AWSを活用した脅威リサーチのためのデータ分析環境
公開日
2022年3月30日
こんにちは、トレンドマイクロにてデータを使った脅威リサーチをしております。東です。
トレンドマイクロでは、Trend Micro Smart Protection Network(以下SPN)という技術基盤を用い、世界中から様々な脅威情報を収集・分析しお客様の保護に活用しています。SPNは様々な脅威情報を格納するData Lakeがあり、機械学習や統計的手法を活用する場合はData Lakeから直接データを読み込み、処理を行います。トレンドマイクロでは、様々なチームがデータを活用する取り組みを行っていますが、私たちは脅威の予兆や発生している攻撃を見つけることを目的としています。本記事では、AWS上で脅威リサーチ・分析を行うためのデータ処理について紹介します。
データ活用の課題
脅威リサーチのためのデータを活用するにあたって、課題を整理します。
課題① データの中身を参照することが難しい
ビジネスインテリジェンス等における一般的なデータ分析が活用されている分野と異なる点として、敵対的な環境下でデータを分析する必要がある点が挙げられます。攻撃者は常にセキュリティ対策の回避や無効化を試みます。つまり、収集されるデータにはそういった攻撃者の振る舞いの影響を受けていることが多くあります。そのため、メトリクスや指標だけでなく、データ自体を参照しなければならないことが多いです。
一方で、私たちが調査目的で処理するデータは1日当たり500GByte~1TByte程度生成されますが、これらのデータすべてに目を通すことは不可能です。また、データの形式もCSV等であればエディタや表計算ソフトで中身を確認できますが、Apache Parquet等の列指向フォーマットのものは中身を確認するために何らかの処理が必要になります。
課題② 検索時にストレスがある
脅威リサーチではハッシュ値等のIndicator of Compromise (侵入の痕跡、以下IoC)や特徴的なキーワードを、様々なデータソースで検索します。そこで見つけた関連データを分析し、新たに見つかったIoCやキーワードに対して再度様々なデータソースで検索するという作業を繰り返すことがよくあります。データソースや検索システムにもよりますが、結果を取得するまでに数十秒から長いものでは数時間を要し、作業効率への影響が少なくありません。また後述の費用を気にせず、ある程度スムーズに検索ができることが望ましいです。
課題③ 費用が掛かる
脅威リサーチのためのデータ分析では、必ずしも目的としたものが見つかるわけではありません。また、各リサーチャーがそれぞれの経験やナレッジを基に多角的に分析できる状態が理想、つまり限られた予算内で試行回数を増やすためには、費用はできる限り抑えなければなりません。一方で、製品やサービスを提供する場合と異なり、多少の遅延は許容できると考えます。
課題④ 機微な情報の取り扱い
脅威リサーチで使用するデータには機微な情報を含むものがあります。一方で、機微な情報が含まれるためにアクセス可能な人を限定しすぎることも、多角的に分析するという点と矛盾します。誰でもアクセスできるのではなく、必要な人が必要なデータにアクセスできるようアクセスコントロールやトレースできる状態が必要です。
調査・分析環境
ストレスなくスムーズに調査や分析ができ、費用を抑え、必要な人のみが必要なデータにアクセスできる状態を目指して、環境を構築しました。
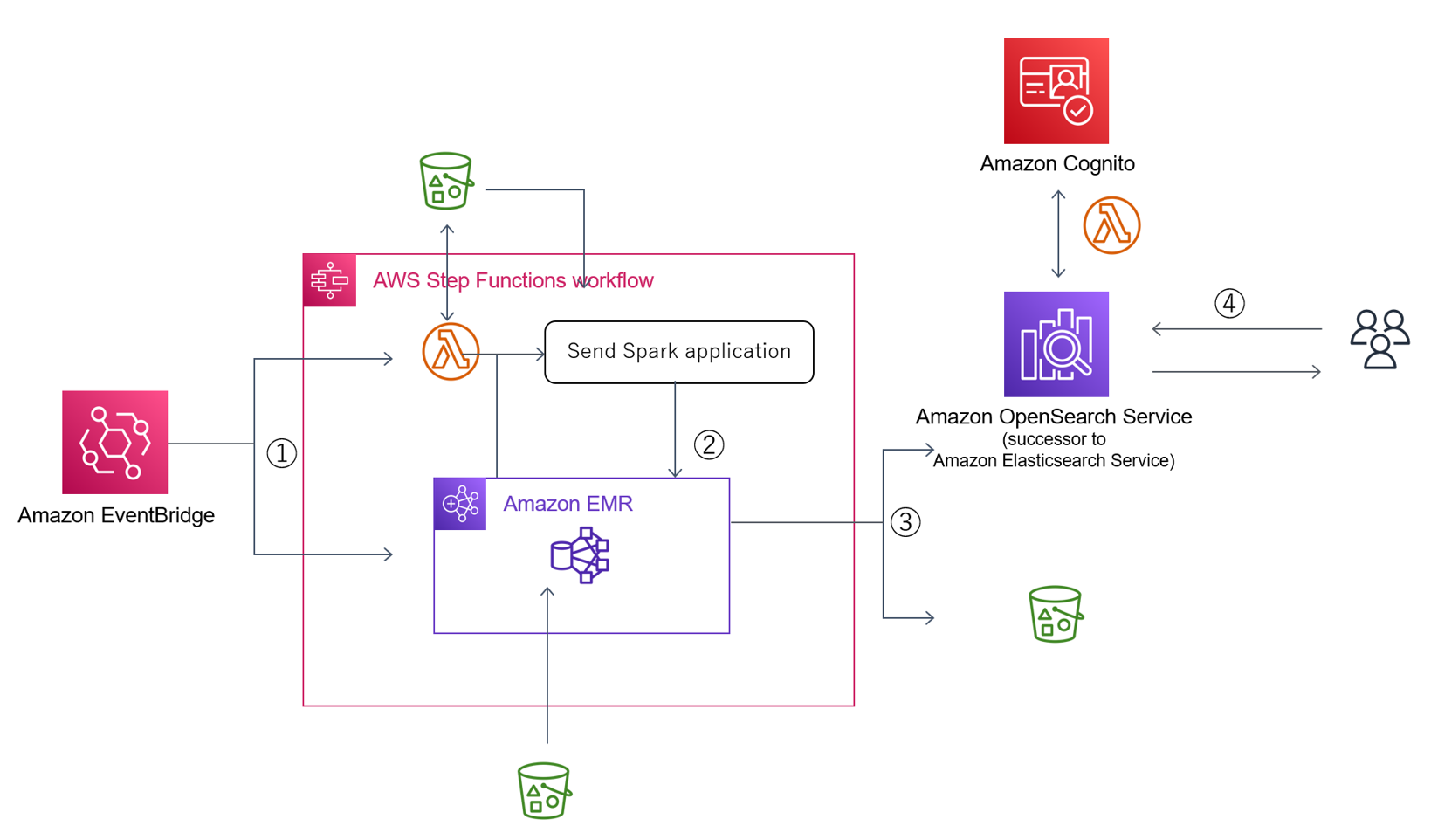
図1:アーキテクチャ図
処理の流れは以下の通りです。
① Amazon EventBridgeで毎朝AWS Step Functionsを実行
AWS Step Functionsでは、まずAmazon EMR クラスターを起動すると同時に、Amazon Simple Storage Service (Amazon S3)上の設定ファイルを読み込み、その日実行したい処理を行うPython スクリプト(Spark アプリケーション)を生成しAmazon S3に保存します。
② Amazon EMR クラスターでSpark アプリケーションを実行
生成したSpark アプリケーションをAWS Step FunctionsのAPIを用いAmazon EMR クラスターにSubmitします。通常Spark アプリケーションは数十個あるので、Map 状態を使用し順番に実行させます。
③ 処理結果を保存
処理した結果は、基本的にOpenSearchに送信します。Amazon EMRで統計処理したデータはCSV等のフォーマットに変換してAmazon S3に保存しリサーチャーまたは他のシステムで参照できるようにします。
④ OpenSearch経由でデータを閲覧
Amazon Cognitoで認証を行ってログインし、データを閲覧・分析します。
環境を設計する際に検討したポイントは以下の3点です。
待ち時間なく、検索・調査できる形でのデータ保持
データ処理の観点から考えると、列指向フォーマットはメリットが多いですが、人が分析する際は簡単に開け閲覧できる形式であることは重要です。平均値等の要約統計量であれば、CSVとしてAmazon S3に書き出し必要に応じて表計算ソフトで加工しています。生データについては、ファイルサイズが大きく、複数のデータソースを参照するためスキーマが異なることがあり表計算ソフトで処理できないケースがありました。そういった場合に使われる有名な製品としてはSplunkやElastic Stackが挙げられます。AWSではElasticSearchとKibanaをForkしたAmazon OpenSearch Serviceがマネージドサービスとしてありますので、これを高機能表計算ソフトとして活用しています。Splunkに比べ、OpenSearchはデータの加工に制限がありますが、データの加工(フィルタおよびエンリッチ)はAmazon EMR側でカバー可能です。
費用を減らす
費用の削減は様々な角度からチャレンジしています。
1) AWS Step Functionsの活用
AWS Step Functionsでは様々なAWSサービスを制御でき、費用削減につながります。例えばAWS Lambda内でSleepする場合Sleepしている間も費用が発生します。一方、AWS Step Functionsでは状態遷移に対して費用が発生するので、AWS Step Functionsで費用が抑えられることがあります。また、AWS Step Functionsは直接APIアクションを呼び出すことができます。当初、本環境でAmazon EMRクラスターを制御するために複数のAWS Lambdaが必要でした。現在は、クラスターの起動・停止、ステップの追加等、必要な制御をAWS Step Functionsから行うことが可能になりました。
また、”.sync”サフィックスを持つAPIを使用すると、AWS Step Functionsが操作対象サービスの状態を確認し制御してくれます。例えばcreateCluster.syncだと、AWS Step Functions はクラスターがセットアップされるまで待機し、WAITING 状態になったのを確認したのち、次の処理に遷移します。これも当初はAWS LambdaやAWS Step FunctionsのWait状態を使って制御していましたが、扱いやすくかつ費用削減になりました。
2) スポットインスタンスとインスタンスフリートの活用
脅威リサーチ目的でのデータ分析では、リアルタイム性は必須ではないため、1日分まとめて処理をしています。今回の環境で大きく費用を占めるサービスの一つであるAmazon EMRクラスターはAmazon Elastic Compute Cloud(Amazon EC2)で構成されています。本環境では基本的にスポットインスタンスを使用しており、スポットインスタンスアドバイザーで定期的に中断率を確認し、中断率が低いインスタンスを中心に構成しています。また、インスタンスフリートも活用しています。AWSのブログで紹介されているベストプラクティスをもとに、クラスター起動時Sparkにexecutorに関する設定を入れているため、インスタンスフリートで設定するインスタンスタイプは統一しています。
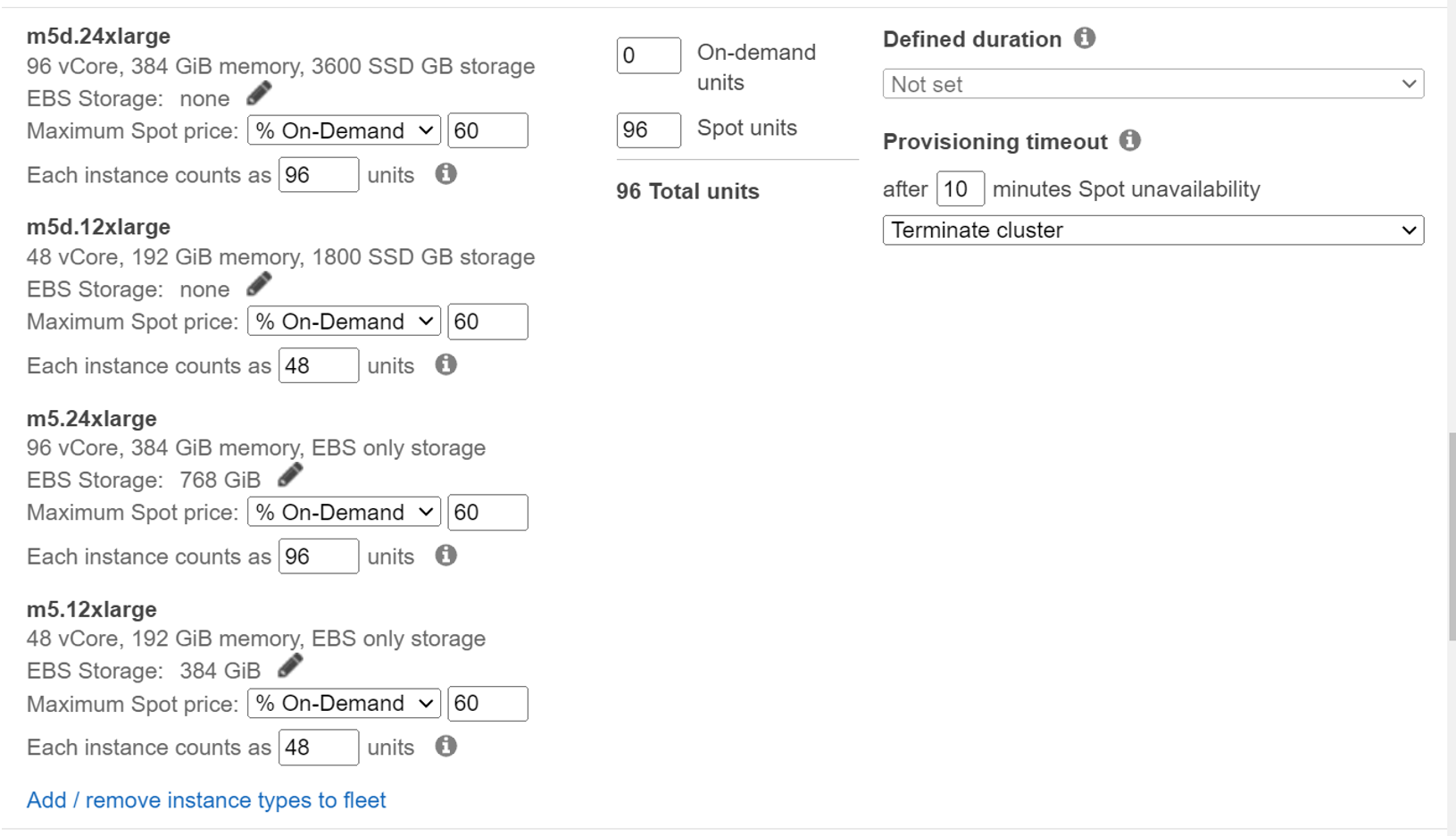
図2:インスタンスフリートの設定例
また、Amazon EMRではAmazon EC2料金に加えAmazon EMR 料金も追加されます。本記事執筆時、私たちがよく使用するM5インスタンスでは、m5.8xlarge以上のインスタンスでAmazon EMR 料金が一定になります。コア・タスクノードとしてスポットインスタンスを使用する場合、中断通知等を活用しても処理が中断する可能性もありますし、処理するデータやクラスターの規模にもよりますが、基本的にクラスターのノードを増やし、できるだけ処理時間を短くすることが費用削減につながると考えて設定変更をしています。
3) データの削減
検索時の処理時間に起因するストレスや中身の確認が難しくなっている大きな要因は対象のデータが膨大であることだと考えています。脅威リサーチにおいて、その日生成される調査対象すべてのデータが必要ということはなく、調査するトピックに関連するデータとその周辺データのみあれば十分です。本環境ではSparkを用いデータの抽出を行っているのですが、どういった条件でデータを抽出するかが問題になります。主に、IoCやキーワードをキーとして抽出することが多いのですが、追加変更がたびたび発生します。毎回スクリプトを書き換えることが面倒だったので、UDFを使用しないシンプルな検索についてはYAMLで条件を指定することで、SparkアプリケーションをAWS Lambdaで生成するようにしています。抽出条件を比較的柔軟に変更できるので、抽出範囲を広げたり狭めたりすることでデータ量の調整が可能となります。
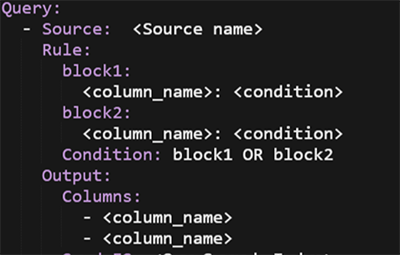
図3:抽出条件のyamlファイル例

図4:生成されるクエリ例
アクセスコントロールとロギングを強化する
脅威リサーチでは、各トピックに対し担当のリサーチメンバーがアサインされることが多くあります。無関係な第三者からのアクセスはもちろん、トピックによっては担当していないリサーチメンバーからのアクセスが好ましくない場合があります。そのため、OpenSearch Dashboard へのアクセスはAmazon Cognitoで認証を行い、Fine-grained access controlで各グループに所属するユーザが参照できるIndexやテナントの読み書きを制限しています。同じトピックを担当するリサーチメンバーのみが対象データの参照やダッシュボードの共有ができ、異なるトピックを担当するリサーチメンバーはいずれも参照できないようになっています。
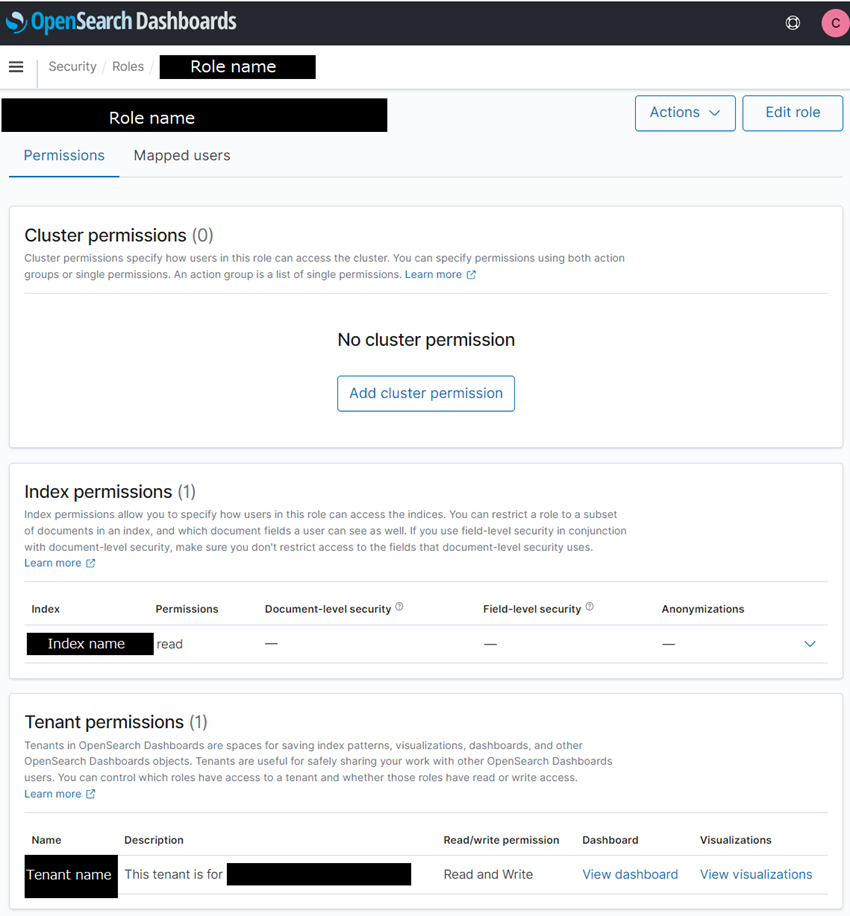
図5:Open Searchでのセキュリティ設定例
また、アーキテクチャ図には明記していませんが、OpenSearchのログについてはAWS CloudTrailに保持しています。これにより、何か問題が生じた際に正規のユーザのアクティビティを確認することができます。悪意の有無を問わず分析環境に大きな影響を与える変更についてはメールやSlack/Teams等への通知を行い、詳細なログの確認にはAmazon QuickSightで確認できるように構成しています。
おわりに
本記事では、AWSの様々なサービスを活用し脅威リサーチのためのデータ処理ついて紹介しました。Amazon EMRとSpark アプリケーションによって柔軟にデータの抽出やエンリッチができ、OpenSearchで扱いやすくなりました。また、よりコストや人を介さない形での運用につながる各サービスのエンハンスも発表されているので、私たちは検証が追い付いていない部分がありますが、取り入れていければと考えています。
本記事では脅威リサーチでのデータ分析に必要な環境について紹介してきましたが、実はデータ分析だけで脅威や攻撃を特定できることは多くはありません。データ分析で気づいた不審なアクティビティの詳細を調査し、関係のあるファイル類の解析結果等と合わせて脅威や攻撃の特定を進めていきます。
本環境は、現在エンリッチ処理を中心とした拡張を続けています。付加した情報により未だ顕在化していない脅威や攻撃に早く気付き、それらの特定につなげていきたいです。そして、これらの調査で得た知見を活かしたソリューションや情報提供により、お客様の環境の護りに貢献してまいります。
アプライドサイバーセキュリティラボ スレットリサーチチーム 東 結香
監修

根本 恵理子
トレンドマイクロ株式会社 セキュリティエキスパート本部
セールスエンジニアリング部 サーバセキュリティチーム
ソリューションアーキテクト
CDN業界にて大規模なWebサービスの負荷分散やパフォーマンス改善、セキュリティ対策等の提案・導入を経験した後にセキュリティ業界へ転身し7年業務に従事。Trend Cloud Oneシリーズのソリューションアーキテクトとして、クラウド全体のセキュリティ対策の検討やストレージ環境に対するセキュリティ対策の普及に注力。またトレンドマイクロとAWSのアライアンスにてTech担当をしており、共催イベント、エンジニア連携企画等のリードに従事。



電子公告 | ご利用条件 | 個人情報保護方針 | Privacy and Legal |利用者情報の外部送信について | 製品使用許諾契約 |プレスリリース | サポート | サイトマップ | RSS
Copyright ©2026 Trend Micro Incorporated. All rights reserved