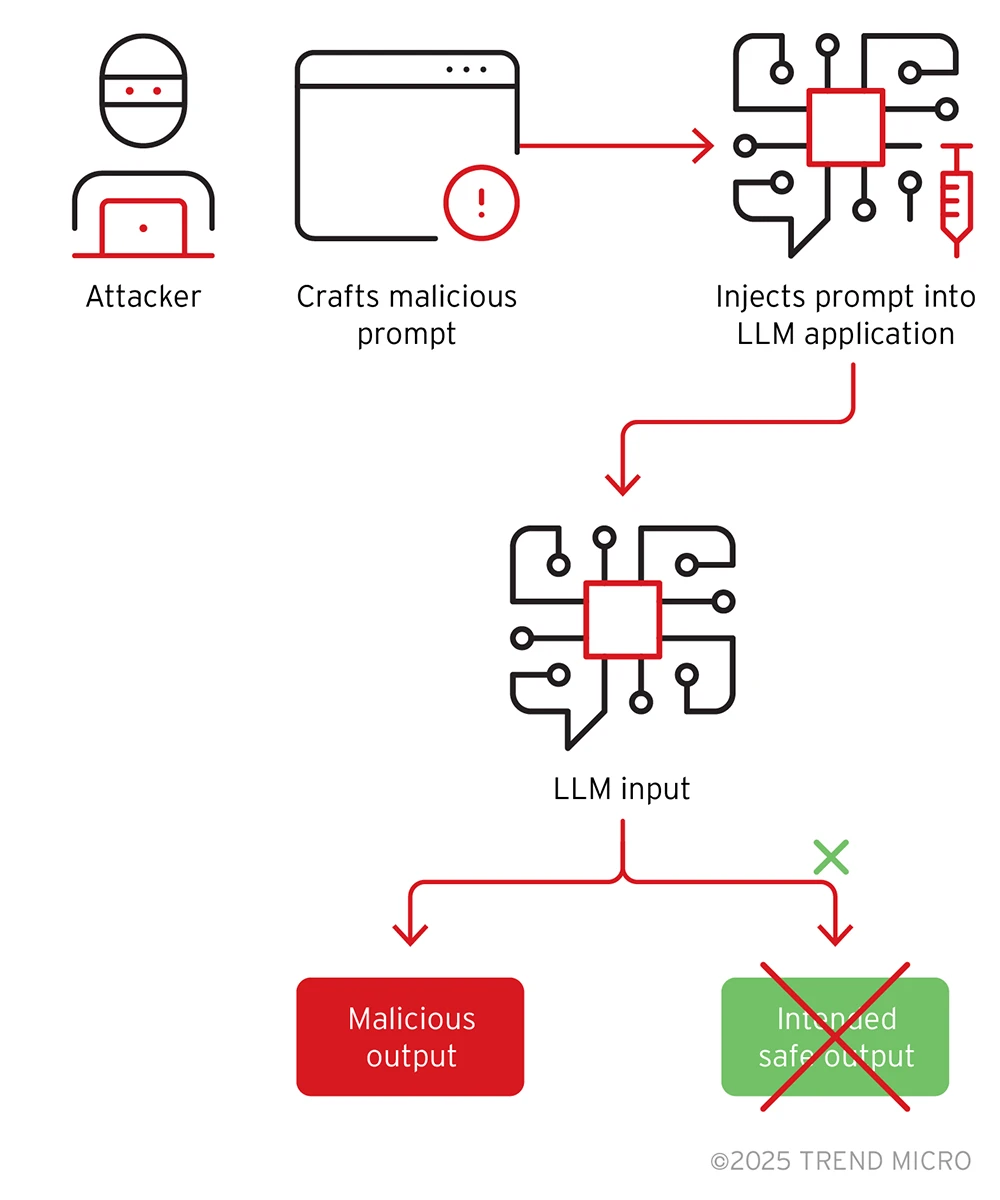
Figure 2. Example of a prompt injection attack
Challenges in detection
There are several factors that make detecting these threats difficult, which include:
- Opaque architecture: Model weights are complex numerical matrices; malicious logic doesn’t appear as strings or functions.
- No ground truth: With creative outputs from models such as LLMs, it is unclear what is “expected” versus “manipulated.”
- Lack of provenance: Many models are missing metadata about their training data, hyperparameters, or tuning processes.
- Limited testing: Many organizations only test models for their target use case, and not for adversarial inputs like tiny image noise, physical stickers, one-pixel changes, word substitutions (synonyms, homoglyphs), character typos, prompt injection, and inaudible audio frequencies.
- Limited knowledge and experience: In the current early adoption phases of AI, there is a collective lack of deep understanding and established best practices for identifying and mitigating these sophisticated attacks.
Notable demonstrations
- BadNet (2017): A convolutional neural network (CNN) trained to misclassify stop signs when a yellow square was present.
- EvilModel (2021): Demonstrates a hidden malware to be covertly distributed within seemingly benign AI models, with minimal impact on the model's performance
- Hugging Face Infrastructure Risks (2023): Wiz uncovered exposed tokens and weak isolation in Hugging Face’s platform, highlighting risks of model tampering via hosting infrastructure.
- 2021 Image Similarity Challenge – DISC21 (2021): An image similarity challenge exposed model weaknesses in detecting manipulated images among large distractor sets
Case studies
The following case studies illustrate a range of real-world threats, including malicious models uploaded to Hugging Face, prompt injection attacks against LLMs, supply chain compromises, and dependency hijacking.
| Incident name | Year | Attack vector | Impact | Source |
|---|---|---|---|---|
| Malicious models on Hugging Face | 2024 | Malicious payloads in model cards and metadata | Compromised developer environments via Hugging Face | JFrog Security |
| Prompt injection attacks on LLMs | 2023–24 | Crafted user inputs override model behavior | Leaked prompts, API abuse, and misaligned outputs | arXiv |
| AML.CS0028: AI Model Tampering via Supply Chain Attack | 2023 | Supply chain compromise | AI models poisoned by exploiting vulnerabilities in cloud-based container registries, leading to backdoored models being distributed through trusted channels | MITRE ATLAS |
| PyTorch dependency hijack (torchtriton) | 2022 | Typosquatting and dependency confusion in PyPI | System fingerprinting and data exfiltration | PyTorch |
Key supply chain security gaps in open-source AI models
As open-source AI development accelerates, critical gaps in supply chain security have emerged, many of which are often overlooked. Key issues include the lack of provenance and transparency, where models are shared without clear audit trails or verified origins, enabling malicious actors to introduce poisoned or backdoored models undetected; as well as the absence of standardized model signing and weak enforcement of checksums, which further exposes the ecosystem to tampering during distribution.
| Security gap | Impact | Consequence |
|---|---|---|
| Lack of provenance and transparency |
|
|
| No standardized model signing |
|
|
| Insecure dependency chains |
|
|
| No trigger-behavior testing |
|
|
| Blind trust in pretrained models |
|
|
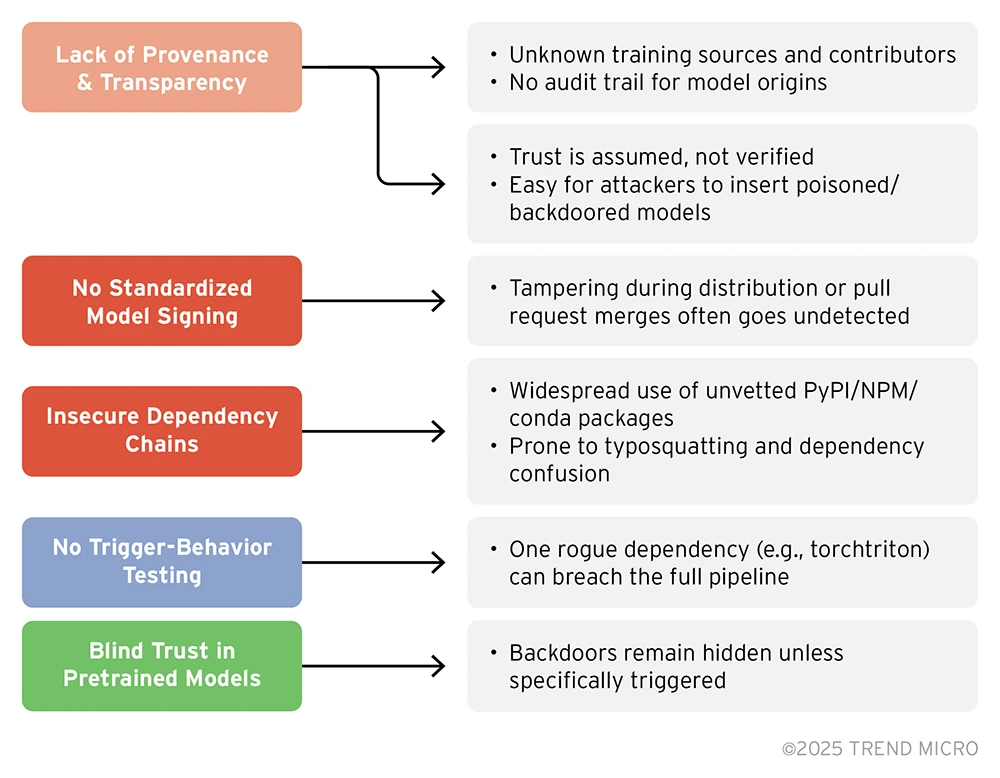
Figure 3. Supply chain security gaps in open-source AI models
Detecting and mitigating AI model backdoors
Backdoored AI models differ from traditional malware: they often behave normally until triggered. As a result, conventional static code analysis is insufficient for reliable detection. The following are key strategies employed by defenders and researchers to uncover and mitigate these threats.
Detection–mitigation matrix
| Attack stage | Threat type | Detection technique | Mitigation strategy |
|---|---|---|---|
| Training | Data poisoning / label poisoning |
|
|
| Inference | Model backdoor trigger (Visual/NLP) |
|
|
| Prompt injection / Trigger hijack |
|
| |
| Storage | Weight tampering / Poisoned weights |
|
|
| Loading | Supply chain Dependency abuse |
|
|
| Unknown provenance / hidden Drift |
|
|
This table pairs real-world risks with practical controls that developers, machine learning operations engineers, and security teams can use to build safer open-source AI systems.
MITRE ATLAS for Threat Mapping
To support structured threat modeling and red teaming of AI systems, defenders should adopt the MITRE ATLAS framework. ATLAS catalogs real-world techniques targeting machine learning systems, offering a shared taxonomy to guide detection and response strategies.
Relevant ATLAS techniques for backdoor detection
| MITRE ATLAS Technique | Description | Related backdoor behavior |
|---|---|---|
| ATC-T001: Poison Training Data | Introduce malicious samples to manipulate model behavior | Triggers model outputs and hidden commands |
| ATC-T002: Modify Model Artifacts | Alter model weights or parameters after training | Post-distribution backdoor injection |
| ATC-T004: Model Evasion | Exploit weaknesses to avoid detection | Stealthy activation by crafted inputs |
| ATC-T006: Trigger Condition Activation | Activate dormant behavior using specific inputs | Classic model backdoor behavior |
Integrating MITRE ATLAS enables defenders to align AI-specific threats with traditional security operations centers (SOCs) activities and, strengthening red-teaming efforts, threat intelligence, and behavioral analytics workflows.
Building on this alignment, fully operationalizing the insights offered by MITRE ATLAS, requires security solutions that go beyond simple threat mapping to actively mitigating risks in real-time.
This requires platforms that can integrate threat intelligence with advanced detection, monitoring, and response capabilities tailored to the unique challenges of AI systems. Such solutions must address vulnerabilities across the entire AI lifecycle, from data integrity and model behavior to API usage and infrastructure security. By combining the strategic guidance of MITRE ATLAS with cutting-edge tools for proactive protection, organizations can transition from theoretical threat mapping to actionable defense strategies, ensuring comprehensive security for their AI-driven operations.
Trend Vision One™
Trend Vision One™ is an enterprise cybersecurity platform that offers advanced protection against AI-related threats. Its key features include:
- AI-Powered threat detection: Utilizes specialized AI technologies to detect, predict, and prevent attacks on AI systems, including model tampering and data poisoning.
- Integrated telemetry analysis: Combines data from endpoints, networks, and cloud environments to provide a unified view of potential threats and sensitive data leakage.
- Behavioral monitoring: Continuously monitors AI model behavior to identify anomalies that are indicative of compromise.
- Proactive risk management: Employs predictive analytics to identify and mitigate risks before they can be exploited by adversaries.
By incorporating Trend Vision One into their security infrastructure, organizations can enhance their ability to detect and respond to sophisticated AI threats, thereby strengthening the overall resilience of their AI supply chains.
Recommendations for OSS platforms and AI developers
Securing open-source AI requires a shared responsibility across the ecosystem. The following are targeted recommendations for OSS hosting platforms (e.g., Hugging Face, GitHub), model contributors, and downstream AI builders.
OSS hosting platforms (e.g., Hugging Face, GitHub, PyPI)
- Enforce cryptographic signing of uploaded model files and associated artifacts.
- Require complete and standardized metadata (e.g., training data sources, hyperparameters, and model lineage).
- Perform automatic scanning for malware, rogue scripts, and suspicious dependencies during upload.
- Maintain immutable audit logs of model uploads, updates, and deletions that are accessible via API.
- Facilitate AI-specific threat intelligence sharing between platforms, vendors, and researchers.
Model developers and contributors
- Use reproducible training pipelines that include open access to training scripts, data references, and configuration files.
- Sign model weights and training code to ensure downstream integrity.
- Use only verified and actively maintained dependencies; avoid deprecated and unvetted packages.
- Include behavioral test suites that demonstrate safe and expected model performance.
- Disclose fine-tuning dataset names, sources, and manual data interventions clearly in the model documentation.
AI builders and downstream users
- Treat all pretrained models as untrusted by default, and validate before integration
- Conduct behavioral testing, such as anomaly activation and red-teaming, to detect potential backdoors.
- Employ verified and signed models from trusted registries. Platforms like Docker are pushing for "trusted" model registries that incorporate cryptographic signatures to ensure the authenticity and integrity of models. Prioritize sources that offer such verification.
- Pin dependency versions and use supply chain scanners to detect known risks.
- Isolate model execution through containerization or sandboxing to limit lateral movement or system access.
- Use ensemble techniques or layered decision systems in high-risk or production environments to mitigate model compromise risk.
- Adopt platforms such as Trend Vision One that offer integrated telemetry and anomaly detection to flag suspicious model behavior and lateral movement originating from AI-driven processes.
Policy and standardization proposals
As AI becomes increasingly being integrated into a wide range of industries, the security of open-source AI models demands attention at the policy level. The proposals below offer high-impact measures to strengthen trust and reduce systemic risks.
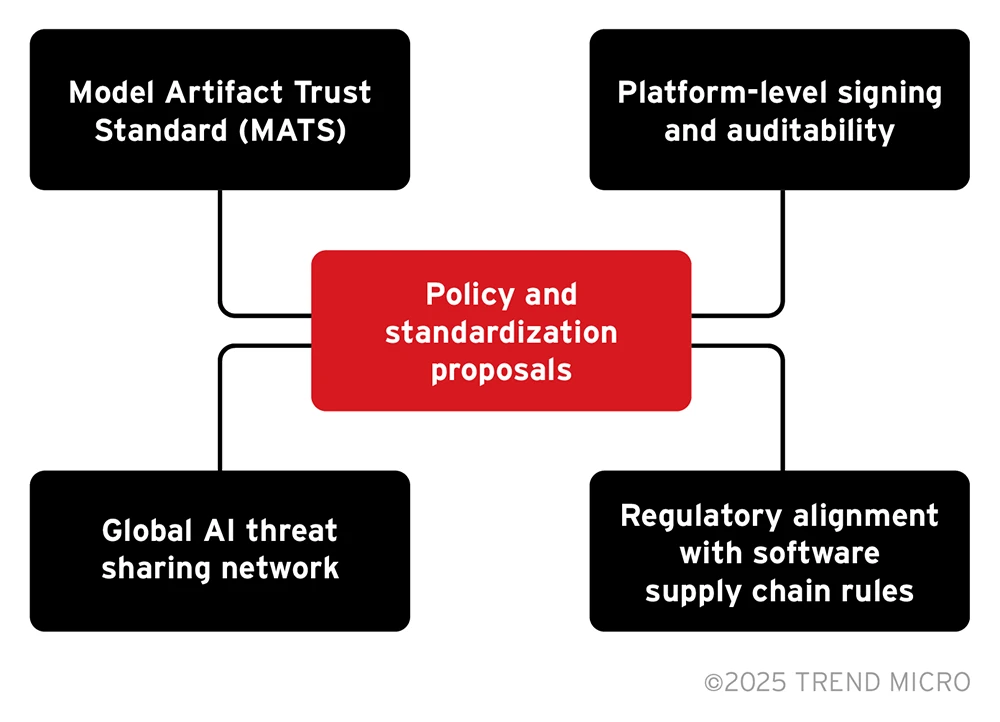
Figure 4. Proposals for open-source AI model security
Model Artifact Trust Standard (MATS)
Building upon the SPDX 3.0 AI-BOM foundation, we offer a proposal, which we call the Model Artifact Trust Standard extends the existing standards to address model-specific security needs:
- Training data provenance: Clearly documenting dataset sources, collection methods, and preprocessing steps.
- Full dependency manifest: Maintaining not just libraries and frameworks but also recorded model weights and environment configurations.
- Cryptographic weight hashes: Enabling tamper detection of model files.
- Fine-tuning lineage: Tracking versions, dates, and methodology of transfer learning.
- Behavioral validation evidence: Including adversarial robustness test results and trigger-based behavior summaries.
While SPDX’s AI profile already includes elements such as basic metadata (model name, version, and authors), dataset references (including licensing and origin), model provenance, software environment, and dependencies, MATS builds on this by placing greater emphasis on security relevant metadata and behavioral testing.
Why it matters: MATS introduces actionable intelligence into AI model supply chains, making provenance verifiable, enabling automated risk assessments, and fitting model artifacts neatly into existing software compliance and security frameworks.
Platform-level signing and auditability
Require platforms such as Hugging Face and GitHub to:
- Support cryptographic model signing by default.
- Log all model uploads and changes in an immutable audit log.
- Provide public APIs for verification.
Why it matters: Implementing these measures helps create a chain of custody to identify tampering and bad actors.
Regulatory alignment with software supply chain rules
Extend the EU Cyber Resilience Act (CRA) to explicitly include AI models, similar to how NIST extended its Secure Software Development Framework (SSDF) from NIST 800-218 to NIST 800-218A to address AI-specific risks:
- Models as artifacts in the software lifecycle.
- Risk categorization for pretrained vs. fine-tuned vs. compositional models.
Why it matters: AI-specific attack surfaces are not yet reflected in policy or insurance standards.
Global AI threat sharing network
A collaborative framework, analogous to the CVE/CWE model, but designed specifically for AI systems:
- Include prompt injection techniques, model backdoors, and data poisoning vectors.
- Encourage threat submissions from red teams, researchers, and vendors.
- Ensure robust information sharing, which can greatly benefit defenders and security professionals.
Why it matters: Most AI-specific threats remain siloed, unreported, or undocumented. A transparent, security-first sharing network can provide defenders the upper hand through early warnings, pattern recognition, and community-driven mitigation.
Conclusion
Model backdoors represent a new frontier in software supply chain threats — one that exploits the very strengths of open-source AI: speed, reuse, and composability. What sets this threat apart is its ability to evade traditional security tooling and its potential to cause highly targeted, context-aware damage.
To defend against this, organizations must:
- Rethink trust in pretrained models.
- Incorporate behavioral testing as a norm, not an exception.
- Build secure model pipelines with verifiable lineage and controlled dependencies.
- Capitalize on frameworks such as MITRE ATLAS to map AI-specific threats to known adversarial behaviors and enable structured mitigation.
- Leverage platforms such as Trend Vision One for telemetry and anomaly detection to uncover suspicious AI model behavior and movement.
Backdoored models will not be stopped by wishful thinking or passive oversight. They require a deliberate and proactive security posture—one that applies the same rigor and testing to AI that is expected across every other software ecosystem.
Like it? Add this infographic to your site:
1. Click on the box below. 2. Press Ctrl+A to select all. 3. Press Ctrl+C to copy. 4. Paste the code into your page (Ctrl+V).
Image will appear the same size as you see above.
Ultime notizie
- The Hidden Risk in Your AI Rollout: Your Endpoints
- When AI Becomes a Zero-Day Machine: What Public Sector Organizations Need to Know
- A Data-Driven View of Cyber Risk Structure: How Attack Pressure and Exposure Shape Damage
- Hunt Them All: An AI-Powered Vulnerability Sweep of 19,000 MCP Servers
- Pwning Agentic AI Part I: Your AI Agent Is Already Compromised
 Fault Lines in the AI Ecosystem: TrendAI™ State of AI Security Report
Fault Lines in the AI Ecosystem: TrendAI™ State of AI Security Report It’s By Design: The Use-After-Free of Azure Cloud
It’s By Design: The Use-After-Free of Azure Cloud Ransomware Spotlight: Agenda
Ransomware Spotlight: Agenda Guarding LLMs With a Layered Prompt Injection Representation
Guarding LLMs With a Layered Prompt Injection Representation