O que é Machine Learning?
Uma forma de inteligência artificial (IA) que possibilita a um sistema aprender iterativamente com os dados, usando vários algoritmos para descrevê-los e prever resultados, aprendendo com os dados de treinamento que produzem modelos precisos.
Introdução ao Machine Learning
Ter computadores que descobrem o que fazer sem ser explicitamente contado cativou a imaginação por um longo tempo.
A ideia de um carro em que você pode dirigir (no assento do motorista, é claro) que fará toda a direção, identificando pedestres e buracos e respondendo de forma rápida e eficiente às mudanças no ambiente para levá-lo com segurança ao seu destino – que é o Machine Learning (ML) na prática.
Como funciona? Vamos começar analisando apenas os dados comerciais.
ML é um tipo de IA que permite que as empresas entendam e aprendam com grandes quantidades de dados. Veja, por exemplo, o Twitter. De acordo com o Internet Live Stats, os usuários do Twitter enviam aproximadamente 500 milhões de tweets todos os dias, o que equivale a aproximadamente 200 bilhões de tweets por ano. Não é humanamente possível analisar, categorizar, classificar, aprender e prever qualquer coisa com esse número de tweets.
O Machine Learning requer um trabalho considerável para que as empresas obtenham informações valiosas. Para aproveitar ao máximo o ML, você deve ter dados limpos e saber quais dúvidas você tem sobre eles. Em seguida, você pode selecionar o melhor modelo e algoritmo para beneficiar o seu negócio. ML não é um processo simples ou fácil. Seu sucesso exige um trabalho diligente.
Existe um ciclo de vida para ML:
- Entendimento. Por que você está recorrendo ao ML e o que deseja fazer ou aprender.
- Coleta e limpeza de dados. Você tem a quantidade de dados de que precisa e é tão limpa quanto necessário para fornecer os insights de que necessita.
- Seleção de recursos. Envolve determinar os dados que você precisa alimentar no ML para construir um modelo de ML. Dependendo do tipo de algoritmo usado, existem diferentes métodos disponíveis para ajudar a selecionar recursos. Por exemplo, suponha que você vá usar um algoritmo de árvore de decisão. Nesse caso, o analista ou ferramenta de modelagem pode aplicar uma “pontuação de interesse”, ou seja, colunas em um banco de dados para determinar se esses dados devem ser usados para construir seu modelo.
- Seleção de modelo. A escolha do arquivo (modelo) que foi treinado para processar e procurar certas coisas nos dados. Um modelo recebe um algoritmo para trabalhar e os dados de teste combinam os dois e desenvolvem suas conclusões.
- Treinamento e ajuste. As conclusões que o modelo encontrou para garantir que obterá respostas às suas perguntas.
- Avaliação do modelo e algoritmo para determinar se ele está pronto para uso ou se você precisa voltar algumas etapas e refinar seu modelo, recurso, algoritmo ou dados para atingir seus objetivos.
- Implantação do modelo treinado em produção.
- Revisão da saída do modelo existente em produção
Para que é usado o machine learning? Aplicações de Machine Learning
O Machine Learning é uma maneira de as empresas entenderem e aprenderem com seus dados. Uma empresa pode usá-lo para um grande número de subcampos. O caso de uso depende se a empresa está tentando melhorar as vendas, fornecer um recurso de pesquisa, integrar comandos de voz em seu produto ou criar um carro autônomo.
Subcampos de Machine Learning
O ML tem uma variedade fantástica de usos nos negócios de hoje e só pode aumentar e melhorar com o tempo. Os subcampos da IA incluem redes sociais e recomendações de produtos, reconhecimento de imagens, diagnóstico de saúde, tradução de idiomas, reconhecimento de fala e mineração de dados, para citar alguns.
Plataformas de mídia social, como Facebook, Instagram ou LinkedIn usam ML para sugerir páginas para seguir ou grupos para ingressar com base nas postagens que você gosta. Ele pega dados históricos do que outras pessoas gostaram ou quais postagens são semelhantes ao que você gostou, faz essas sugestões para você ou as adiciona ao seu feed.
Também é possível usar o ML em um site de comércio eletrônico para fazer recomendações de produtos com base em compras anteriores, suas pesquisas e ações de outros usuários semelhantes às suas.
Um uso significativo do ML hoje é para reconhecimento de imagem. As plataformas de mídia social recomendam marcar pessoas em suas fotos com base em ML. A polícia tem conseguido usá-lo, procurando suspeitos em fotos ou vídeos. Com a abundância de câmeras instaladas em aeroportos, lojas e campainhas, é possível saber quem cometeu um crime ou para onde o criminoso foi.
Os diagnósticos de saúde também são um bom uso do ML. Depois de um evento como um ataque cardíaco, é possível voltar e ver os sinais de alerta que foram esquecidos. Um sistema usado por médicos ou hospitais pode ser alimentado com registros médicos do passado e aprender a ver as conexões da entrada (comportamento, resultado de teste ou sintoma) para a saída (por exemplo, um ataque cardíaco). Então, quando o médico colocar suas anotações e resultados de testes no sistema no futuro, a máquina poderá detectar os sintomas de ataque cardíaco de forma muito mais confiável do que os humanos, de modo que o paciente e o médico possam fazer alterações para evitá-lo.
A tradução de idiomas em páginas da web ou aplicativos para plataformas móveis é outro exemplo de ML. Alguns aplicativos fazem um trabalho melhor do que outros, o que se resume ao modelo, técnica e algoritmos de ML que utilizam.
Hoje em dia, o ML é usado diariamente em cartões bancários e de crédito. Existem sinais de fraude que o ML pode detectar rapidamente e que levaria muito tempo para os humanos descobrirem. A abundância de transações que foram examinadas e rotuladas (fraude ou não) pode permitir que o ML aprenda a identificar fraudes em uma única transação no futuro. ML que é excelente para isso é a mineração de dados.
Mineração de dados
Mineração de dados é um tipo de ML que analisa dados para fazer previsões ou descobrir padrões em big data. O termo é um pouco enganador, pois não exige que ninguém, seja um agente malicioso ou funcionário, vasculhe seus dados para encontrar um dado que seja útil. Em vez disso, o processo envolve a descoberta de padrões em dados úteis para a tomada de decisões no futuro.
Considere, por exemplo, uma empresa de cartão de crédito. Se você tiver um cartão de crédito, seu banco provavelmente o notificou sobre uma atividade suspeita em seu cartão em algum momento. Como o banco identifica tal atividade tão rapidamente, enviando um alerta quase instantâneo? É a mineração contínua de dados que permite essa proteção contra fraudes. No início de 2020, havia mais de 1,1 trilhão de cartões emitidos apenas nos EUA. O número de transações desses cartões produz diversos dados para mineração, pesquisas de padrões e aprendizagem para identificar transações suspeitas no futuro.
Deep learning
Deep learning é um tipo específico de ML baseado em redes neurais. Uma rede neural funciona para emular como os neurônios em um cérebro humano funcionam para tomar uma decisão ou entender algo. Por exemplo, uma criança de seis anos pode olhar para um rosto e distinguir sua mãe do guarda de trânsito porque o cérebro analisa muitos detalhes rapidamente – cor do cabelo, características faciais, cicatrizes, etc. - tudo em um piscar de olhos. O machine learning replica isso na forma de deep learning.
Uma rede neural tem de 3 a 5 camadas: uma camada de entrada, uma a três camadas ocultas e uma camada de saída. Os ocultos tomam as decisões para trabalhar em direção à camada de saída ou a conclusão, um por um. Qual a cor do cabelo? Qual a cor dos olhos? Existe uma cicatriz? À medida que as camadas aumentam para centenas, isso é chamado deep learning.
Tipos de Machine Learning
Existem basicamente 4 tipos de algoritmos de machine learning: supervisionado, semi-supervisionado, não supervisionado e reforçado. Os especialistas em ML acreditam que aproximadamente 70% dos algoritmos de ML em uso hoje são supervisionados. Eles trabalham com conjuntos de dados conhecidos ou rotulados – por exemplo, fotos de cães e gatos. Os dois tipos de animais são conhecidos, portanto os administradores podem rotular as imagens antes de entregá-las ao algoritmo.
Algoritmos de ML não supervisionados aprendem com conjuntos de dados desconhecidos. Veja, por exemplo, os vídeos do TikTok. Existem tantos vídeos com tantos tópicos que é impossível treinar um algoritmo a partir deles de forma supervisionada; os dados ainda não estão rotulados.
Os algoritmos de ML semi-supervisionados são inicialmente treinados com um pequeno conjunto de dados que é conhecido e rotulado. Em seguida, ele é aplicado a um conjunto de dados não rotulado maior para continuar seu treinamento.
Algoritmos de ML reforçados não são treinados inicialmente. Eles aprendem com a tentativa e erro em movimento. Pense em um robô que está aprendendo a navegar em uma pilha de pedras. Cada vez que ele cai, ele aprende o que não funciona e altera seu comportamento até ter sucesso. Pense no treinamento do cão e no uso de guloseimas para ensinar vários comandos. Com o reforço positivo, o cão continuará a executar os comandos e a mudar o comportamento que não retorna uma resposta favorável.
Machine Learnig supervisionado x não supervisionado
Machine Learning supervisionado
Ele usa conjuntos de dados conhecidos, estabelecidos e classificados para encontrar padrões. Vamos expandir a ideia anterior das fotos de cães e gatos. Você poderia ter um enorme conjunto de dados cheio de milhares de animais diferentes mantidos dentro de milhões de fotos. Como os tipos de animais são conhecidos, eles poderiam ter sido agrupados e rotulados antes de serem entregues ao algoritmo de ML supervisionado para que ele aprendesse a entender.
O algoritmo supervisionado agora compara a entrada com a saída e a imagem com o rótulo do tipo de animal. Com o tempo, ele aprenderá a reconhecer um certo tipo de animal nas novas fotos que encontrar.
Machine Learning não supervisionado
Algoritmos de ML não supervisionados são como filtros de SPAM hoje. Inicialmente, os administradores podem programar filtros de SPAM para procurar palavras específicas no e-mail para entender o SPAM. Isso não é mais possível, portanto, não supervisionado funciona bem aqui. O algoritmo de ML não supervisionado é alimentado por e-mails que não foram marcados para começar a procurar padrões. À medida que esses padrões são encontrados, ele aprenderá como é o SPAM e o identificará no ambiente de produção.
Técnicas de machine learning
As técnicas de ML resolvem problemas. Dependendo do problema que você enfrenta, você escolhe uma técnica de ML específica. Aqui estão 6 comuns.
A técnica de regressão
A regressão pode ser usada para prever os preços do mercado interno ou determinar o preço de venda ideal de uma pá de neve em Minnesota em dezembro. A regressão diz que mesmo que os preços flutuem, eles sempre retornarão ao preço médio, embora com o tempo os preços das casas estejam subindo, há uma média que sempre voltará a ocorrer. Você pode traçar os preços ao longo do tempo em um gráfico e encontrar a média conforme o tempo passa. Conforme a linha vermelha continua subindo no gráfico, ela permite as previsões futuras.
Classificação
A classificação é usada para agrupar dados em categorias conhecidas. Você pode estar procurando clientes que são previsivelmente bons clientes (eles sempre voltam e gastam mais dinheiro) ou que, previsivelmente, começarão a comprar em outro lugar. Se você puder olhar para trás no tempo e encontrar preditores para cada classificação de clientes, você aplicará isso aos clientes atuais e preverá em qual grupo eles se encaixarão. Assim, você poderá comercializar com mais eficácia e, possivelmente, converter o cliente que sairá potencialmente em um excelente cliente recorrente. Este é um bom exemplo de BC supervisionado.
Clustering
Ao contrário da técnica de classificação, o agrupamento é ML não supervisionado. No armazenamento em cluster, o sistema descobrirá como agrupar dados que você não sabe agrupar. Este tipo de ML é excelente para analisar imagens médicas, analisar redes sociais ou procurar anomalias.
O Google usa clustering para generalização, compressão de dados e preservação de privacidade em produtos, como vídeos do YouTube, Play apps e faixas de música.
Detecção de anomalia
A detecção de anomalias é usada quando você está procurando por valores discrepantes, como detectar a ovelha negra em um rebanho. Ao olhar para uma grande quantidade de dados, essas anomalias são impossíveis de serem encontradas pelos humanos. Mas, por exemplo, se um cientista de dados alimentasse um sistema com dados de faturamento médico de muitos hospitais, a detecção de anomalias encontraria uma maneira de agrupar o faturamento. Ele pode descobrir um conjunto de outliers que acaba sendo o local onde ocorre a fraude.
Análise de cesta de compras
A lógica da análise da cesta de compras permite previsões futuras. Um exemplo simples – se os clientes colocassem carne moída, tomate e tacos em sua cesta, você poderia prever que eles adicionariam queijo e creme de leite. Essas previsões podem ser usadas para gerar vendas extras, fazendo sugestões valiosas para os compradores online de itens que eles teriam esquecido ou para ajudar a agrupar produtos em uma loja.
Dois professores do MIT usaram essa abordagem para descobrir o "precursor do fracasso". Acontece que alguns clientes gostam de produtos que falham. Se você puder identificá-los, poderá determinar se continuará a vender um produto e que tipo de marketing aplicar para aumentar as vendas dos clientes certos.
Dados de série temporal
Os dados de séries temporais são comumente coletados sobre muitos de nós com monitores de condicionamento físico em nossos pulsos. Ele pode coletar batimentos cardíacos por minuto, quantos passos por minuto ou hora damos e alguns agora até medem a saturação de oxigênio ao longo do tempo. Com esses dados, seria possível prever quando alguém fugirá no futuro. Também seria possível coletar dados sobre máquinas e prever falhas por causa dos dados baseados no tempo sobre o nível de vibração, nível de ruído em dB e pressão.
Algoritmos de machine learning
Se o ML deve aprender com os dados, como você projeta um algoritmo para aprender e encontrar os dados estatisticamente significativos? Os algoritmos de ML suportam o processo de ML supervisionado, não supervisionado ou de reforço.
Os engenheiros de dados escrevem trechos de código que são os algoritmos que permitem que uma máquina aprenda ou encontre significado nos dados.
Vejamos alguns algoritmos específicos que são os mais comuns. Aqui estão os 5 primeiros em uso hoje.
- Os algoritmos de regressão linear estabelecem uma relação ajustando variáveis independentes e dependentes a um gráfico e traçando uma linha reta para a média ou tendência. Merriam-Webster define regressão como "uma função que produz o valor médio de uma variável aleatória sob a condição de que uma ou mais variáveis independentes tenham valores especificados." Essa definição também se aplica à regressão logística.
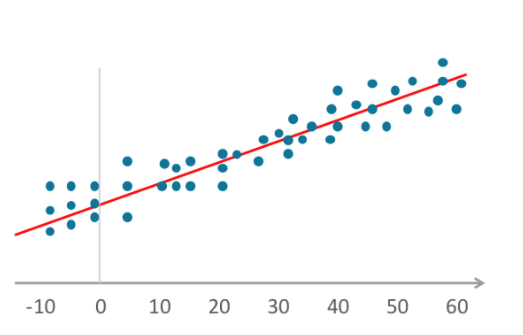
- A regressão logística (também conhecida como logit) também ajusta variáveis a um gráfico, assim como a regressão linear, mas a linha não é linear. A linha aqui é uma função sigmóide.
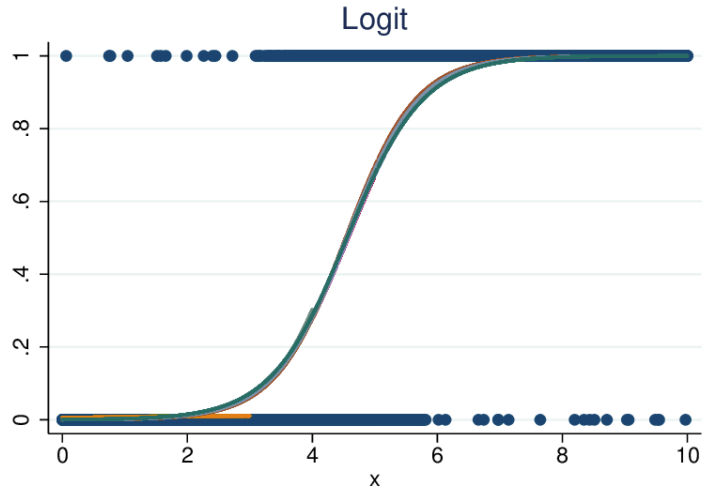
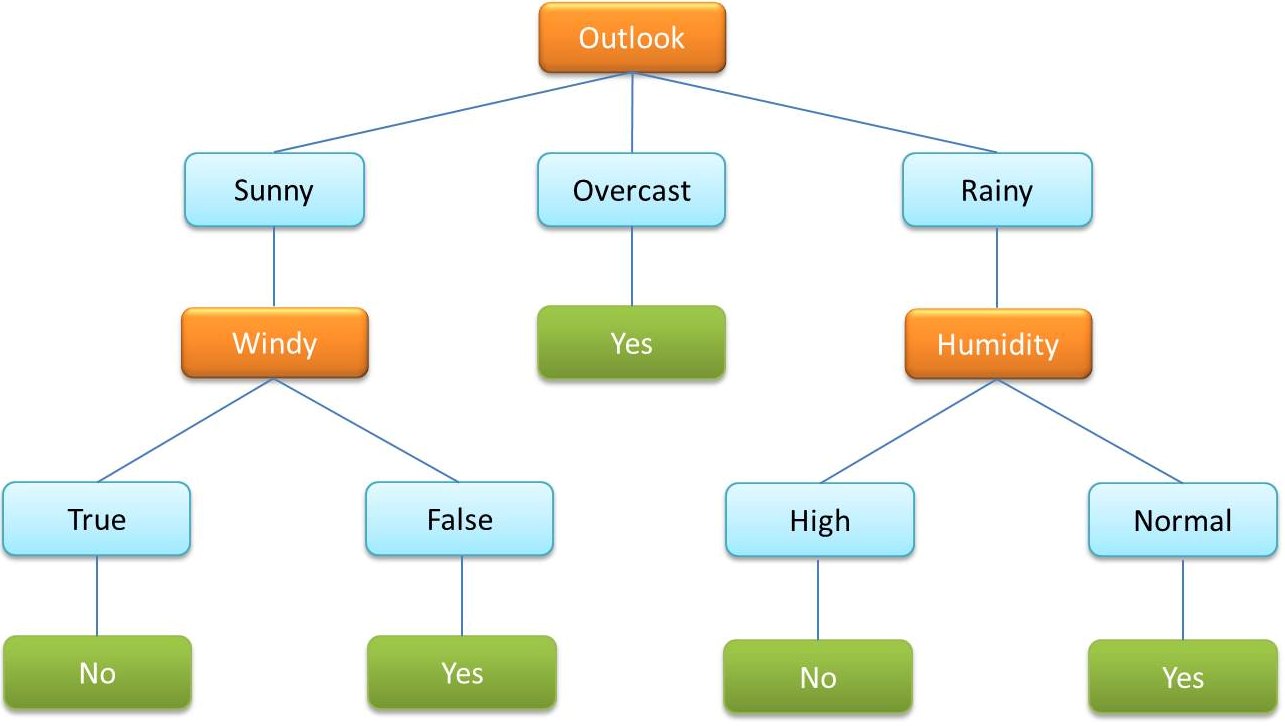
- Uma árvore de decisão é um algoritmo muito comumente usado em ML supervisionado. É usado para classificar dados por variáveis categóricas e contínuas.
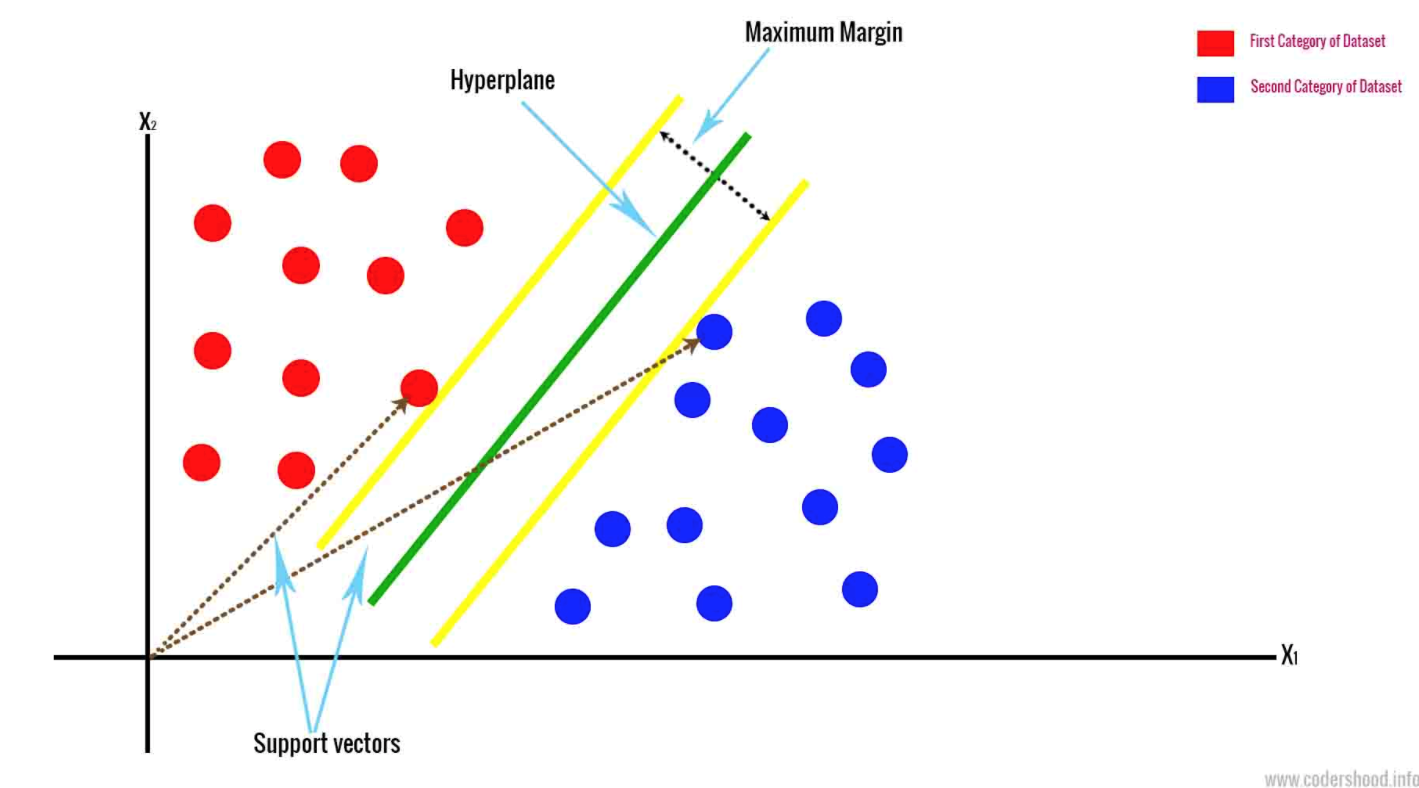
- Support Vector Machine desenha um hiperplano com base nos dois pontos de dados mais próximos. Isso separa os dados marginalizando as classes. Ele classifica os dados com base em um espaço n-dimensional. N representa o número de recursos diferentes que você possui.
- Naïve Bayes calcula a probabilidade de um determinado resultado. É muito eficaz e supera modelos de classificação mais sofisticados. Um modelo classificador Naïve Bayesiano entenderá que qualquer característica dada não está relacionada à presença de outras características particulares.
Modelos de Machine Learning
Depois de combinar o tipo de ML (supervisionado, não supervisionado, etc.), as técnicas e os algoritmos, o resultado é um arquivo que foi treinado. Esse arquivo agora pode receber novos dados e será capaz de reconhecer os padrões e fazer previsões ou decisões para a empresa, o gerente ou o cliente, conforme necessário.
Melhores linguagens para machine learning
As linguagens de machine learning são como as instruções são escritas para o sistema aprender. Cada idioma tem uma comunidade de usuários para oferecer suporte para aprender ou orientar outras pessoas. Existem bibliotecas incluídas em cada linguagem para uso de machine learning.
Aqui estão os 10 principais de acordo com a pesquisa dos 10 principais do GitHub em 2019.
- Python
- C++
- JavaScript
- Java
- C#
- Julia
- Shell
- R
- TypeScript
- Scala - uma linguagem que está sendo usada para interações com big data
Machine Learning Python
Como Python é a linguagem de ML mais comum, aqui está mais especificamente.
Python é uma linguagem interpretada, de código-aberto e orientada-a-objetos que leva o nome de Monty Python. Por ser interpretado, ele é convertido em bytecode antes de ser executável por uma máquina virtual Python.
Há uma variedade de recursos que tornam o Python a escolha preferida para ML.
- Um grande conjunto de pacotes poderosos que estão disponíveis para uso agora. Existem pacotes de ML específicos, como numpy, scipy e panda.
- Fácil e rápido de prototipar.
- Existem várias ferramentas que permitem a colaboração.
- À medida que um cientista de dados vai da extração à modelagem e à atualização da solução de ML, o Python pode continuar a ser a linguagem de escolha. O cientista de dados não precisa alterar os idiomas durante o ciclo de vida.
Recursos