
Una forma di intelligenza artificiale (IA) che consente ai sistemi di apprendere gli schemi dai dati e di migliorare le loro prestazioni nelle attività nel tempo senza essere esplicitamente programmati.
Sommario
Machine Learning Significato
Avere computer che capiscono cosa fare senza che gli venga detto esplicitamente è stato un desiderio irrealizzato per molto tempo.
L'idea di un'auto che possa essere utilizzata per guidare, identificare pedoni e buche e rispondere in modo rapido ed efficiente ai cambiamenti dell'ambiente per raggiungere la tua destinazione in modo sicuro, ovvero il machine learning (ML) nella pratica.
Come funziona? Iniziamo con l'analizzare solo i dati aziendali.
Il ML è un tipo di IA che consente alle aziende di dare un senso e imparare da enormi quantità di dati. Richiede un lavoro considerevole affinché le aziende ottengano informazioni preziose. Per ottenere il massimo dal machine learning, bisogna disporre di dati puliti e sapere quali domande si intende porre. A questo punto è possibile selezionare il modello e l'algoritmo migliori per la propria azienda. Il machine learning non è un processo semplice o facile. Il successo del suo impiego richiede un lavoro diligente.
In che modo il machine learning può aiutare le aziende
Il machine learning aiuta a proteggere le aziende dalle minacce informatiche. Tuttavia, funziona meglio come parte di una soluzione di sicurezza multilivello.
Il machine learning richiede alle aziende un lavoro considerevole affinché queste possano ottenere delle informazioni preziose. Per ottenere il massimo dal machine learning, bisogna disporre di dati puliti e sapere quali domande si intende porre. A questo punto è possibile selezionare il modello e l'algoritmo migliori per la propria azienda. Il machine learning non è un processo semplice o facile. Il successo del suo impiego richiede un lavoro diligente.
Esiste un ciclo di vita per il machine learning:
- Comprensione aziendale. Definire il problema, i criteri di successo e se il ML è l'approccio giusto.
- Raccolta dati e pulizia. Avere la quantità necessaria di dati, puliti in modo efficace, pronti a fornire le informazioni di cui hai bisogno.
- Selezione delle caratteristiche del dato. Il processo di scelta delle variabili di input (caratteristiche) da utilizzare nella creazione del modello. I metodi includono test statistici, regolarizzazione o misure di importanza basate su algoritmi. Ad esempio, gli alberi decisionali classificano le caratteristiche in base a criteri come il guadagno di informazioni o l'impurezza di Gini.
- Selezione del modello. Scegli un algoritmo e un tipo di modello appropriati, quindi addestralo con i tuoi dati.
- Addestramento e ottimizzazione. Adatta il modello ai dati e regola gli iperparametri per migliorare le prestazioni.
- Valutazione del modello e dell'algoritmo per determinare se è pronto per l'uso o se è necessario tornare indietro di un paio di passaggi e perfezionare il modello, la caratteristica del dato, l'algoritmo o i dati per raggiungere gli obiettivi prefissati.
- Distribuzione del modello addestrato in produzione.
- Analisi dell'output del modello esistente in produzione

Per cosa viene usato il machine learning?
Il machine learning è uno strumento che permette alle aziende di comprendere e imparare dai propri dati. Un'azienda può usarlo in un vasto numero di settori. Il caso d'uso dipende dal fatto che un'azienda stia cercando di migliorare le vendite, fornire una funzione di ricerca, integrare comandi vocali nel proprio prodotto o creare un'auto a guida autonoma.
Settori di applicazione del machine learning
Il machine learning ha una fantastica gamma di utilizzi nelle aziende di oggi e tale varietà può solo aumentare e migliorare nel tempo. I settori di applicazione del machine learning includono social media e consigli sui prodotti, riconoscimento delle immagini, diagnosi in campo medico, traduzione linguistica, riconoscimento vocale e data mining, solo per citarne alcuni.
Le piattaforme di social media, come Facebook, Instagram o LinkedIn, utilizzano il machine learning per suggerire pagine da seguire o gruppi a cui partecipare in base ai post apprezzati da uno specifico utente. Utilizza i dati storici di ciò che è piaciuto ad altri o di quali post sono simili a ciò che è piaciuto all'utente e li offre come suggerimenti o li aggiunge al suo feed.
È anche possibile utilizzare il ML su un sito di e-commerce per fornire consigli sui prodotti basati su acquisti precedenti, ricerche e azioni di altri utenti simili a quelle dell'utente.
Un altro uso significativo per il ML di oggi è il riconoscimento delle immagini. Le piattaforme di social media consigliano di taggare le persone nelle foto in base ai risultati del machine learning. La polizia ha avuto occasione di usarlo nella ricerca di sospetti in immagini o video. Con la pletora di telecamere installate in aeroporti, negozi e citofoni, è possibile capire chi ha commesso un crimine o in quale direzione è andato il criminale.
Anche le diagnosi in campo medico sono un buon campo di applicazione del ML. Dopo un evento come un infarto, è possibile tornare indietro e visualizzare eventuali segnali di allarme che sono stati trascurati. Un sistema a uso di medici o ospedali potrebbe essere alimentato da cartelle cliniche del passato e addestrato a evidenziare le connessioni tra l'input (comportamento, risultato del test o sintomo) e l'output (ad esempio, un infarto). Quindi, quando in futuro il medico inserisce i suoi appunti e i risultati dei test nel sistema, la macchina potrebbe individuare i sintomi dell'infarto in modo molto più affidabile rispetto agli umani, in modo che il paziente e il medico possano agire per prevenirlo.
La traduzione linguistica su pagine web o app per piattaforme mobili è un altro esempio di ML. Alcune app fanno un lavoro migliore di altre, il che dipende dal modello, dalla tecnica e dagli algoritmi che utilizzano.
Un uso quotidiano del ML a cui non pensiamo sempre è nelle banche e nelle carte di credito. Ci sono segnali di frode che il machine learning è in grado di rilevare rapidamente laddove agli esseri umani servirebbe molto tempo per scoprirli o addirittura passerebbero del tutto inosservati. La pletora di transazioni che sono state esaminate ed etichettate (frode o meno) può consentire al machine learning di imparare a individuare le frodi in una specifica transazione futura. La tecnica di machine learning ideale per questo scopo è il data mining.
Data mining
Il data mining è un tipo di machine learning che analizza i dati per fare previsioni o scoprire modelli all'interno dei big data. Il termine è un po' fuorviante in quanto non richiede a nessuno, che si tratti di un attore malevolo o dipendente, di rovistare nei dati per trovarne uno che sia utile. Il processo implica invece l'individuazione di schemi nei dati utili per prendere decisioni in futuro.
Prendiamo, ad esempio, una società di carte di credito. A chi ha una carta di credito, è probabilmente capitato a un certo punto di essere informato dalla banca di un'attività sospetta sulla carta. Come fa la banca a individuare tale attività così rapidamente, inviando un avviso quasi istantaneo? È il data mining continuo che consente questa protezione dalle frodi.
Deep learning
Il deep learning è un tipo specifico di machine learning basato su reti neurali. Una rete neurale funziona emulando il modo in cui i neuroni di un cervello umano funzionano per prendere una decisione o comprendere un argomento. Ad esempio, un bambino di sei anni può guardare una faccia e distinguere sua madre dall'addetto al traffico davanti alla scuola perché il cervello analizza rapidamente molti dettagli: colore dei capelli, lineamenti del viso, cicatrici, ecc., tutto in un batter d'occhio. Il machine learning replica questo processo sotto forma di deep learning.
Una rete neurale è costituita da un numero di livelli che va da 3 a 5: un livello di input, da uno a tre livelli nascosti e un livello di output. All'interno di ognuno dei livelli nascosti avvengono le decisioni che portano verso il livello di output o la conclusione. Di che colore sono i capelli? Di che colore sono gli occhi? C'è una cicatrice? Nel momento in cui i livelli aumentano fino a essere centinaia, si parla di deep learning.
Tipi di machine learning
Esistono fondamentalmente quattro tipi di algoritmi di machine learning: supervisionati, semi-supervisionati, non supervisionati e rinforzati. Gli esperti di machine learning ritengono che circa il 70% degli algoritmi di machine learning in uso oggi siano supervisionati. Funzionano con set di dati noti o etichettati, ad esempio immagini di cani e gatti. I due tipi di animali sono noti, quindi gli amministratori possono etichettare le immagini prima di sottoporle all'algoritmo.
Gli algoritmi di machine learning non supervisionati apprendono da set di dati sconosciuti. Consideriamo, ad esempio, i video di TikTok. Ci sono così tanti video con così tanti argomenti che è impossibile utilizzarli per addestrare un algoritmo in modo supervisionato. I dati non sono ancora etichettati.
Gli algoritmi di machine learning semi-supervisionati vengono inizialmente addestrati con un piccolo set di dati noto ed etichettato. Vengono quindi applicati a un set di dati non etichettati più grande per proseguire con il loro addestramento.
Gli algoritmi di machine learning con rinforzo non vengono inizialmente addestrati. Imparano per mezzo di tentativi ed errori durante il funzionamento. Pensiamo a un robot che sta imparando a navigare tra un mucchio di rocce. Ogni volta che fallisce, impara cosa non funziona e ne modifica il comportamento fino al suo successo. Pensiamo all'addestramento del cane e all'uso di dolcetti per insegnare i vari comandi. Con il rinforzo positivo, il cane continuerà a eseguire i comandi e cambierà il comportamento che non genera una risposta favorevole.
Machine learning supervisionato vs. non supervisionato
Machine learning supervisionato
Utilizza set di dati noti, stabiliti e classificati per individuare i modelli. Espandiamo l'idea precedente delle immagini di cani e gatti. Si potrebbe disporre di un enorme set di dati pieno di migliaia di animali diversi racchiusi in milioni di immagini. Poiché i tipi di animali sono noti, questi potrebbero essere stati raggruppati ed etichettati prima di sottometterli all'algoritmo di machine learning supervisionato affinché impari a capire.
L'algoritmo supervisionato ora confronta l'input con l'output e l'immagine con l'etichetta del tipo di animale. Alla fine imparerà a riconoscere un certo tipo di animale nelle nuove foto che incontra.
Machine learning senza supervisione
Gli algoritmi di machine learning non supervisionati sono usati oggi come filtri SPAM. Inizialmente, gli amministratori potevano programmare i filtri per cercare parole specifiche nell'e-mail al fine di individuare le email di SPAM. Questo non è più possibile, quindi in questo caso l'uso del machine learning non supervisionato è l’ideale. L'algoritmo di machine learning non supervisionato riceve e-mail che non sono state etichettate per iniziare a cercare modelli. Quando individua tali modelli, imparerà a individuare l'aspetto dello SPAM e lo identificherà nell'ambiente di produzione.

Tecniche di machine learning
Le tecniche di machine learning risolvono i problemi. A seconda del problema da affrontare, bisogna scegliere una tecnica di machine learning specifica. Ecco sei comuni.
La tecnica della regressione
La regressione può essere utilizzata per prevedere i prezzi del mercato immobiliare o determinare il prezzo di vendita ottimale di una pala da neve in Minnesota a dicembre. La regressione si basa sull'assunto che, anche se i prezzi oscillano, torneranno sempre al prezzo medio. Anche se nel tempo i prezzi delle case aumentano, c'è una media che si ripresenterà sempre. È possibile tracciare i prezzi nel tempo su un grafico e individuare la media mentre passa il tempo. La proiezione della linea rossa sul grafico consente le previsioni future.
Classificazione
La classificazione viene utilizzata per raggruppare i dati in categorie note. Si potrebbero voler individuare clienti che siano prevedibilmente buoni clienti (che tornano sempre e spendono più soldi) o che prevedibilmente inizieranno a fare acquisti altrove. Se riesci a guardare indietro nel tempo e a trovare i predittori per ogni classificazione dei clienti, potrai applicarli ai clienti attuali e prevedere a quale gruppo appartengono. In questo modo potrai commercializzare i tuoi prodotti in modo più efficace e possibilmente convertire il cliente che potenzialmente potrebbe diventare un ottimo cliente abituale. Questo è un buon esempio di machine learning supervisionato.
Clustering
A differenza della tecnica di classificazione, il clustering è una tecnica di machine learning non supervisionato. Nel clustering, il sistema individua il modo in cui raggruppare dati che non si sa come raggruppare. Questo tipo di machine learning è eccellente per valutare immagini mediche, analizzare social network o individuare anomalie.
Google utilizza il clustering per la generalizzazione, la compressione dei dati e la tutela della privacy in prodotti come i video di YouTube, le app di Play e i brani musicali.
Rilevazione delle anomalie
Il rilevamento delle anomalie viene utilizzato quando si cercano valori anomali, analogamente all'individuazione della pecora nera in un gregge. Quando si esamina una quantità enorme di dati, queste anomalie sono impossibili da rilevare per gli esseri umani. Ma, ad esempio, se un data scientist fornisse a un sistema i dati di fatturazione medica di molti ospedali, il rilevamento delle anomalie troverebbe un modo per raggruppare la fatturazione. Potrebbe scoprire una serie di valori anomali che si rivelano essere le occasioni in cui si verificano le frodi.
Analisi del paniere di mercato
La logica dell'analisi del paniere di mercato consente previsioni future. Un semplice esempio: se i clienti aggiungono carne macinata, pomodori e tacos al loro carrello, potresti prevedere che aggiungeranno formaggio e panna acida. Queste previsioni possono essere utilizzate per generare vendite extra offrendo preziosi suggerimenti agli acquirenti online per gli articoli che potrebbero dimenticare o per aiutare a raggruppare i prodotti in un negozio.
Due professori del MIT hanno usato questo approccio per scoprire i "precursori del fallimento". A quanto pare, ad alcuni clienti piacciono i prodotti che non hanno successo. Se si riesce a individuarli, è possibile determinare se continuare a vendere un prodotto e che tipo di azioni di marketing attuare per aumentare le vendite verso i clienti giusti.
Dati di serie temporali
Molti di noi raccolgono serie temporali di dati attraverso i sensori per il fitness indossati al polso. Questi possono raccogliere informazioni sui battiti cardiaci al minuto, sui passi al minuto o all'ora effettuati e ora alcuni misurano persino la saturazione di ossigeno nel corso del tempo. Con questi dati, potrebbe essere possibile prevedere quando una persona correrà in futuro. Potrebbe anche essere possibile raccogliere dati sui macchinari e prevedere i guasti grazie ai dati legati al tempo relativi a livello di vibrazione, livello di rumore in dB e pressione.
Algoritmi di machine learning
Se si suppone che il machine learning impari dai dati, come si progetta un algoritmo per l'apprendimento e la ricerca di dati statisticamente significativi? Gli algoritmi di machine learning supportano il processo di machine learning supervisionato, non supervisionato o con rinforzo.
Gli ingegneri dei dati scrivono pezzi di codice che sono gli algoritmi che consentono a una macchina di apprendere o individuare un significato nei dati.
Diamo un'occhiata ad alcuni algoritmi specifici tra i più comuni. Ecco i primi cinque in uso oggi.
- Gli algoritmi di regressione lineare stabiliscono una relazione adattando variabili indipendenti e dipendenti a un grafico e tracciando una linea retta che rappresenta la media o la tendenza. Il dizionario Merriam-Webster definisce la regressione come "una funzione che fornisce il valore medio di una variabile casuale a condizione che una o più variabili indipendenti assumano i valori specificati". Questa definizione si applica anche alla regressione logistica.
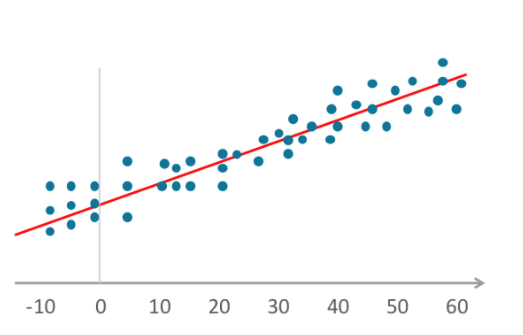
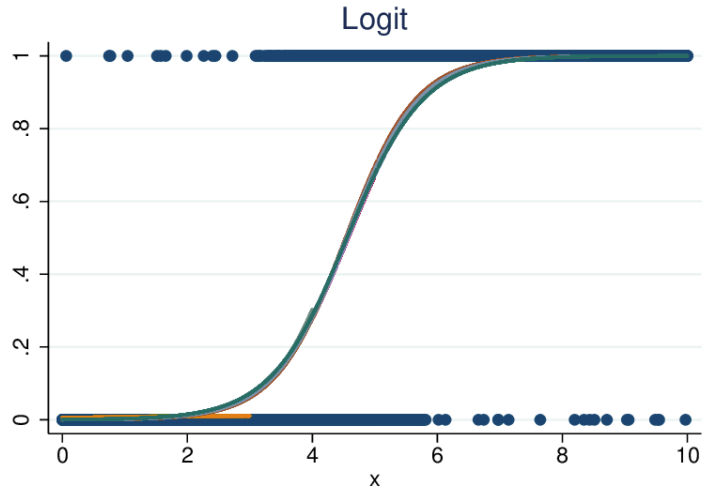
- Anche la regressione logistica (nota anche come logit) adatta le variabili a un grafico, così come la regressione lineare, ma il grafico tracciato non è lineare. La linea qui diventa una funzione sigmoidea.
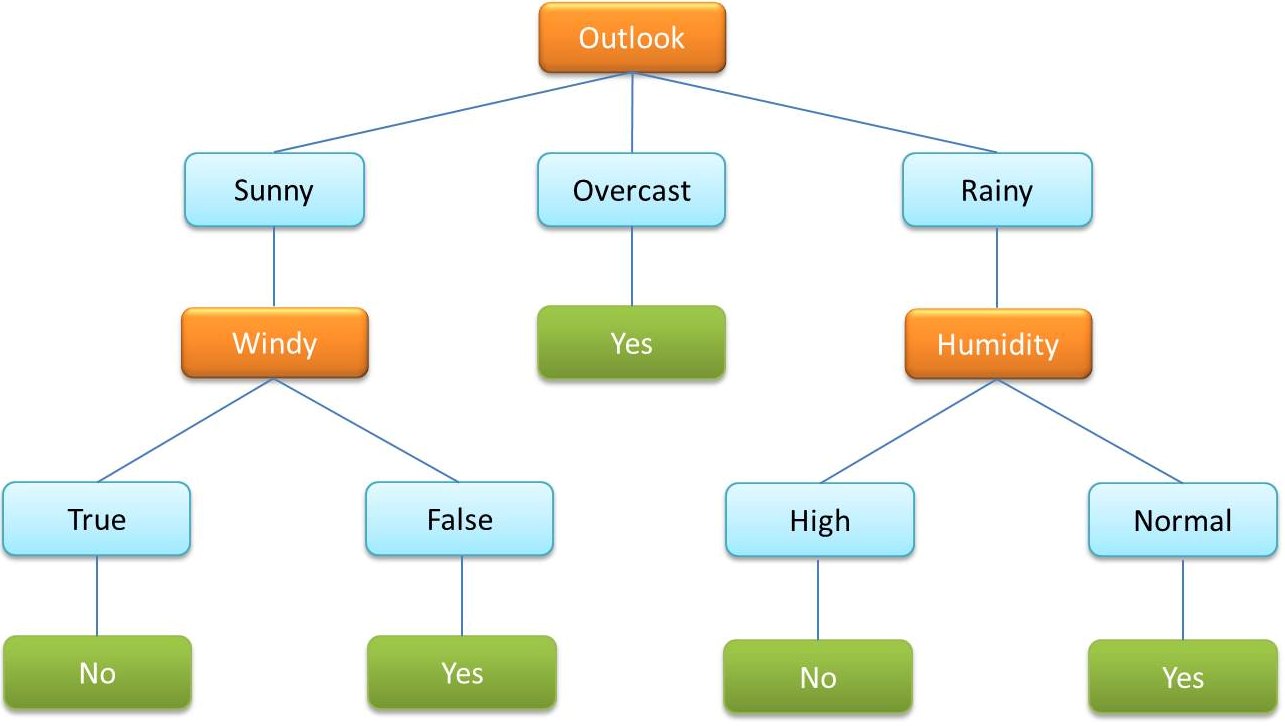
- Un albero decisionale è un algoritmo molto comunemente usato all'interno del machine learning supervisionato. Viene utilizzato per classificare i dati per variabili categoriali e continue.
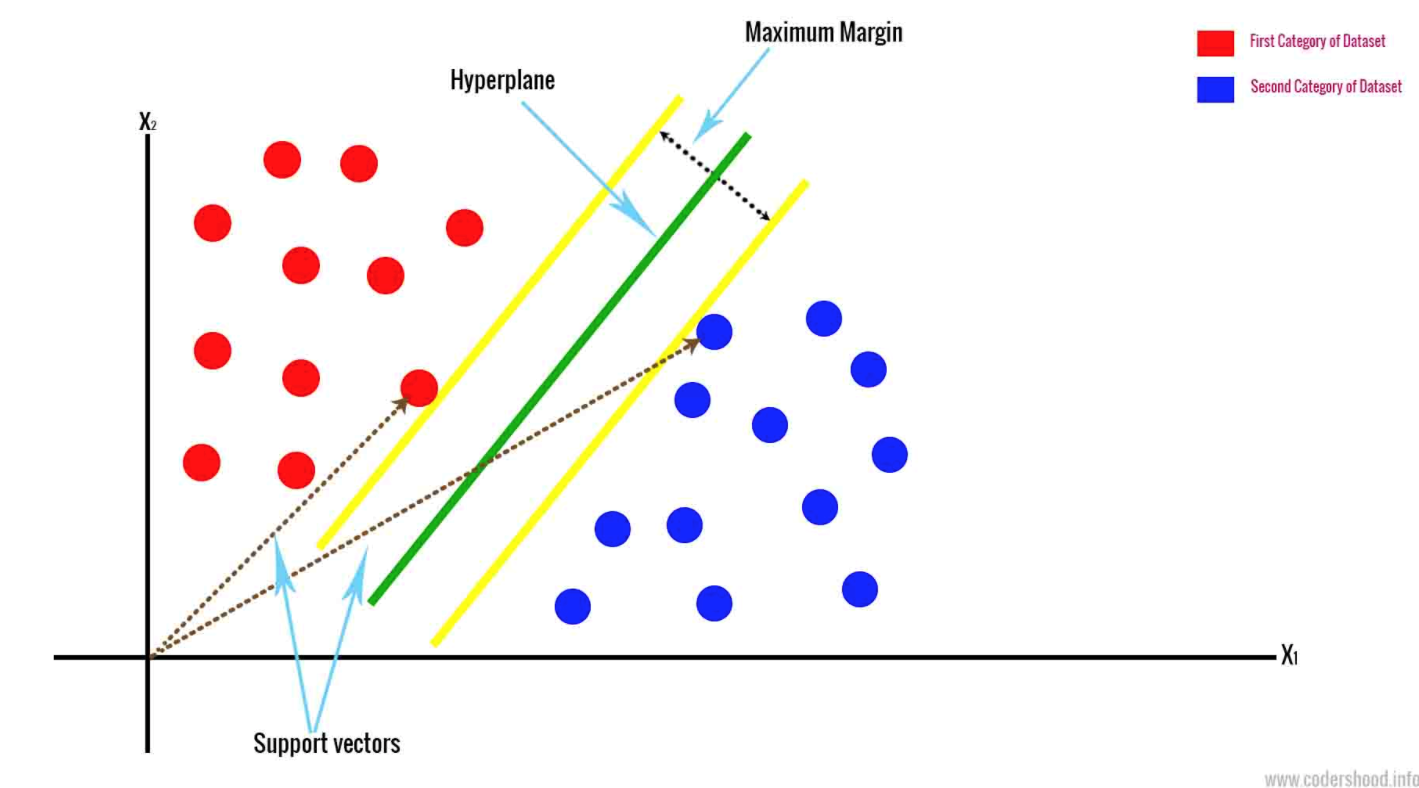
- Support Vector Machine disegna un iperpiano basato sui due punti dati più vicini. Questo separa i dati definendo le classi. Classifica i dati in base a uno spazio n-dimensionale. N rappresenta il numero di diverse caratteristiche del dato di cui si dispone.
- Naive Bayes calcola la probabilità di un particolare risultato. È molto efficace e supera i modelli di classificazione più sofisticati. Un modello di classificatore bayesiano comprenderà che una determinata caratteristica non è correlata alla presenza di altre caratteristiche particolari.
Modelli di machine learning
Dopo aver combinato il tipo di machine learning (supervisionato, non supervisionato, ecc.), le tecniche e gli algoritmi, il risultato è un file che è stato addestrato. Questo file può ora ricevere nuovi dati e sarà in grado di riconoscere i modelli e fare previsioni o prendere decisioni per l'azienda, il manager o il cliente, se necessario.
I migliori linguaggi per il machine learning
I linguaggi per il machine learning sono lo strumento con cui vengono scritte le istruzioni per l'apprendimento del sistema. Ogni linguaggio ha una comunità di utenti in grado di fungere da supporto per l'apprendimento e l'assistenza. Ogni linguaggio include librerie per l'utilizzo nel campo del machine learning.
Ecco i primi 10 secondo il sondaggio GitHub Top 10 nel 2019.
- Python
- C++
- JavaScript
- Java
- C#
- Julia
- Shell
- R
- TypeScript
- Scala: un linguaggio utilizzato per le interazioni con i big data
Machine learning con Python
Poiché Python è il linguaggio più comune per il machine learning, ecco qualche informazioni più approfondita su di esso.
Python è un linguaggio interpretato, open source e orientato agli oggetti che prende il nome dai Monty Python. Poiché è un linguaggio interpretato, viene convertito in bytecode prima di essere esguito da una macchina virtuale Python.
Ci sono una varietà di funzionalità che rendono Python la scelta ideale per il machine learning.
- Un ampio set di potenti pacchetti pronti all'uso. Esistono pacchetti specifici per il machine learning come numpy, scipy e panda.
- Prototipazione facile e veloce.
- Esistono diversi strumenti che facilitano la collaborazione.
- Python può continuare a essere il linguaggio preferito da un data scientist in tutte le fasi, dall'estrazione, alla modellazione e fino all'aggiornamento della propria soluzione di machine learning. Il data scientist non deve cambiare lingua durante il ciclo di vita.
Machine learning e cybersecurity
L'emergere del ransomware ha portato il machine learning sotto i riflettori, data la sua capacità di rilevare gli attacchi ransomware al tempo zero.
Evolution è il gioco del malware. Alcuni anni fa, gli aggressori utilizzavano lo stesso malware con lo stesso valore hash, l'impronta digitale di un malware, più volte prima di parcheggiarlo in modo permanente. Oggi, questi aggressori utilizzano alcuni tipi di malware che generano valori di hash unici frequentemente. Ad esempio, il ransomware Cerber può generare una nuova variante malware, con un nuovo valore hash ogni 15 secondi. Ciò significa che questi malware vengono utilizzati una sola volta, rendendoli estremamente difficili da rilevare utilizzando vecchie tecniche. Inserisci il machine learning. Con la capacità del machine learning di rilevare tali moduli malware in base al tipo di famiglia, è senza dubbio uno strumento di cybersecurity logico e strategico.
Gli algoritmi di machine learning sono in grado di fare previsioni accurate basate sull'esperienza precedente con programmi dannosi e minacce basate su file. Analizzando milioni di diversi tipi di rischi informatici noti, il machine learning è in grado di identificare attacchi nuovi o non classificati che condividono somiglianze con quelli noti.
Dalla previsione di nuovi malware basati su dati storici al monitoraggio efficace delle minacce per bloccarle, il machine learning dimostra la sua efficacia nell'aiutare le soluzioni di cybersecurity a rafforzare lo stato complessivo della cybersecurity.
E anche se il machine learning è diventato un importante punto di discussione nella cybersecurity di recente, è già stato uno strumento integrato nelle soluzioni di sicurezza di Trend Micro dal 2005, molto prima dell'inizio del crollo.
Dove posso ottenere aiuto per utilizzare meglio il machine learning (ML)?
Il machine learning può migliorare significativamente la capacità di una piattaforma di cybersecurity di proteggere la tua organizzazione, i tuoi dipendenti e i tuoi partner, consentendo un rilevamento e una risposta alle minacce più rapidi, intelligenti e proattivi.
Trend Vision One™ è l'unica piattaforma di cybersecurity aziendale basata sull'intelligenza artificiale che centralizza la gestione dell'esposizione al rischio informatico, le operazioni di sicurezza e una solida protezione a più livelli. Questo approccio completo ti aiuta a prevedere e prevenire le minacce, accelerando i risultati di sicurezza proattivi in tutto il tuo patrimonio digitale. Sfruttando set di dati di sicurezza su larga scala, analisi comportamentale avanzata e modelli di rilevamento delle anomalie, Trend Vision One aiuta a identificare minacce note e precedentemente non viste, compresi exploit zero-day e campagne di phishing mirate.


Joe Lee è Vice President of Product Management presso Trend Micro, dove guida la strategia globale e lo sviluppo dei prodotti per le soluzioni di sicurezza di rete e e-mail aziendali.
Domande frequenti (FAQ)
Che cos’è il Machine Learning?
Il machine learning è un tipo di IA che consente ai computer di imparare dai dati e migliorare le loro prestazioni nel tempo, senza dover essere esplicitamente programmati per ogni attività.
Qual è un esempio di machine learning?
Un esempio di machine learning sono le tecnologie di riconoscimento facciale, in cui un sistema informatico impara a riconoscere gli input visivi in modo da poter infine identificare i volti umani.
Quali sono i 4 tipi di machine learning?
I quattro principali tipi di machine learning (ML) sono l'apprendimento supervisionato, l'apprendimento non supervisionato, l'apprendimento semi-supervisionato e l'apprendimento di rinforzo.
Qual è la differenza tra IA e ML?
L'intelligenza artificiale (IA) si riferisce a sistemi progettati per simulare l'intelligenza umana. Il machine learning (ML) è un sottoinsieme di IA che trova modelli nei dati per migliorare le prestazioni del sistema.
ChatGPT è un LLM o una IA generativa?
ChatGPT è un esempio sia di LLM (large language model) che di IA generativa (GenAI).
Un chatbot è AI o ML?
I chatbot sono solitamente sviluppati utilizzando sia l'intelligenza artificiale (IA) che le tecnologie di machine learning (ML).
Che cos'è l'IA ma non il ML?
Alcuni sistemi IA non si basano sul machine learning, come i sistemi esperti basati su regole, i sistemi di ragionamento simbolico e gli algoritmi pre-programmati che seguono regole fisse.
Che cos'è meglio, IA o ML?
A seconda di ciò di cui hai bisogno, nessuno dei due è "migliore". ML è un sottoinsieme di IA che consente ai sistemi informatici di imparare dall'esperienza senza la supervisione umana.
Devo imparare prima l'IA o il ML?
Dipende dai tuoi interessi e obiettivi. Ma la maggior parte delle persone impara l'IA prima di specializzarsi in sottoinsiemi di tecnologia IA come il machine learning (ML).
Articoli correlati
I 10 principali rischi e mitigazioni per LLM e app IA generative per il 2025
Gestione dei rischi emergenti per la pubblica sicurezza
Quanto possono portarci lontano gli standard internazionali?
Come scrivere una politica di cybersecurity per l'intelligenza artificiale generativa
Attacchi dannosi potenziati dall'intelligenza artificiale tra i principali rischi
Minaccia crescente delle identità Deepfake