Cloud
How to Optimize Your Lambda Code
Learn how to make your code run more efficiently in AWS Lambda, so you can save money and time!


Save to Folio
What is AWS Lambda?
Serverless is cool. Running serverless code, even cooler. And if you are using AWS, you either are, or are about to start, using AWS Lambda. For those unaware, Amazon defines AWS Lambda as a serverless compute service that lets you run code without provisioning or managing servers, creating workload-aware cluster scaling logic, maintaining event integrations, or managing runtimes. With Lambda, you can run code for virtually any type of application or backend service – all with zero administration.
This great for two reasons:
- It allows builders to focus on business logic instead of infrastructure.
- It’s also secure, since Lambda invokes your function in an execution environment, which provides a secure and isolated runtime environment.
Paying only for the compute time that is consumed is also one if its benefits, which made it a perfect choice for a project that my team was working on because this code would run a few hundred times over two days and that would be it.
AWS handles the trouble of spinning up the execution environment when the function is triggered (a HTTP request in our case), executes the code, and terminates it right away. Or does it?
Let me show you how our code made me realize I was wrong about Lambda, and how you can capitalize on my mistake to make your code run more efficiently in Lambda and save you a few bucks in the process!
Our case
Our Lambda function code had a clear purpose. It would verify a specific Amazon S3 bucket for the existence of two objects, where each key (“name”) had to match one of the two prefixes we were looking for. Below is a reduced and simplified version of our Python code:
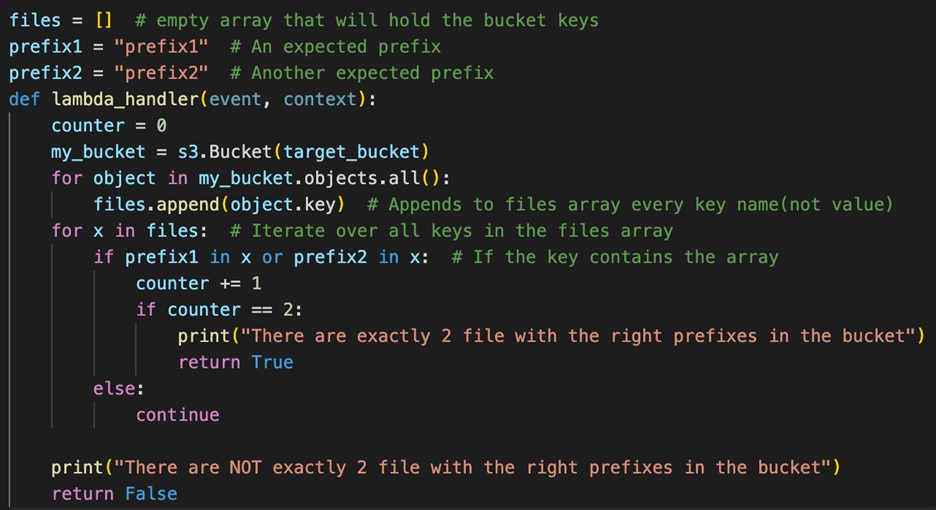
This code worked well in our tests and was approved in the code review process. It returns True when there are two files with the right prefixes, and it returns False when there isn’t. Simple enough.
That wasn’t what happened in real life, however. It would still work in the scenario where the right files are there, but it would, only sometimes, return True when just one of the files were there. And this was frustrating because it was happening in production and only sometimes. Nothing is more annoying than “sometimes.”
Let’s figure this out
Don’t try this at home kids, but the first idea that came to mind to troubleshoot the problem was to edit the Function code and add a “print(files)” between the two “for” loops. This way I would be able to check the files array content before looping through all its contents. Then I checked the bucket and saw that there was just one file there, with the right prefix. Right away I executed the code and in that line the code printed exactly what I was hoping for, array had only the right item, and it returned False, as expected as well.
I was confused. I ran the code again, just because I was out of ideas. To my surprise, the code returned True this time. I was twice as confused as before. That print output now showed the right file there… twice! There were 2 objects with the same key in the same bucket, which we know is impossible. Right away I went to check if versioning was enabled on said bucket, maybe that was the issue. But it wasn’t. Versioning was off. I ran the code again, and once again, it returned False and printed the filename just once.
Feeling more lost than I already was in the beginning of all this, I stopped, took a deep breath, and tried all over again. First execution, False with printing the file name once. Second, returned True printing the file name twice. Third, returned False, printing the filename thrice. Clearly there was something wrong with this files variable.
What I got wrong
Any beginner developer knows the concept of Scope, even if the name isn’t known. For those who don’t, Scope can be defined as a variable that is declared is only available inside the region it is created. If we go back to our code, we can see that the variable files are declared in the global scope (in the function root, outside of any function/method). I moved this declaration to inside the lambda_handler function scope (right before the counter declaration) and it worked! An execution would ways return False and print the filename just once given my bucket content. So, what happened?
We tend to oversimplify everything for our own sake. In Lambda’s case, why would we overthink how the process behind running our code works if in the general case, “it just works?” This was one of the cases that understanding the (fascinating) process was helpful, and it can be to you too.
How it actually works
The Lambda execution environment lifecycle has three distinct phases: Init, Invoke and Shutdown, which are defined by AWS as:
- Init: Lambda creates or unfreezes an execution environment with the configured resources, downloads the code for the function and all layers, initializes any extensions, initializes the runtime, and then runs the function’s initialization code (the code outside the main handler.) The Init phase happens either during the first invocation, or in advance of function invocations if you have enabled provisioned concurrency.
- Invoke: Lambda invokes the function handler. After the function runs to completion, Lambda prepares to handle another function invocation.
- Shutdown: This phase is triggered if the Lambda function does not receive any invocations for a period of time. In the Shutdown phase, Lambda shuts down the runtime, alerts the extensions to let them stop cleanly, and then removes the environment. Lambda sends a Shutdown event to each extension, which tells the extension that the environment is about to be shut down.
Unsurprisingly, the documentation shoves in my face what we were getting wrong all along: code in the global scope is executed once in the Init process. An execution environment is only shutdown if it doesn’t receive invocations for a period of time. While there are executions to be processed, the same initiated execution environment will be reused across executions. They even add an illustration to make it extra clear!

Figure 1. AWS Lambda execution environment example from https://docs.aws.amazon.com/lambda/latest/dg/runtimes-context.html
How you can capitalize from my mistake
On top of now knowing you don’t want to declare variables that are intent to be unique between executions globally, there is an even bigger way to capitalize on this story. As bad as it is to declare such variables, it is a great practice to declare constants, or variables that are reused amongst executions to save you on both execution time and money.
For instance, let’s say you have a code that connects to a database to query customer data. You could write it as seen below:
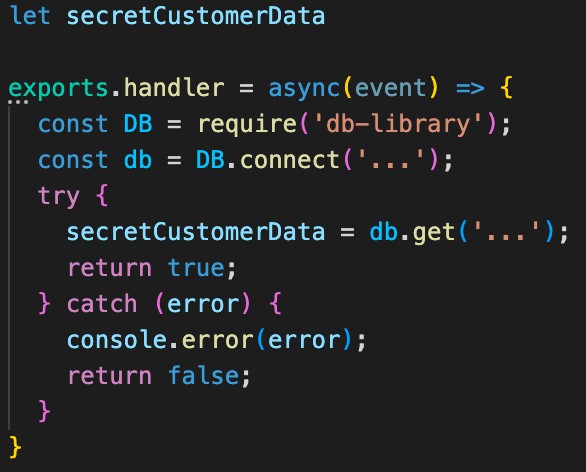
Which is great, it works really well. But it isn’t Lambda optimized. We now know we can do better. See below:
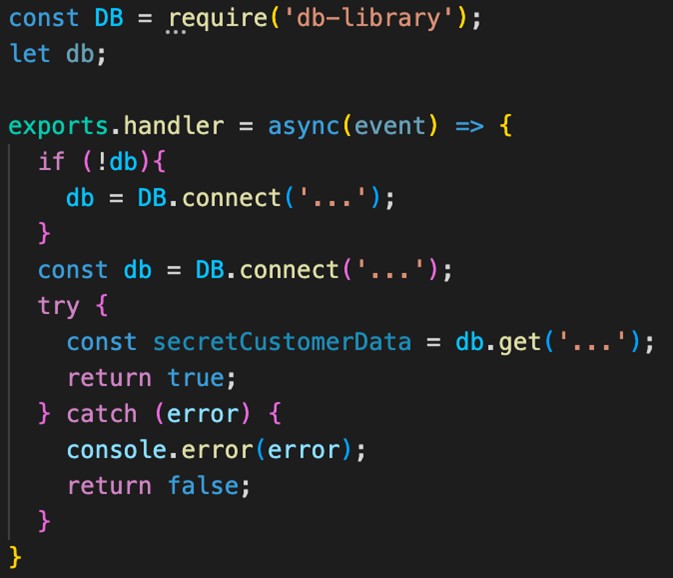
These small changes bring a lot of benefits for your code execution.
- We are moving the initialization of the library to the global scope, doing this only once across executions.
- We are moving the potentially dangerous expose secretCustomerData to inside the function handler. This means it won’t be shared between execution, reducing its exposure.
- We are making sure that the act of connecting to the database is made just once across executions, potentially drastically reducing the amount of time to execute this code.
I’m glad I could share my experience so that others could learn from what I’ve been through. But I would like to know, did you know all of this about Lambda? For more insights into using Lambda securely, check out the following articles:
Security for AWS Lambda Serverless Applications
Secure Your Images with AWS Lambda Serverless Functions
