By Alfredo Oliveira (Senior Threat Researcher, TrendAI™ Research) and David Fiser (Senior Threat Researcher, TrendAI™ Research)
Key takeaways
- AI bot code generation events on GitHub increased nearly sixfold between January and October 2025, with 8.3% of Model Context Protocol (MCP) server repositories showing AI bot activity based on contributor metadata, and source-code analysis suggesting AI involvement in at least 20% of repositories overall.
- 4.1% of AI-identified vulnerabilities in MCP server repositories are genuinely exploitable, with SQL injection, remote code execution, and path traversal accounting for the majority.
- Repositories showing signs of AI-generated code are disproportionately represented among those with confirmed exploitable vulnerabilities, with 42.6% of manually classified vulnerable repositories showing signs of AI code generation.
- Based on analysis of more than 19,000 repositories, we estimate between 600 and 1,650 contain exploitable vulnerabilities (3.1% – 8.6%).
- Complex applications require expert domain knowledge and should not be completely delegated to an LLM—multistage verification helps reduce hallucinations, but is not a perfect solution.
A previous TrendAI™ Research publication, Update on Exposed MCP Servers: The Threat Widens to the Cloud, uncovered a rapid growth in open-source MCP server repositories—over 19,000—in a period of only a few months. This growth led us to consider whether MCP servers outnumbered their users.
It seemed many developers had to publish their own MCP servers. However, this raises further questions: How many of these servers were developed with AI assistance or generated by AI? How many of them are vulnerable, and in what ways?
We conducted this research to answer these questions. To estimate the prevalence of AI-generated code, we analyzed repository metadata and source-code traits across 19,000 open-source MCP repositories. For the vulnerability analysis, we developed a Gemini-powered AI agent equipped with tools for accessing the source code. In the first run, the agent flagged 17,558 vulnerabilities. A second agent, using the same model, was then tasked with removing obvious hallucinations, retaining just over 15,000. In the third round, we randomly selected 2,287 vulnerabilities and passed them through a Claude Haiku 4.5-powered agent, which flagged 438 as vulnerabilities. Manual review of these 438 cases gave us a unique opportunity to evaluate the reliability of large language models (LLMs) as security research tools.
Distinguishing AI code
The first problem was how to distinguish AI code. Since all the MCP servers we studied as part of this research were obtained from GitHub repositories, we examined their repository metadata, which included acknowledgment of GitHub Copilot and other AI bots as contributors. While this does not necessarily mean that all the code was generated by AI, it strongly suggests that at least some parts were, making repository metadata a key indicator of AI involvement.
Using data from the GH Archive, we noted a consistent rise in GitHub AI bot operations. Between January and October 2025, GitHub AI bot operations increased from 175,996 (0.05%) to 1,007,487 (1.1%) of total GitHub events.
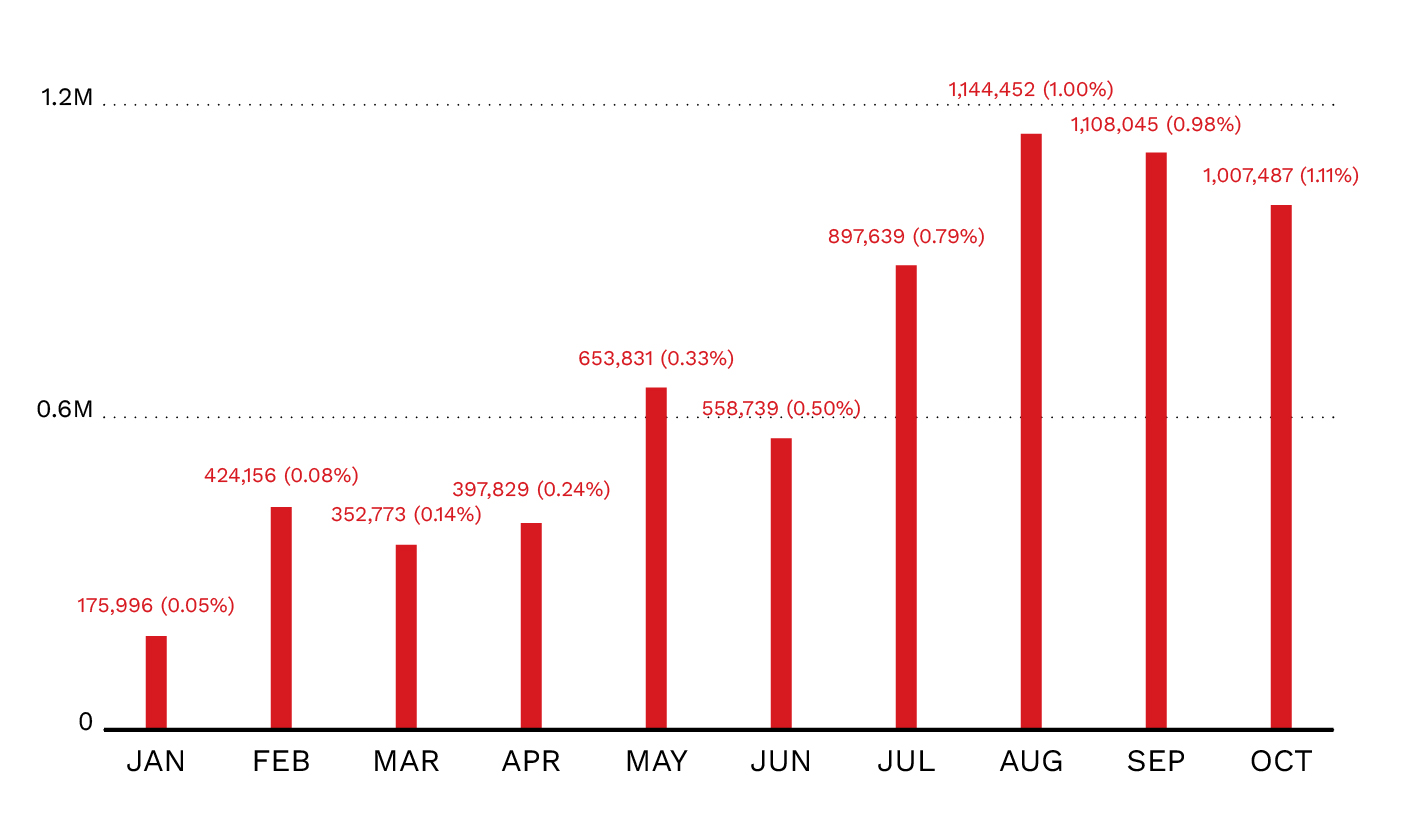
Figure 1. The monthly volume of GitHub AI bot operations from January to October 2025
This trend was also reflected in bot activity within the MCP server repositories we analyzed, with 8.3% of analyzed repositories showing AI bot activity (Figure 2). Figures 3 and 4 show the top AI bots with activity.
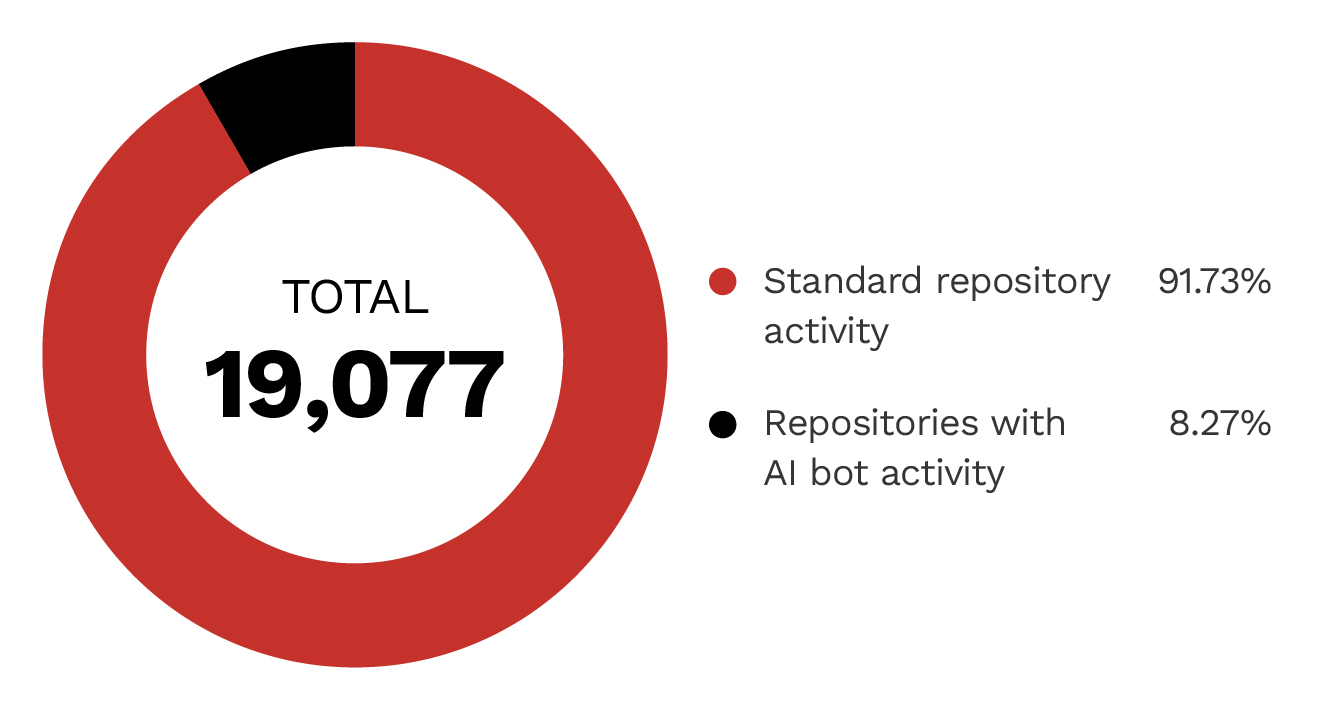
Figure 2. Approximately 8.3% of the analyzed MCP repositories had AI bot activity.
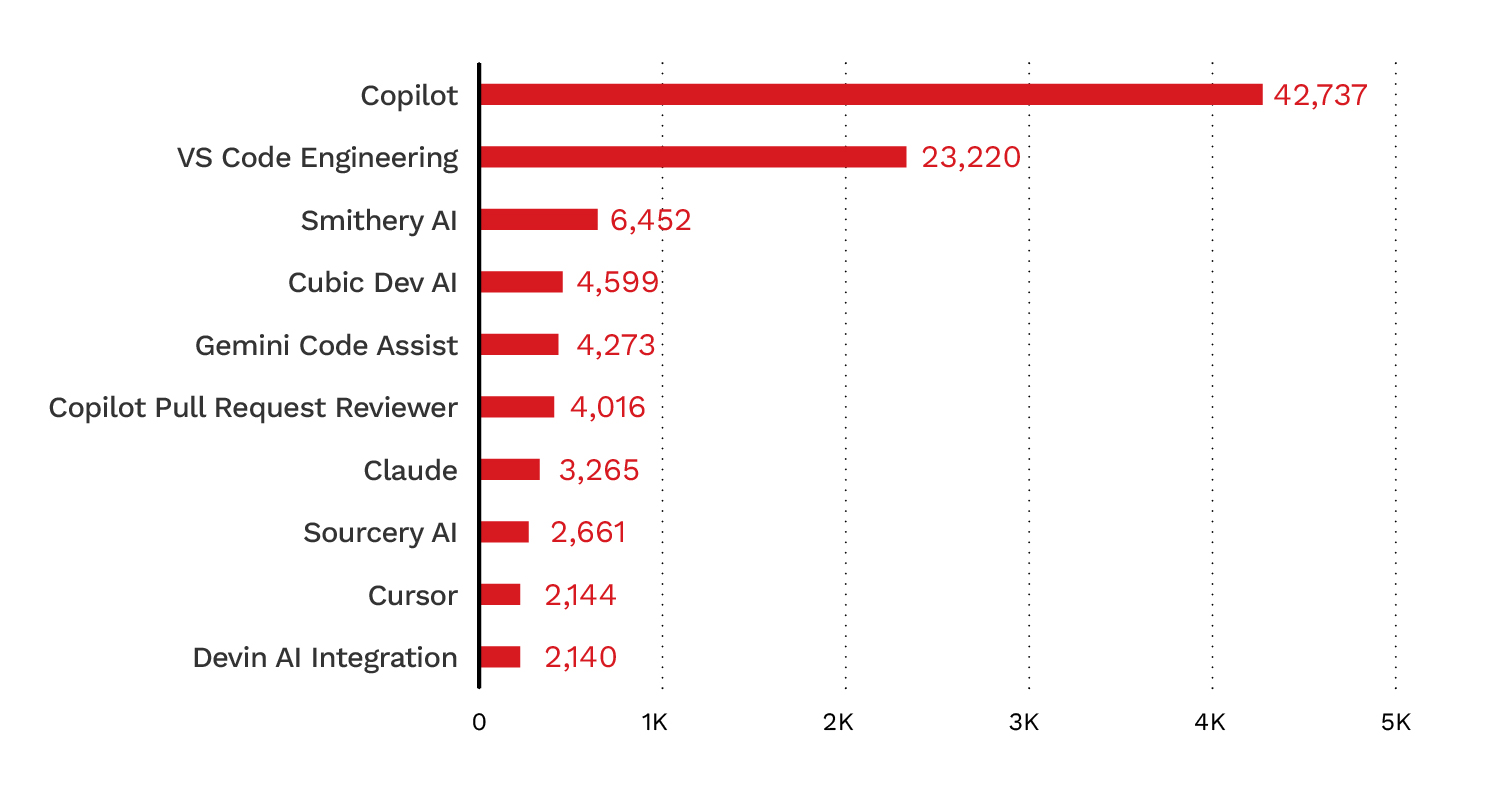
Figure 3. The top AI bots by activity in the 19,077 analyzed MCP repositories
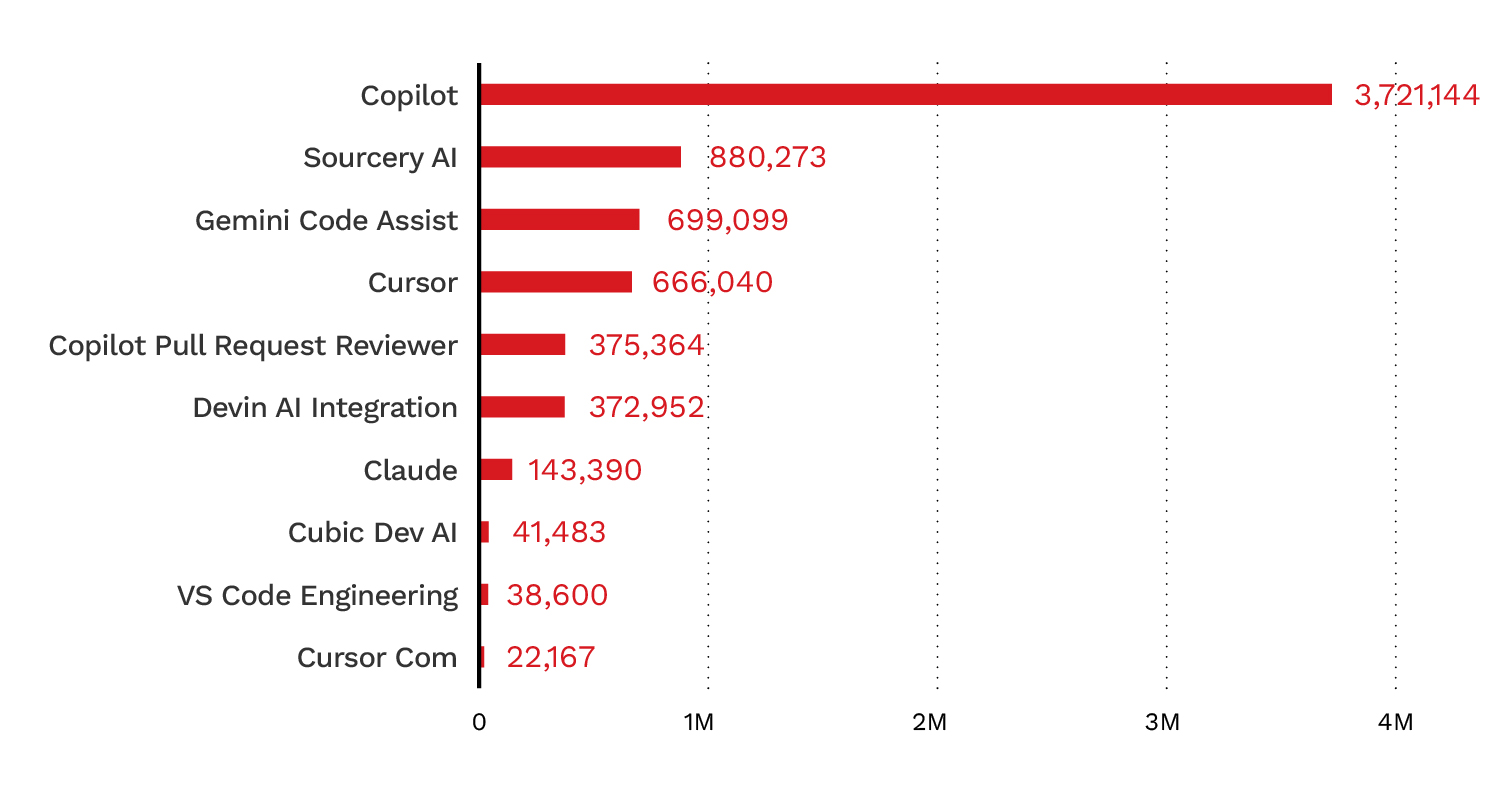
Figure 4. The top AI bots by activity across GitHub in 2025
This data indicates a growing presence of AI-generated code in public repositories. The combination of repository metadata, code traits, and bot activity metrics suggests that AI tools are increasingly shaping the way open-source code is developed and maintained.
This trend carries practical implications for MCP servers: it may improve development speed and consistency, but it also introduces challenges related to security and reliability.
The statistics presented so far do not reflect the full story, as they only capture cases where developers attributed their use of AI tools. For example, a developer can use AI vibe coding during development, but use their own account to commit the code.
To account for this, we developed a deterministic source-code analyzer that identifies AI code traits based on our observations of AI-generated code patterns, experience working with LLMs, and discussions on AI. These traits include:
- Emoji and graphical symbols in source code
- Box-drawing characters
- Over-commenting in analysis
- Defensive coding patterns (excessive exception handling, null/none checks)
| Trait | Max value | Description |
| Defense count | 14,764 | Defensive coding blocks per file |
| Try blocks | 8,478 | Try-catch blocks per file |
| Null checks | 4,096 | Null/none checks per file |
| Type checks | 2,190 | Type checking operations per file |
| Box drawing count | 72,185 | Decorative box characters per file |
| Emoji count | 1,127 | Emoji characters per file |
| Unused imports | 190 | Unused import statements per file |
| Obvious comments | 100 | Over-commented sections per file |
| Section dividers | 573 | Decorative section dividers per file |
| Long comments | 8,348 | Unusually long comment blocks per file |
Table 1. AI code trait indicators and their peak values across 566,845 analyzed files
The results were indeed interesting. Notably, the maximum number of defensive coding blocks within a single file reached 14,764. This was clearly generated during the REST API-to-MCP conversion. In fact, defensive coding numbers were significantly fewer in most cases. When we set our AI indicator to more than 10 try-catch blocks within a single source file, we got 6,109 files across 1,586 repositories—8.3% of all analyzed repositories. Meanwhile, more than one section divider was found in 1,462 repositories. These two indicators (high try-catch block counts and section dividers) are consistent with the 8.3% bot activity figure found in the repository metadata.
When we lowered the threshold to five try-catch blocks, we got 16,686 files within 3,602 repositories (approximately 19%).
Upon examining emoji-based indicators, we found more than one emoji in 35,689 files across 6,893 repositories. When we narrowed our search to only the source code files (discarding .md files), we found emojis in 17,734 source code files across 3,662 repositories (19.3%).
This trend was further supported by other indicators we added:
- Repositories with decorative boxes: 4,485 (23.6%)
- Repositories with unused imports: 9,550 (50.3%)
These findings reflect a consistent trend. While no single indicator or trait is definitive on its own, the convergence of these indicators across repositories led us to a conservative estimate that AI code generation has been used in at least 20% of MCP server repositories.
Hunting the vulnerabilities
Due to the large number of open-source MCP server repositories, it became clear that manually analyzing every repository within a reasonable timeframe would not be possible. Fortunately, advances in large language models (LLMs) and derived agentic systems have given us a unique opportunity to conduct not only our MCP vulnerability research but also AI research alongside it.
For this research, we completed a three-stage, Gemini-powered static analysis of the MCP server source code to identify vulnerabilities.
In the first stage, we had our agent analyze the source code and look for all possible vulnerabilities. Our AI agent found 17,558 vulnerabilities. We could not take this at face value, so we randomly picked several reports to further examine and evaluate the results. In all cases, we observed the well-documented tendency of LLMs towards sycophancy, providing results and responses that align with user expectations rather than objective analysis, flagging every potential issue as a vulnerability, even when we explicitly included instructions in the prompt not to do so.
These findings raised further questions: What about using a different prompt or model? Can we improve the result using a lower temperature setting?
In the second stage, we altered the prompt and asked the same LLM for a critical assessment to remove hallucinations, unproven potential cases, and instructions the LLM disregarded in the first stage.
The second stage reported over 15,000 vulnerabilities, but we remained skeptical. Reviewing the reports, we realized that although our scanning agent detected many vulnerabilities, not all of them were necessarily recognized by the security community. For example, exploiting some of these vulnerabilities would already require direct access to the server environment, which would itself present a more significant security issue, as it implies the linked data source is already accessible without needing to exploit the MCP server.
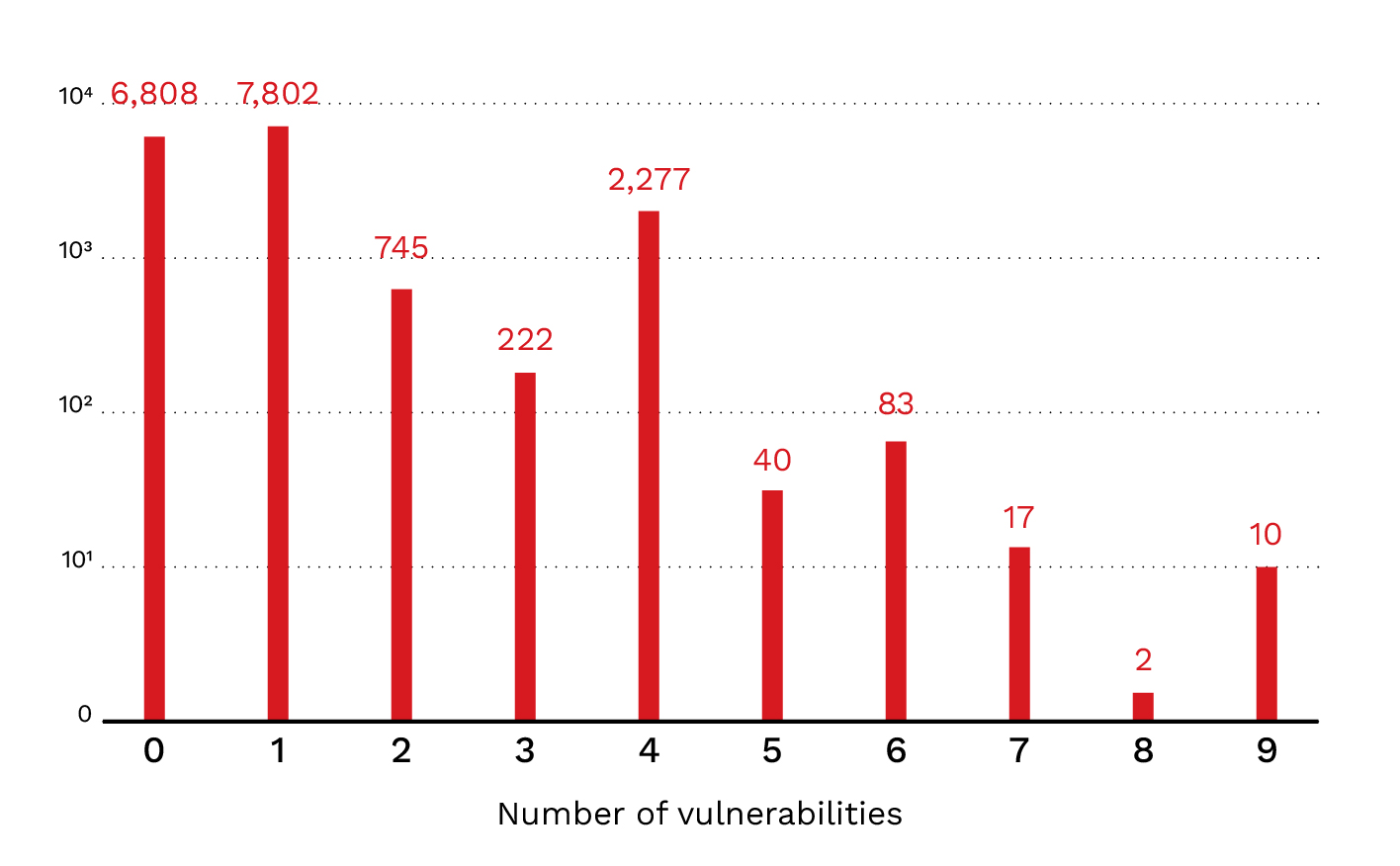
Figure 5. The distribution of identified vulnerabilities across stage 2 repositories
In the third stage, we randomly selected 2,287 vulnerabilities from stage 2 and processed them with a Claude-powered AI agent for verification. The run also included the necessary tools to access the source code.
Given the significant gap between the 438 flagged by the agent and the 17,558 originally flagged from stage 1, we decided to manually verify the flagged vulnerabilities.
Of the 2,287 sampled candidates, the agent flagged 438 (19.1%). Manual review confirmed 93 of those as genuine, putting the agent's precision at 21.2% (95% confidence interval: 18% – 25%) and the end-to-end true-positive rate at approximately 4%.
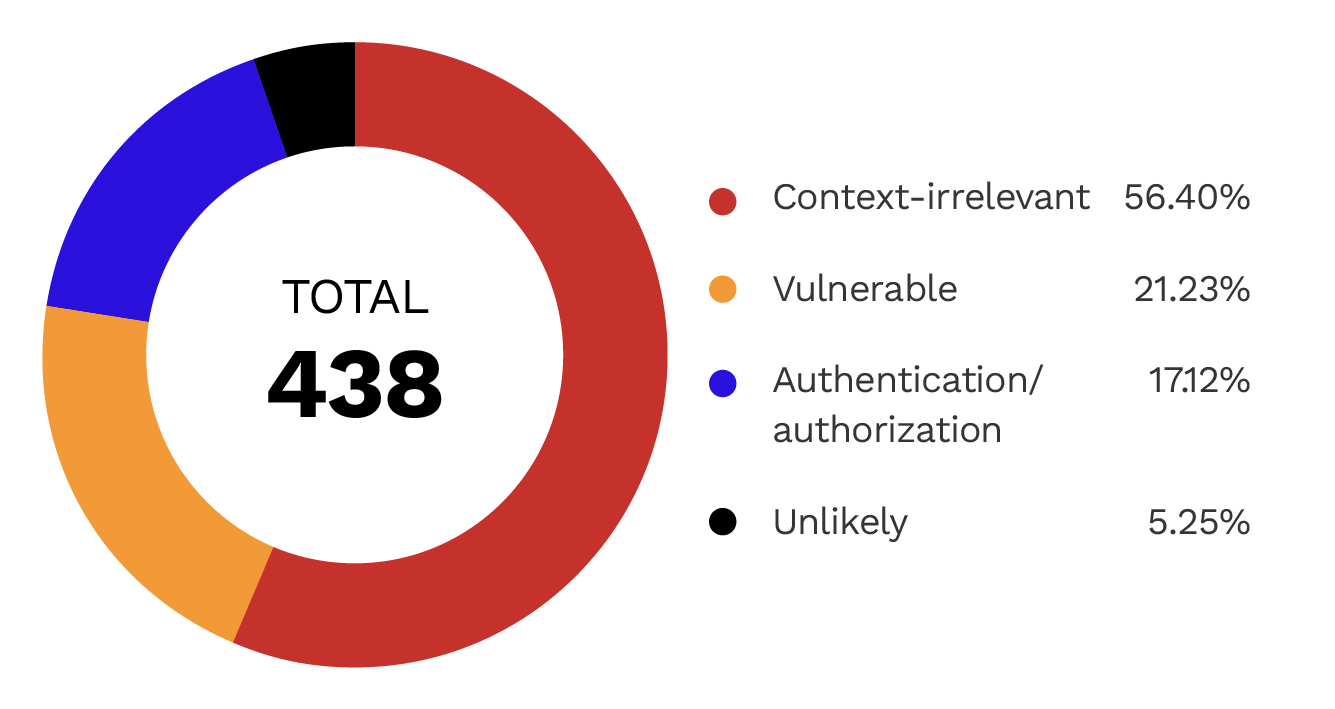
Figure 6. Manual classification of 438 AI-verified vulnerabilities, by category
First, we clarified what we do not consider a vulnerability in the MCP context. Since the majority of MCP servers are known for not implementing authentication or authorization on the server level, we did not treat this as a vulnerability. We explicitly instructed our agent to ignore these, though notably, the instruction was disregarded in 17% of instances.
As shown in Figure 6, the context-irrelevant category represents the highest occurrence at 56.4%—cases where the agent flagged a vulnerability without accounting for the broader context of the code. The simplest explanation for context-irrelevant findings is logical inconsistency. In some cases, the agent identified SQL injection, allowing write operations on a linked database without considering that those operations were already permitted elsewhere in the code. In others, it flagged vulnerabilities in standard input/output (stdio) MCP servers where direct server interaction represents a more significant security problem.
Complicating this further, inclusion in the context-irrelevant category does not guarantee that a vulnerability cannot be exploited, as RCE-type issues account for 17% of findings in this category.
In scenarios where an LLM API call is redirected to a malicious endpoint controlled by a threat actor—for example, by exploiting a vulnerability or misconfiguration on the LLM proxy—the attacker can gain access to the user’s machine or even the wider private network (Figure 7).
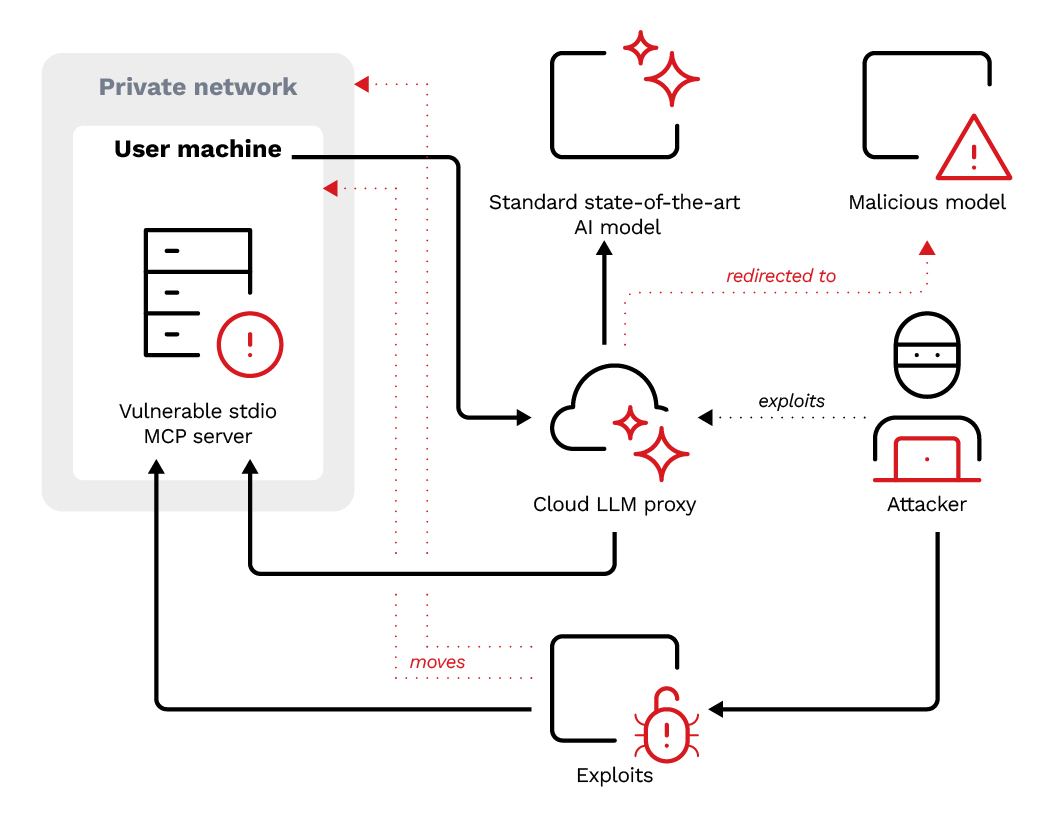
Figure 7. An attack scenario in which a threat actor exploits a misconfigured cloud LLM proxy to redirect API calls to a malicious model, then leverages a vulnerable stdio MCP server to move laterally within the user's private network
Figure 6 shows that the unlikely category (approximately 5.3%) refers to vulnerabilities that exist, but are highly unlikely to be exploited.
Lastly, 93 cases (21.2%) were confirmed as genuinely exploitable vulnerabilities. SQL injection was the most common type, accounting for 26% of vulnerabilities, stemming from failed SQL protection mechanisms in MCP servers. Remote code execution (RCE) was the second most common type, accounting for 22.5% of vulnerabilities. These vulnerabilities are often triggered by command-line injection in a wrapper around a well-known command-line utility. Path traversal vulnerabilities ranked third at 19%. These vulnerabilities allow arbitrary read or write access to files outside the intended directory, potentially exposing data or enabling unauthorized changes to the server.
The presence of authentication bypass vulnerabilities (7.5%) indicated that even when the authentication features were present in an MCP server, they were not necessarily implemented correctly. Figure 8 presents the full breakdown of confirmed vulnerability types.
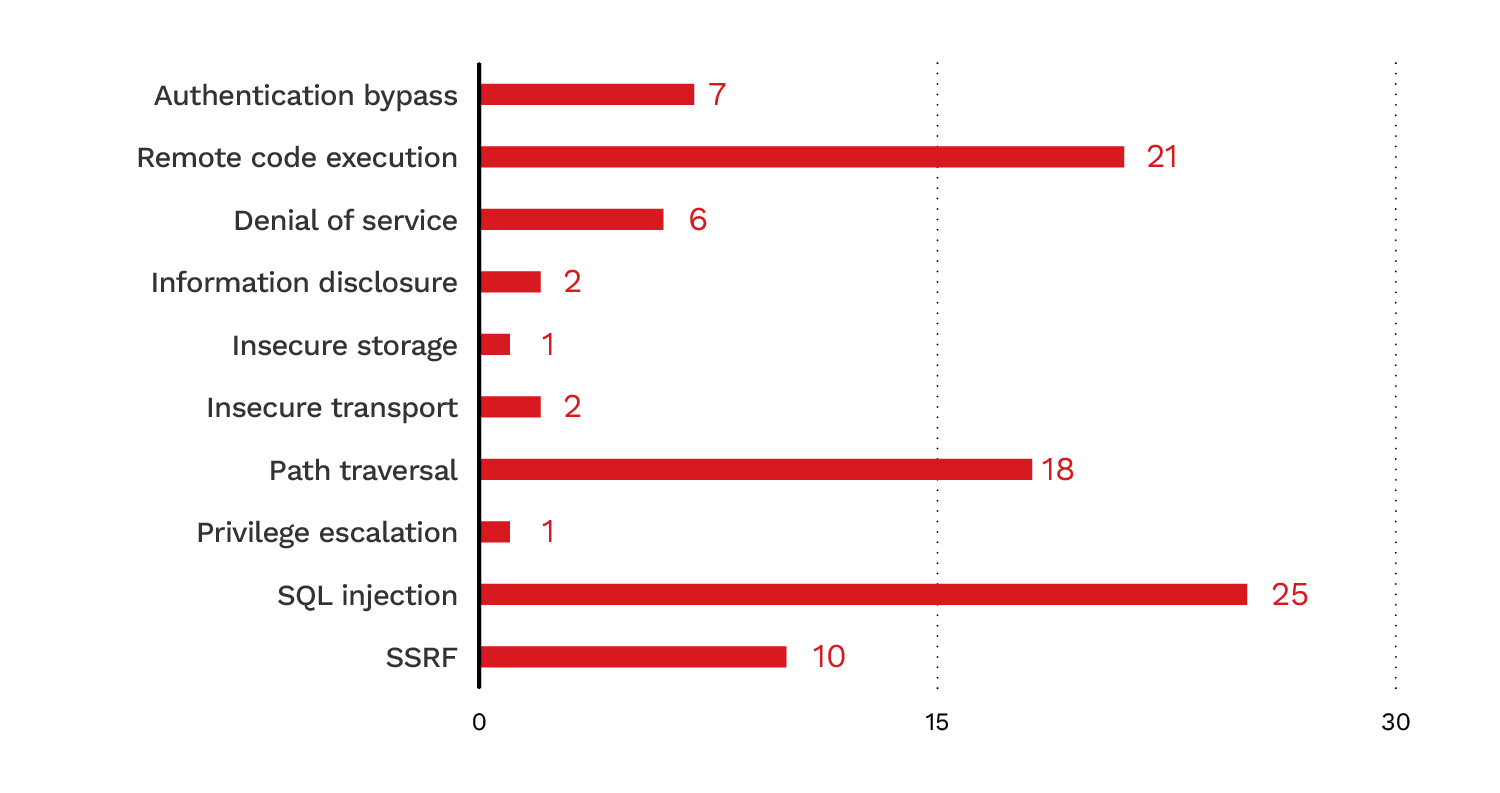
Figure 8. The breakdown of exploitable vulnerability types across 93 confirmed cases
The data confirms our earlier findings and the need for additional isolation mechanisms. For instance, container file system isolation helps mitigate path traversal vulnerability exploitation, while network firewall rules and intrusion prevention systems (IPS) prevent server-side request forgery (SSRF) exploitation. Authentication bypasses and SQL injection call for an external authentication mechanism and fine-grained role-based access control (RBAC) instead of relying on built-in MCP server protections.
A key question remains: how many of these vulnerable repositories have signs of AI usage? Metadata analysis identified AI bot activity in 3% of exploitable repositories. However, our source-code trait analysis tells a strikingly different story—42.6% of repositories that were manually classified as having exploitable vulnerabilities show signs of AI code generation.
| Total events | AI bot events | AI bot % | |
| chromewillow/repo-to-txt-mcp | 33 | 3 | 9.09% |
| ahujasid/blender-mcp | 13,936 | 5 | 0.04% |
| weibaohui/kom | 887 | 0 | 0% |
| dremio/dremio-mcp | 279 | 0 | 0% |
| rulego/rulego-server | 194 | 0 | 0% |
| MiniMax-AI/MiniMax-MCP-JS | 166 | 0 | 0% |
| feiskyer/mcp-kubernetes-server | 159 | 0 | 0% |
Table 2. The top seven repositories containing exploitable vulnerabilities by total events, with only two showing confirmed AI bot activity — representing 3% of the 68 repositories analyzed
Conclusion
How many open-source MCP servers are vulnerable?
Based on our research data, we estimate that the number of exploitable vulnerabilities across the 19,000 repositories lies between 600 and 1,650, with a point estimate near 770 (≈4% of repositories).
Here is how we arrived at these figures. From the full dataset, we randomly sampled 2,287 agent-flagged candidates. A stricter second agent retained 438 (19.1%), and manual review confirmed 93 of those as genuinely exploitable—a confirmation rate of 21.2%. Extrapolating this 4.1% prevalence (93 out of 2,287) across 19,000 repositories gives the point estimate of approximately 770.
The range reflects three sources of uncertainty:
- Sampling variance alone accounts for the floor of our uncertainty. With 93 confirmed positives out of 2,287, the 95% confidence interval translates to 630 – 940 vulnerabilities at the population level—what we would get even with a perfect classifier and a perfect-recall agent.
- Manual reviewers can err in both directions on borderline cases. Treating bidirectional human error at approximately 5% shifts the confirmed-positive count by about ±10%, modestly widening the confidence interval in both directions.
- The second agent discarded 1,849 candidates before manual review ever reached them. We did not directly measure how many of those discards were genuinely exploitable. Assuming the agent's recall lies between 60% and 100%, the true count scales upward by a factor of up to 1.67 times—the dominant contributor to the upper end of the range.
The point estimate (~770) assumes near-perfect agent recall and unbiased manual review. The upper end (~1,650) corresponds to the scenario where the agent missed approximately 40% of true exploitable vulnerabilities and reviewers slightly under-counted. The lower end (~600) corresponds to sampling variance combined with slight reviewer over-counting.
These results confirm that not all AI-identified vulnerabilities are real vulnerabilities. Multistage verification reduces hallucinations or inaccurate reports; however, it is not a perfect solution. Refining prompts and defining what constitutes a vulnerability helps, yet LLMs do not always follow even well-crafted prompts, even at lower temperature settings. These findings emphasize the importance of expert domain knowledge and caution against shortcuts such as full AI delegation.
For AI-powered research, particularly in exploratory phases where the scope is not yet fully defined, it is better to start with a small random dataset, verify the results, and refine the methodology before scaling up. LLMs do not produce consistent output; carefully validate parsed results—particularly numeric fields in JSON output, which should never be taken at face value.
As our ongoing research has shown, MCP adoption is expanding the attack surface in the age of AI. These findings lend further weight to this reality, representing a snapshot of a still-evolving threat landscape that warrants continued monitoring and research.
Like it? Add this infographic to your site:
1. Click on the box below. 2. Press Ctrl+A to select all. 3. Press Ctrl+C to copy. 4. Paste the code into your page (Ctrl+V).
Image will appear the same size as you see above.
Recent Posts
- Supporting the National Cyber Strategy Part 2: How TrendAI™ Helps
- TrendAI™ 2026 Cyber Risk Report
- The Hidden Risk in Your AI Rollout: Your Endpoints
- When AI Becomes a Zero-Day Machine: What Public Sector Organizations Need to Know
- A Data-Driven View of Cyber Risk Structure: How Attack Pressure and Exposure Shape Damage
 Fault Lines in the AI Ecosystem: TrendAI™ State of AI Security Report
Fault Lines in the AI Ecosystem: TrendAI™ State of AI Security Report It’s By Design: The Use-After-Free of Azure Cloud
It’s By Design: The Use-After-Free of Azure Cloud TrendAI™ 2026 Cyber Risk Report
TrendAI™ 2026 Cyber Risk Report Guarding LLMs With a Layered Prompt Injection Representation
Guarding LLMs With a Layered Prompt Injection Representation