Cloud
The AWS Well-Architected Framework Guide
Discover the six Amazon Web Services (AWS) Well-Architected Framework pillars by examining best practices and design principles to leverage the cloud in a more efficient, secure, and cost-effective manner.


Save to Folio
Related articles in the Well-Architected series:
- Operational Excellence
- Security Pillar
- Reliability Pillar
- Performance Efficiency Pillar
- Cost Optimization Pillar
- Sustainability Pillar
Designing and building a secure cloud environment is critical to ensuring your business has a strong security posture, but this is easier said than done. In the past, when the data center was fully within your control and you only had a single server to be concerned about, it was already challenging to uphold strong security posture management. Fast forward to the world of cloud—where we don’t have physical control over our data centers—the challenge grows a lot greater. Luckily, there is good news. Just because you don’t have physical control over your data center, doesn’t mean you can’t secure it.
So, the burning question is; what should and can we do to build a secure cloud? Even if your security posture is strong today, there is no guarantee it will be tomorrow. Threat actors are always looking to get around the new defenses being implemented, so you need to stay a step ahead. Otherwise, cybercriminals will make their way in and may cause devastating consequences to the business. To prevent an attack from occurring in your business requires careful planning, use tactics such as the Deming Cycle of Plan, Do, Check, Act. This iterative four-step management method promotes organizational control and continuous improvement.
Discerning cloud service default settings
One of the exceedingly difficult challenges with cloud is knowing what the default settings are for each cloud service and the changes needed to have a secure implementation. Take, for example, the simple creation of Amazon Simple Storage Service (Amazon S3) on AWS:
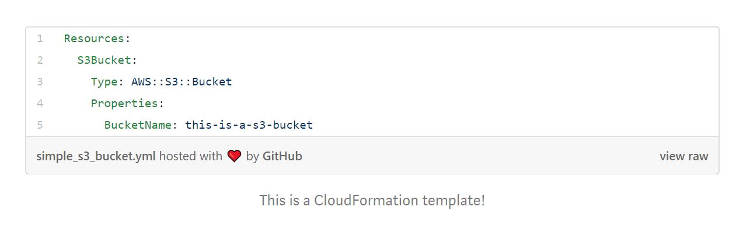
With the command-line interface (CLI), it takes but a few lines to create a bucket. Unfortunately, that isn’t enough to ensure the data stored in the bucket is secure. Here is a look at a well-architected bucket:

Not so easy, huh? Luckily AWS has created several reports on the Well-Architected Framework to explain cloud architectural design principals that can help guide you through the process. For example, in the case of an Amazon S3 bucket, you need to remember to disallow public read access, ensure logging is enabled, use customer-provided keys to ensure encryption is on, and so on.
With so many cloud services and resources, it’s tough to remember what to do and what configurations should be there. However, as you can see from links to articles on infrastructure configuration, Trend Micro has lots of information about what should be done to build cloud architecture to best practice levels. The Trend Cloud One™ – Conformity Knowledge Base contains 1,000 best practice articles to help you understand each cloud best practice, how to audit, and how to remediate the misconfiguration.
Cloud infrastructure misconfiguration automation
Automation is an essential step towards minimizing the risk of a breach, always scanning and providing feedback to stay ahead of threat actors. For those building in the cloud, having an automated tool to continuously scan your cloud infrastructure for misconfigurations is a thing of beauty. It can ensure you are always complying with those 1,000 best practices, without the heavy lifting.
If you'd like to be relieved from manually checking for adherence to well-architected design principals, sign up for a free trial of Conformity.
Alternately, if you’d to see how well-architected your infrastructure is, check out the free guided public cloud risk self-assessment to get personalized results in minutes.
The Six Pillars of a Well-Architected Framework
Conformity and its Knowledge Base are built around the AWS Well-Architected Framework, which is defined by six pillars:
- Operational Excellence: Running and monitoring systems
- Security: Protecting information and systems
- Reliability: Ensuring a workload performs as it should
- Performance Efficiency: Efficient use of IT
- Cost Optimization: Avoiding unnecessary costs
- Sustainability: Environmental impacts
Each of these pillars has its own set of design principals, which are extremely useful for evaluating your architecture and determining if you have implemented design principles that allow you to scale over time.
1. Operational Excellence Pillar
Starting with the Operational Excellence pillar, creating the most effective and efficient cloud infrastructure is a natural goal. So, when creating or changing the infrastructure, it is critical to follow the path of best practices outlined in the AWS Operational Excellence pillar.
The Operational Excellence pillar focuses on two business objectives:
- Running workloads in the most efficient way possible.
- Understanding your efficiency to be able to improve processes and procedures on an ongoing basis.
To achieve these objectives, there are five critical design principles can be utilized:
- Perform operations as code, so you can apply engineering principles to your entire cloud environment. Applications, infrastructure, and so on, can all be defined as code and updated as code.
- Make frequent, small, reversible changes, as opposed to large changes that make it difficult to determine the cause of the failure—if one were to occur. It also requires development and operations teams to be prepared to reverse the change that was just made in the event of a failure.
- Refine operations procedures frequently by reviewing them with the entire team to ensure everyone is familiar with them and determine if they can be updated.
- Anticipate failure to ensure that the sources of future failures are found and removed. A pre-mortem exercise should be conducted to determine how things can go wrong to be prepared.
- Learn from all operational failures and share them across all teams. This allows teams to evolve and continue to increase procedures and skills.
CI/CD is good, but to ensure operational excellence, there must be proper controls on the process and procedures for building and deploying software, which include a plan for failure. It is always best to plan for the worst, and hope for the best. So if there is a failure, we will be ready for it.
With data storage and processing in the cloud, especially in today's regulatory environment, it is critical to ensure we build security into our environment from the beginning.
There are several critical design principles that strengthen our ability to keep our data and business secure, however, here are the seven recommended based on the Security pillar:
- Implement a strong identity foundation to control access using core security concepts, such as the principle of least privilege and separation of duties.
- Enable traceability through logging and metrics throughout the cloud infrastructure. It is only with logs that we know what has happened.
- Apply security at all layers throughout the entire cloud infrastructure using multiple security controls with defense in depth. This applies to compute, network, and storage.
- Automate security best practices to help scale rapidly and securely in the cloud. Utilizing controls managed as code in version-controlled templates makes it easier to scale securely.
- Always protect data in transit and at rest, using appropriate controls based on sensitivity. These controls include (but not limited to) access control, tokenization, and encryption.
- Keep people away from data to reduce the chance of mishandling, modification, or human error.
- Prepare for security events by having incident response plans and teams in place. Incidents will occur and it is essential to ensure that a business is prepared.
Five areas to configure in the cloud to help achieve a well-architected infrastructure
There are several security tools that enable us to fulfill on the design principles, above. AWS has broken security into five areas that we should configure in the cloud:
- Identity and access management (IAM), which involves the establishment of identities and permissions for humans and machines. It is critical to manage this through the lifecycle of the identity.
- Detection of an attack. A common challenge faced by businesses, detection attacks often arise from user error. Enablement of logging features, as well as the delivery of those logs to the SIEM is essential. Once the SIEM has detected a malicious action, alerts should be sent out.
- Infrastructure protection of the network and the compute resources is critical. This is done through a variety of tools and mechanisms. This comprises of either infrastructure tools or code protection, included (but not limited to) virtual private clouds (VPCs), code review, vulnerability assessments, gateways, firewalls, load balancers, hardening, and code signing.
- Data protection in transit and at rest is also critical. This is primarily done with IAM and encryption. Most discussions of encryption review what algorithms are used and the key size. The most important piece to discuss, in relationship to encryption, is the location of the key and who has control over it. It is also important to determine the authenticity of the public key certificates.
- Incident response is the ability to respond immediately and effectively when an adverse agent occurs. As the saying goes “failing to plan is planning to fail,” not having incident responses planned and practiced can lead to a costly incident.
What is essential to remember is that security of a cloud ecosystem is a split responsibility. AWS has defined where responsibility lies with them versus where it lies with the consumer. It is good to review the AWS shared responsibility models to ensure you are upholding your end of the deal.
Reliability is important for any IT-related system, as it must provide the services that users and customers need, when they need it. Reliability involves understanding the level of availability that your business requires from any given system.
When it comes to the Reliability pillar, AWS has defined five critical design principles:
- Automatically recover from failure. Depending on business needs, it may be essential that there are automated recovery controls in place, as the time it takes a human to intervene may be longer than a business can tolerate.
- Test recovery procedures. Backing up the data from an Amazon S3 bucket is good first step, but the process is not complete until the restoration procedure is verified. If the data cannot be restored, then it has not been successfully backed up.
- Scale horizontally to increase aggregate workload availability as an alternate way to envision a cloud infrastructure. If the business is using a virtual machine with a large amount of CPU capacity to handle all user requests, you may want to consider breaking it down into multiple, smaller virtual machines that are load balanced. That way, if a machine failed, the impact is not a denial of service, and if planned well, the users may never know there was a failure.
- Stop guessing capacity. Careful planning and capacity management is critical to the reliability of an IT environment and may save you money where you are spending on unnecessary capacity needs.
- Manage change and automation so alternations to the cloud do not interfere with the reliability of the infrastructure. Change management is core to ITIL. Changes should not be made unless they are planned, documented, tested, and approved. There must also be a backup plan for if/when a change breaks your environment.
With availability being at the core of this pillar, it is good to understand its definition. AWS defines availability as:
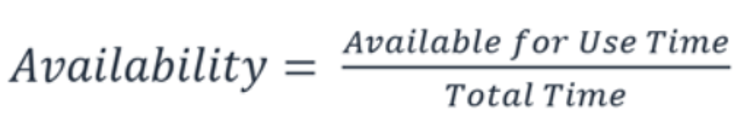
When availability is understood, it is possible to choose the right systems and the right configurations needed to fulfill the needs of the business. This should be in our design goals from the beginning. Redesigning a system later to match goals that we did not understand from the beginning is a very costly alternative.
4. Performance Efficiency Pillar
This focuses on your ability to use computing resources as efficiently as possible and maintain that efficiency as the demands from the business change and technologies evolve.
To fulfill performance efficiency, the following five design principles should be adhered to:
- Democratize advanced technologies. For example, when new technologies are available it might be best to leave the learning and management of these technologies to the cloud provider, consuming them as a service instead. This frees up the time and skills of your developers and operations departments to focus on their jobs.
- Go global in minutes to ensure the services accessed by users or customers are as close to them as possible. As the workforce expands to a global presence, the workload within the cloud can and should expand to regions that are closer to the end user to improve the response time for everyone.
- Use serverless architectures to leave management of physical servers to the cloud provider. While the idea of serverless sounds like a technology that removes the actual servers, it is essentially an alternative way of running services and lowering costs. It creates the illusion that there is no server, but rather the cloud provider manages it in a completely transparent manner, allowing the customer to focus on their functions or applications.
- Experiment more often to discover the best infrastructure or configuration that serves the business most efficiently. Virtualization makes it possible to spin up a new resource quickly. If it does not work for the business, then it can be shut down just as quickly.
- Consider mechanical sympathy by looking at how your data is accessed and utilized. From a data-centric perspective, you want to find the best technology to meet the needs of the business.
Justifying business spending on any given service is no cake walk. Cloud does not change that. In fact, it could be more difficult to justify because it changes the way businesses look at their IT cost. Traditionally, IT is a capital expenditure and equipment is purchased based on the prediction that the equipment will be used for the next three to five years. With cloud services, money is spent as an operational expenditure, which means that money is spent on the services needed and used each month. There are many choices when configuring and building cloud environments that make a difference in your bottom line. Therefore, it is important to strike a balance between money spent on services and what you actually use.
To help you make the most informed decision, five design principles for cost optimization are provided:
- Implement cloud financial management by creating a cost-aware culture. It is essential that budgets and forecasts are used to predict and determine the amount of money that should be spent on any given cloud service. It is also good practice to determine any reasons that the business may incur cost overruns, using root cause analysis from existing processes.
- Adopt a consumption model that enables IT to take actions that reduce or increase usage, based on your business’ needs. The cloud has a basic design principal of paying only for what you consume. For example, in a test environment, shutting down the virtual servers at the end of the day would save money.
- Measure overall efficiency by tracking metrics for specific usage parameters to the specific department that uses the service to enable better calculations and proof of efficiencies made by increasing the output and functionality.
- Stop spending money on undifferentiated heavy lifting. The cloud service providers do the heavy lifting for you—buying servers, racking them, and managing them. By having the cloud provider do this work, your business only has to spend money on the actual usage.
- Analyzing the attributed expenditure using a tagging method. Tagging allows the usage of a cloud service to be attributed to certain departments within a business and enables more accurate return on investment (ROI) calculations.
This pillar focusing on environmental impact may seem odd, considering you’re building in the cloud—an intangible environment. However, since you’re using energy to build your cloud workloads, you’re negatively impacting the environment via indirect emissions. The Sustainability pillar helps you understand the impact of services used, how they’re typically accounted, and the follow-on impacts to your organization’s own emissions. By adhering to the design principles, you can build architectures that maximize efficiency and minimize waste—a win-win for cloud builders and their organizations.
The six design principles include:
- Measure the impact of your cloud workload and mock-up future impact. Make sure you include all sources of impact, such as customer use and eventual decommissioning. Leverage this data to establish KPIs, evaluate ways to optimize productivity while reducing impact, and estimate the impact of the changes over time.
- Establish long-term sustainability goals like reducing the compute and storage resources required per transaction. Draft a plan to obtain these goals, keeping in mind future growth. These goals will encourage sustainability across your organization, identify any setbacks, and prioritize areas of improvement.
- Maximize utilization by implementing efficient design. This means eliminating or minimizing unused resources, processing, and storage. Consolidate resources can also be included here. Instead of two hosts running at 30% utilization, run one host at 60% to eliminate the wasted baseline power consumption of the extra host.
- Leverage new, more efficient offerings to help you reduce the impact of your cloud workloads. If you’re following the well-architected framework, your architecture should have the flexibility to quickly adopt and integrate new technology.
- Sharing is caring. Use managed services across your customer base to maximize resources, reducing the amount of infrastructure needed to support your workloads. For example, automatically moving infrequently accessed data to cold storage with Amazon S3 Lifecycle configurations will help minimize your impact.
- Reduce the amount of energy or resources required for your cloud workloads by minimizing or eliminating the need for customers to upgrade their devices to access your apps. You can use device farms to run tests to better understand the expected or actual impact from customers using your services.
AWS Well-Architected LensesThese evaluations compliment the guidance offered by AWS Well-Architected to particular sectors and technical areas. This includes as machine learning (ML), data analytics, serverless, high performance computing (HPC), IoT, SAP, streaming media, the games industry, hybrid networking, and financial services.
To fully evaluate workloads, use applicable lenses together with the AWS Well-Architected Framework and its six pillars:
- SaaS Lens. Best practices for architecting your software as a service (SaaS) applications on AWS.
- IoT Lens. Best practices for architecting your IoT applications on AWS.
- Data Analytics Lens. Best practices for designing well-architected analytics workloads.
- Healthcare Industry Lens. Best practices for how to build and manage healthcare workloads on AWS.
- Container Build Lens. Best practices for how to build and manage containerized workloads on AWS.
- Serverless Applications Lens. Best practices for architecting your serverless applications on AWS.
Growing with the cloud and remaining well-architected
As more security breaches hit the news and data protection becomes a key focus, ensuring your organization adheres to the well-architected framework’s design principles is crucial. Conformity can help you stay compliant to the well-architected framework with its 750+ best practice rules.
Identifying how well-architected your organization is starts with seeing your own security posture in 15 minutes or less.
