
A form of artificial intelligence (AI) that enables systems to learn patterns from data and improve their performance on tasks over time without being explicitly programmed.
Table of Contents
Machine learning uses algorithms and statistical models to make predictions or decisions based on input data. Having computers that figure out what to do without being explicitly told has captured imaginations for a long time.
The idea of a car you can ride in that will do all the driving, identifying pedestrians and potholes and responding quickly and efficiently to changes in the environment to deliver you safely to your destination – that is machine learning (ML) in practice.
How does it work? Let's start with analyzing just business data.
ML is a type of AI that allows businesses to make sense of and learn from massive quantities of data. It requires considerable work for businesses to gain valuable information. To make the most of ML, you must have clean data and know what question you have about it. Then you can select the best model and algorithm to benefit your business. ML is not a simple or an easy process. Its success takes diligent work.
There is a life cycle for ML:
- Business understanding. Defining the problem, success criteria, and whether ML is the right approach.
- Data collection and cleaning. You have the necessary amount of data, and it has been effectively cleaned, so it’s ready to deliver the insights you need.
- Feature selection. The process of choosing which input variables (features) to use in building the model. Methods include statistical tests, regularization, or algorithm-based importance measures. For example, decision trees rank features by criteria like information gain or Gini impurity.
- Model selection. Choose an appropriate algorithm and model type, then train it with your data.
- Training and tuning. Fit the model to the data and adjust hyperparameters to improve performance.
- Evaluation of the model and algorithm to determine if it’s ready to use, or if you have to go back a couple of steps and refine your model, feature, algorithm, or data to achieve your objectives.
- Deployment of the trained model into production.
- Review of the output of the existing model in production

What is machine learning used for?
Machine learning is a way for businesses to understand and learn from their data. A business can use it for is a vast number of subfields. The use case depends on whether a company is trying to improve sales, provide a search feature, integrate voice commands into their product, or create a self-driving car.
Machine learning subfields
ML has a fantastic array of uses in today's business, and it can only increase and improve over time. The subfields of ML include social media and product recommendations, image recognition, health diagnosis, language translation, speech recognition, and data mining, to name a few.
Social media platforms, like Facebook, Instagram, or LinkedIn use ML to suggest pages to follow or groups to join based on the posts that you like. It takes historical data of what others have liked or what posts are similar to what you’ve liked, makes those suggestions to you, or adds them to your feed.
It is also possible to use ML on an eCommerce site to make product recommendations based on previous purchases, your searches, and other users’ actions similar to yours.
Another significant use for ML today is for image recognition. Social media platforms have recommended tagging people in your photos based on ML. Police have been able to use it, looking for suspects in pictures or videos. With the plethora of cameras installed in airports, stores, and doorbells, it is possible to figure out who committed a crime or where the criminal went.
Health diagnoses are also a good use of ML. After an event like a heart attack, it is possible to go back and see warning signs that were overlooked. A system used by doctors or hospitals could be fed medical records from the past and learn to see the connections from the input (behavior, test result, or symptom) to the output (e.g., a heart attack.) Then when the doctor feeds their notes and test results into the system in the future, the machine can spot the heart attack symptoms much more reliably than humans so that the patient and doctor can make changes to prevent it.
Language translation on web pages or apps for mobile platforms is another example of ML. Some apps do a better job than others, which comes down to the model, technique, and algorithms they utilize.
An everyday use of ML that we don’t always think about is in banking and credit cards. There are signs of fraud that ML can detect quickly and would take humans a long time to discover, if at all. The plethora of transactions that have been examined and labeled (fraud or not) can allow ML to learn to spot fraud in a single transaction in the future. ML that is terrific for this is data mining.
Data mining
Data mining is a type of ML that analyzes data to make predictions or discover patterns within big data. The term is a bit misleading as it does not require anyone, be it a bad actor or employee, rooting around in your data to find a piece of data that would be useful. Instead, the process involves discovering patterns in data helpful for making decisions in the future.
Take, for example, a credit card company. If you have a credit card, your bank has likely notified you of a suspicious activity on your card at some point. How does the bank spot such activity so quickly, sending a nearly instantaneous alert? It’s the continuous data mining that enables this fraud protection.
Deep learning
Deep learning is a specific type of ML based on neural networks. A neural network works to emulate how the neurons in a human brain function to make a decision or understand something. For example, a six-year-old child can look at a face and discern her mom from the crossing guard because the brain analyzes many details quickly – hair color, facial features, scars, etc. – all within the blink of an eye. Machine learning replicates that in the form of deep learning.
A neural network has 3 to 5 layers: an input layer, one to three hidden layers, and an output layer. The hidden ones make the decisions to work towards the output layer or the conclusion one by one. What hair color? What eye color? Is there a scar? As the layers increment into the hundreds, it is called deep learning.
Types of machine learning
There are fundamentally four types of machine learning algorithms: supervised, semi-supervised, unsupervised, and reinforced. ML experts believe that approximately 70% of the ML algorithms in use today are supervised. They work with known or labeled datasets – for example, pictures of dogs and cats. The two types of animals are known, so the administrators can label the pictures before giving them to the algorithm.
Unsupervised ML algorithms learn from unknown datasets. Take, for example, TikTok videos. There are so many videos with so many topics that it is impossible to train an algorithm from them in a supervised fashion; the data is not labeled yet.
The semi-supervised ML algorithms are initially trained with a small dataset that is known and labeled. It is then applied to a larger unlabeled dataset to continue its training.
Reinforced ML algorithms are not initially trained. They learn from trial and error on the go. Think about a robot that is learning to navigate a pile of rocks. Every time it fails, it learns what doesn’t work, and it alters its behavior until it’s successful. Think about dog training and the use of treats to teach various commands. With positive reinforcement, the dog will continue to perform the commands and change behavior that doesn’t return a favorable response.
Supervised vs. unsupervised machine learning
Supervised machine learning
It uses known, established, and classified data sets to find patterns. Let’s expand on the previous idea of the pictures of dogs and cats. You could have a massive dataset full of thousands of different animals held within millions of pictures. Since animal types are known, these could have been grouped and labeled before giving them to the supervised ML algorithm for it to learn to understand.
The supervised algorithm now compares the input to the output and the picture to the label of the animal type. It will eventually learn to recognize a certain kind of animal in new photos it encounters.
Unsupervised machine learning
Unsupervised ML algorithms are like SPAM filters today. Initially, administrators could program SPAM filters to look for specific words in the email to understand SPAM. That is no longer possible, so unsupervised works well here. The unsupervised ML algorithm is fed emails that have not been labeled to begin to look for patterns. As those patterns are found, it will learn what SPAM looks like and identify it in the production environment.

Machine learning techniques
ML techniques solve problems. Depending on the problem that you are faced with, you choose a specific ML technique. Here are six common ones.
The regression technique
Regression can be used to predict home market prices or determine the optimal selling price of a snow shovel in Minnesota in December. Regression says that even though prices fluctuate, they will always return to the mean price, even though over time the prices of homes are increasing, there is an average that will always reoccur. You can plot prices over time on a graph and find the mean as time moves on. As the red line continues up the chart, it allows for the future predictions.
Classification
Classification is used to group data into known categories. You could be looking for customers that are predictably good customers (they always come back and spend more money) or are predictably going to start shopping elsewhere. If you can look back over time and find predictors for each classification of customers, you will apply that to current customers and predict which group they will fit. Then you will be able to market more effectively and possibly convert the customer that will potentially lead into an excellent returning customer. This is a good example of supervised ML.
Clustering
Unlike the classification technique, clustering is unsupervised ML. In clustering, the system will find how to group data that you do not know how to group. This type of ML is excellent for analyzing medical images, analyzing social networks, or looking for anomalies.
Google uses clustering for generalization, data compression, and privacy preservation in products, such as YouTube videos, Play apps, and Music tracks.
Anomaly detection
Anomaly detection is used when you are looking for outliers, like spotting the black sheep in a flock. When looking at a massive quantity of data, these anomalies are impossible for humans to find. But, for example, if a data scientist fed a system medical billing data from many hospitals, anomaly detection would find a way to group the billing. It might discover a set of outliers that turns out to be where fraud occurs.
Market basket analysis
The logic of market basket analysis allows for future predictions. A simple example – if customers put ground beef, tomatoes, and tacos into their basket, you could predict that they’ll add cheese and sour cream. These predictions can be used to generate extra sales by making valuable suggestions to online shoppers for items they would have forgotten or to help group products at a store.
Two professors at MIT used this approach to discover the “harbinger of failure.” As it turns out, some customers like products that fail. If you can spot them, you can determine whether to continue to sell a product and what kind of marketing to apply to increase sales from the right customers.
Time series data
Time series data is commonly collected about many of us with fitness monitors on our wrists. It can collect heartbeats per minute, how many steps per minute or hour we take and some now even measure oxygen saturation over time. With this data, it would be possible to predict when someone will run in the future. It would also be possible to collect data about machinery and predict failure because of the time-based data about vibration level, dB noise level, and pressure.
Machine learning algorithms
If ML is supposed to learn from data, how do you design an algorithm for learning and finding the statistically significant data? ML algorithms support the process of supervised, unsupervised, or reinforcement ML.
Data engineers write pieces of code that are the algorithms that allow a machine to learn or find significance in data.
Let's look at a few specific algorithms that are the most common. Here are the top five in use today.
- Linear regression algorithms establish a relationship by fitting independent and dependent variables to a graph and plotting a straight line for the mean or the trend. Merriam-Webster defines regression as "a function that yields the mean value of a random variable under the condition that one or more independent variables have specified values." This definition applies to logistic regression as well.
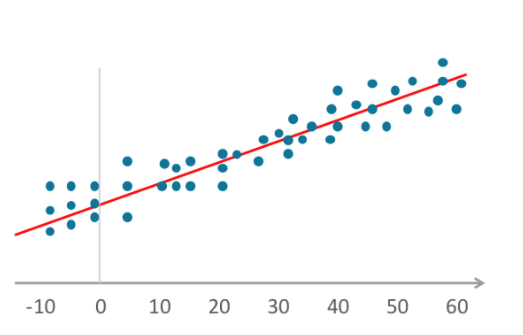
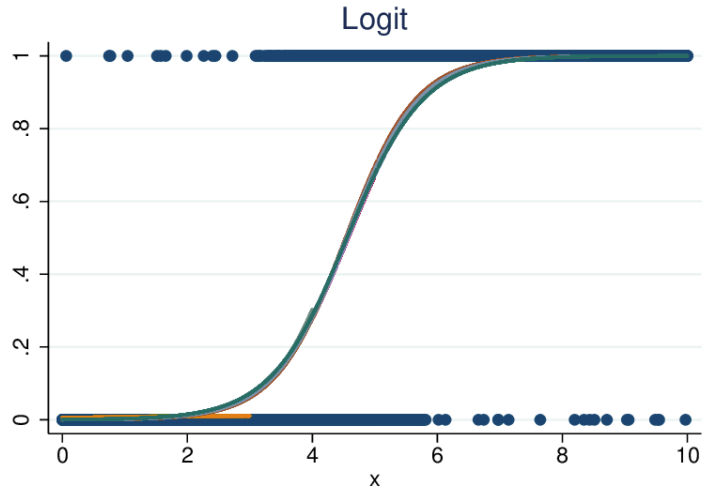
- Logistic (a.k.a. logit) regression also fits variables to a graph, as does linear regression, but the line is not linear. The line here is a sigmoid function.
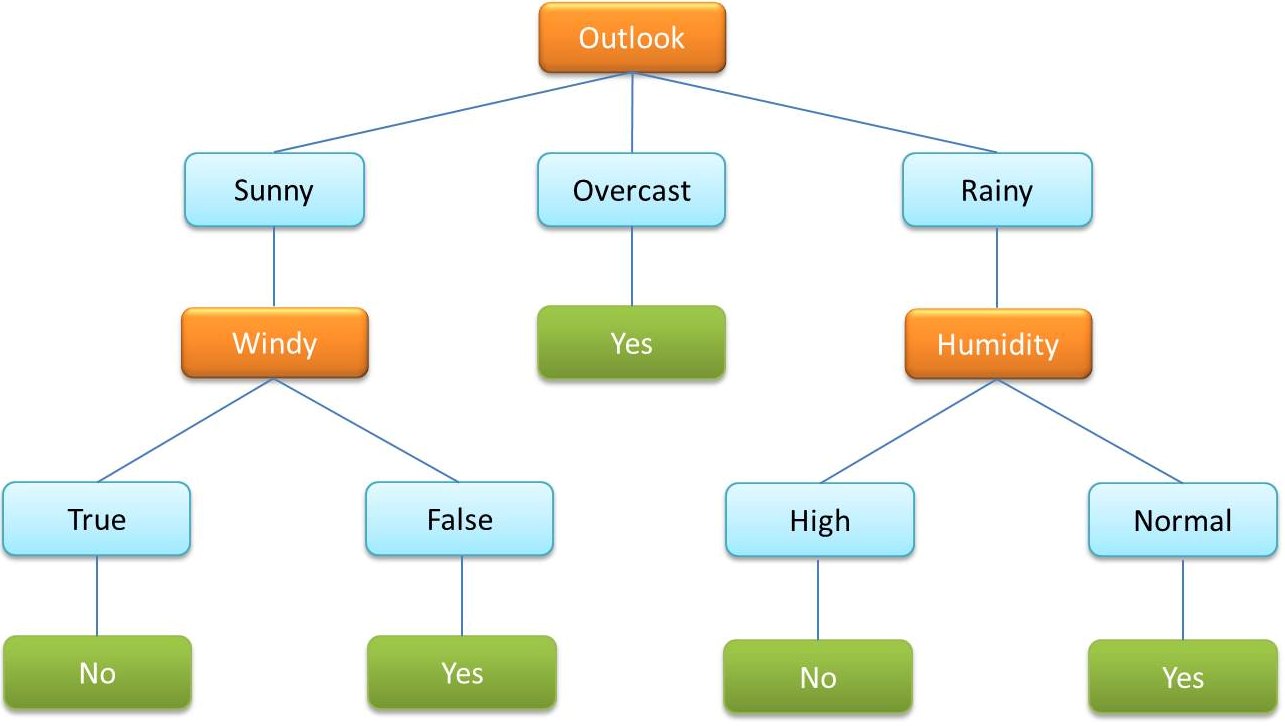
- A decision tree is a very commonly used algorithm within supervised ML. It is used to classify data by categorical and continuous variables.
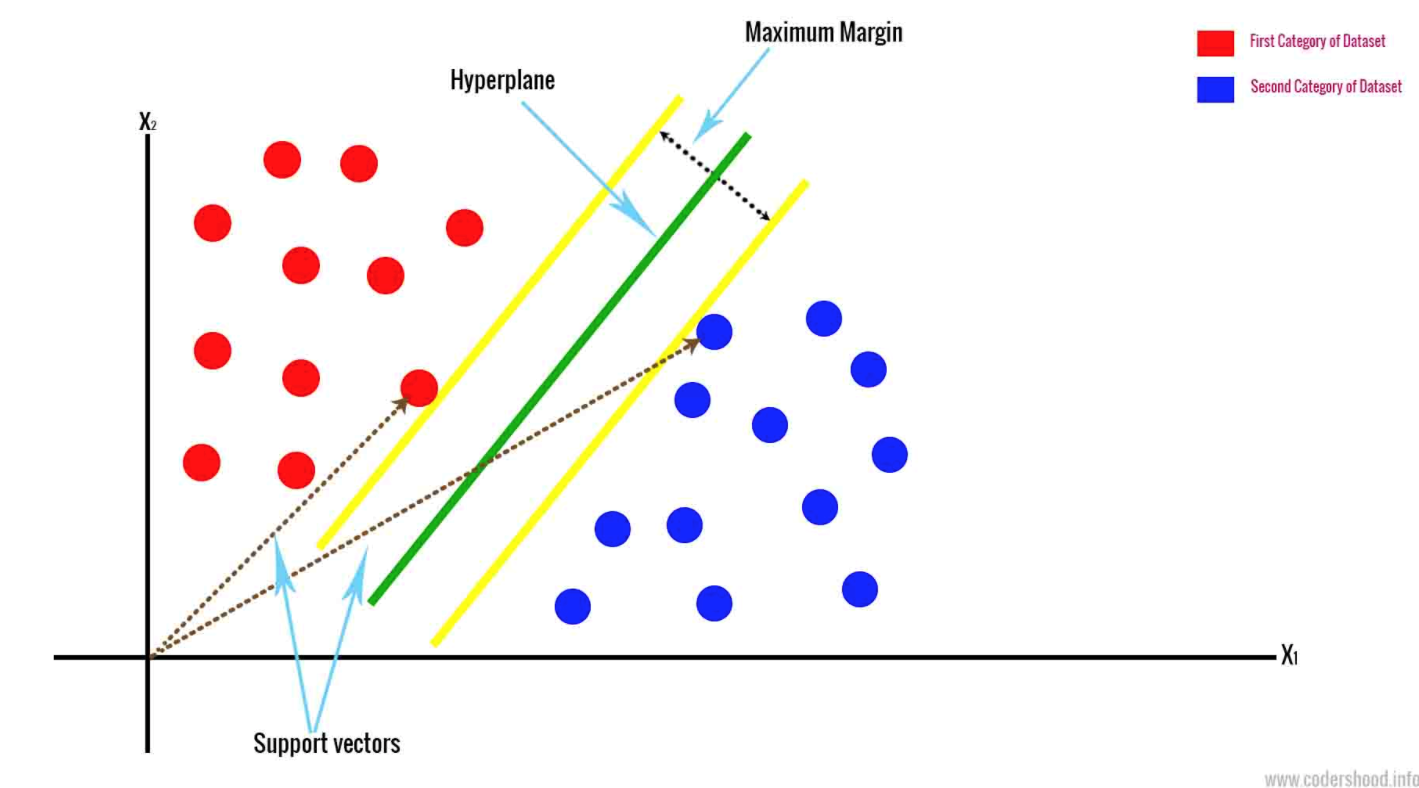
- Support Vector Machine draws a hyperplane based on the two closest data points. This separates the data by marginalizing the classes. It classifies data based on an n-dimensional space. N represents the number of different features that you have.
- Naive Bayes calculates the probability of a particular outcome. It is very effective and outperforms more sophisticated classification models. A Naive Bayesian classifier model will understand that any given feature is not related to the presence of other particular features.
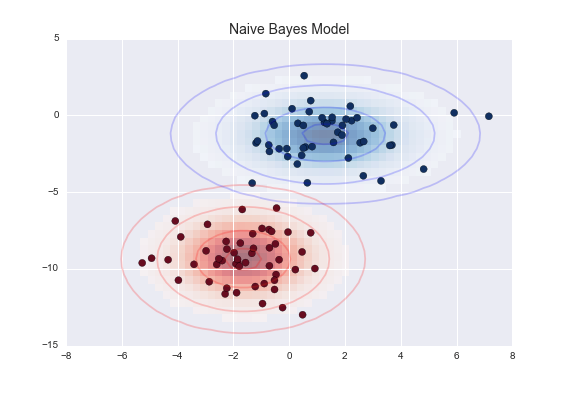
Machine learning models
After combining the type of ML (supervised, unsupervised, etc.), the techniques, and the algorithms, the result is a file that has been trained. This file can now be given new data and will be able to recognize patterns and make predictions or decisions for the business, the manager, or the customer as needed.
Best languages for machine learning
Machine learning languages are how instructions are written for the system to learn. Each language has a user community for support to learn from or guide others. There are libraries included within each language for machine learning uses.
Here are the top 10:
- Python
- R
- Java
- Julia
- Scala
- C++
- JavaScript
- Lisp
- Haskell
- Go
Python machine learning
As Python is the most common ML language, here is more on it specifically.
Python is an interpreted, open-source, object-oriented language named after Monty Python. Because it is interpreted, it is converted to bytecode before it is executable by a Python virtual machine.
There are a variety of features that make Python a preferred choice for ML.
- A large set of powerful packages that are available for use now. There are specific ML packages such as numpy, scipy, and panda.
- Easy and fast to prototype.
- There are a variety of tools that allow for collaboration.
- As a data scientist moves from extraction to modeling and through to updating their ML solution, Python can continue to be the language of choice. The data scientist does not have to change languages while moving through the life cycle.
Where can I get help to better utilize machine learning (ML)?
Machine learning can significantly enhance a cybersecurity platform’s ability to protect your organization, employees, and partners by enabling faster, smarter, and more proactive threat detection and response.
Trend Vision One™ is the only AI-powered enterprise cybersecurity platform that centralizes cyber risk exposure management, security operations, and robust layered protection. This comprehensive approach helps you predict and prevent threats, accelerating proactive security outcomes across your entire digital estate. By leveraging large-scale security datasets, advanced behavioral analysis, and anomaly detection models, Trend Vision One helps identify both known and previously unseen threats, including zero-day exploits and targeted phishing campaigns.


Joe Lee is Vice President of Product Management at Trend Micro, where he leads global strategy and product development for enterprise email and network security solutions.
Frequently Asked Questions (FAQs)
What is meant by machine learning?
Machine learning is a subset of artificial intelligence (AI) that enables computer systems to mimic how human minds make complex decisions and learn from experience.
What is machine learning in simple terms?
Machine learning is a type of AI that enables computers to learn from data and improve their performance over time, without needing to be explicitly programmed for every task.
What is an example of machine learning?
An example of machine learning would be facial recognition technologies, where a computer system learns to recognize visual inputs so it can eventually identify human faces.
What are the 4 types of machine learning?
The four main types of machine learning (ML) are supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning.
What is the difference between AI and ML?
Artificial Intelligence (AI) refers to systems designed to mimic human-like intelligence. Machine Learning (ML) is a subset of AI that finds patterns in data to improve system performance.
Is ChatGPT LLM or generative AI?
ChatGPT is an example of both an LLM (large language model) and generative AI (GenAI).
Is a chatbot AI or ML?
Chatbots are usually developed using both artificial intelligence (AI) and machine learning (ML) technologies.
What is AI but not ML?
Some AI systems don’t rely on machine learning, such as rule‑based expert systems, symbolic reasoning systems, and pre‑programmed algorithms that follow fixed rules.
Which is better, AI or ML?
Depending on what you need, neither is ‘better.’ ML is a subset of AI that allows computer systems to learn from experience without human supervision.
Should I learn AI or ML first?
It depends on your interests and goals. But most people learn AI first before specializing in subsets of AI technology like machine learning (ML).