Using Machine Learning to Detect Malware Outbreaks With Limited Samples
 View Generative Malware Outbreak Detection
View Generative Malware Outbreak Detection
Catching malware on the onset is integral to keeping users, communities, enterprises, and governments protected. With the advent of machine learning (ML) technology for cybersecurity, detecting malware outbreaks has been made relatively more efficient. Machine learning helps analyze large amounts of data to find patterns and correlations in malware samples as well as helps train systems to detect future similar variants as they emerge. But can machine learning aid in analyzing a malware outbreak given a small dataset? We, in collaboration with Federation University Australia researchers, conducted a study titled “Generative Malware Outbreak Detection,” which showed the effectiveness of the latent representations obtained through adversarial autoencoder for such situations. This ML model for malware outbreak detection uses
Big, Bad Malware Outbreaks
In today’s threat landscape, malware outbreaks have become overt events that have adversely affected users and companies globally and caused billions of dollars’ worth of damages. The NotPetya ransomware, which came out in 2017, became “the most destructive and costly
Meanwhile, in 2018, the
In both cases, a sizeable amount of data was readily available for analysis. But for outbreaks with only a handful of available data, we propose a method that detects malware samples similar to other variants. This method uses just one malware sample for training with adversarial autoencoder and has a high detection rate for similar malware samples and a low false positive rate for benign ones.
For this research, we collected 3,254 in-the-wild OS X malware samples and 9,981 benign, randomly chosen OS X Mach-O samples. In order to replicate a malware outbreak, 175 out of the 3,254 malicious samples that showed unique instruction sequence patterns were handpicked by a human malware expert. These selected malware samples are the core malicious training samples and were assigned unique labels.
An Important Feature: Program Instruction Sequence
Malware authors usually use custom tools to automatically generate mutated or modified malware samples. And these samples are basically a collection of malware that has the same functionality but made to look different through obfuscation, the purpose of which is to evade static signature-based detection by security products. Though the malware samples are obfuscated, we observed that they still have one feature that’s relatively unchanged: the distribution of the program instruction sequence.
|
To illustrate, we analyzed different variants of the MAC.OSX.CallMe malware using the following samples:
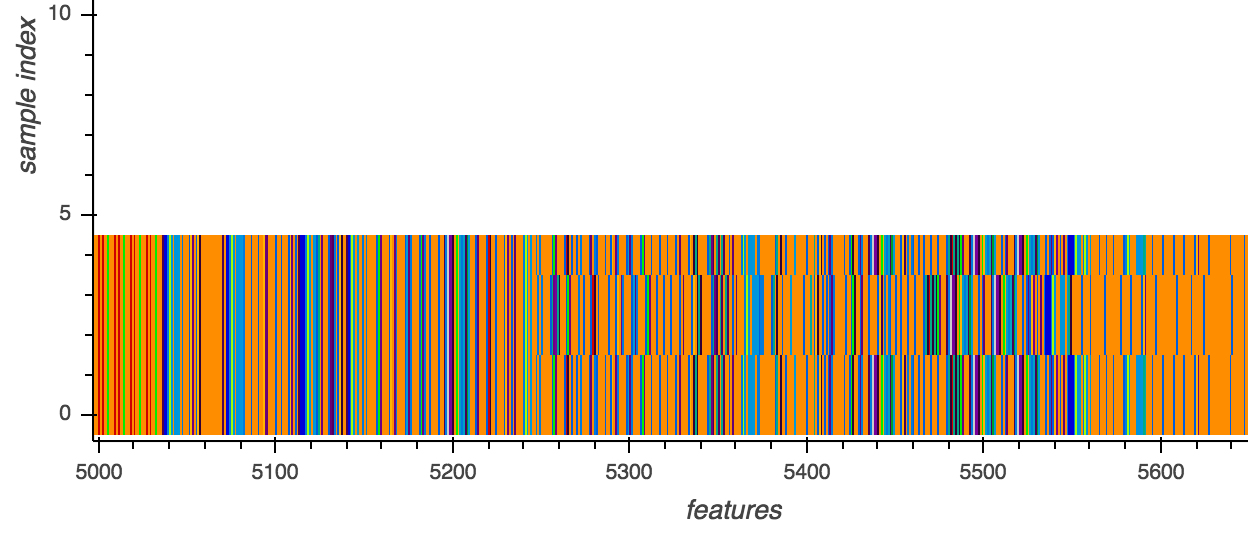
In Figure 1, we noticed that all variants of the MAC.OSX.CallMe malware
An example of a malicious cluster detected by adversarial autoencoder with semantic hashing (
Our research paper “Generative Malware Outbreak Detection” provides a deep dive on how we used the instruction sequence as the sole feature for the malware outbreak detection model we proposed. Our full paper also discusses how our proposed model captures the program instruction sequence in the presence of code transposition and integration metamorphism through adversarial autoencoder. It was presented at the IEEE International Conference on Industrial Technology (ICIT) 2019. An updated version will be available in the IEEE Xplore Digital Library.
Like it? Add this infographic to your site:
1. Click on the box below. 2. Press Ctrl+A to select all. 3. Press Ctrl+C to copy. 4. Paste the code into your page (Ctrl+V).
Image will appear the same size as you see above.
 Complexity and Visibility Gaps in Power Automate
Complexity and Visibility Gaps in Power Automate AI in the Crosshairs: Understanding and Detecting Attacks on AWS AI Services with Trend Vision One™
AI in the Crosshairs: Understanding and Detecting Attacks on AWS AI Services with Trend Vision One™ Trend 2025 Cyber Risk Report
Trend 2025 Cyber Risk Report The Road to Agentic AI: Navigating Architecture, Threats, and Solutions
The Road to Agentic AI: Navigating Architecture, Threats, and Solutions